



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
InfoVisModel可视化原型系统的实现
[周宁 , 何坚]
, 何坚]
, 何坚]
|
|


主要讨论信息可视化原型系统的理论方法和实现技术。具体探讨可视化模型的构建策略、原型系统的环境配置、功能模块和操作方法;文本信息、语音(音频)信息、图像信息可视化模型的构建、数据准备与数据规模、操作界面与运行结果。该原型系统的研究不仅是通用信息资源管理可视化模型的有益尝试,而且在中文信息可视化方面也取得一定的经验。
This article mainly discusses the theoretical methods and technologies of information visualization prototype system. It specifically discusses constructing strategy of visualization model, environmental configuration, functional module and operation method of prototype system. What’s more, it also discusses construction of text, voice (audio) and image information visualization model, data preparation and data scale, operation interface and running result. The research on this prototype system is not only a helpful attempt in studying visualization model of general information resources management with certain experience achieved, but also a successful explore in terms of visualization of Chinese information.
InfoVisModel通过对各种可视化模型调研分析,分别实现了文本、音频、图像的可视化模型的构建,并且将其应用到文本、音频、图像的可视化检索中,实现了文本、音频、图像的可视化检索。系统的主界面如图1所示:
 | 图1 InfoVisModel系统主页 |
InfoVisModel可视化原型系统处理的数据量达到10 000个信息对象,其中,文本可视化检索处理的文本数据为3 600条期刊论文数据;图像可视化检索处理的图像对象为1 700幅;音频可视化检索处理的音频数据达4 700首。论文数据采用了半自动的采集方式,从中国期刊网[ 1]采集而得;音频数据采用网络爬虫程序,由Yahoo音乐库[ 2]自动采集而得;图像数据采用爬取程序,由Baidu图像库[ 3]自动采集而得。
如图2所示,InfoVisModel系统将信息可视化分为三大模块,其主题动画由5幅图片缩放展开:
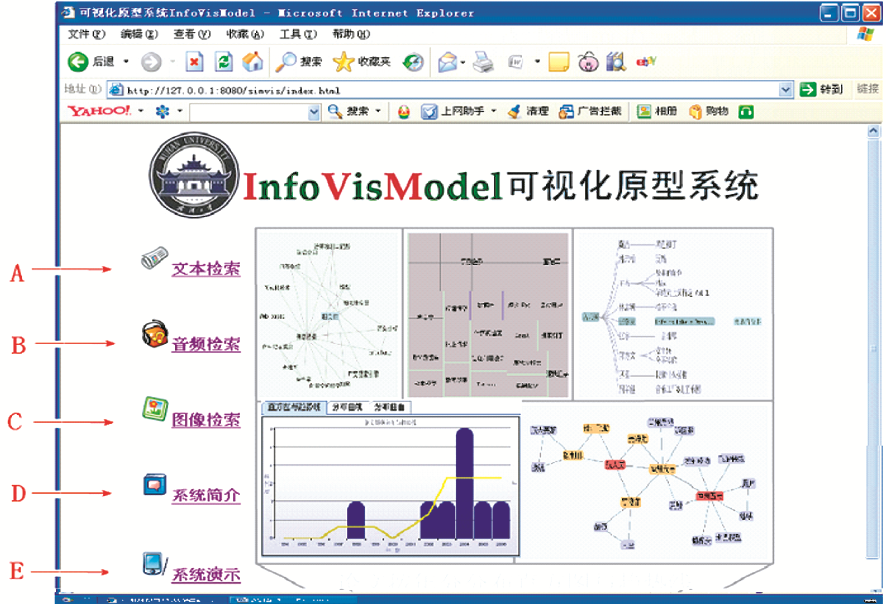 | 图2 InfoVisModel原型系统主页的布局 |
(1)文本检索(见A→):文本信息可视化模块包括文本信息采集、文本信息标引、文本信息检索、文本信息可视化数据生成及文本信息可视化界面展示等功能;
(2)音频检索(见B→):音频信息可视化模块包括音频信息采集、音频信息标引、音频信息检索、音频信息可视化数据生成及音频信息可视化界面展示等功能;
(3)图像检索(见C→):图像信息可视化模块 包括图像信息采集、图像信息标引、图像信息检索、图像信息可视化数据生成及图像信息可视化界面展示等功能。
另外,InfoVisModel系统还有两项辅助功能:
(1)系统简介(见D→):对原型系统进行全面介绍;
(2)系统演示(见E→):用图、文、声多媒体对系统自动演示。
根据信息可视化参考模型[ 4],可以将信息可视化模型构建分为三步:
(1)数据准备:确定和获取可视化的原始数据,形成原始数据空间;
(2)数据析取:从原始数据中析取需要可视化的数据,形成可视化数据空间;
(3)可视化映射:采用一定的映射算法把可视化数据空间映射到可视化对象。
为形成原始数据空间,需要从其他数据源(如中国知网期刊数据库和搜索引擎等)中获取数据形成本系统的原始数据源,需要实现信息的采集和标引。因此,InfoVisModel系统的文本检索、音频检索和图像检索功能整体上分为5个部分,如图3所示:
 | 图3 可视化的进程 |
(1)信息采集:从数据库中或万维网上采集需要的信息资源;
(2)信息标引:对采集得到的信息资源进行标引形成原始数据源;
(3)信息检索:根据检索需要从原始数据源中查询符合结果的信息列表;
(4)可视化数据生成:将检索结果中需要进行可视化展现的数据转换为可视化数据;
(5)可视化界面展示:将可视化数据映射为可视化对象展现在可视化界面上。
InfoVisModel可视化原型系统采用了流行的B/S模式。整个开发过程采用强大的免费开源集成开发环境Eclipse平台[ 5];信息标引和检索使用Lucene工具包[ 6]完成;可视化功能使用开源的Prefuse及Char2D Java工具包实现;XML封装和解析使用Dom4j工具包[ 7];而Web服务器使用Apache Tomcat[ 8]构建。
InfoVisModel系统中文本信息可视化模型构建过程为系统模型实现了文本信息的自动/半自动采集,采集得到的文本信息以XML的形式提供给标引模块;文本标引模块通过对源文本XML库建立索引,生成文本索引数据库即是原型系统的文本原始数据源;用户通过检索界面提交检索式,文本信息检索模块在索引数据库里匹配符合需求的文档;文本信息可视化数据生成模块将检索列表中的关键词信息生成两个XML文档[ 9]:关键词分布XML和关键词关联XML;为文本信息可视化展现模块提供可视化数据支撑;文本信息可视化界面不仅展现关键词分布图、关键词关联图、论文按年份分布直方图,还给出相关的检索列表及其他检索结果信息。
由此可知,文本信息可视化模型主要使用XML作为数据转换的接口,原始文本信息采集的最终结果使用XML文档提交;而可视化数据采用Prefuse提供的XML接口。使用XML作为数据接口,可以提高系统的可扩展性。例如,系统可以接受其他文本信息源的数据,只要这些文本信息源能够转换为系统定义的源文本XML格式,系统即能将其自动标引,添加到索引数据库,成为本系统的原始数据源。而基于XML的可视化数据格式则可以较好地满足多种可视化展现形式的需要,如各种点线式、填充式树形结构等。
文本信息可视化主要实现了关键词关联可视化及关键词分布可视化,分别利用Prefuse提供的RadialGraphView和TreeMap类及Char2D提供的Histogram类实现。
(1)关键词关联可视化的原理是认为同一篇文献标引的关键词之间具有联系,将某一学科领域多篇文献的关键词根据这种联系形成的网络结构就能在一定程度上代表这一学科的知识结构,关联词可视化实质是通过关键词之间的联系揭示知识结构,而关键词的联系依据词共现的原理确定;
(2)关键词分布可视化则是将标引同一关键词的文献归入同一层次结构,形成树形结构,其中树形结构使用填充式树——TreeMap实现。
这样,不仅给出了层次结构关系,而且可以反映其他诸如文献在同一关键词的数量指标,关键词可视化的实质是揭示关键词和文献之间的联系,将同一关键词的相关文献聚合;而论文按时间分布直方图则展示出与查询词对应的研究领域内,不同年份中发表的论文数,从而可以直观地分析出该领域是否为研究热点、是否为成熟研究领域等信息。
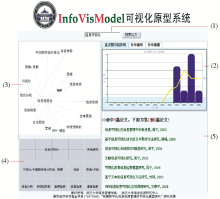
文本信息可视化界面包含5个部分,总体界面如图4所示:
 | 图4 文本信息可视化界面 |
(1)查询输入文本框
用户通过该文本框输入要查询的关键字,提交查询,如图4中(1)所示。如用户输入“信息可视化”,则该输入将被解析成为查询字符串,Lucene以此查询字符串为输入,检索生成结果列表,同时对结果列表进行信息抽取,分别抽取出关键词关系XML,关键词分布XML以及文献按时间分布频率数据;最终以可视化的方式展现给用户。
(2)文献发表时间可视化图
该图由一个Applet(Histogram.class)生成,这个Applet调用了Chart2D.jar。Chart2D是一个用于显示2D图表的可视化工具包,它可以很方便地绘制直方图、散点图、线型图、饼图等。为生成趋势图需要输入查询结果文献集合中的按时间统计的文献频率。以“信息可视化”作为查询字符串,最终命中9篇论文,与直方图对应的datastring为“0,0,0,0,0,0,0,0,0,3,1,4,1”,与之对应的直方图如图4中(2)所示。
图中纵坐标代表论文数,横坐标代表不同的年份。文献发表时间可视化图中,除了包含直方图及趋势线外,还包含分布曲线及分布曲面。
通过文献发表时间可视化图,可以清晰地看出文献按时间发表的规律,有利于分析与查询关键字对应的研究领域的研究周期、是否是热点以及在不同时间的受关注程度;进而帮助用户从宏观上把握研究领域的特点和规律,为论文撰写和阅读提供指导性建议。以“信息可视化”查询为例,结果显示其在2005年的发文率最高,代表在2005年是研究热点,而到了2006年热度有所下降;从趋势图可以看出,其已经越过了峰值,逐渐趋于平缓。
(3) Radial Graph View
如图4中(3)所示,该图由Applet生成,以kwRelation.xml作为数据输入。它反映了文献查询结果集合中的关键字之间的关联关系。
在Radial Graph中,点击某一节点,程序会以当前节点作为根,采用广度遍历算法,以当前节点为初始节点进行遍历,然后获取节点间的父子关系,生成一棵树,树中的节点对应图中的节点,树中的每个节点(根节点除外)都以它在图中的一个邻居作为父节点。在对生成的树进行展示时,采用“Radial Drawing”方法进行绘制。各个节点被排列在以根节点为中心的多个圆环上,每个节点处于哪个圆环上取决于它在树中所处的深度,深度越深,则离根节点(当前节点)越远,越处于远离根的圆环上。
对于Radial Graph,以当前节点为中心,向外扩展的发散图可以划分为多个扇区(Sector),每个节点在圆环上所处的位置取决于该圆环分配给该节点的扇区。每个节点处于其父节点的扇区内,而扇区分开的角度与该节点的子树的角宽度(Angular Width)成比例。这种方法被称为“Radial Placement”,其中所有的节点具有相同的大小,节点角宽度的大小取决于该节点子树的后代中叶子节点的数目。
除了静态地绘制各个节点和边外,Radial Graph还支持动态交互,当前节点发生变化时,可视化图会动态变化,用户可以看到图的变化过程,而不仅仅是另一张静态图。
采用Radial Graph View,不仅能显示出查询结果中每篇论文的关键字,还可以展示关键字之间的关系。通过这些关系的展示,可以帮助用户扩展思维,发现不同研究领域的相关性,发现紧密联系的领域,并对与查询关键字相关的领域有一个全面的认识;可以帮助用户发现新的查询词,起到一个关键字推荐的作用,通过限定更多的关键词,缩小查询范围;Radial Graph View的动态交互性可以使用户集中注意力于当前节点,并可以动态渐变地发现关键词关联关系的变化。
(4) TreeMap
该图由Applet生成,以kwDistribution.xml作为数据输入。它反映了每个关键词的文献分布频率。如果在查询结果集中,“信息可视化”在8篇文献中出现,则其频率为8。TreeMap可以直观地展示每个关键词在当前页面显示的多少篇论文中出现过,这样有利于观察关键词的分布特性。发现与关键词对应的研究领域的热门程度。以“信息可视化”查询结果为例,共查出9篇文献,在第一页中包含了8篇,其关键词分布TreeMap如图4中(4)所示,由于每篇文献都包含“信息可视化”关键字,因此与信息可视化对应的矩形框有8个,“方法研究”关键词在2篇文献中出现,因此与之对应的为2个。
(5)检索命中结果框
如图4中(5)所示,若命中结果多,可分页管理,页面号在本框下方排列。根据需要可自由选取所需页面,点击后可立即调出所需页面。最后显示该部分的结果列表。
音频信息可视化建模分为数据采集、数据析取和可视化空间映射三个实现环节。InfoVisModel系统音频信息可视化模型构建过程为音频信息的采集利用爬虫爬取Yahoo的音乐库的方式完成,采集得到的音频信息以XML的形式提供给音频信息标引模块;音频标引模块通过对源音频XML库建立索引,生成音频索引数据库即是原型系统的音频原始数据源;用户通过检索界面提交检索式,音频信息检索模块在索引数据库里匹配符合需求的音频信息;音频信息可视化数据生成模块利用检索结果中的艺术家、专辑名、歌曲名等信息生成音乐树XML,为音频信息可视化展现子模块提供可视化数据支撑;音频信息可视化界面不仅展现音乐图,还给出检索结果中的其他信息。
音乐树的生成基于用户检索音频信息(以音乐信息为例)时最为关注的艺术家、专辑名、歌曲名三方面信息,通过将检索结果生成以“艺术家—专辑名—歌曲名”顺序排列的层次结构,不仅提供了这三方面的信息,而且提供了它们之间的关联图,实现了对检索结果的自动分类,将同一艺术家的作品集中在一起,并且将同一艺术家的不同专辑也分别聚合在一起,便于进行相关检索,这样便于人们检索和利用音频信息。其中,音乐树的可视化展现利用Prefuse[ 10]中的TreeView类实现。
音频信息可视化界面包含三个部分,如图5所示:
 | 图5 音频信息可视化界面 |
(1)查询输入文本框
用户通过该文本框输入要查询的关键字,提交查询。如用户输入“爱情”,则该输入将被解析成为查询字符串,Lucene以此查询字符串为输入,检索歌曲名,对于包含“爱情”的歌曲,生成歌曲结果列表,根据结果列表输出歌曲信息,并生成MusicTree.xml用于可视化展示。
(2)音乐树视图
该视图是一个横向的树目录,在初始状态下显示三级目录:根目录、一级、二级。当用户点击某级目录时,将动态显示此目录的下两级子目录。这样能够将视图限制在有效区域内,而不会因为目录深度过大而使得展示空间不足。音乐树的一级目录为歌手名,是命中的结果中包含的歌手;二级目录为此歌手的专辑;三级目录为具体的命中的属于某专辑的歌曲名。以“喜欢”作为查询字符串的音乐树的初始化图。
(3)歌曲列表
将检索到的歌曲以列表的形式显示出来,每条歌曲信息包含歌手名、专辑以及歌曲名称。
InfoVisModel系统图像信息可视化模型的建立也分为数据准备(采集)、数据析取和可视化映射三部分。构建过程为图像信息的采集主要通过自动爬取Baidu搜索引擎中的图像库的方式完成,采集得到的图像信息以XML的形式提供给图像信息标引子模块;图像标引子模块通过对源图像XML库建立索引,生成图像索引数据库即是原型系统的图像原始数据源;用户通过检索界面提交检索式,图像信息检索模块在索引数据库里匹配符合需求的图像信息;图像信息可视化数据生成模块利用检索结果中的图像ID、关键词等信息生成图像关键词关联XML,为图像信息可视化展现子模块提供可视化数据支撑;图像信息可视化界面不仅展现图像关键词关联图,还给出检索结果中的其他信息。
图像关键词关联图主要基于图像的标注关键词之间的关联性。将多幅图像的关键词关联起来,能帮助用户寻找更合适的关键词来进行进一步查询。在实现时,图像关键词关联图的可视化展现利用Prefuse中的GraphView[ 11]类实现。
 | 图6 图像信息可视化界面 |
如图6所示,图像信息可视化界面包含三个部分:
(1)查询输入文本框: 用户通过该文本框输入要查询的关键字,提交查询。如用户输入“神州飞船”,则该输入将被解析成为查询字符串,Lucene以此查询字符串为输入,检索图像描述及图像关键字,生成图像结果列表,根据结果列表输出歌曲信息,并生成ImageGraph.xml用于可视化展示。
(2)图像-关键词关联图: 该视图是在一个基于图的数据结构上生成的可视化视图,采用的可视化模型为力导向模型(Force Directed Model)。它是一种基于物理方法的可视化模型,该模型将图的各个节点看作质点,而节点之间的边看作力的作用,或者是排斥力,或者是吸引力,当力的相互作用达到平衡时,即为最终的可视化图。所以可视化图是力之间相互作用的结果,在美学观点上看,力平衡时,图的可视化显示最美观。以“神州五号”作为查询字符串的图像-关键词关联图的初始化效果,从图6中可以看出,“神州五号”关键词节点位于图的中间,通过直线连接与之相关的图像(整数ID节点),代表这些图像的关键词都包含“神州五号”。从图中可以看出,除了“神州五号”外,“神州六号”、“神州飞船”和“杨利伟”三个关键词也关联了许多图片。
(3)图像结果列表: 以表格的形式显示结果图像,附带图像的ID、长宽、存储容量和格式信息。
综上所述,信息资源管理的可视化模型方法分图、文、声三类分别处理。它们分别经历数据准备、数据析取和可视化映射三个阶段来实现。这种可视化模型的生成过程不仅解决了通用信息资源管理可视化模型构建的难题,而且给InfoVisModel原型系统的研制成功提供了一个新的范例。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|