{kind=link}
{kind=link}
本体集成方法和工具综述*
引用本文
于晓繁, 王效岳, 白如江. 本体集成方法和工具综述* . 现代图书情报技术, 2011, 27(1): 14-21
Yu Xiaofan, Wang Xiaoyue, Bai Rujiang. Review on the Methods and Tools for Ontology Integration. 现代图书情报技术, 2011, 27(1): 14-21
Permissions
Yu Xiaofan, Wang Xiaoyue, Bai Rujiang. Review on the Methods and Tools for Ontology Integration. 现代图书情报技术, 2011, 27(1): 14-21
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
本体集成方法和工具综述*
关键词:
本体集成; 集成方法; 集成工具
中图分类号:TP311
Review on the Methods and Tools for Ontology Integration
Abstract
Ontology integration is a process that can eliminate Ontology heterogeneous, so as to achieve the highest level of semantic communication and semantic integration, and finally achieve knowledge reuse and interoperability. The paper reviews the four main methods and the five main tools for Ontology integration, and gives some comparative analysis.
Keyword:
Ontology integration; Integration methods; Integration tools
1 引 言
1993年,Gruber等对本体进行深入研究后给出了一个比较明确、全面、概括的概念,他们认为本体是“共享概念模型的明确的形式化规范说明”[ 1]。本体的目的是实现领域知识的共享和重用,它在人们与组织的信息和知识交流中起了非常重要的作用,在多个领域取得了广泛的应用。但是,随着应用领域的扩大和本体描述语言的发展,本体的数量和规模激增,由于本体创建者的不同和使用的本体建模方法的不同,即使同一领域问题的建模,不同的专家开发出的本体也存在差别,不同的人和组织倾向于使用不同的本体。因此,为了交流信息和知识,解决多专业、跨领域应用的协同异构信息交换,达到知识的重用和互操作,需要采用相同的本体,或者是集成不同的本体。这就决定了本体集成研究的必要性,并直接导致了本体集成的复杂性。
2 研究背景
欧洲委员会于2001年启动的SWAP(Semantic Web and Peer-to-peer)项目[ 2]发现了本体集成问题。该项目发现了将多个不同团队构建的不同小本体集成为大本体时的本体映射和本体合并问题[ 3]。另外,欧洲委员会资助的另一个项目SEKT(Semantically Enabled Knowledge Technologies)[ 4]也发现了本质上的问题,他们需要找出本体间的关系,实现本体之间的交互,以达成基于这些本体的数据的重用和互操作[ 5]。
国外关于本体集成研究的总体状况是:实力较强的研究团队多、研究项目多、研究范围广泛、研究成果丰富、使用系统的研发增多,更倾向于生物和医药方面的本体集成的研究。Klein从本体语言的语法角度研究了本体集成,并从语义角度研究了本体集成可能存在的语义不匹配[ 6];Wache等从本体集成的体系结构角度研究了信息源集成的三种方式,并分析了各种方式的优缺点[ 7];Mitra介绍了关联本体库的概念并提出了本体代数[ 8]。通过对本体集成涉及关键技术的分析,对全局本体库和关联本体库进行了描述,给出了相应的集成步骤。ONIONS项目的研究人员Gangemi等介绍了一种集成大量重要的医学术语的本体集成方法ONIONS[ 9]。生物医学信息学团队、人工智能实验室的Pérez-Rey等介绍了一种集成基因组和临床数据数据库的本体集成方法ONTOFUSION[ 10]。人工智能实验室的Pinto等阐明了集成和本体集成的一些概念,并且展示了集成的一些相关工作,辨析了与本体集成过程有关的三个概念:Integration、Merge和Use[ 11]。Napier大学 计算机学院的Keet以生物学为例阐述了本体集成的几个重要方面[ 12]。
国内的本体集成研究虽晚于国外,但近年来这方面的研究也取得了一定进展,主要特点是:研究单位逐渐增多,并形成了一些研究团队;研究理论逐渐增多,囊括了本体集成基本理论、方法、评估等多个方面;系统方面出现了一些在国际上有一定影响的本体映射系统。范莉娅等介绍了包括本体集成方法的语义强度、信息的丰富性、集成层次的深入性和方法的适应性4个方面的评价指标体系,并对文法层、Chimaera、PROMPT、FCA-Merge和IF-Map等5种典型的本体集成方法进行了评价[ 13]。卢胜军等对本体匹配、本体映射、本体联结、本体融合、本体集成以及本体协同等相关概念进行了分析,并给出了重要概念的较为准确的定义[ 14]。于娟等介绍了本体集成的相关概念,给出了集成的一般化工程化方法,并对国内外有代表性的本体集成工具进行了比较分析[ 15]。
本文介绍了本体集成的问题、本体异质、本体集成的基本框架、方法和工具,并对4种集成方法和5种集成工具进行了比较分析。
3 本体集成
3.1 本体集成的问题及本体异质
本体集成(Ontology Integration)是指使用己经存在的不同主题的本体建立一个范围更广或更具体的本体,本质上讲,就是消除本体语义异质、实现语义通信并达到最高层级的语义融合的过程。在集成过程中,将两个或多个本体中的知识以一种统一的形式表示在新的本体中,如果原本体由于某种原因需要调整,其直接或间接引用的本体也需要进行相应的更新。文献[14]对本体集成和本体融合的概念问题进行了探讨,认为本体集成是比本体融合更为广泛的概念,不能强加条件、限定使用范围,也不能无条件限制地混用滥用,强调本体融合的“归并、合并”的特点和本体集成的“一体化、综合”的特点。笔者没有刻意地区分本体集成和本体融合,一概用本体集成来描述。
本体集成的问题在于不同组织机构开发的本体描述的领域可能相关或重叠、采用的语言和组织方式不同、对领域知识描述的侧重点和详细程度不同、存储格式不同,从而导致了本体异质,形成了大量异构本体。参考文献[15]和[16],根据本体异质产生的原因将其划分为5个层次:表示层、术语层、概念层、语义层和系统层,如表1所示:
| 表1 本体异质 |
本体集成主要解决两类问题:构建新本体时重用现有本体,实现对本体及其结构的持续改进和丰富;跨领域应用本体知识时,对不同领域本体进行集成,以解决不同应用间的信息异构问题。
3.2 本体集成的基本框架
本体集成框架[ 17]主要包括3个部分:异质本体层、中间层和用户层。
(1)异质本体层,包括不同的异质的领域本体,是集成的对象。
(2)中间层,实现本体的管理,包括本体映射管理、本体查询管理和通信平台。本体映射管理主要是本体的范化、本体映射的生成和进化,以实现异构本体之间的互操作。它包括:本体范化插件、范化本体库、近义词汇库、本体语义映射生成器和本体映射库。本体范化插件根据各个异质本体的存储形式不同,把各个异质本体转化为标准形式,只需要概念、属性以及它们之间的语义、层次关系的信息,不涉及具体的实例。范化本体库存储范化后的本体。本体映射的实现需要计算本体元素的相似度,所以需要构建一个近义词汇库。范化本体输入到本体语义映射生成器,根据近义词汇库,输出本体映射集,把映射集存放在本体映射库里。本体查询管理包括:查询扩展器、查询转换器、查询插件和查询结果集成器。根据本体映射库,查询扩展器把查询扩展为相关领域本体的查询,查询转换器把各个查询转换成各个领域本体的查询语言,再把各个领域本体的查询结果集成反馈给用户。通信平台负责领域本体、本体范化插件、本体语义映射生成器和领域专家之间的通信。
(3)用户层,包括用户和领域专家。用户选择某个领域本体,提出查询需求,查询与这个领域本体相关的本体信息。领域专家管理本体的映射,负责近义词汇库的建立和管理、本体映射算法的制定以及对本体自动映射后产生的映射库进行修正和管理。
本体集成的4个主要阶段包括:
①分析领域本体。根据各个领域本体的存储方式,编写本体范化插件和查询插件,领域专家制定该领域近义词汇库。
②确定映射法则。根据上一阶段的分析,确定本体映射算法和映射修正规则。映射算法主要用于本体的自动映射,映射修正规则用于帮助领域专家对自动生成的映射进行修正。
③建立映射。领域本体通过本体范化插件生成范化本体,并把它们存到范化本体库中。根据映射算法规则,为每个范化本体建立映射集,并将它们存到本体映射库中,领域专家再对其进行修正。当领域本体发生变更时,即时更新对应的映射集。
④本体查询。选择入口领域本体,从这个本体出发,根据本体映射库中该本体的映射集,查询整个领域本体。
4 本体集成的主要方法
4.1 主要本体集成方法介绍
(1)基于WCONS的本体集成
①WCONS
WCONS[ 18](Word and CONtext Similarity)是卢胜军等提出的,它是一种基于词语和语境相似度的本体映射方法,其依据是:词语相似度和语境相似度表现本体概念的语义相似度,语境相似度起决定作用;词语相似度较高而语境相异度较低的概念的语义相似度较高,词语相似度较低但语境相似度较高的概念的语义可能相似,这两种情况都可能产生映射[ 19]。WCONS将概念语境分为结构面、关系面、属性面、实例面4个分面语境,比较充分地考虑了语境对概念语义的作用,通过采用Levenshtein距离[ 20]与Tversky相似度模型[ 21]等语义相似度度量方法来计算概念间的映射关系。
②WCONS+解决的问题
在WCONS的基础上提出了本体集成方法:WCONS+。WCONS+方法解决的主要问题是通过发掘两个领域本体中的概念与概念、关系与关系、属性与属性等同类元素间的等同关系的映射,实现两个领域本体的有效集成。也就是说,WCONS+仅讨论两个同一领域或相关领域的、具有重叠部分的本体的集成,且仅限于两个本体中概念与概念、关系与关系、属性与属性这三种相同类型元素间的等同关系的映射。现阶段,WCONS+针对的仅是采用OWL DL描述的领域本体。
③WCONS+的过程
WCONS+方法是本体集成基本过程的深化和重组,它分为准备、映射、集成和检测4个阶段。
1)准备阶段:获取可用于集成的领域本体,并为消除本体语言方面的异质障碍做好准备;
2)映射阶段:计算两个本体中同类型元素间的语义相似度,发掘、选择及确定相互匹配的概念,采用WCONS方法进行概念、关系与属性等元素的映射,最终产生元素间的映射;
3)集成阶段:本体集成操作时实现本体元素集成的基本工作,依据PROMPT、Chimaera等工具,WCONS+方法提出者设计了6种基本集成操作和25种具体集成操作,依据本体元素间的映射关系类型,结合本体集成工具,对本体元素执行添加、删除、修改和合并等类型的集成操作,最终实现本体集成;
4)检测阶段:集成后的结果本体必须检测知识的一致性和连贯性,采用推理机推理、对照比较领域知识和领域专家评估等方式消除集成后本体中存在的矛盾知识。
WCONS+准备阶段针对的是语言层上可能出现的异质问题,映射阶段主要是解决本体层上的异质问题,集成阶段是使本体以紧密的形式无障碍、无中介地进行语义通信,并能执行语义推理,实现知识的完全融合,产生集成的本体,检测阶段是对上述阶段的校验、论证和总结,最终构建具有较高质量的本体。
(2)基于RDFS闭包的本体集成
①RDFS
资源描述框架(Resource Description Framework,RDF)是由W3C自1999年开始开发的,目的是为了创建描述Web资源的元数据,它是表述对象及对象之间二元关系的语言规范,是一个网络资源对象和其间关系的数据模型,拥有简单的语义,该数据模型可由XML语法编码。RDF同时也是一种基本的本体描述语言,是语义网表示语义信息的基础[ 22]。RDFS[ 23](Resource Description Framework Schema)是基于XML对RDF的实现,是一种扩展了XML的符号和语法后形成的语言,是用来描述RDF资源的属性和类型的词汇集描述语言,可以看作是RDF的扩展和补充。RDFS是一种定义RDF Schemas的声明语言,它的数据模型是基于框架的,为定义属性与资源之间的关系提供了机制,核心的概念/类是类、资源和属性。RDF Schema支持从客观世界到抽象世界的映射,为知识共享打下基础。
RDFS的基本结构是声明三元组的集合,其数据模型由资源(Resource)、属性(Property)和声明(Statement)三部分构成。一个特定的资源加上其属性、属性值就是一个RDFS的声明,这三个个性化的部分分别叫做主体、谓词和客体。RDFS本体可用具有节点和有向边的有向图来表示[ 24]。
②基于RDFS本体集成方法的过程
RDFS能够描述子类与父类及关系间的蕴含特征,使RDFS描述的本体具有一定的推理能力。Hayes总结了一系列关于RDFS的公理,其中包括13条推理规则[ 25],对这13条推理规则进行扩展形成了9条扩展规则,利用这些规则对已有的RDFS声明进行新的RDFS声明,新的RDFS声明可以看作是原RDFS本体中隐含知识的显示说明。RDFS模型中所有显示的和隐含的声明统称为RDFS模型的闭包[ 26]。循环地应用推理规则和扩展规则,如果有声明满足这些规则中的一条,则生成新的声明,将新的声明添加到原有声明中;直到所有声明都不满足推理规则的触发条件,停止循环。这时所有声明组成了RDFS的本体图闭包。
通过对RDFS本体的研究,提出了一种基于RDFS图闭包的本体集成算法BRCOIA (Based RDFS Closure Ontology Integration Algorithm),过程为:本体的解析和过滤,使用Jena中的ARP(Another RDF Parser)工具将不同本体定义语言(如OWL、DAML+OIL等)描述的本体统一转换成易于推理和检索的RDFS三元组描述的形式,并对生成的三元组进行过滤,去掉没有意义的空节点;RDFS图闭包生成,RDFS模型的闭包中包含所有显示的和隐含的声明,在RDFS图闭包的基础上进行本体的集成,可以保留更多的领域知识,循环推理规则和扩展规则,产生RDFS图闭包;相似性评估,生成图闭包后,进行本体间实体的相似度计算;本体推理映射,主要考虑4种映射:类等价、类包含、属性等价、属性蕴含,并用推理结果去修正初始相似度;本体剪枝,经上述步骤得到虚拟本体,虚拟本体是已经建立了映射联系,但还没有对源本体中没有用到的类、实例、关系等进行删除操作。该步骤进行剪枝操作后就得到了最终的本体。
(3) ONTOFUSION
①ONTOFUSION
ONTOFUSION[ 10]是基于本体的生物医学数据库集成系统方法,它有两个过程:映射和联合。映射是用虚拟模式命名的概念框架本体链接数据库模式的半自动化的过程,有三种方法可以获得虚拟模式:自顶向下,利用已存在的本体,如UMLS或者Gene本体;自底向上,建立一个新的领域本体;混合组合。联合是一个自动化的集成本体的过程,之后数据库就可以链接到数据。基于这些方法提出了ONTOFUSION来集成大规模的基因组、临床数据库和生物医学本体。
ONTOFUSION系统构建在多Agent系统JADE基础上,共有4个模块:用户界面、词表服务模块、中介器模块和数据访问模块。系统的核心模块是中介器模块,负责提供对各异构数据库的一致性访问。词表服务模块负责维护和提供医学和遗传学本体,数据访问模块实现对公共和私有生物医学数据库的查询,用户界面模块包括用户接口和管理模块。ONTOFUSION系统采用了多Agent架构,使得其各个模块可以运行于不同的计算机上,增强了系统的并行处理能力和灵活性。ONTOFUSION系统提供了独立的词表服务模块,既可以用于数据集成,完成各异构数据库模式之间的映射,又可以直接为用户提供本体数据,使词表服务模块的复用性得到充分体现。
②ONTOFUSION方法的过程
ONTOFUSION的集成过程:构建虚拟模式,本方法提出者开发了一种映射工具来促进虚拟模式元素从相应的领域本体中获得,然后物理数据库的图表和属性与虚拟模式的元素相映射,这些关系用XML进行存储,虚拟模式为物理数据库提供了新的视角,对于转换用户查询到物理数据库的查询提供了方法;虚拟模式的统一,这个统一过程是完全自动化的,管理者用统一工具在虚拟模式群里选择一套有效的、能用来开发新的虚拟模式的模式;用户界面,ONTOFUSION界面是一个本体导航,用户利用这个程序能浏览物理和虚拟数据库的本体;系统评估。
(4) ONIONS
①ONIONS
ONIONS[ 9](ONtologic Integration Of Naïve Sources)是意大利国家研究委员会项目SOLMC(Ontologic and Linguistic Tools for Conceptual Modeling)[ 27]资金支持的,它是从异质概念的存储方面来集成术语知识的一种方法论,这种方法论建立在哲学基础上以解决语义问题。ONIONS建立了一个一般性的概括和集成用于组织一套术语资源定义的框架。也就是说,它能够连贯地解决每个资源的领域术语本体,而且能够与其他术语源比较并映射到集成本体库中。目前ONIONS应用在大量相关的医学术语本体的集成项目中。
ONIONS的目标包括:开发一套完备的通用本体来支持医学领域相关本体的集成,目前医学本体缺少公理化、语义精度和本体论机智;集成一套在形式上和概念上都令人满意的领域本体来支持一些任务,如信息检索、自然语言处理、计算机化指导方针的形成和数据库集成等;为本体建设中的概念映射、约束限制和选择提供一个明确的表示,以便于扩展和更新。
ONIONS工具包括一套形式体系,一套能实现和支持形式体系使用的计算工具,一套为了形式体系从正式或者非正式情形的文献中提取、转换或者更新的通用本体。ONIONS的主要产品是:通用本体ON9库、IMO(Integrated Medical Ontology)和一些医学存储库的形式化表示。
②ONIONS方法的过程
ONIONS是一种分析和集成领域本体的方法,它的过程是:建立一个某个领域经过验证的文本资源语料库,这些资源必须根据领域社团的扩散和验证断言有区别地放在一起;分类分析,如果没有,就要构建分类学标准;局部资源分析,术语的概念分析以定位自由文本的描述和其他约束条件;多元局部资源分析,描述的概念分析允许链接局部定义和多元局部概念和范例;建立一个集成本体库,一个本体库包括用于构建多元局部和集成定义的局部定义和范例;执行和分类本体库。这些步骤适合于传播、使用、分类和验证模型。
4.2 主要本体集成方法的比较
主要本体集成方法的比较,如表2所示:
| 表2 主要的本体集成方法的比较 |
基于WCONS的本体集成和基于RDFS闭包的本体集成是国内提出的本体集成方法,相对于国外提出的本体集成方法,它们没有基金项目的支持,仅仅是方法模型,只是在小型的本体测试集上是有效的,试验使用的本体的规模极其有限,当面对真正的本体时,这些方法的有效性难以保证。ONTOFUSION和ONIONS是国外开发的本体集成方法,它们已经是相对成熟的方法,在生物医学数据库的集成方面起着重要的作用。
5 本体集成的主要工具
5.1 主要本体集成工具的介绍
由于本体集成是由国外最先开始研究的,所以国外本体集成的研究要比国内成熟,并且也开发出了一些集成工具,例如:Ariadne、PROMPT、InfoSleuth、MAFRA、OBSERVER、OntoMerge、RDFT、GLUE、MOMIS等。本文选取了5种工具进行了分析比较:Ariadne、InfoSleuth、OntoMerge、RDFT、MOMIS。
(1) Ariadne
Ariadne[ 28](http://www.ariadne-eu.org/)是GLOBE(Global Learning Objects Brokered Exchange)的一部分,由南加利福尼亚大学的信息科学研究室开发,如图1所示。
Ariadne是网络的内容管理系统和应用框架,用来快速构造智能Agent从网络资源中进行抽取、查询和集成数据,它是一个由PHP构建的丰富的用户界面,包括:向导、下拉菜单和WYSIWYG HTML编辑器。
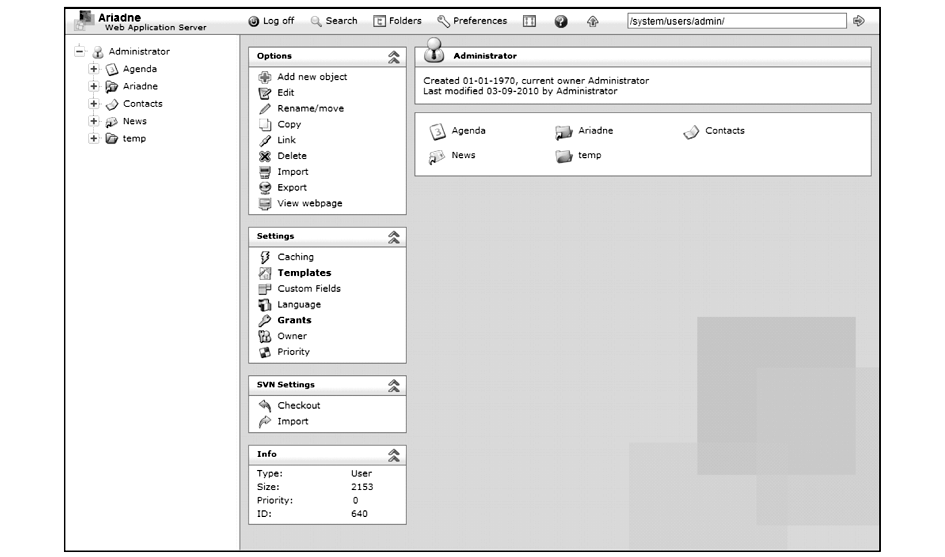 | 图1 Ariadne |
Ariadne支持MySQL, PostgreSQL和MS SQL。它致力于改善服务和信息管理决策系统 (Service and Information Management for decision Systems,SIMS),提供对半结构化信息(如网页)的管理。使用Ariadne信息Mediator存取不同信息。Mediator用来建立本体和信息源之间的映射。
(2) InfoSleuth
InfoSleuth[ 29](http://www.argreenhouse.com/InfoSleuth/index.shtml)是MCC(Microelectronics and Computer Technology Corporation)的一项科研项目,采用了多Agent的体系结构、领域本体、服务匹配和网络计算等技术,并支持动态开放环境中数据和服务的互操作。多Agent的体系结构由一组可以互相通信的Agent构成,每一个Agent负责系统某一方面的功能,Agent之间可以通过KQML(Knowledge Query Manipulation Language)进行通信。InfoSleuth中存在多个不同的本体,一部分在信息源间共享,提供某种“全局”概念视图,一部分只与某一特定的信息源关联。本体Agent中存有这些本体的信息,并能够响应以KIF(Knowledge Interchange Format)形式提出的关于本体信息的查询。
(3) OntoMerge
OntoMerge(http://cs-www.cs.yale.edu/homes/dvm/daml/ontology-translation.html)是2002年耶鲁大学研发的,这是一种通过本体合并实现本体翻译的方法,也是一种本体集成方法。这种方法通过公理语义的计算对不同本体进行合并。合并过程首先对所有的术语根据名称空间的差异进行区分,然后使用“桥公理(Bridging Axioms)”[ 30]连接两个本体中的重叠部分。在这种集成工具中,两个相关本体的合并通过合并两个本体的术语和定义术语的公理,然后在本体中添加连接两个本体中相关术语的桥公理来实现。OntoMerge中包含半自动化的产生桥公理的工具,产生出来的公理需要经过专家的确认。
(4) RDFT
Omelayenko和Fensel假定了不同组织在XML文档里制定的产品分类。产品分类的集成技术是双层的,因为产品信息用XML表示,而不同表示形式的转换由RDF来完成。为了描述RDF文档间的转换,定义了一个映射元本体[ 31]。这个映射元本体叫做RDFT,它使用RDF Schema指定并且用来描述两个RDFS本体间的映射。此外,Omelayenko描述了一种基于一个Naïve Bayes分类器在不同产品分类模式间发现语义一致性的技术。
(5) MOMIS
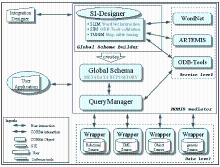
MOMIS(Mediator envirOnment for Multiple Information Sources)(http://www.dbgroup.unimo.it/Momis/)项目由Modena大学的Bergamaschi教授指导,在INTERDATA和D2I意大利国家研究项目的基础上研发的[ 32],是一个实现从结构化和半结构化数据资源中提取和集成信息的框架,利用面向对象的语言和描述逻辑(ODL-13)从标准ODMG中进行信息提取。信息集成是半自动的方式,使用由局部数据模型合并产生的全局本体来集成异构数据源。使用ARTEMIS工具来合并本体。ARTEMIS工具进行匹配来决定本体间术语的相似性。基于常见的Wrapper/Mediator体系结构的MOMIS提供的方法和工具在基于网络的信息系统中用CORBA-2[ 33]界面实现了数据的管理。MOMIS的原型系统架构如图2所示:
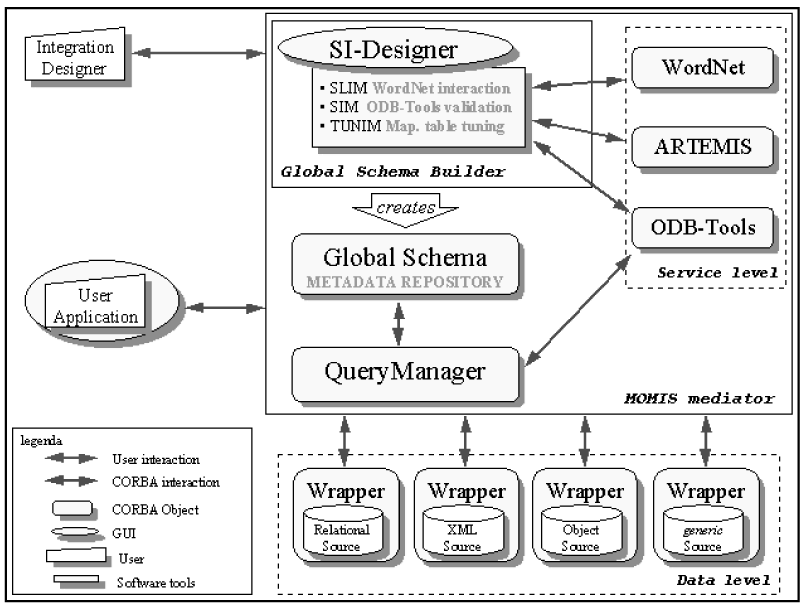 | 图2 MOMIS的原型系统架构[ 33] |
5.2 主要本体集成工具的比较
笔者从以下几个方面分析比较现有本体集成工具:映射范围;映射方法;用自动或半自动化的方法来发现本体间的相似或不同,自动化的强弱;考虑本体进化对后期本体集成的影响的强弱;本体集成系统的可扩展性的强弱;支持语言;人机交互方式。主要本体集成工具的比较如表3所示(表格中强弱指标的设置参考文献[34]):
| 表3 主要的本体集成工具的比较 |
由表3可以看出,Ariadne和MOMIS能有效地支持系统的可扩展性,但是它们在系统的自动化程度以及对本体的进化考虑方面仍存在一些不足。InfoSleuth和OntoMerge在本体的自动化程度方面相对其他的工具较强,但是它们的扩展性及对本体进化的考虑较弱。RDFT和OntoMerge的映射范围相比其他的较广。由于本体映射方法大多不涉及语言层面,因此,对国外的集成工具稍加改动都可以用于中文本体的集成。
6 结语
本体集成作为本体工程的重要技术之一,能够实现本体或基于本体的软件间的通信和语义互操作,能够用于构建、维护与扩展本体或知识库,是本体研究的重要方向。但是本体集成是关于语义的集成,是一个非常复杂的过程,集成过程中会产生各种问题。到目前为止,仍没有理想的本体集成方法和工具,因此研究的空间很大。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|