
{kind=link}
科技术语语义相似度计算方法研究综述
[徐健1  , 张智雄
, 张智雄2 , 肖卓3 , 邓昭俊1 ]
, 张智雄|
|


在对当前术语语义相似度计算进行分析研究的基础上,将科技术语相似度计算归纳为基于语料文集的相似度计算和基于开放知识资源的相似度计算,对相似度指标的集成算法进行综述。并对科技术语语义相似度计算在自然语言处理和知识挖掘方面的应用进行总结,对其未来研究发展进行展望,为进一步构建高效的术语相似度计算系统提供良好借鉴。
Based on the analysis of recent related literatures and projects, the paper concludes the term semantic measure methods as follows: similarity measure methods based on corpus characters and similarity measure methods based on open knowledge resources. And then it reviews the integration methods of multi-measure methods. It also summarizes the applications of term semantic similarity measure methods on the area of Natural Language Process (NLP) and Knowledge Mining (KM). Finally, the future development of research on term similarity measure is discussed to help build more efficient term similarity calculation system.
科研领域的快速发展导致了大量新知识的不断涌现。这些新的知识经常以各种概念、实体、事件、过程所对应的术语以及它们之间的关系表达出来。术语代表了特定的领域概念,例如实体、过程以及功能等,并且在特定主题内表现出高相关性。通过对术语之间相似程度的计算,能够为自然语言处理和知识挖掘的多项任务的开展提供重要支持。术语规范化、识别同义/近义词、基于实例的机器翻译等任务都将术语相似度计算作为任务过程的核心模块。在本体构建和知识库构建任务中,通过计算术语语义相似度,能够发现术语之间存在的新关系,并在此基础上实现本体自动构建。
对于术语相似度概念,学者们从不同角度进行了阐释。Hindle认为,术语的相似度取决于它们语境的相似程度[ 1]。Resnik认为,术语相似性可以通过它们之间共有的信息量来衡量[ 2]。共有信息量越高,则相似性越高。本文倾向于采用维基百科对“术语语义相似度”的定义,即术语语义相似度是一个用来说明术语之间语义内容相似程度的度量[ 3]。
术语语义相似度计算思路大致可归纳为两类:基于领域文集本身所携带的语词、句法、语境等特征开展相似度计算;基于本体、搜索引擎等开放知识资源开展相似度计算。此外,也有学者对各种相似度算法的集成方法进行了研究。
特定领域文集本身所携带的一些特征能够作为术语语义相似度计算的依据。这些特征可以进一步划分为基于语词构成的特征、基于句法模式的特征和基于语境的特征。
判断术语间相似关系的最直接的方法是测量术语构成语词的相似程度[ 4]。一些学者认为,术语的语词构成,也就是术语中关键词汇(Head)和修饰词汇(Modifiers)可以作为测度语词相似性的重要标志。Bourigault等在半自动术语抽取系统中,借助术语的关键词汇和修饰词汇特征来构造候选术语网络,为人工对候选术语的验证操作提供了便利[ 5]。通过术语抽取工具产生的多词候选术语,在句法解析阶段首先被分割为关键词汇和修饰词汇两部分,并以术语网络的形式组织在一起。该网络的纵向反映术语之间的关键词汇关联,横向反映术语之间的修饰词汇关联。术语网络的一个片段如图1所示:
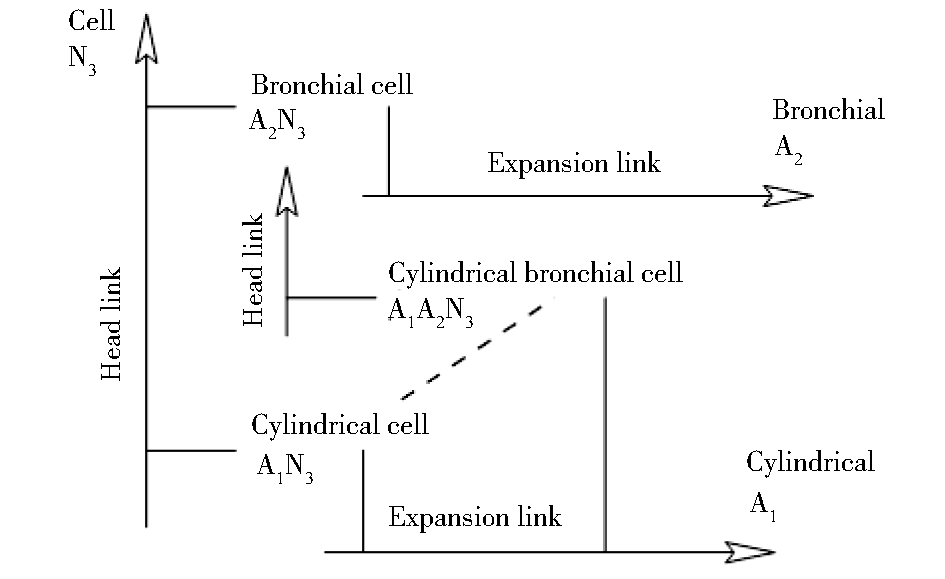 | 图1 候选术语网络片段[ 5] |
图1中,术语“Cylindrical bronchial cell”和“Cylindrical cell”之间并没有直接的联系,但是由于两者在关键词汇部分和“Bronchial cell”直接相关,在修饰词汇部分和“Cylindrical”直接相关,因此可以判断两者是具有相似性的。
如果一个术语是在其他术语的基础上通过增加修饰词汇产生,这意味着两个术语之间具有概念属种关系或功能关系。这种相似情况在Ogren等关于基因本体的研究成果中有较为深入的论述[ 6]。Nenadic等在此基础上提出了共用关键词汇的术语具有相似性的假设[ 4]。他们认为,共有相同关键词汇的术语可看作同一个术语的下位词(例如:progesterone receptor和oestrogen receptor都是receptors)。也就是说,当一个术语存在于另一个术语之中,则它们之间具有某种语义相似性。
除了根据关键词汇、修饰词汇部分的匹配情况来判断术语相似度,通过语词字符序列的对比来判断术语之间的相似度也是一种重要的基于语词特征的计算思路。Levenshtein提出了编辑距离(Edit Distance)相似度计算方法,通过衡量将一个字符序列转换为另一个字符序列时所需要的插入、删除和替换操作成本来计算相似度[ 7]。Kelil等针对编辑距离方法只能进行顺序匹配,以及插入、删除和替换操作的权重赋值受到主观影响等问题,提出了SCS相似度计算方法。该方法首先从字符序列中抽取有意义的模式集,通过过滤去除噪音模式,然后使用N-Gram方法将模式中原始字符序列映射到低维向量空间,运用向量之间的余弦内积计算获得字符序列之间的相似度[ 8]。
基于语词特征的相似度计算思路主要以语词构成的外在特征作为计算对象和依据,因此对于语义相似而构词特征不相似的术语对而言,计算就有可能失效。为了克服这种局限性,在术语语义相似度计算过程中还需要结合基于句法特征、基于语境特征或其他能够体现语义相似性的方法进行集成计算。
基于句法特征的术语相似度计算主要借助句法模板匹配来实现。由于句法模板能够暗示共同出现在其中的术语之间的相似关系,因此构造能够表达相似关系的句法模板,并对领域文集中术语共同出现的句法模板数量进行统计,就能够计算出术语之间的相似程度。Hearst等最早提出了这样的假设:特定句法模式可以传达术语之间的某种关联性。例如,类似“NP0 such as {NP1, NP2, …, (and | or)} NPn”这样的句法形式可能暗示出名词短语NP0和NPi之间具有上下位类关系。根据该假设,Hearst认为可以通过找到更多的句法模板,并识别这些句法模板所暗示的语义关联,来发现实体之间的特定语义关系[ 9]。Nenadic等在Hearst方法的基础上,进一步指出术语的句法相似性一般以三种形式表达[ 10],分别是:术语列举(Enumeration of Terms,例如:“steroid receptors, such as, estrogen receptor, gluco-corticoid receptor, and progesterone receptor”),术语协作(Term Coordination,例如:“adrenal glands and gonads”)和术语联合(Conjunction of Terms,例如:“estrogen receptor and pro-gesterone receptor”)。以上三种句法形式暗示这些术语之间存在语义相关关系。
由于相似术语并不总是出现在特定模板中,基于语词模板的术语相似度算法具有准确率较高、召回率较低的特点。此外,特定领域文集中模板实例的稀疏性问题,以及仅能捕获有限关系类型(例如:上下位类关系、同位类关系等)的特点,决定了基于句法模板的术语相似度算法并不适合在术语语义相似度计算过程中被独立使用。
术语的语境是术语出现在文本中的上下文环境。语境的单元划分有多种方案,可以将一篇完整的摘要或文档作为语境看待,当然也可以将一个语句或更小的语块(例如,一个动词补足短语)作为语境看待。Ding等基于术语共现测量方法,调查了语境单元大小对于语境计算的影响[ 11]。他们的评测结果表明,越大的语境单元划分能够产生越高的召回率,而越小的语境单元划分一般会具有更高的准确率。从整体效果而言,以语句为语境单元性能最好。事实上很多学者正是以术语出现的语句为语境单元计算术语语义相似度。
Neshati等提出了这样的假设:在相同句法角色中的语词,如果与相似名词或动词搭配,则这些语词之间很可能存在语义相似关系[ 12]。他们借助WordNet来发现相似动词。例如,在WordNet分类体系树中,“eat”和“drink”之间的连接距离很短,这表明它们之间具有相似性。从文集中又可以发现,名词“cake”和“coffee”与动词“eat”和“drink”经常在“object-verb”句法结构中共现,由此可以判断“cake”和“coffee”是相似的。类似的方法在Jing等进行基于知识的文本聚类任务时也被使用[ 13]。该方法使用背景知识来判断词语的语义相似度,能够比较有效地克服特定文集中术语实例稀缺性问题。
Nenadic等提出了通过语境模板(Context Pattern)来规范化表达术语出现语境的方法[ 4]。语境模板可以由词性标注、句法标签、本体或类的信息等有意义的语境元素构成。那些信息量少的语境组成部分(例如限定词、副词、连接短语,以及助动词)被丢弃掉,而具有较大信息量和具体内容的语境元素被归类或实例化,以增强它们建立关联的重要性。Nenadic等从术语出现语境中解析语境模板,并提出了对这些语境模板进行自动评价的方法。最后,以术语所关联的优质语境模板为变量,通过类骰子系数(Dice-like Coefficient)公式计算得到基于语境特征的术语语义相似度。
相关实验表明,基于特定领域文集的术语相似度计算方法能够取得较好的计算效果,但是仍然存在应用局限性。基于语词构成特征的术语相似度计算方法很难从语义层面对术语相似程度进行计算,而基于句法、语境特征的术语相似度计算方法在很大程度上依赖于特定领域文集的规模和质量。近年来,一些学者开始探索借助开放知识资源开展术语语义相似度计算的方法,能够较好地弥补基于领域文集进行相似度计算所存在的不足。
除了特定文集本身所携带的术语相似度特征,一些开放知识资源具有的丰富语义信息也能够作为判断术语语义相似度的依据。许多学者已经在基于WordNet、Wiki等开放知识资源进行术语语义相似度计算方面进行了有益尝试。此外,网络搜索引擎可以被看作一种特殊的知识资源,通过检索获得的命中数和摘要信息可以用来进行术语语义相似度计算。
在知识分类体系中,两个概念对应节点之间的距离反映了它们之间的语义关联程度。节点之间距离越近,则节点对应概念之间的相似程度越高。利用这一规律可以开展术语语义相似度计算。Rada等在解决检索式和文档匹配问题时,提出相似性测度可以通过分类体系或词表中语词对应节点之间的距离来确定[ 14]。两个语词对应节点之间的路径越短,它们越相似。如果有多条路径,则选择最短的路径作为计算依据。Jing等在文本聚类任务中,提出在使用WordNet等本体进行相似度计算时除了考虑概念节点之间的距离因素,还应考虑到节点所处的位置因素[ 13]。在概念节点之间距离不变的情况下,概念节点所处的位置越深,则概念之间的相似程度越高。Siemiński在进行网页链接文字相似度计算时,提出了借助WordNet识别待计算语词的共同概念下位词,然后通过计算共同概念下位词的信息内容(Information Content)来反映两词之间相似度的计算方法[ 15]。Rahurkar等在识别特定术语具体有几种意义的任务中,使用Wiki来计算术语之间的相似度[ 16]。他们认为,如果两个概念共享链接集合,那么这两个概念很有可能是相似的。
与在特定文集中术语共现能够反映术语间相似程度的原理类似,在Web庞大网页集合中的术语共现特征也能够直接作为衡量术语相似程度的指标。应用Web网页集合进行术语相似度计算的关键是如何获得术语在Web文集中单独出现的次数、共现的次数以及术语语境等信息,而商业搜索引擎为获取上述信息提供了捷径。借助搜索引擎进行术语相似度计算的方法主要以搜索引擎返回的检索结果命中数和检索结果摘要这两条线索展开。
Matsuo等在抽取Web社区信息任务中,利用搜索引擎返回的命中数指标来计算两个人名之间的相似性[ 17]。他们通过检索获得每个人名的命中记录条数以及两个人名联合检索(And检索)获得的命中记录条数,将这些数值代入Overlap Coefficient公式进行计算,得到人名之间的相似性度量。Chen等提出了使用Web搜索引擎返回的文本摘要来计算语词之间语义相似度的双重检查模型[ 18]。对于两个语词P和Q,从Web搜索引擎收集相关检索结果摘要,然后计算语词P在语词Q对应摘要中出现的次数以及语词Q在语词P对应摘要中出现的次数。这些值在合并后就能够反映出P和Q之间的相似性。
Bollegala等将搜索引擎命中数指标和术语在检索结果摘要中出现的模式指标进行综合,以获得更加准确的相似度计算结果[ 19]。在搜索引擎命中数方面,他们采取了4种流行的共现测度(Jaccard,Overlap,Dice及PMI)来计算术语语义相似度。在摘要方面,采用N-Gram方法抽取术语语境模板。上述两方面相似度指标通过SVM(Support Vector Machine)机器学习方法集成在一起,综合反映术语之间的相似程度。Iosif等总结了基于搜索引擎命中数、检索结果摘要以及检索结果全文的术语相似度计算方法,并通过实验证明,基于搜索引擎的非监督相似度算法在计算效果方面能够达到基于本体等人工生成资源的监督相似度算法计算水平[ 20]。
使用搜索引擎的检索命中数作为相似度测度具有简单、直接的优点,但是也存在以下两个方面的问题:
(1)网页数量分析忽略了术语在网页中出现的位置。即使两个术语出现在同一个网页中,它们也可能并不相似。
(2)多义术语的网页数量可能是术语各种意义对应页面数量的总和。例如,“apple”对应的检索结果命中数包含了那些将“apple”作为水果意义的网页数量和将“apple”作为公司名意义的网页数量。
以上两方面问题可能会影响到这类方法的实际计算效果。基于搜索引擎摘要的相似度算法效果也会受到搜索引擎的制约。由于Web规模巨大,搜索引擎命中结果集通常也很大,只有被搜索引擎排列在最前面的那些摘要能够得到有效处理,因此搜索引擎的排序策略对基于摘要的术语语义相似度计算具有一定影响。
基于单一特征的术语相似度计算往往具有较苛刻的条件限制。近年来,一些学者开始尝试将多种术语相似度计算指标进行综合,以得到能够较全面反映术语相似性的计算方法。在这方面具有代表性的研究思路主要有基于线性加权的指标集成方法,基于神经网络的指标集成方法,以及基于SVM的机器学习方法。
为了综合术语的语词相似度、句法相似度和语境相似度,Nenadic等使用了线性加权的多指标集成方法,计算思路如下[ 4]:
CLS(t1,t2)=αCS(t1,t2)+βLS(t1,t2)+γSS(t1,t2)
其中,t1, t2为需要进行相似度计算的术语对;CS(t1, t2)为术语t1和t2的语境相似度指标;LS(t1, t2)为语词相似度指标;SS(t1, t2)为句法相似度指标;CLS(t1, t2)为经过集成计算后得到的术语相似度值;参数α + β + γ = 1,它们分别是各项相似度指标的权重。Ittoo等采用了类似的线性加权方法来实现语境相似度和语义相似度的集成[ 21]。Dong等在使用本体进行术语相似度计算时,采用了基于概念描述的相似度算法和基于概念在本体中对应节点位置的相似度算法,并通过线性加权的方法集成这两种计算指标,得到最终的术语相似度判断结果[ 22]。
Neshati等认为,仅使用一种现有相似度计算方法很难实现准确的相似度计算,于是他们采用基于WordNet的相似度算法、基于窗口共现的相似度算法以及基于句法共现的相似度算法分别进行相似度计算,并使用神经网络算法来确定这些相似度指标的权重[ 12]。Neshati等首先将相似性测度表达为4维向量,然后使用一个旅游分类系统作为参照,通过基于路径长度的相似度算法计算分类系统中术语对之间的相似性,并将其作为神经网络模型学习各种相似性计算指标集成权重的依据。在测试阶段,每一对待计算术语被表示为相应的向量,使用神经网络学习阶段产生的权重进行集成,得到最终的相似度计算结果。
Bollegala等认为,术语相似度计算可以看作一个分类问题,而多种相似度计算指标的集成则可以通过基于SVM的机器学习方法来实现[ 19]。Bollegala等首先分别计算基于命中数的Jaccard、Overlap(Simpson)、Dice、PMI 4个相似度指标;使用N-Gram方法从检索结果摘要中截取术语出现模板,从中选择术语对共现频率最高的200个模板,加上上述4个基于命中数的指标,构成描述术语对的204维向量,并将其作为SVM分类器的输入,最终通过自动分类得到术语之间相似性的判断结果。这种集成方法避免了使用线性加权方法集成相似度指标时权重设置易受主观因素影响的问题,能够获得较好的集成效果。
对术语语义相似度计算方法的研究,是开展多种自然语言处理任务和知识挖掘任务的前提和基础。
在自然语言处理方面,术语语义相似度计算方法可以用于进行文档内部和文档之间的术语合并和规范化。例如,对于同一概念的不同表达方式而言,有些并不符合构词法规则,可以通过语境分析、句法分析等方法判断其相似性,并进行合并,达到术语规范化的目的。此外,一些学者通过术语的语义相似度计算来发现同义、近义词关系,并基于这些相似关系进行聚类或其他处理任务。例如,Turney等基于Web搜索引擎返回的检索命中数,提出了PMI-IR方法来识别同义词[ 23]。Chen等使用Google Distance相似度算法自动生成检索词集合[ 24]。
在知识挖掘方面,术语语义相似度计算过程中抽取得到的内容模板可被应用于各种信息抽取任务中。例如,模板“V:inhibit TERM1 PREP:of TERM2”能够用来抽取特定生物过程抑制信息[ 25]。也可以通过术语相似度计算过程中自动产生的模板来抽取特定关系,例如层级关系、同级关系、因果关系等。通过术语之间的语义相似度计算,还可以发现新的关系、类、实例,并以此为基础自动或半自动地对本体及知识库进行更新[ 12]。此外,术语语义相似度计算还为术语/文档分类[ 26, 27]、术语/文档聚类[ 28, 29]、自动问答[ 30]、Web Service相似度计算[ 31]等任务的开展提供有力支持。
本文对当前术语语义相似度计算领域的主要计算思路进行了梳理,对重要相关研究文献进行了综述,并总结了术语语义相似度计算在自然语言处理和知识挖掘领域的具体应用。随着该领域研究的不断发展,能够体现术语相似度的指标被逐渐挖掘和探索,各种指标的集成效率得到不断提高。术语语义相似度计算的性能提升也势必会为其在各种相关任务中的应用提供推动力。
目前,术语语义相似度计算仍存在一些问题,阻碍着大规模高效应用的开展,相似度计算的准确率也有较大的提升空间。笔者认为,术语语义相似度计算的研究正在向着多指标集成、高速计算方向发展。当前重点应解决的主要矛盾是如何高效地集成多种相似度指标,以及如何解决术语相似度海量计算处理的高效率与高准确率之间的矛盾。在下一步的研究工作中,提出在计算准确率和大规模处理效率方面均有所突破的术语语义相似度计算方法,为各种自然语言处理任务和知识挖掘任务的开展提供良好支持。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|