{kind=link}
基于条件随机场的介宾结构自动识别
[朱丹浩 , 王东波, 谢靖]
, 王东波, 谢靖]
, 王东波, 谢靖]
|
|


基于条件随机场对介宾结构进行自动识别的研究。为有效地识别介宾结构,基于清华树库统计介宾结构的外部和内部语言学特征。基于条件随机场,结合介宾结构的语言学特征,使用复杂特征模板对无嵌套介宾结构和有嵌套介宾结构进行自动识别。在开放测试中,F值最高分别达到90.29%和89.99%。
Based on Conditional Random Fields(CRF), the article identifies the Chinese prepositional phrase. In order to identify the prepositional phrase effectively, the article counts and analyzes the external and internal linguistic features of the prepositional phrase. The prepositional phrases without nesting and nested prepositional phrases are identified with the complex feature model,and in open tests,the best F value can reach 90.29% and 89.99% respectively.
介宾结构作为一种重要的短语结构,在中文句子中占有较大的比重。通过对清华汉语树库(TCT973)31 970个句子的统计,其中共有介宾结构21 924个,几乎每3个句子中就有2个介宾结构出现。正确识别介宾结构在中文句法分析中有重要的意义, 介词结构识别可以缩小句子中心动词的选择范围;可以简化句子结构,降低后续句法分析的难度;在基于模板的翻译中,它还能为模板匹配提供方便[ 1]。
随着文本自动识别技术的发展,许多学者对介宾结构的自动识别做了有益的研究。国外学者分别使用不同的方法对介宾结构进行了探究和识别:Brill等[ 2]的基于启发式规则的转换算法,Pantel[ 3]的基于语料库的无指导的学习方法,Schwartz等[ 4]提出的双语对齐消歧法和McLauchlan[ 5]的相似词语平滑算法。干俊伟等[ 6]运用规则和统计相结合的方法构造了一个汉语介宾结构的识别算法,奚建清等[ 7]提出了一种基于隐马尔可夫模型(HMM)的介宾结构界定模型,于俊涛[ 8]提出了基于最大熵的汉语介宾结构自动识别方法。
基于隐马尔可夫模型容易引起数据稀疏等问题,而基于最大熵的自动识别模型对于规则的描述又过于繁琐。条件随机场是一种用于序列标注的判别模型,较好地克服了输出独立性假设和马尔可夫性假设的局限性,并且能从上下文中任意地选择所需要的特征。本文在介宾结构自动识别中应用条件随机场模型,取得了良好的效果。基于条件随机场,介宾结构自动识别在开放测试中最高精确率达到91.40%,最高召回率达到89.21%,最高F值达到90.29%。
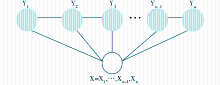
条件随机场是一个基于无向图的条件概率模型,也称作马尔可夫随机域[ 9]。设X是观察到的观察值序列,也就是待标注的对象;Y是相应的标注序列的随机变量。在本文中,X即为待标注的文本,Y为介宾结构标注。
定义:图G=(V,E)[ 10]是一个无向图,如果给定X,随机变量Y=(Yv)v∈V遵循马尔可夫属性,即p(Yv|X,Yw,v≠w)=p(Yv|X,Yw,v~w),v~w 表示v和w是G中相邻的节点,那么(X,Y)是条件随机场。最简单且最常用的条件随机场的图结构是一阶链式结构,即线性链结构,如图1所示:
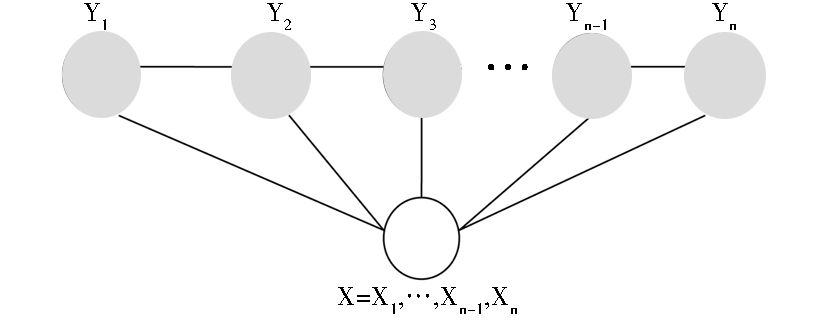 | 图1 条件随机场的链式结构[ 11] |
从条件随机场的定义来看,无向图的结构可以是任意的,当图形模型中的各输出节点被连接成一条线性链的特殊情形下,条件随机场假设在各个输出节点之间存在一阶马尔可夫独立性。任意给定的状态都有可能放大或缩小其转移到下一状态的概率值,而任意状态序列的最终权值将由全局归一化因子定义适当的概率值。与隐马尔可夫模型、最大熵模型相比,条件随机场较好地解决了标注偏置问题[ 9]。正是基于这一特性,条件随机场在基于字符的中文分词、命名实体识别和基本名词短语识别等许多应用中都表现优异。
本文在考察介宾结构的语言学特征的过程中主要使用统计的方法,统计数据主要来源于清华汉语树库(TCT973)。
清华汉语树库的语料是从大规模的经过基本信息标注(切分和词性标注)的汉语平衡语料库中,提取出100万汉字规模的语料文本,经过自动断句、自动句法分析和人工校对,形成高质量的汉语句法树库语料。具体情况如表1所示:
| 表1 清华汉语树库的基本统计数据 |
其中,介宾结构在清华树库中被标成了“xx-JB”,例如:[pp-JB 对/p [np-DZ 国家/n 的/u [np-DZ 货币/n 收入/n ] ] ]。
介宾结构总出现次数为21 924,其中嵌套出现的介宾结构次数为557,占总数的2.54%。出现次数在100次以上的介宾结构短语词性序列如表2所示:
| 表2 介宾结构内部词性序列分布 |
由表2可以看出,出现频次在100以上的介宾结构共有9 839次,占了总频次的46.05%,而其中前5位的总和为6 605次,占总频次的30.91%。由此可以发现,介宾结构的整体分布是一个左偏分布,一小部分介宾结构出现频率很高,比如“介词+名词”的组合,而大部分组合出现频率很低,有4 717个组合在整个语料库中只出现了1次。
在出现次数大于100的26种介词结构中,词性序列主要包括名词(n)、代词(rN)和方位词(f)等,其中以名词居多,并且大部分介词结构中只有2个词,最多的不超过4个词。
通过观察频次出现小于100的介宾结构可以发现,词性序列相对复杂,并且由于出现频次较低,无规律可循,无法用基于规则的方法进行识别,因此只能使用统计模型给予预测,比如:因/p 其/rB 原意/n 泛指/v 一切/rN 财务/n。
本文所用的清华树库的数据结构是树形结构。分析介宾结构的第一层分支节点,比如“[pp-JB 随着/p [np-LH [np-DZ 生产力/n 的/u 发展/vN ]”中,内部的短语序列即为np-DZ。出现频次在100以上的内部短语序列如表3所示:
| 表3 介宾结构内部短语序列分布 |
整个清华树库中介宾结构内部一共出现短语序列13 744次,其中定中结构+方位结构出现了9 573次,占总数的69.8%。而出现频次在100以上的11个结构序列总频次为13 228,占总数的96.2%。由此可见,介宾结构内部结构分布集中在少数几个短语序列中。
经过统计,介宾结构中共出现了54种内部短语序列,其中有4种内部短语序列是由两种结构组成:pp-AD tp-DZ,vp-AD mp-DZ,pp-AD np-DZ,pp-AD sp-DZ。其他所有结构为一元结构。由此可见,在介宾结构包含的子序列中,绝大多数为一元结构,二元及以上结构几乎没有。
清华树库中标记繁多,需要对语料进行预处理,才能对介宾结构进行训练和自动标记。
(1)去除树库中所有的结构的标志,只保留介宾结构的结构标志。例如“[zj-XX [dj-ZW 财政/n [vp-PO 是/vC [np-LH [dj-ZW 国家/n [vp-ZZ [pp-JB 为/p [vp-PO 实现/v [np-DZ 其/rB 职能/n ] ] ],/, [vp-PO 参与/v [np-DZ [np-DZ [np-LH [np-DZ 社会/n 产品/n ] 和/c 国民收入/n ] [np-LH 分配/vN 、/、 再分配/n ] ] 活动/n ] ] ] ] 及其/c [np-DZ 形成/v 的/u [np-DZ 分配/vN 关系/n ] ] ] ] ]。/。 ]”经过处理后变为“财政/n 是/vC 国家/n [pp-JB 为/p 实现/v 其/rB 职能/n ],/, 参与/v 社会/n 产品/n 和/c 国民收入/n 分配/vN 、/、 再分配/n 活动/n 及其/c 形成/v 的/u 分配/vN 关系/n。/。”
(2)对句子中的每个词进行介宾结构标注。在确定用于介宾结构识别的CRF标记数的时候,参考了如下公式:
Lk={Invalid MML}iNk (k>2)
其中,Lk是i≥k时的平均加权介宾结构长度;Nk是语料中介宾结构长度为k出现的次数;k是语料中出现过的最大介宾结构长度;N是语料库中介宾结构总的出现次数。如果k=2,那么Lk代表整个语料的介宾结构的平均长度。在参考这个公式的前提下,根据具体的实验结果,确定使用6词位标注集,具体的标注集为T={B,I,O,M,E,S}。其中,B是介宾结构的开始词;I是结构中第二个词;O是结构中第三个词;M是结构中第4个以上(包括第4个)的词,E是结构结尾的词;S是介宾结构外部的词[ 10]。
基于条件随机场识别介宾结构的核心是特征的确定,特征选择的好坏将直接决定条件随机场的性能。根据特征数量的多少,结合介宾结构的内部和外部语言学特征,使用复杂特征来识别介宾结构。
基于复杂特征的介宾结构自动识别中的复杂特征主要是由词语和词性生成的,词语和词性用标记表示为“W,P”,字母旁边的整数表示所考察的特征位置。例如0表示当前位置、-1表示左边第一个位置、1表示右边第一个位置。所选择的特征窗口分别为:词语为7个窗口,范围是{-3,-2,-1,0,1,2,3};词性为5个窗口,范围是{-2,-1,0,1,2}。根据观察窗口,结合介宾结构识别确定特征模板的实验,基于复杂特征介宾结构自动识别共使用了18个特征,具体为:
W-3,W-2,W-1,W,W+1,W+2,W+3,W-1/W,W/W+1,W-1/W+1,P-2,P-1,P,P+1,P+2,P-1/P,P/P+1,W/P
以清华树库为基础,将其31 970个句子平均分成10份,对其中9份进行训练,一份进行自动标注检验,对10份语料进行交叉测试,一共进行10次实验。为了区分条件随机场在有嵌套介宾结构和无嵌套介宾结构上的不同表现,分两部分进行实验。同时,为了验证条件随机场的性能,基于同样的特征,使用最大熵模型对介宾结构进行识别实验。实验环境操作系统为Windows XP,CPU为Intel Core2 Duo,主频为2.40GHz,内存为4GB。识别性能采用三个指标来衡量:准确率(Precison)、召回率(Recall)、F值(F-measure)。具体计算公式如下:
准确率= [a/(a+b)]×100%
召回率= [a/(a+b+c)]×100%
F值= 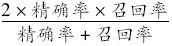
其中:a为正确识别的介词短语个数,b为错误识别的介词短语个数,c为未判断的介词短语个数。
(1)无嵌套介宾结构自动识别结果
介宾结构内部再无介宾结构的介宾结构称为无嵌套介宾结构,如“[pp-JB 作为/p [np-DZ 经常性/n 的/u [np-DZ [np-LH 思想/n 政治/n ] 工作/n ] ] ]”。无嵌套介宾结构由于内部标注无歧义,便于使用条件随机场识别,具体的开放测试实验结果如表5所示:
| 表5 基于CRF的无嵌套介宾结构识别结果 |
由表5可以看出,在10个实验中,F值最高的达到90.29%,最低的为83.05%,上下波动约7%,平均值为86.78%。统计数据表明模型已经达到了较佳效果,且稳定性较强。通过对测试样本数量和F值的观察可以发现,F值的变动和样本数量没有明显线性关系,由此可以得出结论,即训练样本达到一定数量后,训练效果提升并不明显。识别错误的介宾结构如“[经/p 选拔/vN vp-LW 留校/v]任教/v”由于“留校任教”是一个连谓结构,没有修饰或限定关系,右边界往往会确定错误。还有其他原因会造成错误,如分词不一致或分词错误等。
(2)有嵌套介宾结构自动识别结果
介宾结构内部有一个或一个以上的介宾结构的介宾结构称为有嵌套介宾结构,如“[pp-JB 对/p [np-DZ [dj-ZW [np-DZ 我/rN 军/n ] 培养/v ] 的/u [np-DZ [mp-DZ 一/m 大/a 批/qN ] [np-DZ [pp-JB [pp-JB 经/p 选拔/vN ] [vp-LW 留校/v 任教/v ] ] 的/u [np-DZ 青年/n 知识分子/n ] ] ] ] ]”。有嵌套的介宾结构标注过程中会有歧义,尤其是在确定介宾结构右边界的时候,往往会识别错误。具体的开放测试实验结果如表6所示:
| 表6 基于CRF的有嵌套介宾结构识别结果 |
由表6可以看出,在10个实验中,F值最高的达到89.99%,相对无嵌套介宾结构来说,识别结果稍差。通过表6和表5的对比可以看出,造成整体有嵌套介宾结构F值低的主要原因是嵌套的介宾结构识别错误。具体错误主要是由于多个介宾结构的存在造成了边界确定的错误,如“[距离/p 香椿树街/nS]两/m 公里/qN”和[比/p 之/rN]北京/nS 的/u “/w 国宴/n ”/w”等。
为了验证基于条件随机场识别介宾结构的有效性,选取了最大熵模型作为对比,选取的对比样本是有嵌套介宾结构的测试数据10。具体结果如表7所示。
从表7可以看出,由于最大熵模型本身存在标注偏置的问题,错误识别和未识别的问题都比较严重,从总体上导致了F值相对条件随机场来说比较低,这也在一定程度上验证了条件随机场在序列化标注上的良好性能。
| 表7 条件随机场和最大熵的测试对比 |
本文将条件随机场应用于介宾结构的自动识别,取得了良好的效果,在各10份无嵌套介宾结构和有嵌套介宾结构的实验结果中,F值最高分别达到了90.29%和89.99%。与目前其他已有的介宾结构识别方法相比,基于CRF的介宾结构识别有明显提高,在解决数据稀疏和长距离依赖方面,CRF有着最大熵无法比拟的优势。下一步工作将重点解决分词不一致和嵌套介宾结构边界确定问题,进一步提高介宾结构识别的精确率和召回率。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|