
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于B/S模式的三大索引论文数据管理系统
引用本文
倚海伦, 李晶, 师俏梅. 基于B/S模式的三大索引论文数据管理系统. 现代图书情报技术, 2010, 26(7-8): 120-124
Yi Hailun, Li Jing, Shi Qiaomei. Three Famous Indexes Paper Data Management System Based on B/S Architecture. New Technology of Library and Information Service, 2010, 26(7-8): 120-124
Permissions
Yi Hailun, Li Jing, Shi Qiaomei. Three Famous Indexes Paper Data Management System Based on B/S Architecture. New Technology of Library and Information Service, 2010, 26(7-8): 120-124
Copyright©2010, The modern information technology editorial office
This article is the open access journal literature, in the following situations are free to use: academic research and academic exchanges, scientific research and teaching, etc., but don't allow for commercial purposes.
基于B/S模式的三大索引论文数据管理系统
摘要
以TRS全文检索系统为平台,利用TRS Java应用开发接口以及JFreeChart、POI等开源插件技术开发基于B/S模式的三大索引收录西北工业大学论文数据管理系统,实现三大索引数据管理业务的网络运行,具有网上信息检索、数据维护、图表统计、报表生成等功能。
关键词:
三大索引; TRS; JFreeChart; POI
中图分类号:G252
Three Famous Indexes Paper Data Management System Based on B/S Architecture
Abstract
Based on the TRS full text retrieval platform, this paper presents a Three Famous Indexes Paper Data Management System designed by B/S architecture, TRS Java API and open plug-in technology such as JFreeChart and POI. This system realizes a Web-based data management, which provides such functions like information retrieval, data maintenance, graphical statistic and Excel generation.
Keyword:
Three famous indexes; TRS; JFreeChart; POI
1 引 言
近年来,对高校科研人员发表论文被SCI、EI、ISTP三大索引收录的情况进行查证,已成为科研绩效评估、职称评定的重要依据。为了提高学校科研水平,使读者能够全面了解学校科研现状,图书馆多年来致力于对学校科研人员论文收录数据的收集整理工作,通常采用分学院按季度、年度的归类方法,网页发布、邮件推送、馆刊印刷等发布方式为读者提供三大索引收录学校论文信息及相关服务。然而,随着数据的积累,这种传统的手工管理方式不仅工作量大、容易出错,而且存在数据检索、查询困难,数据内容不易更改,数据统计工作繁重等问题,极大地影响了图书馆员的工作效率。因此,对三大索引收录的论文数据进行科学有效的管理显得尤为重要。
本文从系统开发的角度,对基于TRS系列产品构建的三大索引论文数据管理系统的设计与实现进行详细介绍。与众多利用TRS系统制作的全文检索系统相比,本系统的特色在于它不再仅仅是一个自建数据库的检索系统,而是更侧重于对数据的管理维护和统计分析,是建立于TRS平台的、综合利用TRS Java应用开发接口技术[ 1, 2]以及JFreeChart[ 3]、POI[ 4]等开源插件技术的论文数据管理系统,通过该系统,传统的三大索引论文整理工作具有了基于Web的信息检索、数据维护、图表显示、报表生成等新功能,为图书馆信息咨询工作提供了一个实用性的服务平台,有助于提高咨询馆员的工作效率。
2 系统的功能需求及结构设计
根据以上分析,为满足咨询馆员的多样化需求,三大索引论文数据管理系统应具备以下几个基本功能:
(1)基于Web的论文信息检索。系统可以按照题名、作者中英文姓名、学院、收录号等检索词进行在线关键词检索、二次检索、截词检索,并支持检索结果的浏览、排序、下载等功能。
(2)基于Web的论文数据内容维护。系统支持基于Web的数据新增、删除、修改操作,以满足用户移动作业的需求。
(3)基于Web的批量数据装载入库。系统允许授权用户经由网络批量装载新数据,比如季度数据或年数据。
(4)基于Web的图表统计分析。对三大索引论文收录数据进行报表统计是咨询馆员的日常工作之一,为摆脱繁杂的手工统计模式,自动统计分析功能不可或缺,这要求系统应能够自动地从后台数据库中挖掘有价值的信息,对三大索引论文收录情况按年份、按学院进行分类统计,并生成基于Web的柱状图、表格以及可供下载的Excel报表。
(5)基于Web的用户管理。系统支持用户的权限分级以保证数据库的安全操作,为此,基于Web的用户管理需要实现用户的权限设置、密码修改等功能。
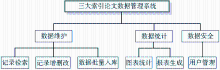
系统的功能结构设计如图1所示:
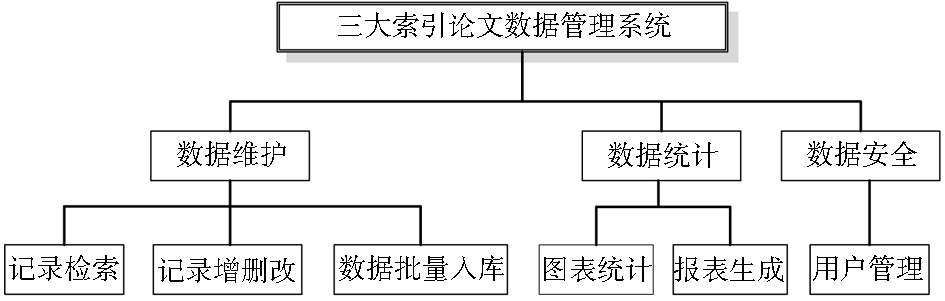 | 图1 三大索引论文数据管理系统功能结构图 |
3 系统实现
3.1 系统平台
本系统运行环境为Windows Server 2003,在Dreamweaver MX 2004、NetBeans 6.5调试环境下采用Java、JSP、JavaScript、CSS、TRS JavaBeans等技术,实现数据的读写操作以及页面的动态生成。
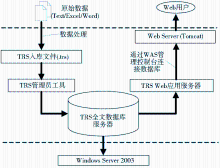
基于对检索准确性、检索效率以及检索功能多样性等方面的考虑,选用TRS信息发布检索系统作为开发平台, 具体包括TRS全文数据库服务器、TRS Web应用服务器和TRS管理员工具三个部分,系统架构如图2所示:
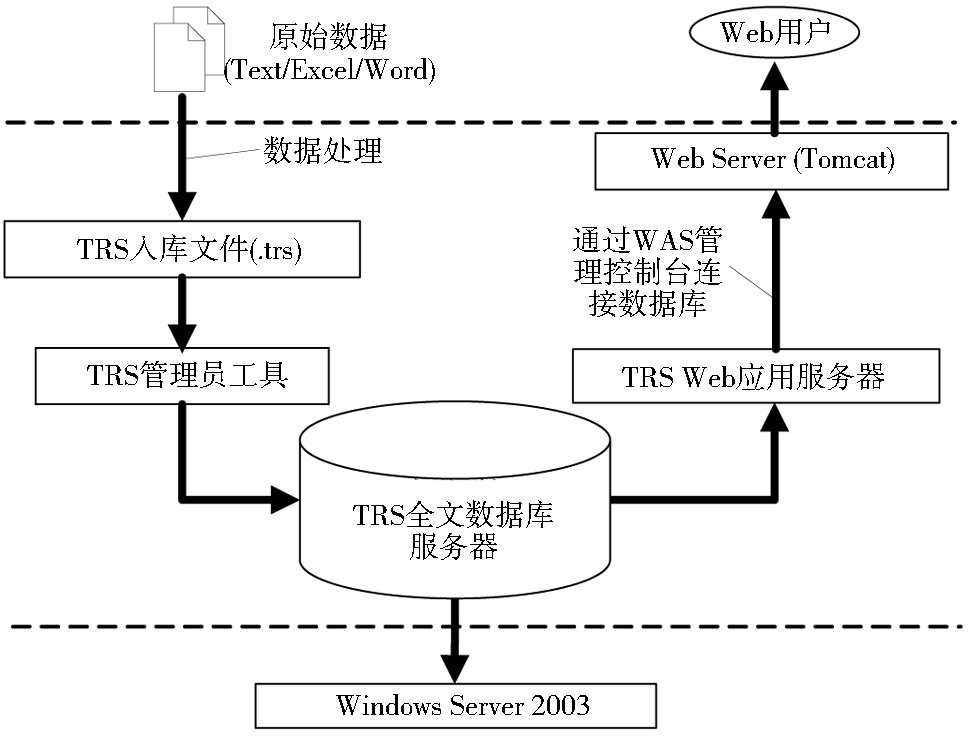 | 图2 三大索引收录数据管理系统架构图 |
尽管TRS管理员工具完全可以实现数据维护功能,但却依赖于客户端软件的安装。为避免这种依赖性,借助TRS Web应用服务器的B/S模式,实现基于Web的数据管理,客户端只需安装通用的Web浏览器即可完成具体的数据库操作。
3.2 数据库设计与频道建立
三大索引论文数据包括全校师生历年发表的被EI、SCI、ISTP收录的论文信息,由于这三个检索系统所包含的论文信息存在差异,故分别建立三个数据库,定义各自的字段名称和类型,以分别存储EI、SCI、ISTP的收录数据。
构建好数据库之后,需要在Web信息发布频道和后台数据库之间建立连接关系,因此,系统通过WAS管理控制台相应地建立了EI、SCI、ISTP三个频道,并对其所在TRS服务器的IP地址和端口号、关联数据库进行设置,以保证数据库连接的正确性。
3.3 主要功能模块及关键技术
(1)利用TRS JavaBeans实现数据库的读写操作
数据库的读写操作可以通过将表现层与逻辑层相分离的JavaBean技术实现,本系统即借助TRS Java应用开发接口(TRS JavaBeans)[ 2]来完成对TRS数据库的读取与写入。TRS JavaBeans组件封装了与TRS数据库服务器相关的诸多Java类,为操纵TRS数据库提供了统一的接口,只需在程序中引入trsbean.jar库文件,即可调用其中的Java函数进行相应的数据库操作。这里以基于Web的批量数据入库模块为例,介绍TRS JavaBeans的实际应用。
该模块为馆员提供了一个开放的基于Web的数据装载接口,改变了依靠TRS管理员工具软件装入数据的传统方式,是整个系统易用性、独立性的重要体现。模块主要分为两部分:入库文件与目标数据库参数的获取,以及数据库的连接、装库操作。入库文件必须是由一条或多条记录数据组成的带有TRS标记的、符合TRS记录格式的.trs文件。目标数据库参数包括数据库服务器IP地址、端口号以及用户名、密码。数据库连接和装库操作通过TRS JavaBeans所封装的TRSConnection、TRSDataBase两个类及其方法来实现,核心代码如下:
try{
TRSConnection trsConnection = new TRSConnection();
trsConnection.connect(ip,port,user,password); //建立与TRS服务器的连接
TRSDataBase trsDataBase = new TRSDataBase (trsConnection, "system." + db); //建立数据库对象
RecordReport report = trsDataBase.loadRecords(loadpath, null, false); //装库并返回装库结果摘要信息
…
}catch(TRSException e){
…
}
(2)利用TRS置标实现概览/细览功能
检索结果首先以概览页展示,它是对检索结果的列表显示,用户可以对结果列表进行标记,并按所选记录进行下载,也可点击相关记录的“题名”链接,查看该记录的全字段信息,即结果的细览。概览与细览需要通过包含TRS置标的HTML或JSP文件来实现,TRS置标是TRS Web应用服务器实现内容与表现相分离的核心技术。例如,在用于控制概要浏览记录信息的概览页面文件中加入概览置标元素<TRS:Outline></TRS:Outline>,就可以精确控制数据库的显示内容。对于显示单篇记录数据的细览页面,则使用细览置标<TRS:Detail></TRS:Detail>控制显示内容。确定好概览与细览字段内容之后,结合页面CSS样式以及概览导航、细览导航置标能够实现页面的动态分页功能,最终呈现完整的概览与细览JSP页面。
(3)利用Servlet实现数据维护功能
数据的插入、删除、修改和下载等维护功能允许用户以B/S的方式与TRS数据库服务器进行交互操作,其具体实现机制是通过TRS WAS自带的Servlet完成。例如完成插入操作的loadrecord,完成删除操作的delete,完成修改操作的update,实现下载功能的download等。这些带有参数的Servlet实际是一些运行于服务器端的Java应用程序,完全由Web服务器进行加载,具有独立于平台和协议的特性。在实际应用时,只要在提交表单中设置action为相应的Servlet名称,并通过隐藏表单域传递这些Servlet请求的参数,就可以直接通过HTTP方式从外部访问这些功能。以完成数据插入功能的loadrecord为例,其调用过程如下:
此外,还需要通过web.xml文件对该Servlet进行部署,完成对loadrecord的名称和类的映射以及名称和URL地址的映射[ 5]:
<servlet>
<servlet-name> loadrecord </servlet-name>
<servlet-class>com.eprobiti.was.servlet.Loadrecord </servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>loadrecord</servlet-name>
<url-pattern>/ loadrecord </url-pattern>
</servlet-mapping>
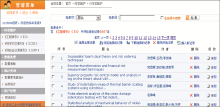
数据维护界面如图3所示:
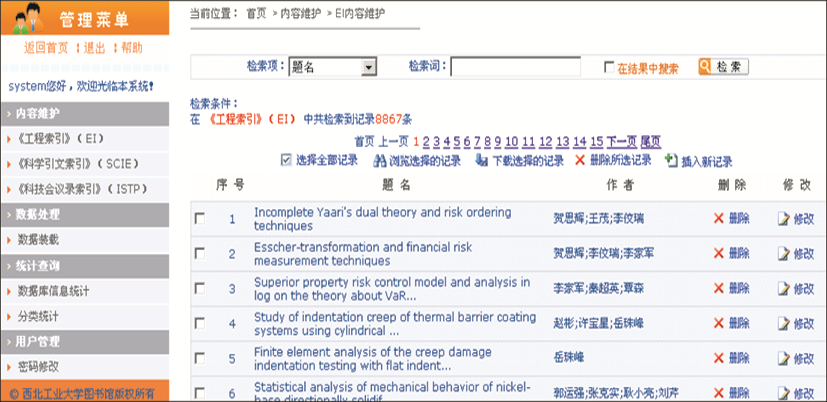 | 图3 “内容维护”页面展示 |
(4)利用开源插件技术实现基于Web的图表统计、报表生成
本模块为管理人员提供了一个智能化、可视化的统计分析平台,主要实现数据的自动汇总统计,包括对历年来三大索引收录学校论文数据按年统计和按学院统计,统计结果可以以基于Web的柱状图直观显示,也可以生成网页表格并提供Excel报表生成和下载功能。
系统应用图表绘制类库JFreeChart[ 3]实现柱状图的自动生成和Web显示,具体实现步骤如下:
①配置访问图片的Servlet[ 6];
②连接TRS数据库,获得数据库连接对象trsConnection;
③构造检索条件,检索数据库,获得检索结果集trsResultSet;
④通过柱状图数据集对象DefaultCategorydataset建立数据集实例Dataset,将trsResultSet中的数据保存在Dataset中;
⑤建立图表对象。图表对象 JFreeChart代表了要显示的图形,可以由工厂类ChartFactory 创建柱状 JFreeChart对象,并进行图表显示样式的设置。
⑥生成图片,详见文献[6]。
除了图表显示外,系统还提供了报表输出成Excel的功能,这样馆员就可以利用Excel的强大功能继续编辑数据报表。为实现与MS Office的交互操作,系统引入了一个第三方库——POI[ 4],它是Apache的一个开放源项目,由几个Jar包组成,可以应用于任何Java程序,具体配置及使用方法如下:
①将POI功能包解压缩至\tomcat\common\lib路径下,确保库的正常引用;
②在JSP页面中通过Page指令的Import变量引入POI包;
③分别创建Excel工作薄实例、表格实例、表格行实例以及单元格实例,并调用相应的函数生成完整的Excel报表;
④通过数据流对象FileOutputStream创建输出文件,并默认上传至服务器指定路径下;
⑤采用文件流输出的方式实现Excel表格的下载功能。当用户点击“下载Excel文件”按钮时可以将Excel报表保存到客户端本地指定路径下。核心代码如下:
response.setContentType("application/x-download");
String filedisplay = "year.xls"; //为用户提供的下载文件名
filedisplay = URLEncoder.encode(filedisplay,"UTF-8");
response.addHeader("Content-Disposition","attachment;
filename=" + filedisplay);
OutputStream outp= null;
FileInputStream in = null;
try{
outp= response.getOutputStream();
in = new FileInputStream(savepath1);
byte[] b = new byte[1024];
i = 0;
while((i = in.read(b)) > 0){
outp.write(b, 0, i);
}
in.close();
outp.flush();
outp.close();
}catch(Exception e){
…
}
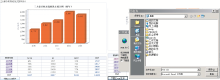
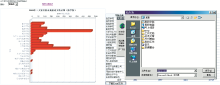
基于Web的按年和按学院图表统计、报表生成界面如图4和图5所示:
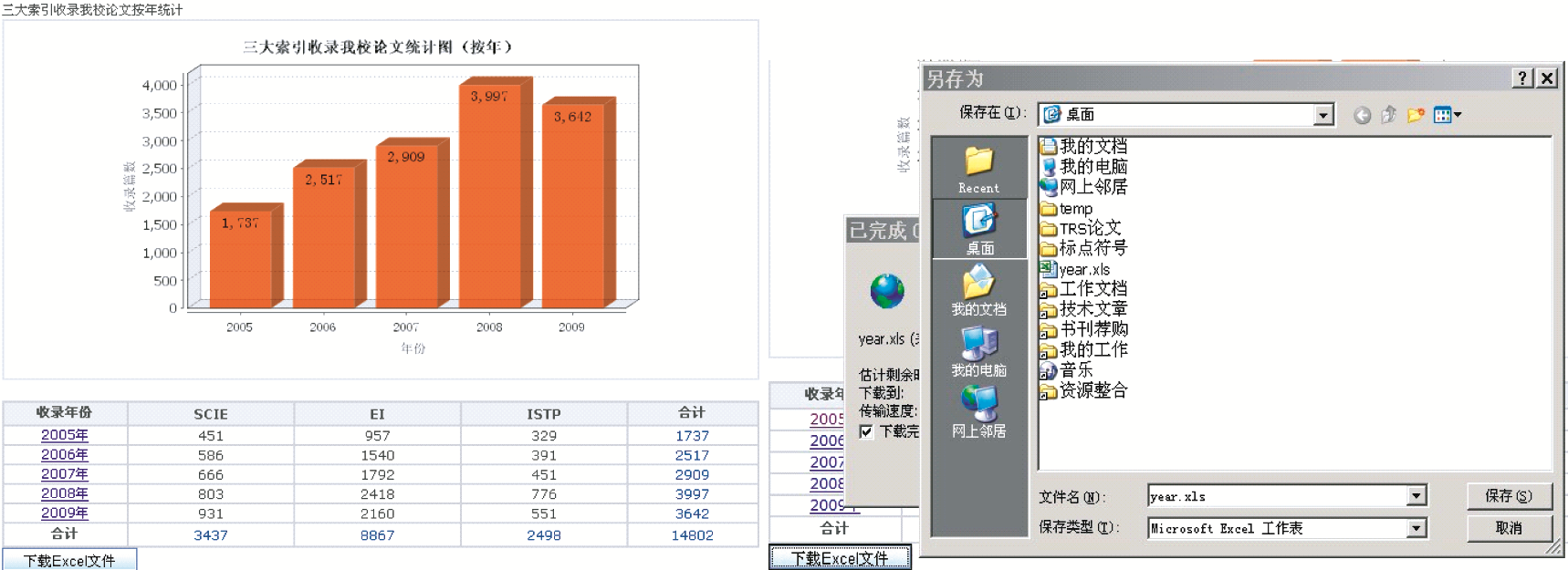 | 图4 “按年”图表统计和Excel报表下载 |
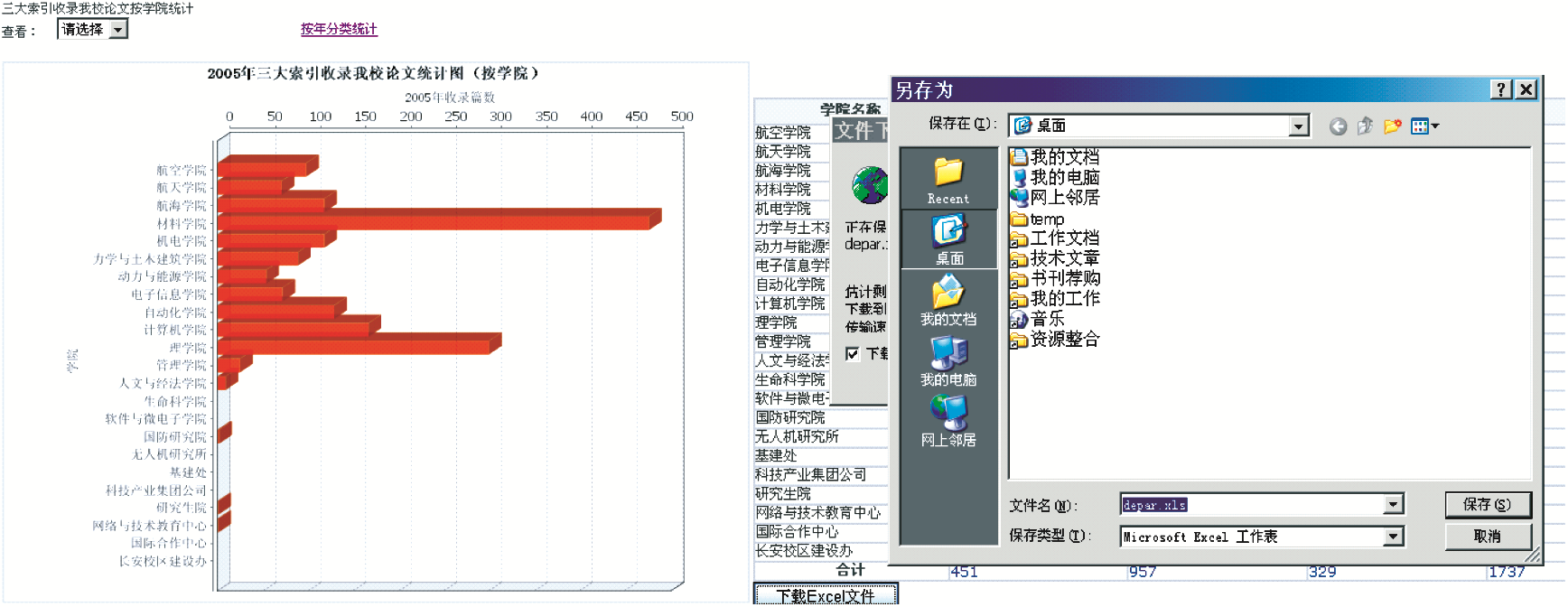 | 图5 “按学院”图表统计和Excel报表下载 |
(5)利用TRS权限管理实现用户安全管理功能
安全性对于任何一个数据库管理系统来说都是至关重要的。因此,用户安全管理成为三大索引论文数据管理系统一个必不可少的模块。
当用户访问数据库时,必须经过三个认证过程:
①数据库的身份认证,只有用户名和密码验证成功的合法用户才被允许登录管理系统。
②若是合法的用户,当其要进行具体的数据库操作时,系统还要进一步验证此用户是否具有数据库的操作权。
③当用户操作数据库中的数据时,还必须具有相应的数据操作权。
在TRS平台下,这三层安全控制都可以通过TRS的权限管理来实现,具体可分为4个级别,即用户级权限、数据库级权限、字段级权限和记录级权限。对应于用户的类型,用户级权限由高到低可依次细分为超级用户、系统数据库管理员、用户组数据库管理员、系统资源用户与系统登录用户。数据库级权限规定了对数据库的检索权、更新权、索引权和删除权,字段级权限和记录级权限是针对字段与记录的检索权、更新权、索引权和删除权。以上所述各种权限的管理都可以由最高级权限管理员在TRS Web应用服务器和TRS管理员工具中设置完成,普通用户则可以在本系统的用户管理功能中实现基本的权限管理,例如用户口令与密码的修改操作。
4 结 语
本文对三大索引论文数据管理系统进行了详尽的研究,该系统在西北工业大学图书馆信息咨询工作中取得了良好的应用效果,达到了系统设计的预期目的。实践证明:基于B/S模式的三大索引论文数据增删改、数据批量入库以及用户安全管理功能使得数据库内容维护工作可以不依赖于TRS管理员客户端工具软件进行,在明显提高馆员工作效率的同时,促进了数据管理的有效性与安全性;基于B/S模式的图表统计与报表下载功能为馆员提供了一个可视化的信息统计平台,为进一步的数据分析工作提供了一定的参考和借鉴。目前,系统尚存在的问题是图表统计还仅限于按年度、按学院的分类统计,而统计作者被收录的论文篇数以及收录论文的期刊分布情况在实际工作中对于把握全校师生科研实力及影响力状况也是必不可少的,这将在日后的工作中得以完善。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|