
{kind=link}
{kind=link}
基于SOM的领域热点主题探测*
引用本文
陆伟, 彭玉, 陈武. 基于SOM的领域热点主题探测* . 现代图书情报技术, 2011, 27(1): 63-68
Lu Wei, Peng Yu, Chen Wu. Hot Research Topics Detection Based on SOM. 现代图书情报技术, 2011, 27(1): 63-68
Permissions
Lu Wei, Peng Yu, Chen Wu. Hot Research Topics Detection Based on SOM. 现代图书情报技术, 2011, 27(1): 63-68
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于SOM的领域热点主题探测*
摘要
针对学科领域中热点研究主题探测,尝试综合运用共词分析方法与自组织映射(SOM)方法,在词频统计的基础上,分析高频主题词在文献中的共现,并作为输入数据利用SOM Toolbox进行SOM聚类分析,得到领域热点研究主题。以传统医药领域为例进行实证分析,结果表明该方法对领域中热点主题探测有一定效果。
关键词:
自组织映射; 热点主题; 共词分析; 传统医药
中图分类号:G202
Hot Research Topics Detection Based on SOM
Abstract
According to detection of hot topics in a research field, the paper proposes a method combining co-word analysis and SOM together. By analysing the co-occurrence of high-frequency keywords in the literature as input data and using SOM Toolbox for SOM clustering, the collection of hot research topics is obtained.At last a case study is done by taking traditional medicine as an example, and experimental results show that this method is efficient in the process of hot research topics detection.
Keyword:
SOM Hot research topics; Co-word analysis; Traditional medicine
1 引 言
热点研究主题是学科领域中聚焦了大量研究者关注和研究的一些主题,这些主题可能数量很少,却集中了领域中大部分的研究力量和资源,对热点主题的研究能够摒弃领域中一些并不能对全局产生影响的边缘研究主题,从而迅速简洁地展示整个学科领域的知识结构。热点研究主题的探测,对研究者、研究机构、相关政府部门的选题、科研立项有重要的指导意义,对学科本身的发展也十分重要。
如何准确地探测领域中的热点主题一直是情报学研究的一个问题。科学研究具有高度的动态性,新的研究主题不断出现,已经形成的研究主题通过分裂或融合形成新的主题,各个主题的重要性或者受关注程度也在不断增加或减少。因此热点主题探测的结果对准确性、实时性具有较高的要求。传统的探测方法依赖于研究者查阅领域相关的文献或成果,通常要耗费大量的人力、物力和时间,而且由于目前文献、相关研究成果数量正在迅猛增长,已经很难继续采用这种方法。综合运用信息计量学、数据挖掘等方法实现自动化的热点主题探测,已经成为相关研究的趋势。
2 国内外研究现状
国内外研究者很早就开展了科研领域热点主题识别与趋势预测的相关研究,Price在1965年就提出研究前沿(Research Front)的概念,用以描述某研究领域中引用周期较短暂的一类文献[ 1]。目前国内外的相关研究主要对领域内学术文献采用定量分析的方法,这些方法可以根据以主题词或文献为研究单元而分为两类。
2.1 以主题词为研究单元的相关研究
如果某一关键词或主题词在其所在领域的文献中反复出现,则可反映出该关键词或主题词所表征的研究主题是该领域的研究热点[ 2]。1997年加拿大蒙特利尔大学的Dalpé教授向加拿大国家研究理事会(NRC)提交了一份关于国际纳米科技研究现状的分析报告,这份报告在NRC提供的79个关键词的基础上,通过分析它们的词频总结了纳米科技论文和专利在全球范围内的产出分布[ 3]。
在词频统计的基础上,一些研究者进一步分析高频主题词在文献中的共现,以它们的关联强度为基础进行共词分析,在同簇中的主题词通常具有较高的相关性,因而使研究者能够较为容易地确定一些多义的主题词的具体含义和指向内容,从而有效降低研究者的认知负担。马费成等对CNKI数据库中近10年以来数字信息资源领域发表的期刊论文的关键词进行共词分析,并借助多元统计学方法中的因子分析法和系统聚类法,研究各主题词间的关系,探讨了国内数字信息资源的研究现状与热点[ 4]。Courtial利用此方法描述了科学计量学的学科结构和动态发展变化[ 5]。
一些学者认为热点研究主题是增长势头不断加强、未来可能成为主流研究对象的主题,这些学者采用的方法以Kleinberg的突发检测算法为代表。Kleinberg在2003年提出话题的突发监测(Burst Detection)算法,最初应用于新闻和电子邮件的主题突发性探测[ 6]。Chen在其设计的CiteSpace II中,在构建论文共引网络的基础上,利用Kleinberg算法对每个簇抽取其中文献的关键词,并作为该簇代表的热点主题的标签[ 7]。笔者认为这类主题可以称为趋势主题,与热点主题有较大区别,因而在本研究中没有采用该算法。
2.2 以文献为研究单元的相关研究
以文献为研究单元的相关研究主要分为文献主题分布统计分析和引文分析两类。在某领域已经存在一个权威的分类体系的前提下,用文献主题分布统计分析方法探测热点研究主题,具有简单和易于理解的特点。李文兰等对1993-2002年情报学期刊论文研究主题分布进行了统计分析[ 8],以中图分类法为基础,统计G35下子类别的文献数,从而反映不同主题的研究热度。
引文分析能较好地反映学科的知识结构,因此被广泛用于热点主题探测的相关研究。根据引用关系的不同,引文分析又分为具体的三种形式:共被引分析、文献耦合、直接引用分析。Shibata等对比分析了三者用于探测领域研究前沿的优劣,通过实验得出结论以直接引用计量文献间联系具有一定优势[ 9]。张倩等以Web of Science网络数据库为数据源,对2004年SCI和SSCI共同收录的23种图书情报杂志刊载的参考文献进行共被引聚类分析,结合图书馆学、情报学专业知识对聚类结果进行分析解释,从而动态揭示近年来该学科的研究热点[ 10]。在引文分析的基础上,运用自组织映射(Self-Organizing Map,SOM)、多维尺度分析(Multi Dimensional Scaling,MDS)、路径寻找网络(Path Finder Network Scaling)等方法,描绘出某一学科领域的知识图谱(Knowledge Mapping),能够将学科内部结构以可视化的方式清楚地展现出来。德雷塞尔大学的Chen教授做了大量此方面的研究,他与McCain等以科学计量学1981-2001共20年间文献为数据,可视化展现了被引次数在一定阈值以上的文献的共被引网络[ 11]。近年来,国内也开始关注知识图谱,并取得了一些研究成果。大连理工大学刘则渊教授在此方面做了大量研究[ 12, 13]。
因为领域内的研究成果大多会以学术论文的形式展现出来,所以目前国内外的相关研究基本上都以学术论文为数据源,而忽视了其他数据类型,如专利数据、科研项目、领域内奖励等。这些数据也是进行热点主题识别、趋势预测研究重要的数据源,但目前以这些数据为对象进行热点主题识别研究的成果很少,宋旭昌以iSchool成员科研立项为数据源用词频分析方法研究了2007年iSchool的科研热点[ 14];Courtial等利用从专利标题抽取的主题词进行共词分析,确定发明的主题并预测可能的发展趋势[ 15]。
3 基于共词分析与SOM的热点主题探测方法
本文综合共词分析方法与自组织映射(SOM)作为热点研究主题探测方法。共词分析是目前相关研究中最成熟的方法之一,它能够将表征相同主题的关键词归纳到同一个类中,从而更易总结出热点研究主题,而且避免了引文分析的时滞性的缺点。自组织映射作为一种聚类算法,能够将高维数据映射到低维空间并保持较好的拓扑结构,对噪声数据不敏感并且聚类结果不会因为初始值的选择发生很大变动,可视化的聚类结果结合人的感知能力将使理解数据间的关联和模式变得更加简单。
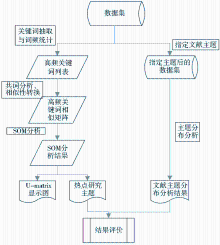
本方法的具体分析过程如图1所示:
 | 图1 基于共词分析与SOM的热点主题识别流程 |
图1中左分支为本研究方法的分析过程,右分支为文献主题分布分析过程,这是为了评价研究方法的有效性而进行的对比实验,在本文中不再详细描述其具体分析过程。热点主题探测整体分析过程如下:
3.1 数据集获取与预处理
为了研究领域的热点主题,必须获取数据集以代表该领域并作为后续研究的基础。本文采用首先由专家人工选取相关关键词,然后以其为检索词从学术数据库中检索并下载的方式得到文献,经过去重、去除非学术论文的记录等预处理操作后,存入本地数据库作为数据集。这种方法最大限度地覆盖了所研究的领域范围,避免了研究主题的遗漏。
3.2 高频词提取
作为共词分析基础的主题词,可以是论文提供的关键词,或者是利用自然语言处理技术从题名、摘要和正文中提取的词。在本文的实证分析中,笔者将论文提供的关键词作为分析对象。
从数据集的文献中抽取关键词,统计各关键词的出现频率,得到关键词列表,并按频率从高到低排序。从该列表中选取部分关键词作为高频词。目前有三种方法较广泛地用于高频关键词的确定:结合研究者的专业知识背景人工确定高频词阈值,该方法主观性太强且受每年文献绝对数量的影响;利用Donohue的高低频词分界公式确定阈值,该方法的有效性在学术界目前还存在争议;按词频高低顺序选择一定数量的关键词,使这些关键词的频率之和与所有关键词的总频率的比值达到一定阈值,该方法不受每年文献绝对数量变化的影响,在相关研究中取得了较好的结果,所以笔者采用了该方法。
3.3 共词分析
对高频词列表中的关键词两两间的共词关系进行统计并生成共词矩阵,在本文的实证研究中仅统计关键词在特定字段中而不是全文中的共现情况。共词矩阵中的元素值是词对的共现次数,没有经过规范化处理,高频词相对于其他频率不高的词在规模上的优势将会影响相似性分析结果的准确性。因此共词矩阵的元素值不能直接作为词对的相似度,笔者采用余弦系数将共词矩阵转换为相似性矩阵。
3.4 SOM分析
SOM由Kohonen在20世纪80年代提出,近年来被应用于众多领域并取得了很好的研究成果。它是一种两层结构(输入层、输出层)的无监督竞争式学习的神经网络,通过递归的竞争学习,输入层中的对象分别映射到与之最合适的输出层结点中,其中具有较高相似度的对象所对应的输出层结点在理想状态下是相同的,或者具有较小的欧氏距离。
SOM的输出层如图2所示。
 | 图2 2008年传统医药领域高频词SOM分析结果 |
同一个结点对应的输入层对象一般可以归为同一个聚类中;相邻结点的相似度较高,因此它们对应的输入层对象也可能是同一类。输出层结点的颜色代表其U-matrix值,U-matrix是Ultsch在1992年定义的,其大小与原输出层一致,每个元素的值等于该结点的权向量与所有直接相邻结点的权向量之间的距离之和除以出现的最大的值[ 16]。因而在SOM输出层中,颜色值较大的结点表示这个结点与相邻结点的距离较大,这些结点可能是聚类的边缘;颜色值较小的结点表示这个结点与相邻结点的距离较小,这些结点可能处于聚类的内部。
将关键词相似矩阵作为输入数据进行SOM分析,生成U-matrix显示图,结合图中结点的颜色及结点下关键词的意义,人工将所有结点归纳为不同的聚类,每个聚类代表该领域内的一个热点研究主题。
3.5 结果评价方法
对于聚类效果,笔者认为,某个聚类下与聚类主题相关的关键词占此聚类总关键词数的比例越大,则聚类效果越好。定义聚类Ck的隶属度为M(Ck),其计算方式如下:
M(Ck)=,mi=1,0(1)
其中,n为Ck下的关键词数,mi为第i个关键词与Ck的相关性,值1,0分别表示相关、不相关。当以下几种情况中至少有一种发生时,mi=1。
(1)该词与聚类主题意义相近,如Tumor(肿瘤)与主题癌症意义相近。
(2)该词与聚类主题的某一方面相关,如Bone-marrow-transplantation(骨髓移植)与主题白血病相关。
(3)该词意义过泛,而不能看出与聚类主题的相关性,但由其组成的词组与聚类主题相关,如Expression的意义不明显,但Gene Expression与主题癌细胞基因相关。
对于聚类内容,笔者通过比较本方法的研究结果与文献主题分布的分析结果,来评价研究结果的客观性及是否与领域宏观发展状况相符。如果文献主题分析采用的分类体系是该领域内的权威分类体系,其分析将能够较好地反映领域宏观情况,并具有很高的可信度和客观性,因而本文以其作为评价聚类内容的基准。
4 以传统医药领域为例的实证分析
以2008年的传统医药领域为例,对本文提出的基于共词分析与SOM的热点主题探测方法进行实现和实证分析,以评价本研究方法的有效性。
4.1 实验结果
数据集由2008年传统医药领域的22 991篇文献构成,共有不重复的关键词80 735个,总词频259 397次。按词频从高到低选取了984个关键词作为高频词,它们的词频之和占总词频的35%。统计高频词的共现情况,生成984×984的相似矩阵,将其作为输入数据,利用芬兰赫尔辛基大学信息与计算机科学实验室在Matlab环境中开发的SOM Toolbox[ 17]进行SOM分析。生成的U-matrix图(见图2),有17行9列共153个结点,结点中的数字表示映射到其中的关键词的数量。
通过查看SOM结点内的关键词,发现153个输出结点中有56个结点的主题较为明显。由于SOM分析的特点,相邻输出结点的主题可能是相同或者相近的,所以结合这些主题本身以及对应SOM结点的相邻程度,将这56个结点归纳为17个聚类主题。本文以该17个聚类主题作为2008年传统医药领域热点研究主题,如表1所示。其中,G(i,j)表示图2中第i行第j列的SOM输出结点。
| 表1 2008年传统医药领域热点研究主题 |
4.2 结果分析
17个热点研究主题的隶属度如表2所示。
| 表2 2008年传统医药领域热点主题探测隶属度 |
最终的平均隶属度超过了0.6,由此可以看出该56个节点与其所属聚类主题的相关性较高,17个热点研究主题都对应了一定数量的相关关键词。因而笔者总结出的这17个主题能够代表其所在的聚类及包含的关键词。
MeSH是医学领域最权威的分类体系,本文以其为基础进行文献主题分布分析,得到的分析结果中与前文总结的17个热点主题有许多相互印证之处,如表3所示。
| 表3 SOM聚类结果与文献主题分布分析结果对比 |
本文的研究结果与文献主题分布分析结果有很多吻合之处,因此本研究的结果正确反映了传统医药领域的大致研究状况,利用本方法识别领域的热点主题得到的结果可信。利用本研究方法得到的热点研究主题更加具体和细致,聚类主题中的关键词可以帮助研究者了解相关的主题中正在被研究的具体问题或者方法。例如C7(植物成分提取、植物提取物的各种作用)与D26.667(Plant Extracts),通过查阅C7下的关键词,可以发现植物提取中经常被提取的成分、经常用到的植物部件以及植物提取物的用途等。
5 结 语
本文将共词分析与自组织映射综合运用于领域热点主题探测,取得了较好的研究成果,但尚存不足之处。
(1)本研究以主题词为研究单元,而以文献为研究单元的方法也具有其特点和长处,可以在未来的研究工作中综合运用以充分利用各自的优点;
(2)本文的研究仅采用了学术文献作为研究对象,各种其他数据源如专利也可以揭示领域的热点研究主题,在以后的研究中需要探讨如何综合多种类型的数据源。
致谢:本文得到了武汉大学“70”后学者团队计划和汇海科技——武汉大学移动商务平台联合实验室资助,特此感谢!
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|