


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
超大型中文叙词表本体的检索与推理研究
[曾新红1, 2  , 黄华军
, 黄华军2 , 林伟明1 ]
, 黄华军|
|


研究超大型中文叙词表本体检索和推理的网络化实现方法,运用其成功实现“中国分类主题词表本体”(CCT1_OntoThesaurus)的共建共享系统(CCT1_OTCSS),且时效性已达到实用要求。提出基于RDF三元组思想的Lucene索引结构构造方法, 以CCT1_OntoThesaurus (基于CCT一版的纯文本电子版建立)为例,构建Lucene索引,在此基础上实现高效的本体检索和一致性检测推理,并进一步实现CCT1_OTCSS的各项功能。该解决方案对于我国现有的几部应用最为广泛的超大型中文叙词表快速实现本体化升级、网络化共建共享和动态完善具有良好的应用前景,对于国内外其他采用XML、RDF或OWL表示的大型知识组织系统(叙词表、本体等)实现网络化检索与推理也具有参考价值。
This paper makes a research on the implementation of network-based retrieval and reasoning about Ultra-Large-Scale OntoThesaurus, and the proposed solution has successfully applied to the realization of the CCT1_OTCSS, which is a co-construction and sharing system of an Ultra-Large-Scale Ontology named CCT1_OntoThesaurus. This paper proposes the structure of Lucene index based on the idea of triple “subject, predicate, object” of the RDF, and validates the feasibility of implementing efficient retrieval, terminology services and reasoning based on the Lucene index of Ultra-Large-Scale OntoThesaurus. The solution can be reused for several Ultra-Large-Scale Chinese thesauri most widely used in China at present, implementing quickly Ontology-oriented upgrading, networked co-construction, sharing and dynamic updating for them, and also has a reference value for other large-scale knowledge organization systems (thesauri, Ontology, etc.) in the form of XML, RDF or OWL at home and abroad.
中文叙词表本体共建共享系统(OntoThesaurus Co-construction and Sharing System,OTCSS)[ 1]是国家社会科学基金项目(项目编号:05CTQ001)的研究成果,原采用Jena[ 2](惠普公司的一个针对语义网应用的Java开源工具包)和SPARQL[ 3](W3C推荐的RDF标准本体查询语言)实现网络化检索和推理,可以有效解决目前国内已有的一般大型及以下规模(即130余部中的120余部)中文叙词表转换成本体后的检索和推理问题,其时效性已达到实用要求[ 1, 4, 5, 6]。
但对于少数几部超大型中文叙词表(5万叙词款目以上),原来采用的技术还远不能使其时效性达到通过网络实时使用的要求,需要寻求一种低投入、高效率的解决方案来解决这些OWL大型本体文件(60MB以上)的检索与推理问题,使我国现有的几部应用最为广泛的超大型中文叙词表可以快速地实现本体化升级、网络化共建共享和动态完善。
近年来,国内已有许多针对XML文档的搜索及索引的研究[ 7, 8, 9, 10, 11],但其查询速度慢且又不适合大数据量的要求。
HP公司的Jena开发包可以实现对中小型和一般大型中文叙词表本体的检索与推理,但缺乏对超大型本体动态完善的支持。根据实验结果发现[ 5, 6, 12, 13]:在推理要求不高且数据量不大的情况下,Jena就是一个不错的选择,但是对于超大型的本体,Jena的支持还远远不够。
美国斯坦福大学的Protégé-OWL在做本体推理时一般使用Jena或Jess来实现。Jess作为前向推理系统,推理时用空间换时间,会产生大量的中间数据,空间效率很低,同时由于Jess是通用推理引擎,不可能提供针对各种具体领域的效率优化能力[ 13]。Racer、FaCT、Pellet等推理机和Jena一样,是针对具体本体语言的推理机,针对性较强,效率相对较高,但是都没有解决超大型本体检索与推理的案例。通过相关调查,也没有找到进一步实现美国国家癌症研究所(NCI)2003年发布的叙词表OWL版本的检索和推理问题的信息。
Oracle和SQL Server数据库都提供了高性能的XML 存储和检索,并提供管理 XML数据的基础架构,也可以满足大数据量的要求,但它们并非开源软件,使用成本较高,且不支持本体推理,因此未成为本文的选择方案。
鉴于当前开源的全文检索引擎Lucene[ 14]在实现检索方面的出色表现,虽然尚未发现使用Lucene来解决OWL本体大文件推理问题的相关研究和报道,课题组仍决定采用Lucene来解决这一难题。通过对Lucene全文检索引擎的深入研究,以及对现有的中文叙词表OWL本体大文件构建索引、定制查询与推理进行的初步实验,发现其在时间效率方面与已有的方法相比有很大的提高,而且能够满足大数据量的要求,因此,最终Lucene成为本文的选择方案。
本体的检索建立在它的存储机制上,目前RDF本体存储机制主要有数据库、内存、磁盘等载体。通过相关研究与实验可知,这三种存储方式具有以下特点:
(1)采用关系数据库来存储本体三元组数据源是一种比较常见的存储方式。优点是数据库管理系统提供了标准的查询接口,使用方便,但存在高成本和对本体推理支持不足的问题。文献[15]具体描述了目前使用数据库存储本体三元组的几种可能的形式,分别是:水平数据库,模型简单,但浪费存储空间,使数据库成为一张稀疏表;垂直数据库,由Jena等众多RDF引擎采用,缺点是每一次检索都需要遍历整个表,处理联合查询时,查询引擎很难获得高效率;按属性来建表的存储方式,造成表多而不易维护,且查询效率不高。
(2)基于内存的RDF存储与数据库相比,安装和配置较为简单,而且在内存中,处理OntoThesaurus三元组的插入、查询和推理操作的速度很快。但该机制的缺点也很明显,由于内存容量的限制,只适合小规模的数据量,而且存储是非持久性的[ 15],内存还需处理很多其他的进程,易造成工作效率低下等。
(3)如果将OntoThesaurus的信息以OWL文件的形式直接存储在磁盘里,这样虽然可以存储海量数据,但是对查询引擎提出了很高的要求,需要具备解析和处理OWL大文件的能力,与其他方式相比,既缺乏查询支持,又不具备效率的优势[ 15]。
因此,考虑到既要存储大量数据,又要实现高效查询,本文选择为超大型OntoThesaurus建立存储在磁盘的Lucene倒排索引来实现本体检索与推理。
本文提出了基于RDF三元组思想的Lucene索引存储结构。
简单而言,需要索引的信息来自一个RDF/XML本体文件的ABOX部分,它包含多个资源描述,而一个资源描述是由多个语句(声明)构成,每一个语句是由资源(主体)、属性(谓词)、属性值(客体)构成的三元组,即表示资源具有的一个属性。
Lucene的数据结构是虚拟文档,即Document,OWL本体大文件是Lucene需要索引的数据源。RDF的三元组思想为将这些数据源定制成Lucene的虚拟文档Document提供了参考,即本体文件中的一个三元组对应Lucene的一个虚拟文档Document,然后将所有的虚拟文档交给Lucene做索引,通过倒排索引的形式存储在磁盘。
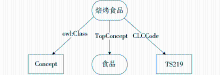
中文叙词表本体OWL文件是RDF/XML格式的文件,其ABOX部分由许多个XML节点组成,其中每个节点表示一个完整的中文叙词款目。也就是说,一个概念(叙词)表示一个资源,它由多个语句组成。例如,从CCT1_OntoThesaurus文件中抽取出来的一个叙词概念“焙烤食品”由两个语句表示:概念的中图法分类号是“TS219”,它的族首词是“食品”,如图1所示:
 | 图1 OWL本体大文件中的一个完整叙词款目 |
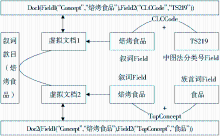
从这些信息可以知道,叙词“焙烤食品”有两个属性,一个为CLCCode,另一个为TopConcept,其值分别为“TS219”和“食品”,用RDF三元组的有向图来表示,如图2所示:
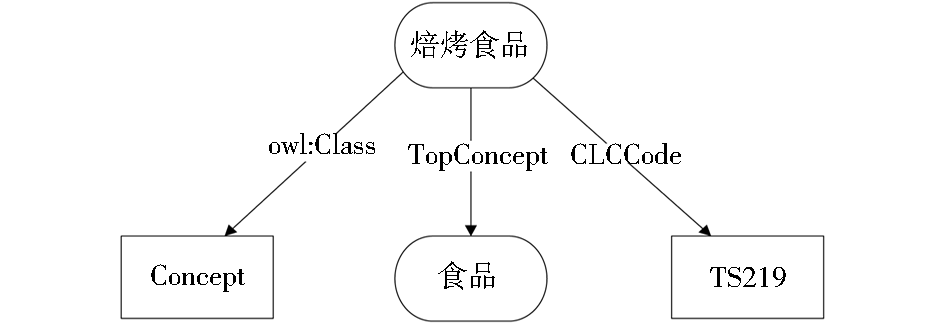 | 图2 RDF三元组有向图表示的叙词款目信息 |
根据RDF三元组的有向图,该叙词的相关信息在做索引的时候,可以构建两个Lucene虚拟文档,其表示方法如图3所示:
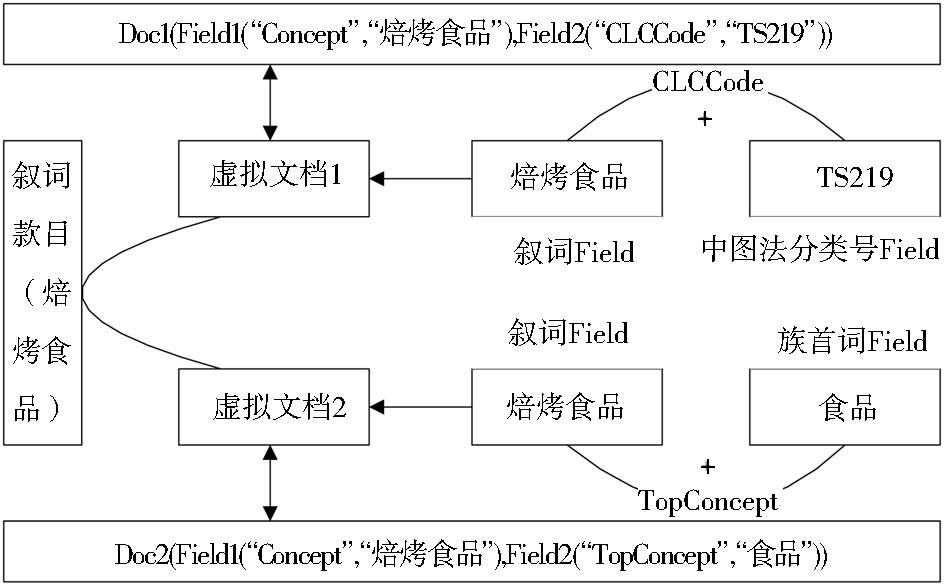 | 图3 Lucene虚拟文档表示的叙词款目信息 |
叙词的每个Lucene虚拟文档都包含两个数据字段(Field),即代表一个三元组,其中概念名称如“焙烤食品”为主体,属性名称如CLCCode或TopConcept为谓词,属性值如“TS219”或“食品”为客体。该叙词款目的存储结构设计成以RDF三元组思想为基础的Lucene虚拟文档后,生成Lucene索引的过程如图4所示:
 | 图4 OntoThesaurus的Lucene索引过程 |
OntoThesaurus的查询机制与它的语法和存储关系密切。在OTCSS中可以使用Lucene来定制各种查询,如构造基于定义域和属性域的词条查询和三元组的查询、布尔或、布尔与和布尔否查询等各种组合查询。倒排索引赋予Lucene高效的检索速度,功能强大且使用方便,这样OntoThesaurus的检索问题将迎刃而解。本文对现有的中文叙词表本体大文件进行了实验,用Lucene做索引后构造各种查询,其检索时间都保持在几百毫秒之内。
将OntoThesaurus以RDF三元组的逻辑结构构造成Lucene虚拟文档后,中文叙词表本体转换成索引数据,它可以看作是若干个Lucene虚拟文档Document,即三元组构成的一个集合,根据RDF(S)推理规则,OntoThesaurus的推理可以在已有的三元组上推出新的三元组,也可以在已有的三元组上推出某些矛盾的三元组,甚至在已有的三元组上推出多余的三元组等信息。
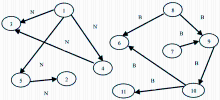
OntoThesaurus中的每一个三元组由两个节点和连接两个节点的有向边组成,边的起始点为OntoThesaurus中的概念实例,边的终节点为该概念实例的某个属性值,有向边由该属性标记。因此OntoThesaurus为一个大型的三元组有向图,它由若干个推理子图组成,如图5所示。设节点为OntoThesaurus的叙词(C),边为OntoThesaurus的谓词(Narrower),可以从三元组T(1, N, 4)、T(4, N, 3)和T(1, N, 3)以及T(8, B, 9)、T(9, B, 10)、T(10, B, 6)和T(8, B, 6)推出下位词传递关系T(1, N, 3)和上位词传递关系T(8, B, 6)越界。
 | 图5 OntoThesaurus中的推理有向图 |
OntoThesaurus的推理在相应的每个推理子图中进行,这样可以节省大量的时间开销,避免每次推理都在整个OntoThesaurus中进行。对于每个推理图G = (C, {T}),其中每条有向边对应一个三元组t(S, P, O)∈T,推理图中的三元组为推理条件,对于每种推理结果,推理后对推理图进行更新,因此更新后的图还是一个推理图。
根据构造的Lucene索引及其逻辑结构,可以分析Lucene版的本体推理机在时间和空间上的复杂度,确定该本体推理机是否能够解决网络化的在线推理难题。设超大型的OntoThesaurus的三元组个数为n(n = np + nc + nh + nt + nn + nb + nr,下标为OntoThesaurus中相应属性名称的首字母[ 1]),OntoThesaurus中关系属性种类数目为p,结合文献[6]的中文叙词表本体定义的一致性检测机制,构造了相应的推理算法来实现,并且估算出其中一些推理的复杂度,如表1所示:
| 表1 Lucene版本体推理机部分推理复杂度分析表 |
从表1可以看出,Lucene版的本体推理机的在时间复杂度上基本上都是线性的。由于目前一般的服务器内存空间都足够大,所以借助Lucene这个高效的检索引擎,实现OntoThesaurus的网络化在线推理完全是可行的。
OntoThesaurus的检索实现是建立在05CTQ001项目的成果OTCSS基础之上的,功能和界面基本不变,详见文献[5]。将超大型本体的检索转化成为对超大型本体的索引文件的检索,对于精确检索、前方一致检索以及任意一致检索,一般通过不同的查询子类(Query)辅以通配符来实现。
下面主要介绍通过主题词(入口词)途径进行任意一致检索的解决思路,其他途径的检索实现可以参照此解决方案。使用Lucene实现任意一致检索的步骤如下:
(1)初始化存放Lucene索引文件目录的路径;
(2)定义指向Lucene索引文件目录的搜索器;
(3)构建与任意一致检索相关的查询,此时使用通配符搜索(WildcardQuery),如果为精确搜索则使用TermQuery,前方一致搜索使用PrefixQuery;
(4)定义存放检索结果的Hits类;
(5)执行相应的查询;
(6)将查询结果进行归并,即调整成若干个完整叙词款目的形式;
(7)对叙词款目按拼音(Lucene默认为按相关度排序)进行排序后输出;
(8)计算本次检索所花费的时间。
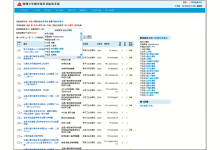
需要注意的是,从构建Lucene虚拟文档的方法来看,如果检索条件是英译名、中图法分类号,则需要通过两次检索才能搜索出用户所想要的检索结果。搜索效果如图6所示:
 | 图6 以“中国”作为关键字的Lucene搜索效果[ 16] |
OntoThesaurus在语义Web界、图书馆界都有着很强的应用背景。本文提供的超大型OntoThesaurus的网络术语服务包括供人使用的OntoThesaurus-TS和供应用程序使用的Web Service API,其中OntoThesaurus-API目前可提供18个服务函数。功能和界面与原OTCSS系统[ 5]保持一致,但实现方法有所改变,保证了服务的时效性。
网络用户利用OntoThesaurus-TS[ 16]的服务,可以检索和获取所需的概念术语及其相关信息(分类号、英译名、同义词、上/下位词或其指定子关系词、相关词或其指定子关系词等),应用于OPAC检索、搜索引擎、数据库检索等应用程序,进行扩展查询、分类标引、翻译等工作。在此过程中,还可以随时提交对现有词表的修订意见。
OntoThesaurus-API[ 17]可以帮助应用程序突破机械式字面(关键字)匹配局限于表面形式的缺陷,从词所表达的概念意义层次上来认识和处理用户的检索请求[ 18],即实现概念检索(或智能检索)。例如,在深圳大学图书馆的OPAC检索系统中,可以通过调用OntoThesaurus-API,实现各种概念检索。以检索“电脑”为例,将此入口词转换为正式主题词“电子计算机”,实现规范化检索,效果如图7所示:
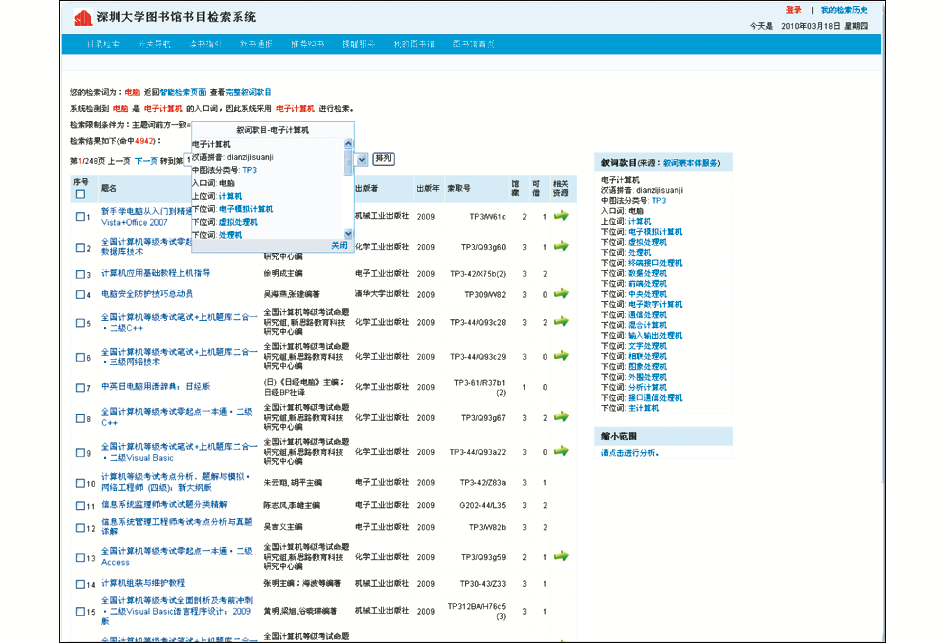 | 图7 以“电脑”作为关键字的智能搜索效果 |
OntoThesaurus-API还可以广泛应用于其他应用程序中。例如:在众多支持Tag的应用程序中,可以使用OntoThesaurus-API为用户输入的标签进行规范化的提示,使用户输入的标签更为规范化;在面向主题词的数据挖掘中,运用OntoThesaurus-API可以基于主题词及其款目信息对数据进行挖掘、统计;在机器学习中,OntoThesaurus-API可以提供同义词辨析机制和主题词分析机制,进行与主题词相关的信息抽取等。
上述所有的应用都可以通过Web Service调用的标准方法,在不同的应用平台上进行实现[ 19]。
超大型OntoThesaurus的推理主要运用于一致性检测机制的实现,OTCSS系统的知识采集、词表管理以及全局检查功能中都用到了一致性检测机制,以保证OntoThesaurus在整个生命周期中的正常运行。
文献[6]结合中文叙词表和本体的特点、编制规范和描述逻辑,建立了OntoThesaurus的一致性检测机制,即10条自定义规则。该文中采用的Jena/SPARQL推理方案可以满足一般大型OntoThesaurus(约2万叙词款目以上)的实时推理要求,但无法满足超大型OntoThesaurus的推理时效性要求。
本文采用Lucene和Jena对OntoThesaurus进行基于自定义规则的推理,可检测出值域不一致、入口词多次出现、非法自反关系、非法对称关系、未成对指引关系、二元关系冲突和传递关系越级等矛盾问题,以及拼音缺失和叙词未定义等信息缺失问题,并可自动生成族关系。在全局检查阶段,这些问题可以通过网络界面呈现在修订专家面前,根据推理结果的问题信息提示,修订专家可进行相应的处理,达到不断完善的目的。
在知识采集和词表管理的各个阶段,根据需要不同程度地应用了一致性检测机制。知识采集的过程包括两个部分:知识发送和知识提取,它是OntoThesaurus进行充实和完善的有效途径。普通网络用户、领域专家和标引员可以发送修订意见给修订专家参考,其发送信息包括:为原叙词增加入口词(同义词)、新增补叙词(正式主题词/概念)、修改原叙词款目信息、原叙词款目整条删除,以及新增相关关系子关系种类等。修订专家通过提取统计后的修订信息进行处理,决定修订意见的去留。词表管理是供修订专家使用的网络维护界面,对完善OntoThesaurus起着非常重要的作用。它通过维护Lucene索引来实现,主要包括以下三个部分:新增叙词、修改叙词和删除叙词。
OTCSS的知识采集和词表管理都是为应对OntoThesaurus的动态发展而制定的一套维护机制。知识采集中新增补叙词款目、修改原叙词款目信息和原叙词款目整条删除的处理方式,分别与词表管理的新增叙词、修改叙词和删除叙词一致;为原叙词增加入口词(同义词)需要检验在OntoThesaurus中新增的该入口词是否作为概念的实例以及概念的实例的入口词存在,如果合法就只需向索引文件中加入一个三元组虚拟文档即可;新增相关关系的子关系种类则需要通过Jena修改OWL本体文件的TBOX部分,向其中添加该关系种类的基本信息。因此,OTCSS应具备完善的推理能力,以保证在更新的过程中不至于破坏OntoThesaurus的一致性而引起矛盾,其具体的检测效果详见文献[16]。
根据OntoThesaurus一致性检测问题的形式化描述[ 6],构造了相应的推理算法来判定这些一致性检测问题。以“传递关系越级”为例,算法如下:
(1)用Jena API解析OntoThesaurus的TBOX(OWL文件),从中搜索出Narrower、Broader关系以及它们的扩展子关系集合R;
(2)定义存储传递关系越级矛盾信息的空集合ErrorMsg;
(3) 依次取出集合R中的任意元素r,从OntoThesaurus中以r域搜索出r关系中的所有三元组,其中c1和c2分别为三元组的主体和客体,即∀r(r∈R∧
(4) 集合R中的所有元素都处理完毕,则转步骤(5),否则转步骤(3);
(5)若ErrorMsg不为空,输出OntoThesaurus中所有传递关系越级的矛盾信息,即print(ErrorMsg),否则提示OntoThesaurus中不存在传递关系越级的矛盾信息。
用Java编程实现了这些算法。本方案与原方案均采用Java语言进行实现,且没有改变系统的架构,不同之处在于原方案对于本体模型的读取、检索、推理和写入都采用Jena提供的API实现,而本方案则基于Lucene提供的API对这些功能进行实现。
为了进一步证明基于Lucene的解决方案对实现超大型中文叙词表本体检索的可行性,通过大量实验统计得出叙词数量(本体大小或三元组个数)与检索时间的关系,如表2所示:
| 表2 叙词数量与检索时间关系表 |
表2的数据表明,使用Lucene实现60MB以下数据量的检索所用时间基本都在毫秒数量级。本文所采用的实例是基于《中国分类主题词表》一版完整数据建立的CCT1_OntoThesaurus,叙词数量约20万(包括主题词串),三元组约60万,本体大小约60MB,使用本文的解决方案完全可行。
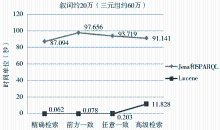
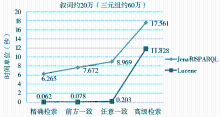
在同样的条件下,采用原Jena/SPARQL推理方案实现该超大型本体的检索效果很不理想。图8为本文Lucene方案与原Jena/SPARQL方案进行对比的效果图,图9为本文Lucene方案与改进后的Jena/SPARQL方案进行对比的效果图,可以看出,Jena/SPARQL方案无法满足超大型OntoThesaurus的检索需求,Lucene方案则在时间上具备明显的优势。
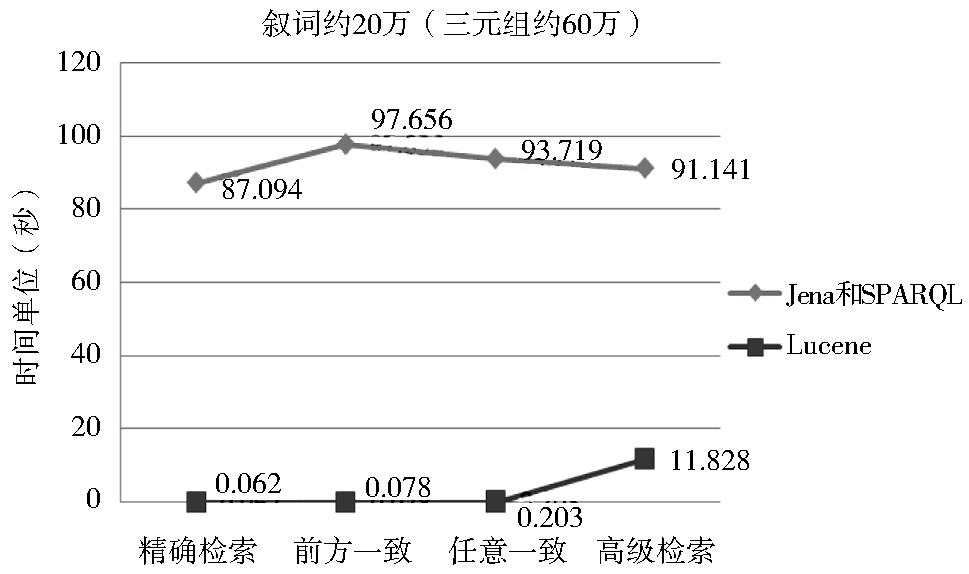 | 图8 Lucene方案和原Jena/SPARQL方案的检索效果对比 |
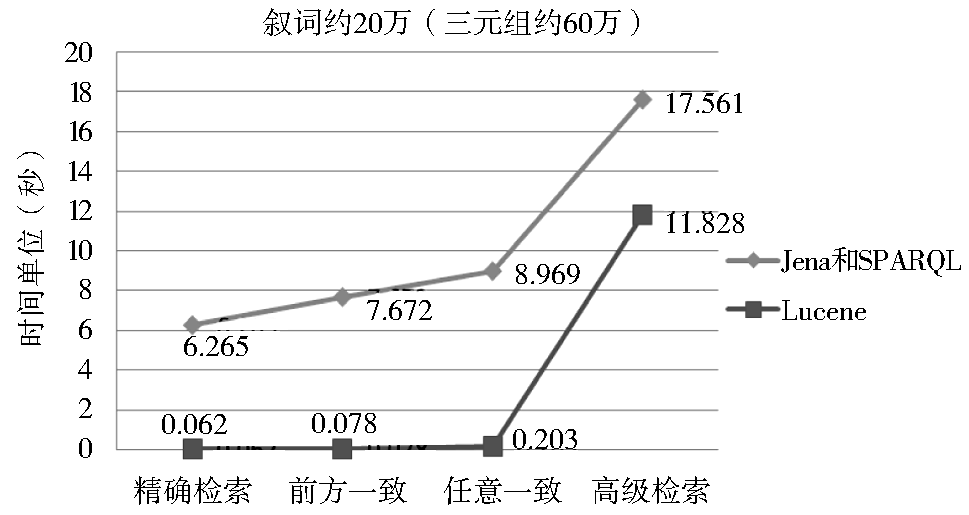 | 图9 Lucene方案和改进后Jena/SPARQL方案的检索效果对比 |
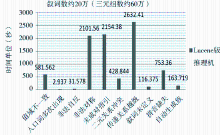
Lucene强大的检索能力为实现超大型中文叙词表本体的推理奠定了坚实的基础。图10是使用Lucene方案实现超大型OntoThesaurus全局推理的时间效果图,图11是全局推理中的“值域不一致”检测运行结果图,而采用原Jena/SPARQL方案解决该超大型OntoThesaurus的全局推理,其所耗时间在实际应用中是无法容忍的。
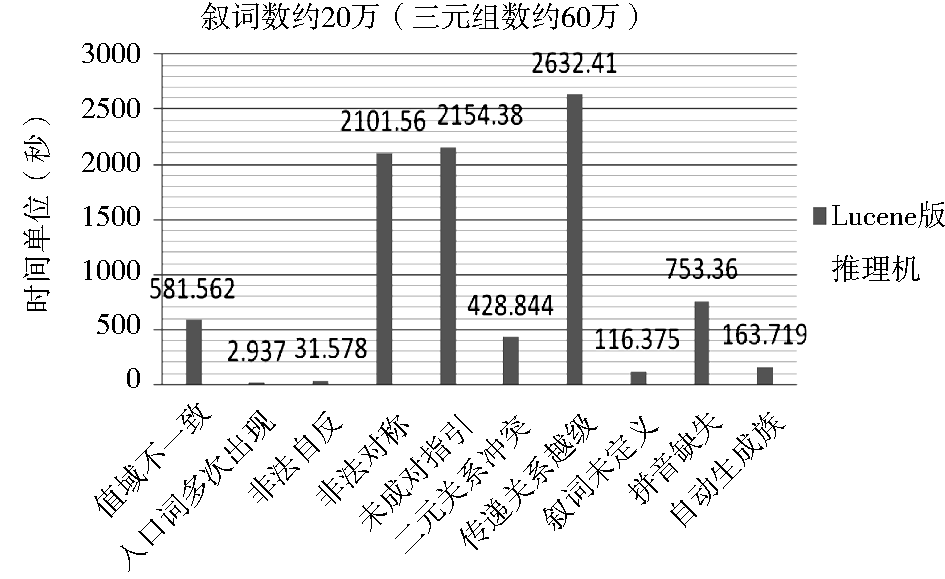 | 图10 Lucene版推理机的效果图 |
 | 图11 Lucene版推理机“值域不一致”检测运行结果 |
实验结果显示,Lucene版的推理机对于实现超大型中文叙词表本体的网络化全局推理是基本可行的。对于少数时间复杂度较高的推理,通过网络提交推理结果还不是很理想,需要进一步改进,如改为分阶段提交推理结果或非网络方式运行。
本文提出了基于Lucene的超大型中文叙词表本体检索和推理方案,成功实现了CCT1_OntoThesaurus的共建共享系统CCT1_OTCSS,其各项功能已基本达到了实用要求。该解决方案对于我国现有的超大型中文叙词表快速实现本体化升级、共建共享和动态完善具有良好的应用前景。
基于RDF三元组思想设计的Lucene索引存储结构,具备扩展性和通用性,对于其他采用XML/RDF/OWL表示的大型或超大型知识组织系统(叙词表、本体等),本文的解决方案也具有参考价值。
笔者拟进一步为本解决方案提供支持SPARQL本体检索语言的API,使其具有更广泛的通用性。
文献[16]和[17]列出了CCT1_OTCSS的登录地址,欢迎使用、测试和批评指正。更多信息和研究进展将在NKOS研究网站(http://nkos.lib.szu.edu.cn)上发布,敬请关注。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|