

{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种多维关键词与分类关联的科学数据资源分类导航平台构建方案
引用本文
刘润达, 彭洁, 涂勇. 一种多维关键词与分类关联的科学数据资源分类导航平台构建方案. 现代图书情报技术, 2010, 26(9): 74-78
Liu Runda, Peng Jie, Tu Yong. A Scientific Data Resource Navigation Platform Scheme Based on Multi-facet Keyword and Classification Connection. New Technology of Library and Information Service, 2010, 26(9): 74-78
Permissions
Liu Runda, Peng Jie, Tu Yong. A Scientific Data Resource Navigation Platform Scheme Based on Multi-facet Keyword and Classification Connection. New Technology of Library and Information Service, 2010, 26(9): 74-78
Copyright©2010, The modern information technology editorial office
This article is the open access journal literature, in the following situations are free to use: academic research and academic exchanges, scientific research and teaching, etc., but don't allow for commercial purposes.
一种多维关键词与分类关联的科学数据资源分类导航平台构建方案
摘要
从图书情报领域的分类法及相关理念入手,研究构建网络科学数据资源的分类导航平台。引入动态面分类法对科学数据资源目录进行组织,在此基础上,提出可行的多维与多维分类关联的标引方法,设计基于分类与关联权重的排序方案,使用该构建方案开发的实验系统可以有效地对分散网络科学数据资源进行分类并提供导航服务。
关键词:
科学数据; 分类法; 导航; 资源目录
中图分类号:TP3
A Scientific Data Resource Navigation Platform Scheme Based on Multi-facet Keyword and Classification Connection
Abstract
Starting from the taxonomy and related technical theory in the field of library and information science,this paper studies the construction of classification and navigation platform for internet scientific data resource. It employs dynamic faceted classification to organize scientific data resource catalogue, then proposes viable multi-facet classification and keyword connection indexing method, as well as designs ranking scheme based on the weight of classification and keyword connection. The experimental system based on this scheme can classify distributed scientific data resource on the internet effectively and provide navigation service.
Keyword:
Scientific data; Taxonomy; Navigation; Resource catalogue
1 引 言
作为科技资源的一个组成部分,科学数据在我国的采集和积累已经初步形成了以部门为主体与科研院所、高等院校互为补充的格局[ 1]。国家科技基础条件平台、地方各级科学数据共享设施以及行业数据中心为数据资源的存储和共享提供了载体,促进了数据的共享和流通。为更有效地帮助科研人员查找所需的数据,实现跨学科的一站式服务,对其中稳定在线的分散的科学数据资源进行索引、分类并提供导航,构建架构于多个数据中心及科学数据共享设施之上的科学数据导航服务平台成为亟需解决的问题。
科学数据资源导航平台可对科学数据资源进行高层次的揭示。从服务的角度,有以下好处:
(1)分类导航浏览功能,尤其是当用户对某一个主题不熟悉的时候,能通过分类获取感兴趣的信息;
(2)缩小检索范围,从而提高查全率和查准率。
对信息资源统一分类,进行有效识别、导航和定位的理念和技术方法在数字图书馆领域已经比较成熟,但在科学数据资源的管理和共享中则使用较少,因此需要研究分类体系的发展趋势,以便形成可行的科学数据目录分类导航方案。
2 分类体系的发展及科学数据资源分类现状
分类体系(Taxonomy)也称分类系统或分类法,是结构化的、通常是分层的类别分类的集。分类体系可以用来表达多个事件、对象之间的关系[ 2]。传统的分类体系一般采用固定的标准分类方法,先制定标准的分类体系,再将所需要分类的目标放入体系中,缺点是不灵活,如:不能满足网络环境下的一些应用。尽管传统分类法也采用了交替列类、类目注释、附加款目等方法,试图弥补其在此方面的不足,但其应用依然受到限制。新的应用需求产生了许多更加灵活的分类法,如:面分类法、混合分类法等。
2.1 面分类法与混合分类法
常见的分类法有线分类法和面分类法。线分类法又称层次分类法或体系分类法,传统的标准分类方法属于线分类法;面分类法也称多维分类法、轴分类法、组配分类法,按选定的若干属性(或特征)将分类对象按每一属性划分成一组独立的类目,每一组类目构成一个“面”,再按一定顺序将各个“面”平行排列,使用时根据需要将有关“面”中的相应类目按“面”的指定排列顺序组配在一起,形成一个新的复合类目。面分类法可以更准确地对信息从不同的侧面进行描述,多个维度的结合将有效地对信息进行分类,提高检索和标引效率。面分类法体现了人类知识的多维性与概念的多向成族性。
面分类法在一定的领域中得到了应用,国际初级医疗分类法ICPC中的诊断是按二轴(面)进行分类,是面分类法的一种形式,其中一轴(面)是器官系统,另一轴(面)是医疗组成部分。多维组合的水利科学数据分类体系结构,构建了由科学属性、获取方法、数据载体和时空定位组成的多维水利科学数据分类体系,并对其进行了规范化的编码设计[ 3]。
虽然面分类法有很大的灵活性,但在一些应用中又需兼顾线分类的一些设计理论,于是产生了混合分类法。混合分类法的出现是由客观事物的复杂性所决定的[ 4],它是将面分类法和线分类法结合使用的一种形式,以其中一种分类法为主,另一种作补充的分类方法。在中国科学数据共享工程一些平台的实施中,中医药科学数据集采用了面分类法和线分类法相结合的技术路线[ 5];气象资料的分类也采用了混合分类法,即一级分类(大类)采用线分类法,二级分类采用面分类法。混合的分类和组织方式为科学数据资源目录的分类导航开启了新思路。
2.2 我国科学数据分类系统现状
在我国不同学科的科学数据共享系统在建设过程中积极寻求和制定本领域的科学数据的分类方法。科学数据共享工程研制了一系列科学数据分类编码系统,如:《气象资料分类编码和命名规范》、《地震科学数据分类与分级方案》、《地球系统科学数据分类体系》、《医药卫生科学数据分类与编码》等[ 6, 7, 8]。刘林等按照海岸线的自然属性和社会属性对海岸线进行分类编码[ 9]。中国农业科学数据中心的“24大类实用农业科学数据分类大纲”,基本反映了农业科学数据类型的概貌,满足了农业科学数据归类的基本需求[ 10],分类方法上,多数为传统的分类法,也有部分采用分面或混合分类法。整体上,科学数据的分类系统及应用虽取得了一些进展,但不如图书文献分类成熟。
以上分类针对某一学科领域,而科学数据的导航平台需要对多学科的科学数据目录进行整合和共享,在这方面,科学数据共享工程制定了SDS/ T2121-2004《数据分类与编码基础原则与方法》,基于此制定了SDS/T112122-2004《科学数据分类与编码》[ 11],但其实用性有待于进一步探讨。针对科学数据导航平台的建设,需要更灵活的解决方案,符合当前分类法的发展,兼顾效率和灵活性。
3 科学数据导航平台构建技术方案
实现导航的基础是确定分类体系,进而通过一定的技术方法对导航对象进行标引。标引一词,源自图书馆专业的信息/文献标引,原意指分析信息/文献中的内容属性(特征)及相关外表属性,并用特定语言表达分析出的属性或特征,从而赋予信息/文献检索标识的过程。常用的标引有分类标引和主题标引,分类标引实质上就是对信息/文献进行分类,也就是对分类对象进行关联(映射)的过程。
目前,常用的树状学科分类采用线分类法,把对象分配到分类体系中的一个或多个适当类别可能是困难的。分面组配方法具有很强的灵活性和容纳性,能够提供多种检索入口,本方案采取以面分类法为主的混合分类法。另一方面,在网络环境下,分类法的建立及维护必须具有弹性,才能满足多元变动的资源使用者的需求[ 12]。本文所实现的科学数据分类是一个动态的、不断扩充的分类系统,它基于多维自由关键词和动态面分类体系,通过关键词与分类关联,解决多领域科学数据的信息组织分类和导航问题。
本系统有4个关键性的表:分类表、数据目录表、关键词分类映射表、关键词数据映射表。对于整个导航系统,可动态设置多个分维。对于每一个科学数据条目,可以选择为其赋予分别属于三个分维的关键词,科学数据目录表与关键词表是多对多的关系,如图1所示:
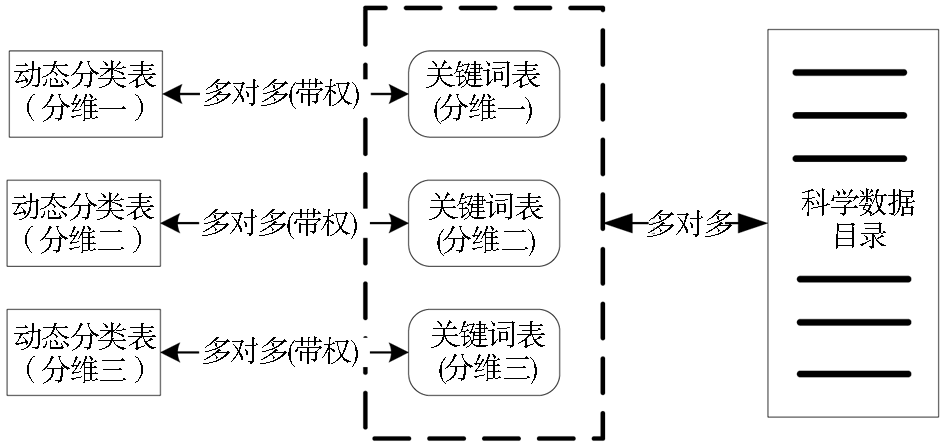 | 图1 多维关键词与分类关联方案 |
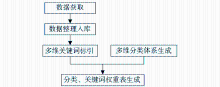
对于设置的分面,要形成针对已有科学数据资源的分类表,此分类表为动态生成,可以方便地进行扩展和修改。第一个分维内的动态分类表与该分维内的关键词表存在多对多的关联关系,为了实现分类后显示结果的合理排序,需要在这一关联建立的时候根据其关联的相似度进行权重赋值。技术路线如图2所示:
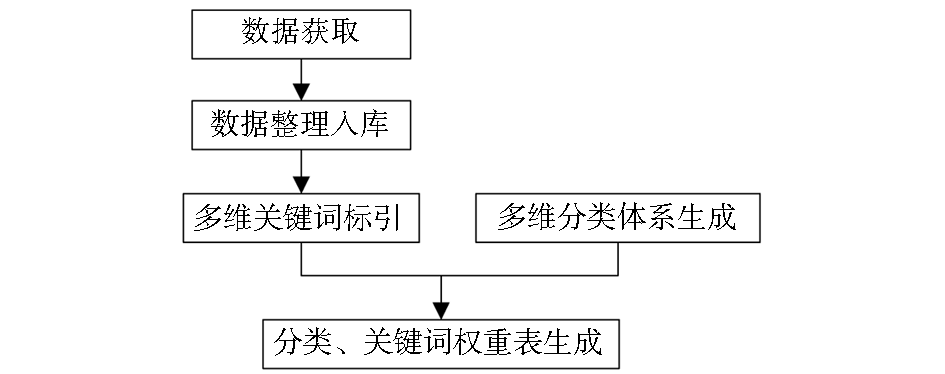 | 图2 平台建设技术方案流程图 |
(1)数据获取
分类对象是指被分类的事物或概念。本文所涉及的分类对象是指存入科学数据目录表中的科学数据的元数据,一条元数据代表一条科学数据集。
为确定中文的科学数据资源的原始发布站点,对我国在线的科学数据资源发布情况进行调查,确定网络科学数据目录的范围,用网络信息抓取的方法下载得到原始的科学数据目录资源。
(2)数据整理及入库
收集的科学数据元数据的预处理和质量控制,包括对重复发布、内容相近条目的合并,不同尺度、粒度科学数据目录的整合,空间和时间维度的合并;同时也包括对数据完整性、错误以及其他一些必要的质量控制。在完成上述步骤后,提取不同来源的科学数据资源核心元数据项作为描述其各种属性和特征数据的基本集合,包括内容信息(例如摘要)、管理信息(例如负责单位等)、获取方式信息(例如在线获取地址等),将其存储在科学数据目录表中。
(3)多维分类体系的动态生成
根据已有的科学数据目录,依据专家知识提取合理的分面(维),并参考领域知识动态建立本分面内的科学数据的目录体系,目录体系可进行垂直和水平扩展。首选的维度如主题、地区、时间、事件(项目)、人员、机构等,另外,对于不同的学科或不同应用数据资源的特点,针对所拥有不同学科的数据资源制定特有的分维,最终形成以分面为主的动态分类树。
(4)多维关键词标引
完成对科学数据目录的主题标引,有多少个分类维度就有多少个关键词维度。关键词标引限于对资源的题名、标题、摘要和资源外部特征的抽词,标引结果存入关键词数据映射表中。
(5)分类、关键词关联及权重生成
分类系统与分类对象的条目关联是目录有机化及走向实用化的重要步骤,通过关键词来实现科学数据目录与多维分类体系的关联。为使分类结果体现出顺序性,实现在分类上选择某一个分支或结点时,列出的关联项目可以按照一定的权重来进行排列,引入专家打分的权重机制。权重也称为得分,是指可以分配给对象的任何数值,得分可以是由公式所确定的数值,也可以根据规则来产生。
关键词分类体系映射表,如表1所示:
| 表1 关键词分类体系映射表 |
除了关键词和所属分类外,设定关键词与分类的映射权重字段,此值在0.01-1之间。当用户选取一个分类维度的一个分支时,在关键词分类映射表中寻找与此分类相关的关键词,然后依据找到的关键词在关键词数据映射表中寻找相应的数据,相关的数据排序则需要计算一个Order值。设关键词与分类关联时所设的权重为w,当选择某一个领域的某一个分类分支时,具体某一关联数据的排序值Order可以通过与这一分类分支关联的关键词权重的平方和计算得到,公式如下所示:
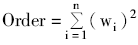
当需要对全局数据进行输出或对多个分类分支或分维进行过滤时,只需将关键词扩展到所需要的分支和分维,可以用Cache、索引等技术实现。
步骤(3)到步骤(5)这一流程可以重复进行,在不断的标引过程中逐渐丰富和完善分类体系以及关键词,并完成二者之间的关联,关键词越多,分类表越完善,则科学数据的分类标引越精确,反映到平台上则更容易找到想要的数据。
本方案在科技信息资源整合共享及综合服务体系建设——基于DOI的科学数据目录数据库建设项目中得到应用,构建的实验系统能够对系统收集整理的科学数据目录信息进行很好的分类和组织,为我国在线的科学数据资源进行导航。
4 实验系统开发与实现
4.1 开发环境与架构
系统采用JavaEE架构,基于B/S模式,应用服务器为Tomcat,底层数据库采用Oracle 11g,开发工具为MyEclipse V5.5,运行于Windows 2008 Server操作系统环境中。
系统分为三层:借助Struts实现的Web表现层、借助Spring Framework进行业务组件的组装关联实现的业务层和借助Hibernate实现的持久层和域对象层。
4.2 后台功能实现
后台功能主要实现多维关键词标引、多维分类体系管理、关键词与分类体系关联。由于同时考虑了数据所关联期刊文献信息的展示与分类,因此,从功能模块划分为以下三个部分:
(1)科学数据元数据管理:对科学数据元数据进行增加、修改、删除等基本操作,对其进行分维度的关键词标引,计算排序权重。
(2)文献数据管理:对文献摘录信息进行增加、修改、删除等基本操作,对其进行分维度的关键词标引,计算排序权重。
(3)多维分类体系管理:包括对动态多维分类体系进行增加、修改、删除等功能,关键词与分类的映射管理等。
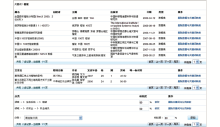
多维关键词分类关联的操作界面,如图3所示:
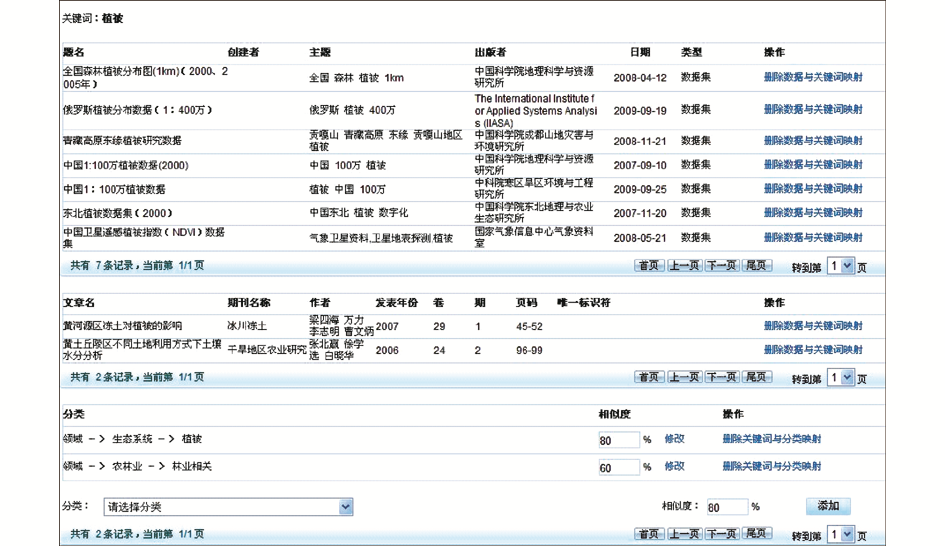 | 图3 多维关键词与分类映射操作界面 |
对于属于“领域”这一维度的关键词“植被”,可以看到被标引的7条科学数据与两条文献。已经有两个分类分支与“植被”这一关键词相关联,并且分别标注了相似度,最后一行可以添加新的分类关联,供选择的分类分支只限于“领域”这一维度,更多的关联将增强数据分类的可靠性。
4.3 前台及核心功能展示
实验系统的前台主要实现了目录导航和元数据展示。根据实验数据的特点,分为4个维度进行分类:领域、时间、地区、来源及格式,如图4所示:
 | 图4 多维分类导航系统界面 |
前台界面右侧区域可以显示出由经左侧多维分类体系过滤后的科学数据列表和文献列表,图4所示的是地区为全国范围,领域为基础地理的数据。当点击其中一条数据或文献时,可以查看其详细信息。对于科学数据,还有原始科学数据发布页面的链接,以便用户迅速地查看感兴趣的数据详情或进一步获取数据体。详细信息页面下部列出了与这条数据相关联的文献和科学数据,这些关联信息便于用户找到更为满意的结果。
通过网络采集等方式,目前已经收集了1 367条科学数据目录和238条相关的期刊论文文献信息。数据的领域涉及到地球系统、生态系统、交通、气象、农林业、海洋等。与其他数据中心的分类导航系统相比,该系统表现出了良好的性能和灵活性。
5 结 语
本文研究科学数据资源目录整合、分类以及导航机制,探讨关键技术的实现;对科学数据资源目录的关键词标引与分类等技术方案进行探索,将图书文献领域的相关应用实例、技术方法应用于科学数据资源目录的管理及组织中;结合科学数据目录库的项目建设实践,构建为科研人员提供科学数据资源快速导航和链接服务的网络平台,方便信息的获取,促进科学数据的共享,对我国科技资源使用及增值服务模式的探索有很强的指导意义。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|