{kind=link}
{kind=link}
基于术语定义的科技知识组织系统自动丰富关键技术研究
[张运良 , 梁健, 朱礼军, 乔晓东]
, 梁健, 朱礼军, 乔晓东]
, 梁健, 朱礼军, 乔晓东]
|
|


为解决知识组织系统手工为主构建过程中存在的专业人员不足、构建工作繁琐、一致性不易保证等问题,提出基于科技术语定义的知识组织系统自动丰富,并对定义抽取、定义解析、定义知识转换等关键技术进行初步探索。通过研究,发现基于术语定义的科技知识组织系统自动丰富具有一定的应用价值,相关关键技术将为进一步加快和扩大科技领域知识组织系统建设及更新提供技术支撑。
To cope with the problems in mainly manual construction of Knowledge Organization Systems(KOS), such as shortage of professionals, tedious work and difficulty to guarantee consistency etc., automatic enrichment of KOS based on scientific and technical definitions is proposed. In this paper, key techniques of definition extraction, definition resolution and definition-knowledge conversion are studied. It is proved that the relative studies have a great value that they can support and affect the construction and updating of scientific and technical KOS in the future.
长期以来,知识组织系统的建设主要依赖知识工程师和相关专家的手工劳动。手工构建存在专业人员不足、构建工作繁琐、一致性不易保证等问题。受限于经费和人力资源,很多国内知识组织系统的更新维护工作陷于停滞状态,即使少量有更新的,其更新周期也较长[ 1]。因此,对自动/半自动的知识组织系统构建的需求越来越急迫。实用的工程化的知识组织系统构建工具或者将处理对象限定在一个比较狭小的范围,或者处理一些较为特殊的资源。本文从特殊的科技文献定义资源出发,目的是对已有知识组织系统进行一定程度的自动丰富。自动丰富系统不是给出知识组织系统所需的全部知识,而是希望能给出构建所需的主要部分,因此其用途主要是在构建早期形成一个初步的知识组织系统框架,或是根据最新的资源对知识组织系统查缺补漏,进行完善。由于定义是对科技术语的最直接、最重要的描述,所以选择定义作为知识组织系统自动丰富的来源既能够获取较为重要的信息,又避免了对科技文献中复杂的图表公式及一般文本的处理。
本文重点研究科技术语定义在知识组织自动丰富中的关键技术,即把定义从海量文献中抽取出来的技术,对定义进行解析加工的技术,将解析结果转化成知识组织系统所需要的知识的技术,从而实现自动丰富的目的。
定义获取的主要来源是词典、百科全书等工具书,也包括期刊文献和互联网文献。词汇的定义形式多样,常见的有内涵定义、外延定义(包括列举定义)、情景定义、理论定义、实物定义、本义狭义定义、递归定义、约定定义、劝导性定义等。本文主要考虑内涵定义和外延定义。
术语定义的自动提取属于信息和知识抽取领域,由于给术语下定义的语句在结构上具有显著的语言学特征,因此,一类研究完全从语言规则出发,根据定义语句的结构特点构建特定的模式,通过模式匹配自动提取定义语句;另一类研究是结合统计方法,将定义语句的识别转换为特征分类问题。张艳等较早开始在定义语句自动提取方面进行研究,通过词法、句法分析工具分析定义语句成分,根据句型特点总结出语法模板,在大百科全书中的电子学和计算机领域进行了实验性探索[ 2]。由于这种方法需要多种语言处理工具和语义词典等资源的支持,实现过程比较复杂,很难进行大规模的实际应用。许勇等简化了定义语句的模式,设计了一套基于互联网网页数据的术语定义获取系统,该系统的测试结果平均准确率达到80%以上[ 3]。张榕等进一步简化了定义语句的匹配规则,使用简单规则进行粗匹配得到定义语句,同时引入统计方法,通过计算定义隶属度和向量空间模型对匹配结果进行优化。该系统对100个术语定义进行测试,结果准确率为84%[ 4]。大部分关于术语定义提取研究都集中于定义语句模板的提取和流程算法的设计,王强军等从资源建设角度出发,提出构建面向术语定义识别的标注语料库,为术语提取和释义识别提供资源基础和工具软件[ 5]。荀恩东等通过对标准术语库和一般语料库进行比照研究,选取术语定义语句的词汇、术语内部词汇以及术语外部邻接词汇作为统计特征,提出以术语定义模式为基础,同时结合术语出现的上下文统计特征,使用SVM分类器识别科技语料中的术语及其定义[ 6]。在应用方面,清华同方知网CNKI已经推出了针对学术术语的定义检索服务(http://define.cnki.net/science)。
自动丰富的研究和利用已有近40年的历史,最早可以追溯到1971年Salton在信息检索中的检索词扩展[ 7]。目前知识组织系统自动丰富主要有三种思路:
(1)利用大规模语料库进行统计分析来发现术语之间的相关性和相似性[ 8, 9, 10, 11, 12, 13, 14];
(2)利用不同知识组织体系之间的映射转换,从已有的知识组织系统丰富当前知识组织系统[ 15, 16, 17, 18, 19, 20, 21];
(3)利用相对精准、但是规模较小的资源对知识组织系统进行自动丰富[ 22, 23, 24]。
利用大规模语料库进行统计分析可以基于简单的共现分析和衍生分析方法[ 8, 10, 11, 13],也可以基于一定的词法和句法分析[ 9]。基于小规模资源则一般不采取统计方法,而是利用一定的匹配规则和算法进行匹配,通常窗口的选择和变化[ 22, 24]以及字符串匹配方法[ 21]的计算非常重要。规则可以基于词法分析,如词性标注;可以基于句法分析[ 25],如GLR、Chart、PCFG;可以基于一定程度的语义分析[ 20],如格框架等。无论是何种自动丰富,目前丰富的主体还是关系,而且主要是等同、层级、相关等粗粒度关系。本文采用第三种思路,但是不仅仅要丰富等同、层级、相关等关系扩展细化后的关系知识,还要丰富属性知识,这是一个新的尝试。对于自动丰富来说,自然语言处理技术比较复杂。本文则是从自然语言限定到科技语言,又从科技语言限定到科技定义语言。相对来说,科技词汇定义的表达方式较为固定,对其进行自然语言处理的分析和进一步解析的可实现性较好。因此虽然要求较高,但具有实施上的可行性。从科技文献中的定义出发,与利用词典释义有类似之处,时效性较好,但是相对来说,严谨程度和体系性要差些。
科技术语定义自动解析是一项新颖的研究课题,国内外仅有少量的相关研究。上述的一些定义结构分析、模板设计和提取实验研究,虽然重点在于提取,但是结构和模板可以为定义解析提供参考。国内外缺乏对术语定义解析方面的研究,一些术语系统,如Ontario Terminology(http://www.onterm.gov.on.ca/default_e.asp),主要提供服务于多语言术语选择的术语的对齐,也没有做到对定义的自动解析。
内涵定义就是把某一个概念放在另一个更广泛的概念里。一个定义可以分为被定义项和定义项两部分,被定义项就是被定义的概念;定义项就是定义的描述,它一般又可分为属概念和种差两部分,如下所示:
被定义项=定义项
(被定义的概念) 属概念 + 种差
其中,种差是使被定义概念与属概念区别开来的属性[ 26]。例如“非转向桥是指不承担转向任务的车桥”,被定义概念是“非转向桥”,属概念是“车桥”,种差是“不承担转向任务”。
通过对前人工作的总结,同时对大量科技期刊中术语定义语句进行考察,归纳出以下定义语句的模式:
(1)Term“指”|“是指”|“指的是”
(2)Term“定义”|“定义为”
(3)Term“称”|“称之为”|“又称”|“称为”|“称作”
(4)“所谓”Term…“是”| “即”
(5)Term“是一种”|“是…的一种”
(6)Term“即”|“即为”|“即是”|“就是”
(7)Term“包括”|“包含”
(8)Term“:”|“——”
外延定义即概念对应的全部实例,通常与内涵定义联合出现,如“气缸组件指组成气缸的各个部件,包括缸筒、端盖、活塞、活塞杆和密封件等”。前半段是内涵定义,后半段是外延定义。除了基本的内涵和外延定义语句之外,还有一些定义包含组成介绍和基本的评价等方面的内容,如“电力液压助力转向装置也是一种助力转向装置,它是电动机电力助力转向装置和齿轮齿条式液压助力转向装置的组合,也是如今市面上最好的转向助力装置”。
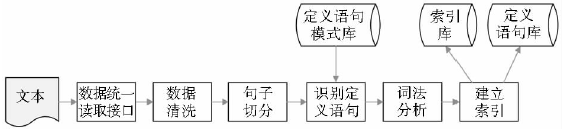
定义自动抽取系统的功能是通过构建定义语句的特征模式,自动提取符合模式的定义语句,同时出于检索效率的考虑,对定义语句进行分词处理,建立全文索引,系统流程如图1所示:
 | 图1 定义语句抽取系统流程图 |
(1)数据来源是文本,即不包括图片、表格、公式等复杂结构。具体来源包括科技期刊、百科全书、电子文档、网页等,内容主要为科学技术类。
(2)来源文本进入数据统一读取接口。由于数据来源的多样性,系统设计了数据统一读取接口,能够处理TXT、DOC、PDF、XML、HTML等多种文本格式的数据。
(3)数据清洗:原始数据中可能会含有一些特殊字符,这些字符或与定义内容无关,如回车符、HTML标签;或会对系统效率或稳定性造成影响,如连续较长的空字符、乱码等,因此在进行数据处理之前需要对数据进行清洗,过滤数据中的特殊字符。
(4)句子切分:定义语句通常是一个句子,因此按句子对文献进行切分和处理。科技类文献一般以句号作为句子的结束标志。
(5)定义语句识别:对切分得到的句子进行识别,使用定义语句模式库中的模式与句子进行匹配,如果匹配成功,则将句子作为定义语句候选,否则将句子过滤。
(6)为了今后利用的便利,需要对定义语句进行词法分析和索引。数据库进行内容查询时,使用字符匹配,查询一条术语需要对数据库中每一条记录进行匹配,类似于一页页地翻书,数据量大时效率极低。为了提高术语检索效率,对定义语句进行全文索引,相当于为术语建立目录,通过目录能够快速定位到术语所在的句子。当然,在建立索引前需要对句子进行词法分析,切分出一条条的术语。
这就是整个术语定义抽取系统流程,系统为定义语句的检索和利用建立了数据基础。
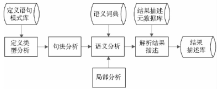
定义解析与定义抽取密切相关,只是定义抽取注重定义特征,而定义解析需要从已获取的定义中解析出关键的信息。定义解析的基本流程如图2所示:
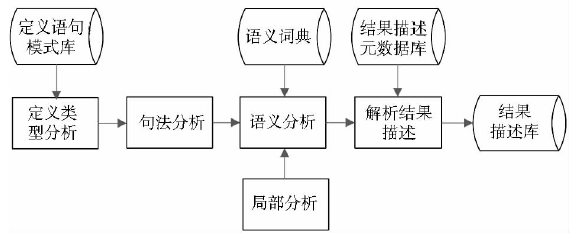 | 图2 术语定义解析流程图 |
通过对定义特征的考察,来确定内涵定义、外延定义等类型。通过内涵定义通常可以得到该术语的类属和特征;通过外延定义,可以得到关于术语内涵的子类或实例。其他类型的定义或者定义的补充部分也能从一定程度上揭示术语之间的关系。定义解析的具体分析过程包括定义句法、语义分析及局部分析。由于涉及到文本处理,需要利用有关的自然语言理解技术,形成关于定义的句法和语义分析工具。相对于通用的文本而言,科技术语定义文本因为具有自身的特点和固有的模式,所以需要定制专门的分析策略,由于处理范围进一步缩小,句法语义分析工具能够达到更高的准确率。科技术语定义的特征包含结构特征和语义特征,这些特征的描述方式的确会影响到后续应用。分析算法的选择很关键,Tomita算法分析结果较好,在其基础上进行适应性改造,实现了较高的分析性能。语义分析主要包括模式匹配、词义消歧、搭配发现、指代消解等,本文采用贝叶斯概率统计学习算法,和已有的语义词典、框架理论结合,并注意局部分析技术。解析结果的输出可以以自然语言描述,也可以是符号描述,还可以是两者结合的描述方式。根据实际的需求,本文采用在自然语言文本中标注标签符号的方式,所有的描述元数据存储在结果描述元数据库中,对于定义中涉及的其他概念仍采用自然语言的形式,便于在概念之间建立关联,进而形成知识网络和本体。对于关系和属性的部分描述标签设计如表1和表2所示:
| 表1定义解析结果输出中的部分关系描述标签 |
| 表2 定义解析结果输出中的部分属性描述标签 |
5 定义-知识转换
对定义解析后的结果可以进一步提取相应的标签内的内容填充到知识组织系统中。在严格要求的情况下可能需要人工审核,审核的关键是对Term及属性值边界的确定。
一些人工干预过的定义解析结果描述示例如下:
例1:<term>非转向桥</term>是指<character>不承担转向任务</character>的
例2:<term>双电层电容器</term>是建立在德国物理学家亥姆霍兹提出的界面双电层理论基础上的一种全新的<class>电容器</class>:在<has-part-of>电解液</has-part-of>中同时插入两个<has-part-of>电极</has-part-of>,并在其间施加一个小于电解质溶液分解电压的电压,电解液中的正、负离子在电场的作用下会迅速向两极运动,并分别在两上电极的表面形成紧密的电荷层,即双电层,从而产生电容效应。是一种介于<similar>电池</similar>和<similar>电容</similar>之间的新型特殊<class>元器件</class>。
例3:<term>电力液压助力转向装置</term>也是一种<class>助力转向装置</class>,它是<has-part-of>电动机电力助力转向装置</has-part-of>和<has-part-of>齿轮齿条式液压助力转向装置</has-part-of>的组合,也是<current>如今市面上最好的转向助力装置</current>。
例4:<term>标准电池</term>是指<character>国际上规定的作为电势(位)测量标准</character>的<class>电池</class>。它是由美国电气工程师E.韦斯顿在<begin>1892年</begin>发明的,故又称<alias-same>韦斯顿电池</alias-same>。
例5:<term>混合动力汽车</term>是指汽车使用汽油驱动和电力驱动两种驱动方式工作的<class>汽车</class>。优点在于车辆启动停止时,只靠发电机带动,不达到一定速度,发动机就不工作,因此,便<merit>能使发动机一直保持在最佳工况状态</merit>,<merit>动力性好</merit>,<merit>排放量很低</merit>,而且电能的来源都是发动机,<merit>只需加油即可</merit>。简单地说,混合动力汽车的主要优势在于,将汽油发动机和电动机相结合,<merit>可以加大马力并提高燃油经济性</merit>。国外的如<c-e>丰田普锐斯</c-e>、<c-e>荣威混合动力车型</c-e>、 <c-e>福特翼虎混合动力车</c-e>、<c-e>马自达RX-8混合动力</c-e>,国内的如<c-e>海马H12电动版</c-e>、<c-e>力帆混合动力车</c-e>、<c-e>长安杰勋混合动力版车型</c-e>。
例6: <term>悬架</term>是车架或车身与车桥之间的一切
通过上述示例即可以通过Term标签范围中的内容以及关系和属性标签范围中的内容得到相应词条的关系和属性,如“非转向桥-类属-车桥”、“非转向桥-特点-不承担转向任务”等。
实验数据集来自新能源汽车领域汉语科技词系统(http://www.vocgrid.org),随机从中抽取了200条核心词的词汇定义,实验中仅考察层级关系和特征属性,并以汉语科技词系统中人工构建的知识作为标准。经过定义解析和定义-知识转换后的实验结果如表3所示:
| 表3 在新能源汽车汉语科技词系统上的实验结果 |
从实验结果看,层级关系的自动丰富准确率较高,而特征属性的准确率较低,两者的召回率都较低。这说明通过定义进行知识组织系统自动丰富,获得的知识是不完备的,因此完全依靠这些技术进行自动构建还有一定问题,但是用于初始骨架的构建和知识组织系统更新具有一定的可行性。此外,虽然准确率偏低,但是自动丰富的关系和属性经人工判断是有一定意义的,只是现在词系统还没有收录,这是由于汉语科技词系统在构建的时候,根据知识工程师和专家的个人经验对知识有所取舍,这也从另外一个角度说明这些自动丰富技术可以用来补充现有的知识组织系统,使之更加完善。
但是在基于定义的描述中也存在一些问题:
(1)知识组织系统中的知识是共享的,体现的是共同认可的知识,反映的是相关领域内公认的概念集,但是定义解析的结果体现的可能是公认的知识,也可能只是局部公认的知识,甚至可能是存在争议的知识,是某个人独特的认识,这与来源有关。
(2)定义的描述尽管可以实现几种关系和属性的自动丰富,但是与全部的关系和属性结合相比,只是其中一部分。
(3)从形式上讲,科技术语定义中除了常见的文字之外,还经常用到符号或者符号的集合,这是自动解析的一个难点。由于符号的有限性,在不同的文献中,同样的符号经常有不同的约定定义,因此在术语定义知识组织的时候,要充分区分这些符号的不同含义。如“传统点火系也称为触点点火系。它以蓄电池或发电机为电源,利用断电器的触点产生点火信号,控制点火线圈初级电路的通断,是点火系统工作。主要由点火线圈a,分电器(包括断电器b,配电器e,电容器f),火花塞c和电源d组成”这一定义中的符号与上面例6中的符号相同,但是代表的含义不同,这种描述经常性地出现在教科书中。
知识组织系统的核心是概念以及对概念的关系描述、属性描述。描述一个概念,尤其是科技领域中的概念,依靠人工构建面临着多重困境,而完全自动构建也不现实。本文从定义对描述概念的重要性以及定义自动分析处理的相对可行性出发,提出了一种基于概念的定义自动解析,进而实现知识组织系统自动丰富的方法,并对定义抽取、定义解析和定义-知识转换等关键技术做了较为详细的研究。实验结果证明,虽然本方法仍然存在一定的不足之处,但是在当前条件下有一定的应用价值,下一步将进一步完善技术,并从来源选择、算法优化、知识库充实等方面尽可能地解决问题,提高其实用性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|