

{kind=link}
{kind=link}
{kind=link}
相关文献检索研究综述
引用本文
王军辉, 胡铁军, 李丹亚. 相关文献检索研究综述. 现代图书情报技术, 2011, 27(1): 39-45
Wang Junhui, Hu Tiejun, Li Danya. Research Review of Related Articles Retrieval. 现代图书情报技术, 2011, 27(1): 39-45
Permissions
Wang Junhui, Hu Tiejun, Li Danya. Research Review of Related Articles Retrieval. 现代图书情报技术, 2011, 27(1): 39-45
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
相关文献检索研究综述
摘要
从文献计量学角度对相关文献检索进行分类,分析其在具体实现过程中涉及到的关键技术,重点阐述PubMed和CBM相关文献检索的文本相似度计算方法、主要研究历程及最新研究进展,在对相关文献检索的评价方法和评价指标进行概述的基础上,从正反两方面对其效用进行分析,最后简要论述其发展方向。
关键词:
相关文献; 相关文献检索; 文本相似度计算; 文献相关性数据库; 相关知识
中图分类号:G254
Research Review of Related Articles Retrieval
Abstract
This paper classifies the related articles retrieval from the perspective of bibliometrics, analyzes the key technologies involved in the process of implementation, and focuses on the text similarity computation algorithm, main research course and recent progress in the system of PubMed and CBM. Based on outlining the evaluation methods and indicators, the paper analyzes the effectiveness of related articles retrieval from both positive and negative aspects.Finally, it discusses the development direction of related articles retrieval.
Keyword:
Related articles; Related articles retrieval; Text similarity computation; Related articles database; Related knowledge
1 引 言
科技文献在数量上呈指数增长,而在内容上却日趋交叉分散,这对文献数据库检索系统的建设提出了更高的要求。作为信息检索系统的一种具体形式或功能,相关文献检索(Related Articles Retrieval, RAR)特指根据某篇文献检索其相关文献(Related Articles)的过程。它不需要用户输入查询表达式,一般通过点击相应超链接,针对数据库中的每篇文献,按照特定的策略,返回一定数量的相关文献。相关文献检索在具体应用中一般以“相关文章”、“相似文献”、“Related Articles”及“Related Records”等形式存在,无论用户通过何种途径发现了一篇其所需要的文献,只需点击相关文献链接即可找到更多的相关文献,而不需要反复地修改检索词和调整检索策略。相关文献检索在一定程度上可以简化检索过程,降低检索技能较低用户获取信息的难度,同时,由于可以揭示传统检索方式所不能揭示的更多文献,有利于提高查全率,是对已有检索系统功能的完善和补充。
目前,国内外专门针对相关文献检索的研究很少,如表1所示。但相关文献检索实现的机制和存在的价值已引起越来越多的关注,因此有必要对当前的研究进行系统的梳理。
| 表1 三个数据库的检索结果 |
2 相关文献检索的分类和关键技术
从文献计量学角度分析,相关文献检索可以分为基于外部特征(著者、研究机构、出处以及参考文献等)和基于内容特征(作者关键词、文本关键词、主题词、分类号)两种基本类型。按照来源字段不同,内容相关文献检索又可分为简单内容相关文献检索和完全内容相关文献检索,前者只基于关键词或主题词或分类号,后者则是综合考虑多种内容特征项[ 1]。
2.1 基于外部或简单内容特征
基于外部特征或简单内容特征的相关文献检索,一般都是先提取源文献相应的检索字段,再到数据库中重新进行二次检索。例如,ISI Web of Science的“Related Records”返回的是当前文献的所有耦合文献;Embase[ 2]的“Related Articles”是将当前文献的主要医学主题词和药物主题词进行组合,重新进行一次“OR”检索;万方的“相似文献”是基于当前文献作者关键词的重新检索。上述相关文献检索均不需要预先进行处理,检索过程都是实时的,系统实现比较容易。
根据检索字段的不同,基于简单内容特征的相关文献检索涉及到分类标引、主题标引和关键词标引三种标引技术。目前,在实际应用的系统中,以人机结合的半自动标引为主,或称为计算机辅助下的人工标引。由于人为因素的影响,不同标引人员主观选择的差异会直接导致相关文献检索结果揭示上的差异,因此自动标引技术的发展应用对相关文献检索结果有重要影响。
2.2 基于完全内容特征
基于完全内容特征的相关文献检索由于涉及的特征项较多,需要通过文本相似度计算(Text Similarity Computation)的方法来实现,由于计算过程非常复杂且耗时,这种相关文献检索功能的实现需要经过预先处理,在建立文献相关性数据库(Related Articles Database, RAD)[ 3]的基础上提供服务。采用这种实现方式的典型代表是PubMed[ 4]的“Related Articles”功能。
文本相似度计算涉及到数学模型和相似计算公式的选择、特征项权重赋值和相似计算的时间复杂度等一系列技术问题。各种相似计算公式和权重赋值方法可以组合成不同的文本相似度计算方法。将文本相似度计算的结果存储到数据库中就构成文献相关性数据库,它将文献的所有相关文献按照与该文献的相似度值从高到低的顺序进行存储,并在提供检索服务时加以显示。
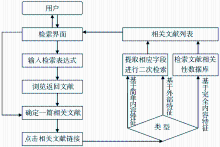
各种类型的相关文献检索工作流程如图1所示:
 | 图1 相关文献检索流程其中基于完全内容特征的相关文献检索是本文分析的主要类型,下文若无说明,均默认为该类型。 |
3 国内外研究进展
国外相关文献检索研究主要是美国国立医学图书馆基于PubMed开展的系列研究,其余的研究均是在PubMed“Related Articles”基础上进行的;国内主要是中国医学科学院医学信息研究所基于中国生物医学文献数据库(CBM)[ 5]开展的构建中文医学文献相关性数据库的系列研究,其是对PubMed“Related Articles”实现机制解析,并结合中文生物医学文本的特点进行的实践。
3.1 国外相关文献检索研究
(1) PubMed相关文献检索研究
PubMed在1997年推出之初就提供了相关文献检索功能,并在实际应用过程中不断完善,其中,较大的一次改进是2006年对文本相似度计算方法的优化。
① 优化前的算法
PubMed最初的文本相似度计算公式是基于向量空间模型(Vector Space Model, VSM)的夹角余弦公式。内容特征项包括MeSH主题词和从题名、摘要中抽取的文本关键词,其中每个特征项都有一个局域权值(Local Weight)和一个广域权值(Global Weight)。局域权值用来衡量特征项在一篇文献内部的重要程度,主要基于出现的频次,并进行了标准化处理,计算公式[ 6]如下:
lwit=0.5+0.5×mitmi(1)
其中,lwit:特征项t在文献Di中的局域权值;mi:文献Di中特征项的个数;mit:特征项t在Di中出现的次数。
广域权值用来衡量特征项在整个文献集中的重要程度,取文献总数与特征项文献频率比值的对数,计算公式[ 6]如下:
gwt=log2Nnt(2)
其中, gwt:特征项t的广域权值;N:数据库中的文献总数;nt:特征项t的文献频率,即数据库中包含特征项t的文献数。
整体权重赋值方案可以理解为一种改进的逆文献频率(Inverse Document Frequency,IDF)加权法。最终计算两篇文献相似度的夹角余弦公式[ 6]如下所示:
SIM(Di,Dj)=∑k=1slwik×lwjk×gwk2∑k=1mlwik2×gwk2×∑k=1nlwjk2×gwk2(3)
其中, Di、Dj:数据库中的任意两篇文献;lwik:文献Di中第k个特征项的局域权值;lwjk:文献Dj中第k个特征项的局域权值;gwk:文献Di或文献Dj中第k个特征项的广域权值;s:文献Di和文献Dj共有特征项的个数;m:文献Di中特征项的个数;n:文献Dj中特征项的个数。
② 优化后的算法
在比较测试的基础上,PubMed于2006年对文本相似度计算方法进行了改进:在特征项局域权值计算过程中引入泊松分布,公式[ 7]如下:
lwit=1+μλk-1e-(μ-λ)l-1(4)
其中, lwit:特征项t在文献Di中的局域权值;μ、λ:泊松分布参数;l:文献长度;k:特征项在文献中出现的次数。
另外,将相似计算的夹角余弦公式替换为向量点积公式,公式[ 7]如下:
SIM(Di,Dj)=∑k=1slwik×lwjk×gwk(5)
其中各项含义均同公式(3)。
引入泊松分布主要基于以下认识:一个词在一篇文献中出现的次数越多,它对于表达文献内容来说就越重要,但是随着出现频率的持续增加,这种重要性的增长会越来越慢,最后达到一个极限值;并且一个词相对于一篇文献的重要程度不仅和词频有关,也和文献的长度有关,需要针对文献长度进行修正。
(2)基于PubMed相关文献检索的研究
基于PubMed实际应用的“Related Articles”功能,国外部分学者进行了更深入的研究,主要是在已有算法基础上,通过引入新的算法或处理方式实现对相关文献检索的揭示,尤其是对排序效果进行优化。具体可归为以下三种类型:
① 引入PageRank/HITS算法
由于“Related Articles”功能的存在,PubMed系统中每篇文献均有一定数量的相关文献,而每篇相关文献又有各自的相关文献,因此一篇文献可以看成是相关文献网络中的一个节点。基于这种认识,Lin[ 8, 9]将网络环境中用于评价网页重要程度的PageRank和HITS算法引入到PubMed相关文献网络中,统计分析表明这种结合可以明显优化相关文献的排序。
Bernstam[ 10]尝试将PageRank算法引入到PubMed文献基于引用关系而形成的网络中,鉴于PubMed并不提供文献的参考文献,首先将测试文献映射到SCI系统中,再基于SCI的引文网络来分析。然而测试表明PageRank算法在引文网络中并不能优化文献的排序。原因在于,与网页间的超链接相比,科技论文间的引用有相对较长的时间滞后,因此最新发表的重要论文并不能通过PageRank算法来发现。
② 考虑句子层次上的共被引关系
基于文本相似度计算,PubMed“Related Articles”只能将在字面内容上有重叠的两篇文献揭示为相关文献,Tran等人[ 11]针对这种局限性,尝试通过句子层次上的共被引关系(Sentence Level Co-citations, SLCs)来优化相关文献的揭示。即假设在同一个句子内同时被引用的两篇文献在内容上密切相关。实验表明,该方法不仅能揭示出高度相关的文献,而且能揭示出PubMed“Related Articles”所不能揭示出的相关文献。同时,该研究还发现, SLCs比PLCs(Paper Lever Co-citations)更有利于揭示出密切相关文献。
③ 引入文本比对算法
在将文本表示成向量的过程中,词间的排列信息以及句子间的排列信息均丢失,而这些信息对于揭示文献之间的内容相关性是有意义的。基于这种认识,Lewis等[ 12]引入动态规划比对算法(Dynamic Programming Alignment Algorithms)。考虑到比对算法的时间复杂度,整体设计分两步实施:首先利用基于VSM的文本相似度计算方法获得最相关的前400篇文献,在此基础上利用文本比对重新排序。统计表明,该方法对相关文献的揭示效果优于PubMed“Related Articles”。另外,研究还发现,句子层次的文本比对(Sentence Alignment)排序效果要优于整篇文本比对(Full Text Alignment)的排序效果。
3.2 国内相关文献检索研究
为了在CBM系统中实现类似PubMed“Related Articles”的检索功能,中国医学科学院医学信息研究所针对医学文献相关性数据库的建立进行了一系列理论探讨和应用研究。此外,国内个别学者也对相关文献的揭示进行了有益的探索。
(1) CBM相关文献检索研究
基于完全内容特征的相关文献检索要考虑尽可能多的特征项,除了直接利用主题词和作者关键词外,还要从题名、摘要甚至全文文本中抽取特征项,这在中文环境中就涉及到分词问题。中国医学科学院医学信息研究所的相关文献研究主要经历了基于词典和基于无词典两个阶段。
① 基于词典的研究
1) 推导PubMed相关文献算法
李军莲[ 13]从相关文献判定的理论基础、空间向量表示、特征项提取和相似度计算4个方面对PubMed“Related Articles”的实现方法进行分析,提出了基于VSM的英文相关文献算法。模拟试验表明该算法的相关文献揭示效果与PubMed具有较高的一致性,最后结合中文文献特点,提出CBM相关文献检索系统的开发设想。
2) 探讨中文相关文献算法
徐莉[ 14]将英文相关文献算法移植到中文环境中,探讨基于VSM的中文相关文献算法(简称“SIM法”)。该算法结合中文文献的特点,提出了特征项来源字段的选择、文本自动分词和特征项权重赋值等问题的解决方案。
3) 优化中文相关文献算法
王闰强[ 3]针对“SIM法”消耗时间过长的问题,提出“分类-SIM法”,即在文本相似度计算之前将待处理的文献分成若干个子集,然后在各个子集中分别进行相似度计算,最后归并各个子集中相似度计算的结果。理论推导和统计分析都表明,在相关文献揭示效果基本一致的前提下,“分类-SIM法”的运算速度比“SIM法”大约快5倍。
4) 构建中文文献相关性数据库
万莉莉[ 15]将“分类-SIM法”付诸实践,成功构建了实验性的中国生物医学工程文献相关性数据库及其检索系统。其构建流程如图2[ 16]所示:
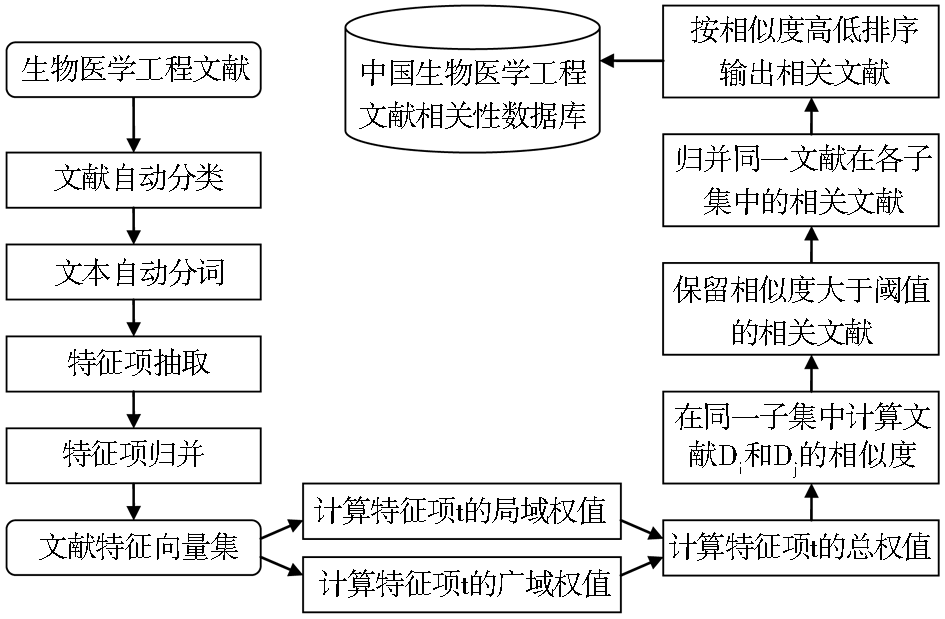 | 图2 中国生物医学工程文献相关性数据库建设流程 |
在上述系列研究中,CBM利用了一系列词表资源,如表2所示:
| 表2 CBM相关文献研究利用的词表 |
这些词表是决定相关文献检索效果的基础。尤其是自动分词的效果主要依赖于所用词表收录的广度和深度,且无法识别新词,因此需要投入大量的人力和时间对词表进行动态维护。另一方面,尽管这些词表具有较强的专业性和实用性,但均由中国医学科学院医学信息研究所自建,尚缺乏足够的公认度。
② 基于无词典的研究
为了规避词典,中国医学科学院医学信息研究所从2008年开始尝试在不利用词典的情况下构建文献相关性数据库。
1)引入后缀树算法
余希田[ 17]将后缀树算法应用到相关文献判定过程中,探讨在不进行分词和特征项抽取的条件下构建中文文献相关性数据库的方法。实验表明,该方法所揭示相关文献的准确率和排序效果略低于原有基于词典的水平,另外文本相似度计算的速度也不够理想,尚有进一步优化和改进的空间。
2)引入基于重现的无词典分词方法
王军辉[ 18]根据中文生物医学文本的特点,引入一种基于重现原理的无词典分词方法进行文献相关性数据库的构建。统计分析表明,该方法揭示相关文献的整体效果与原来基于词典的水平无显著性差异。另外,提出的“倒排-SIM法”较明显提高了文本相似度计算的速度。
③ CBM文本相似度计算方法
借鉴PubMed,中国医学科学院医学信息研究所在进行文献相关性数据库建设的系列研究中,文本相似度计算主要采用基于VSM的余弦相似函数(见公式(3))。其中,广域权值也采用了与PubMed相同的方案(见公式(2)),但局域权值的计算方法则根据中文文本特点进行了改进,如公式(6)和(7)[ 14]所示:
lwit=∑k=1zλk×tfitk (6)
其中,lwit:特征项t在文献Di中的局域权值;λ:加权系数;tfitk:特征项t在文献Di中不同位置(题名、关键词和文摘)出现的频次;z:λ在某篇文本中的取值个数。特征项在不同位置出现时加权系数λ的具体赋值方案如表3[ 14]所示:
| 表3 加权系数λ赋值方案 |
考虑到特征项在特定文献中的权重还会受到该文献篇幅长短的影响。在较长的文献中,特征项t出现的可能性会更大,其频次也会越高。因此,应排除文献的长短对特征项局域权值的影响,故对局域权值进行标准化处理,公式[ 14]如下:
lwit’= 0.5+0.5×lwitlwi (7)
其中,lwit’:特征项t在文献Di中的标准化后的局域权值;lwit:特征项t在文献Di中的原始局域权值;lwi:文献Di所包含的所有特征项在该文献中的局域权值的最大值。
(2) 国内其他相关文献研究
从CNKI和万方数据库中检索到的文献来看,国内除中国医学科学院医学信息研究所以外,相关文献检索方面的研究均在2006年以后。目前主要成果集中在以下两个方面:
① 引入新的算法
邱宇红等[ 19]在对医学文献进行基于VSM的文本相似度计算之后,又通过一定的聚类算法对相关文献进行聚类分析,以指导用户直接浏览感兴趣的类别文献,提高检索效率。但其特征项提取时只考虑了MeSH主题词,未涉及关键词、题名和摘要。陈祖琴等[ 20]引入关联规则挖掘算法,通过用户行为分析确定相关文献集和垂直权重,采用PageRank算法确定水平权重,最后利用改进的混合加权关联规则挖掘算法进行相关文献的推荐。
② 改进系统设计
张志平等[ 21]为了规避构建文献相关性数据库的繁琐过程,设计并实现了实时的相关文献推荐系统,当用户浏览检索结果中的某一篇文献时,实时计算该文献与检索结果列表中位于该文献之后的文献之间的相似度,选择与其最相似的数篇文献作为相关文献进行推荐。笔者认为,这种设计固然实现了相关文献的实时推荐,但也削弱了相关文献的价值。因为相关文献的一个重要作用就是能帮助用户发现传统检索方式所不能揭示的文献,而这种设计所提供的相关文献则全部来自于初始检索结果集。
4 相关文献检索的评价和效用分析
4.1 评价方法与指标
早期, 国外对相关文献检索进行评价的方法比较简单,一般是聘请一位或数位专业领域的学生或研究人员对相关文献检索的结果进行判定,结果分为“相关/不相关”或“非常相关/一般相关/不相关”[ 10, 22]。在判定过程中对“相关”的界定也非常不清晰,如“与源文献指向同一个主题”或“判定者有兴趣查看”等,这样不仅易受判定者个人主观因素的影响,更不具有操作性。这一时期采用的指标均是信息检索领域的传统指标,如准确率(Precision)、召回率(Recall)等,同时,由于均是基于小样本,因此无法在统计学上得出令人信服的结论。
受美国文本检索会议(Text REtrieval Conference,TREC)的影响,近几年,国外对相关文献检索的评价[ 7, 8, 23, 24]均基于TREC提供的文本测试集,并采用更科学合理的评价指标,如P5(Precision@5)、P20、MAP(Mean Average Precision)、MAP20、MAP40等。目前,国内尚无利用TREC文本测试集评测相关文献检索的研究,均是基于小样本的人工判定。值得一提的是,张志平等[ 21]首次引入信息抽取领域的NDCG(Normalized Discounted Cumulative Gain)指标来评价相关文献。
4.2 相关文献检索的效用
根据2007年对PubMed用户使用日志的分析[ 23, 24, 25],大约1/5的有效用户会话中都包含了至少对“Related Articles”的一次点击,同时大约5%的页面浏览量是通过点击“Related Articles”而产生的;而用户在点击一个“Related Articles”后,再点击另外一个“Related Articles”的可能性高于40%,并且随着会话时间的延长,用户更倾向于追踪相关文献链接,而不是直接进行检索。这些数据都表明相关文献检索是PubMed非常有用的特性功能,已成为用户使用PubMed的重要方式。
国外学者一般将相关文献检索归为相关反馈(Relevance Feedback)的一种应用形式,并且是已经被证实的可以显著提高检索性能、改善检索结果的反馈形式[ 26, 27]。除了能满足用户的文献信息需求外,相关文献检索还有其他潜在的应用价值,如利用PubMed“Related Articles”来更新文献目录数据的研究[ 28]。
与本文关注的文献数据库检索领域不同,相关文献检索在搜索引擎领域的效用却不尽如人意。根据笔者文献调研,目前只有一篇论文对Google“Similar Pages”进行评测[ 29],结果表明,利用“Similar Pages”检索的准确率明显低于直接利用引擎进行检索的准确率,对提高用户的检索效率并不十分有效。
4.3 对相关文献检索的质疑
除了上述作用和潜在应用价值外,人们对相关文献检索也存在一定的质疑。Staunton[ 30]认为,由于相关文献检索能返回大量的相关文献,相关文献本身又有许多相关文献,其中有些可能和源文献只是稍微相关,这会使用户产生混淆,干扰其对关键文献的关注。Lin等[ 23]通过分析PubMed用户行为,发现在初始检索效果较差或者返回结果很少的前提下,“Related Articles”会是很好的补充,但如果在初次检索效果很好、准确率很高的情况下,过早地进行相关文献检索则是有害无益的。
另一种类似的质疑是:一篇文献可以包含多个内容特征项,它可以被不同的用户以完全不同的查询方式获得,但在所有情况下,由于相关文献检索并不依赖于用户最初的查询,该文献的相关文献都是完全相同的,并没有考虑用户最初所感兴趣的内容[ 31]。这种由本身实现机制所决定的情况,涉及到如何定位相关文献检索这一服务形式的问题。笔者认为它只是对现有检索系统在揭示文献功能上的一种完善和补充,尤其是在初始检索效果不理想的情况下的一种补偿机制,而不能取代常规的检索方式。
5 结语
目前,国内外专门针对相关文献检索的研究还很少。本文侧重从算法角度,对国内外代表性的研究进行了系统的阐述,并简单综述了相关文献检索的评价方法和效用分析。基于当前研究成果,笔者认为,今后相关文献检索可从以下两个方向予以深入:
(1)综合考虑内容和外部特征
当前实际应用的相关文献检索系统,或基于外部特征或基于内容特征,尚未有综合考虑内容和外部特征的系统。可将不同层次不同类型的引证关系(共引、共被引)与当前成熟的基于文本相似度计算的内容相关文献算法结合,这样不仅可以脱离字面相似匹配的限制,也可使揭示的相关文献更客观。
(2)面向知识服务
图书情报领域正在经历从信息服务到知识服务的转变,知识信息的组织与表达应从物理层次的文献单元向认识层次的知识单元转变,相应地致力于揭示相关文献的相关文献检索也应向揭示相关知识(Related Knowledge)的方向发展,即“相关知识检索”(Related Knowledge Retrieval)。相关知识检索与相关文献检索的关系如图3所示:
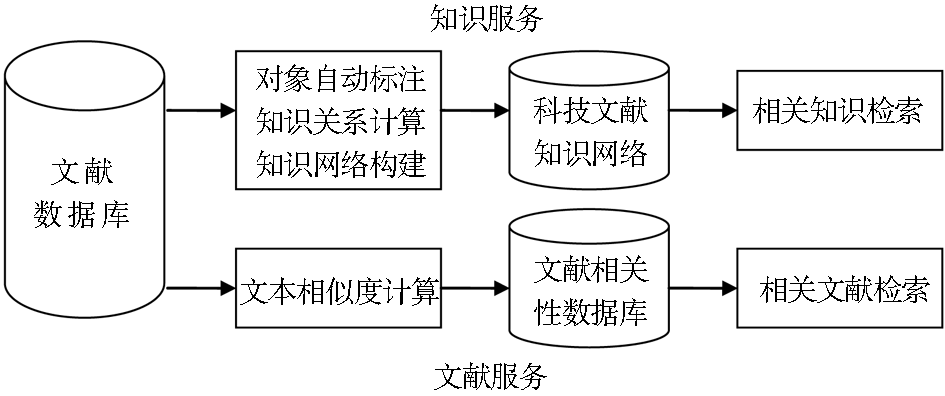 | 图3 相关知识检索与相关文献检索 |
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|