



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于本体知识表示的历史领域专家系统模型
[董慧, 徐雷 ]
]
]
|
|


This paper compares the advantages and disadvantages of the knowledge representation methods, and then introduces the superiority of Ontology based knowledge representation and knowledge reasoning emphatically. At last, it illustrates the applicational advantage of Ontology in expert system by constructing history domain Ontology model.
专家系统具有某一个具体应用领域的专家级知识,能够提供类似专家的解决方案。知识库作为专家系统的核心,其组织形式将直接影响专家系统的性能,传统的知识表示方式诸如基于逻辑的表示法、基于产生式规则的表示法、语义网络表示法等在知识的共享和重用方面都存在一定的局限,难以实现复杂综合型的专家系统对快速开发和共享重用的需求。因而需要一种新的知识表示方法来构建知识库,以实现异构系统之间的共享和重用。本体作为一种知识表示方式,其对知识的明确定义以及推理共享能力逐渐被运用到人工智能等相关领域。近几年,本体在知识库的组织和构建上得到了广泛的关注,基于本体的知识库系统诸如专家系统也得到了快速发展和应用。
构建一个专家系统包括构建知识库以及设计推理机制两个部分[ 1]。知识库是专家系统的核心,专家系统中知识的数量和质量直接决定专家系统解决问题的能力,而知识库中知识表示方式将直接影响知识在使用过程中的有效性、可修改性、一致性、完备性、共享性和重用性。
专家系统中有多种知识表示形式,传统的知识表示方法有逻辑表示法、产生式表示法、框架表示法、对象表示法和语义网络表示法等。不同的知识表示法既有优势又有不足。
(1)基于逻辑的知识表示具有简单、易理解、模块化的特点,但难以表示过程性和启发式知识,难以管理大型知识库,对于事实数量较大的证明过程进行操作时能力差;
(2)产生式表示方法克服了逻辑表示方法只能表示精确知识的局限,它能够通过置信度表示不精确的知识,并且可以把对问题求解中有意义的各种启发性知识引入系统中,但它同样存在效率不高的缺点;
(3)基于框架的知识表示方法解决了产生式表示法不能解决知识之间的结构关系和只能表示事物之间因果关系的局限,具有很好的结构性和继承性,其不足之处是不善于表示过程性的知识,其模块性不如面向对象的表示方法好;
(4)面向对象的表示方法具有封装性、模块性、继承性、易维护性等优点,克服了知识库开发、维护以及管理的难度;
(5)基于语义网络的表示法同框架表示法和面向对象的表示法都是结构化的知识表示方法,其表示方法灵活,可用在很复杂的分类学推理中,但随着对象节点的增加,语义网络的管理将很复杂,同时要避免陷入无穷支路导致无解的状况。
本体最早起源于哲学领域,后来被引入人工智能领域,主要用在知识表示、知识库、语义信息处理等方面。本体是共享概念模型的明确的形式化的规范说明[ 2]。概念模型是指将现实世界中的事物抽象为概念并由此构建为模型,明确是指本体所表示的概念及其约束具有清晰的定义,形式化是指本体所表示的知识能够被计算机所处理,共享则反映了本体中所表达的知识具有普遍的意义,能够被相关领域广泛地使用和认可。
本体作为一种知识表示方式,与传统知识表示方式相比具有不同的层次。本体表达了概念的结构、概念之间的关系等领域中固有特征,即“共享概念化”,其他知识表示方式表达的则是某个个体对领域中实体的认识,而不一定是实体的固有特征[ 3]。本体知识表示法和语义网络表示法最为接近,它们都是结构化的知识表示方法。本体知识表示法继承并扩展了语义网络表示法、框架表示法和面向对象表示法的表示方式,不仅可以表示基本的层级关系,诸如实例联系(ISA)、泛化联系(AKO)、聚集联系(PARTOF)等,还可以表示概念间的并集、交集和基数约束等较为复杂的联系。本体表示法综合了传统知识表示方法的优点,并具有丰富的知识表示语言,能够很好地实现知识的共享和重用,弥补了传统知识表示方法之间存在的差异性。
本体既可以描述通用的知识又可以描述特定领域的知识,既可以描述简单的实体又可以表示抽象的概念,既可以描述静态的知识又可以描述动态的知识。本体在知识表示方面的优势使其在诸如语义Web、信息抽取、信息交换等领域已经有所应用,在专家系统领域国内外也出现了许多探索性的研究和应用。
在国内,胡鹤等[ 4]在原有专家系统开发平台BAPDES之上引入本体中间件的设计思想,以支持知识访问中的知识转换和互操作需求。在BAPDES平台中,其底层是操作系统构建库以及IIS服务层,其上是开发平台内核层,知识库、推理机和解释器均位于这一层。知识库以一定的形式存储在关系数据库SQL Server中。开发平台内核层之上是开发工具层,这是本体中间件所在的核心层,提供了本体知识的编辑、维护和框架定制等功能以及一些接口。本体中间件的接口包括访问层、模块层、本体存储与推理层、知识控制层、本体库等多个层次,其中访问层可支持多种协议,模块层包括管理、查询、输出、安全、版本、推理等模块,用户可以透明地访问本体库,其推理模块可以支持OWL语言[ 4]。
文献[5]将本体的思想应用于高速切削专家系统中,把本体库划分为概念库、关系库、属性库、规则库和实例库,并把构建好的本体库用巴科斯范式表示,存储在关系数据库中。用户可以通过输入参数进行相关的数据查询,还可以通过系统计算需要解决方案的输入参数和实例库参数匹配的相似度,进而输出求解方案,同时在不能成功匹配的情况下,系统提供了优化参数的算法,用于向用户提供新的解决方案;文献[6]将本体运用在森林病虫害专家系统中,构建森林病虫害本体库,以提高专家系统的推理能力;文献[7]将本体作为知识库的构建工具运用于发动机故障诊断专家系统;文献[8]则用OWL语言描述地震灾害信息,辅助灾害援救计划的制定。
国外也有很多将本体技术运用于专家系统的研究和应用。当今传感技术广泛运用于自然灾害响应、军事战略部署、持续监控等领域。文献[9]将本体运用于处理传感数据的专家系统中,该系统包含一个OntoSensor,它是一个本体传感器,包括一个知识模型,用于处理诸如数据采集面板、传感器、处理器、广播等接收到的数据,还包含一个传感类型的分类层次,用于描述传感元件的敏感性和性能参数等元数据以及传感设备的物理性能参数;文献[10]将本体应用于导航系统中,用本体表示路况、用户操作、天气、车辆属性等领域知识和专家知识,以帮助用户实现个性化的路线选择和不同用户模型之间的共享;文献[11]将本体运用于分布式农业专家系统,本体知识库由不同地理位置的农业专家通过语义网络共同维护;文献[12]将本体运用于专家对等检索系统中,用本体树来描述特定领域的专家知识,本体树的每一个节点表示所描述的主题或子主题的相关词汇。用户可以在线发送实时的查询信息,系统将其转换为基于本体的查询树,通过匹配本体树得到系统提供的实时检索结果;文献[13]用本体描述药片的生产工艺信息,实现药片生产工艺的重用和共享;文献[14]通过使用本体来描述财政领域的会计知识,将本体用于企业财政评级;文献[15]将本体用于描述平衡计分卡的领域知识,辅助企业组织战略管理。
专家系统一般由人机交互界面、知识获取模块、推理机、解释器、综合数据库、知识库6个部分构成,专家系统的结构如图1所示[ 16]:
 | 图1 专家系统结构图 |
人机交互界面用于收集用户提出的问题,与用户交互以及反馈和解释系统的推理结果;知识获取模块负责知识库的构建、修改和扩充。针对需要求解的领域问题,知识获取要从专家或者其他知识来源获得相关问题的专门知识并存储在知识库中;推理机是基于知识库进行推理的机构,它按照一定的搜索策略在知识库中搜索相关的知识并解释执行;解释器负责对系统推理过程、推理位置及推理的每个动作给出解释,使用户相信问题求解结论是可信的和正确的;综合数据库主要用于系统运行过程中的中间结果和数据的辅助存储;知识库是为了求解所需要的某一领域的问题,采用某些知识表示方式在计算机中存储、组织、管理和使用的相互联系的知识集合。这些知识包括领域相关的基础知识,由专家经验得到的启发式知识,领域相关的定义、定理、规则以及其他一些信息。
专家系统的设计主要需要实现知识的获取、表示、存储、维护管理和知识检索等功能,知识检索与信息检索相比是体现在语义上,传统的知识检索方法有一定的效率,但将知识的表示、获取、存储和检索等技术综合起来的手段并不多。将本体运用于专家系统中,通过概念以及属性来表达知识,揭示概念内部之间的联系,同时通过概念与概念之间的关系来表示概念之间更广泛的联系,推理机利用这些关联进行推理,以满足用户对知识检索的需求。
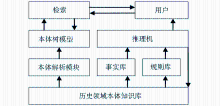
本文在分析和研究国内外相关知识系统的基础上,利用本体技术构建一个历史领域的专家系统模型,选取三国时期历史为研究对象,其结构如图2所示:
 | 图2 历史领域的专家系统结构图 |
(1) 构建本体库
选用斯坦福大学开发的本体编辑器Protégé3.4来构建历史领域的本体库。Protégé具有良好的用户界面和便捷的操作功能,按照Protégé开发领域本体库模型的七步法则来构建本体知识库,主要包括类、属性和个体三个部分。对处理的自然语言描述的历史资料进行分段和分句,针对拆分出的句子、分词和词性进行标注。在词性标注的基础上选择适当的动词作为句子的语义谓词,再根据语义谓词来获取相关的语义实体,同时也把时间和地点维一并提取,对指示代词进行消解。最后将提取得到的结果存入语义数据库。结合历史领域本体构建的实际情况,本体构建思路及流程如图3所示:
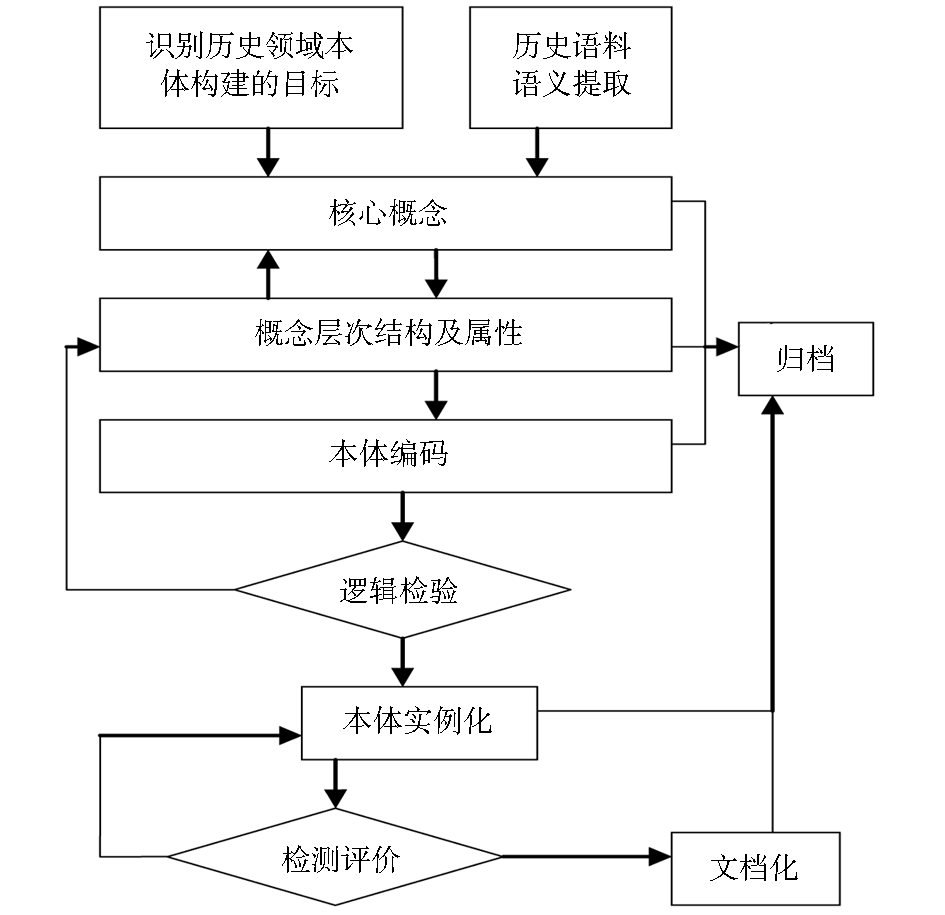 | 图3 历史领域本体构建流程图 |
在历史领域中,类主要包括人物、时间、地点和事件等,在Protégé中属性可分为对象属性和数据属性两种,对象属性是用来描述对象间的关系,比如人物和事件之间是做与被做的关系,数据属性是对象自身所拥有的特点,比如人物具有名字、职官等属性。在本体描述语言中还可以对属性进行约束,比如人物与事件的做与被做之间的关系是可逆属性,可有用Inverse表示,另外在本体描述语言中还有Functional、InverseFunctional、Sysmmetic、Transitive等约束可以满足属性之间关系的约束需求,在Protégé中本体库建立完成后可以用OWL格式存储,还可以方便地将其转存在数据库中。
(2)用OWL描述本体
OWL是W3C推荐的本体描述语言,是在DAML+OIL的基础上发展而来的,保持了对DAML+OIL/RDF/RDFS的最大兼容性,同时具有更强大的语义表达能力和推理能力[ 17]。在OWL中可以通过命名空间来引用不同的本体,实现本体之间的联系,可以定义类、个体和属性以及继承类和继承属性。OWL中对属性的表示有许多有用的表达,诸如SymmetricProperty(对等属性)、 FunctionalProperty(函数属性)、 inverseOf(可逆属性)等,属性之间还定义了很多约束,比如allValuesFrom、 someValuesFrom 、hasValue等。同时,OWL语言通过类之间的交、并、补运算实现复杂类的表示。使用Protégé构建历史领域的本体,考虑到历史领域知识的庞杂,初步将历史领域本体划分为人物、时间、地点、事件4个子类,本文着重描述历史人物本体,通过历史人物来反映整个历史领域知识。
历史人物类(Figure)有数据属性姓名、字、号、别名等,人物类通过相应的对象属性与人物的出生地(BirthPlace)、著作(Book)、职官(Position)、社会关系(SocialRelationship)、生卒年(TimeRange)等取得联系。出生地(BirthPlace)有国家籍贯、具体出生地子类,其中国家类通过hasLastTime对象属性与时间本体(Time)连接,表示国家朝代的起讫年代;hasContraledArea对象属性与地点本体(Place)连接,表示该国家的势力范围;生卒年(TimeRange)有起止年(hasStartYear、hasEndYear)数据属性,并通过hasPeriod对象属性与时间本体(Time)连接,表示人物所处的历史朝代及时期;职官(Position)按中央和地方分为两类;著作类(Book)分为标题、内容、体裁三类,其下又有细分,不再赘述;社会关系(SocialRelationship)分为亲属、工作、朋友三类关系,其中亲属关系较为复杂,需要考虑多代人之间的关系以及属性之间的可逆性,诸如Sonof和Fatherof之间的关系就是可逆的。在设计人物本体时充分考虑人物关系的复杂性,社会关系中的对象属性设计比较完善,也注意了相应的约束条件。由于历史领域本体的构建比较复杂,难免出现数据不一致的情况,需要对本体进行一致性检验,使用的工具是Racer推理机,它能够根据本体中的概念及关系推理出最合理的概念层次,并解决概念之间的冲突。历史领域本体结构如图4所示,部分OWL代码如下。
 | 图4 历史人物本体 |
该部分是定义一对逆反属性
该部分定义一个函数属性,其值域是时代(TimeName),定义域是人物类和生卒年的并集
(3)用Jena解析OWL文件
Jena是HP实验室开发的基于Java的开放源代码语义网工具包[ 18],其内容比较全面,包括RDF API、RDQL查询语言、推理子系统、存储、本体等主要功能模块。上文中提取的语义信息就是通过Jena存储到语义数据库。Jena读取OWL文件的核心代码如下:
Model schema=ModelFactory.createDefaultMode();//用来创建一个本体模型
InputStreamin=FileManager.get().open(inputFileName);// 将OWL文件读入内存
<owl:ObjectProperty rdf:about="#isFatherof">
<rdfs:range rdf:resource="#Figure"/>
<owl:inverseOf rdf:resource="#hasFather"/>
<rdfs:domain rdf:resource="#Figure"/>
<owl:FunctionalProperty rdf:ID="hasPeriod">
<rdfs:range rdf:resource="#TimeName"/>
<rdfs:domain>
<owl:Class>
<owl:unionOf rdf:parseType="Collection">
<owl:Class rdf:about="#Figure"/>
<owl:Class rdf:about="#TimeRange"/>
</owl:unionOf>
</owl:Class>
</rdfs:domain>
public class GetOnto extends Object{
static final String inputFileName=“E:/Ontohistory.owl”;
public static void main(Stringargs[]){
if(in==null)
{thrownewIllegalArgumentException
(“the File:“+inputFileName+”is not found”);}
schema.read(in,“”);// 将该文件映射到建立好的本体模型中
schema.write(System.out);
}}
(4)本体检索
随着本体的运用越来越广泛,对本体资源的检索就变得越来越重要。本体检索语言伴随着本体的广泛运用也得到了很大的发展和应用,诸如SPARQL检索语言现在已经发展得比较成熟。还有在Jena中广泛运用的RDQL检索语言,比较适合熟悉SQL语法的用户。用Jena建立好本体模型后,就可以进行查询操作,部分代码如下:
String queryStr= …;
Query query = QueryFactory.create(queryStr);
QueryExecution qe = QueryExecutionFactory.create(query, schema);
ResultSet results = qe.execSelect(); //查询结果记录集
Vector v = new Vector();
while (results.hasNext()){ //遍历记录集
QuerySolution tqs = (QuerySolution) results.next();
v.addElement(new String(tqs.getLiteral("name").getString()));
}
(5)本体推理
本体推理用于对具体领域的隐性知识进行挖掘、检测本体知识逻辑错误、减少本体构建工作量、减轻对专家领域的依赖[ 19]。推理机的系统结构一般由本体解析器、查询分析器、推理引擎、结果输出和用户API等5部分组成[ 20]。当前的本体推理机有很多种,诸如Racer、Jena推理引擎、FaCT等都是针对性比较强、效率比较高的推理机,还有基于Java的CLISP推理机JESS规则引擎,主要面向底层使用[ 21]。当前的推理机制一般都是基于事实和规则的推理,规则库中知识是否完整、一致,表达是否准确,对知识的组织是否合理等,都会影响到系统的性能和效率,因此对规则库的构建要有足够的重视。建立规则库需要有效地表达领域内的过程性知识,对其进行合理的组织与管理。当前,基于本体的规则语言有SWRL(Semantic Web Rule Language),它综合了OWL的子集OWL DL与OWL Lite语言,以及一元与二元的Datalog RuleML规则标记的语言[ 22]。
本文通过建立规则,在Jena中实现本体的推理。通过两个实例建立两则规则。例如,史书记录曹植的名篇《洛神赋》,如果在设计本体库时,在著作类中增加一个属性以标明该书的创作年代,会显得多余,可以通过该书的作者所处的年代来判断该书的创作年代。曹植生卒年(TimeRange)为公元192-232年,所处时期(Time)为“三国”, 通过推理规则可知《洛神赋》创作于三国时期。用规则可表述如下:如果人物x有著作y,并且x生活在z朝代,那么著作y就是在z朝代完成的,即:
RULE1:(?x has book ?y),(?x hasPeriod ?z) -> (?y writtenin ?z)
如果要判断两个历史人物之间的工作关系,可以通过人物之间生活的时代和任职的地点以及职位间的隶属关系来推理,此规则可描述为:假设两个历史人物x和y生活在同一个朝代z,并且都在w这个地方任职或工作,如果y的官职q是x的官职p的子类,那么x就是y的上司,即:
RULE2:(?x hasPeriod ?z),(?y hasPeriod ?z),(?x workin ?w),(?y workin ?w),(?x hasPosition ?p),(?y hasPosition ?q),(?q subclass of ?p) -> (?x superiorof ?y)
实现推理的代码如下:
String rules = “[RULE1:(?x has book ?y),(?x hasPeriod ?z) -> (?y writtenin ?z)]”+”[RULE2:(?x hasPeriod ?z),(?y hasPeriod ?z),(?x workin ?w),(?y workin ?w),(?x hasPosition ?p),(?y hasPosition ?q),(?q subclass of ?p) -> (?x superiorof ?y)]”
Reasoner reasoner=new GenericRuleReasoner(Rule.ParseRules(rules));//将编写的推理规则加入到规则库中
reasoner=reasoner.bindSchema(schema);
InfModel inf=ModelFactory.createInfModel(reasoner,rawData)
本文建立了历史领域的本体库,初步完成了历史领域专家系统模型的构建。使用Java这种独立于底层操作系统的开发语言,保证了模型中各个模块的整体开放性和可移植性,并为以后实现其他历史时期的本体模型的构建提供了可扩展的接口。同时通过将本体引入历史领域的知识库构建,充分发挥了本体在提高知识的互操作性、共享性、可重用性和可维护性等方面的优势。
由于本系统还处于雏形,历史领域知识的实例化暂时只考虑三国时期。笔者单独对各个模块进行了功能测试,结果均能正常呈现。检索模块可以检索本体实例以及本体属性,暂时没有提供本体之间的关系检索;推理模块可以推理出两个历史人物、历史事件之间所蕴含的关系。
用户通过此模型可以检索历史领域的基本常识,如输入历史人物、历史事件等关键字,可以得到相应的本体描述,以及它们的属性描述;输入一个历史人物,可以得到该历史人物的生平描述,以及其别名、出生地、出生年月、著作等属性,还可以得到该历史人物参与的重大历史事件以及与其联系紧密的其他历史人物,通过一定的推理功能,还能够推理出人物之间的社会关系等隐含的知识。系统的检索模块功能演示如图5所示:
 | 图5 历史领域本体检索模块功能图 |
建立本体的概念模型使知识的维护更加容易。用本体明确清晰地表示知识,避免了不同数据源中知识的异构所带来的问题;本体的形式化表示使知识的推理更加强大;通过本体概念之间的关系,概念的属性及属性之间的关系可以表现出类似人类的逻辑思维,并推理出所需要的信息。
本文通过不同知识表示方式之间的优缺点的比较,分析了将本体运用于专家系统中知识的表示所具有的优势,总结了国内外相关领域的发展现状,初步建立了一个历史领域的专家系统模型。结合本文的分析与研究,今后的工作在以下两个方面仍然需要改进:
(1)由于历史领域的知识庞杂,有的问题历史领域专家也不易解决,诸如不同史料之间存在的矛盾问题,如何处理人物职官随时间变化的问题,如何处理历史事件粒度划分等,这些问题需要进一步同历史领域专家进行探讨,寻求一个合理的解决方案;
(2)进一步完善该专家系统模型的功能和界面设计,对如何使基本的本体库可以方便地进行节点的增加、删除和归并操作等问题需要着重考虑,以便在未来的工作中对历史领域的本体库结构进行改进和优化。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|