
{kind=link}
{kind=link}
{kind=link}
基于条件随机场模型的复杂时间信息抽取研究*
引用本文
逯万辉, 马建霞. 基于条件随机场模型的复杂时间信息抽取研究* . 现代图书情报技术, 2011, 27(10): 29-33
Lu Wanhui, Ma Jianxia. Research on Complex Time Information Extraction Based on CRF Model. 现代图书情报技术, 2011, 27(10): 29-33
Permissions
Lu Wanhui, Ma Jianxia. Research on Complex Time Information Extraction Based on CRF Model. 现代图书情报技术, 2011, 27(10): 29-33
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于条件随机场模型的复杂时间信息抽取研究*
摘要
针对网络信息的时序性和多态性,提出基于条件随机场模型的复杂时间信息抽取研究模型,并通过实验验证该模型的可行性,选取词特征和词-词性特征进行对比研究,结果表明,加入词性特征后召回率有明显提高,而准确率提升不明显,并对这种现象进行分析。
关键词:
复杂时间信息抽取; 条件随机场; 特征选择
中图分类号:TP391
Research on Complex Time Information Extraction Based on CRF Model
Abstract
Because of the characteristic of time-serial and polymorphism of the network information, this paper presents a model of extracting the complex time information based on Conditional Random Fields(CRF), and verifies the feasibility of this model through an experiment, compares the results through choosing the features of words (contexts) and word-POS. The experiment shows that the result will be much improved if adding the POS feature.
Keyword:
Complex time information extraction; CRF; Feature selection
1 引 言
互联网的快速发展使网络上的文本、图像等多媒体信息成几何级增长,并且随着时间的不断演化,各种信息也在逐渐地更新和进化,如何快速高效地利用这些信息成为目前众多研究者关注的问题,于是出现了时序文摘、话题检测与跟踪(Topic Detection and Tracking)、舆情监控等研究,而有关时序特性的识别和抽取又是这些研究中的基础工作。时间表达式的识别与归一化处理,是时序信息抽取应用的支撑,是时序语义标注的基础[ 1]。同时,时间信息作为一个事件的重要组成部分,是信息抽取研究中一个比较重要的领域。有研究表明,时间信息在文本信息中所占的比重仅次于专有名词[ 2]。作为文本语义理解、语块分析等信息抽取中一项关键的技术,解决时间信息的抽取对机器翻译和人工智能领域的推进具有重大研究意义,是一项重要的、基础性的工作。因此,本文通过将时间信息进行分类,比较基于统计方法和基于规则方法在时间信息抽取中的特点,采用条件随机场模型对复杂时间信息的抽取进行重点研究。
2 研究背景
2.1 时间信息抽取研究现状
有关时间信息抽取的研究,最早可追溯到1998年的MUC7会议上,该会议首次在命名实体识别中加入了对时间评测的要求,但是MUC7只对绝对时间进行了定义,而且将绝对时间分为日期、时间、段时间三类[ 3]。之后关于时间信息抽取的研究并没有随着MUC会议的停办而停止,在其替代会议ACE评测中,时间信息抽取评测仍旧是一个重要的研究领域。在2004年8月举办的ACE第5次评测中,其研究的主要内容聚集在自动抽取新闻语料中出现的实体、关系、事件等内容。时间表达式作为事件的重要组成部分,其评测方法在其子项目TERN (Time Expression Recognition and Normalization)中有详细定义和描述,不仅要求系统标示出文本中的时间表达式,而且还要求对这些表达式的语义做规范化的处理[ 4],从而提出了时间表达式的识别和归一化处理的研究方向。2009年,ACE正式更名为TAC,其研究更加倾向于文本内容分析,从2009和2010年的评测任务[ 5]可以看出,其评测任务集中在Recognizing Textual Entailment、Summarization、Knowledge Base Population,时间信息的识别和抽取仍是其中一个重要的研究课题。
英文语料的时间信息表达方式分为三个部分:时相(Phase)、时制(Tense)和时态(Aspect),因此在研究英文时间关系时需要将时态等内容进行还原,以进一步确定时间序列。Stevenson等[ 6]进行了动词情态分类工作的研究,从而将时间信息的抽取扩展到了隐性时间信息领域。
在中文时间信息抽取研究中,徐永东等[ 7]提出了基于规则的时间信息抽取、理解及时间语义的计算方法,将承载时间信息的短语按照不同功能分解成若干个容易识别的语义单元,重点研究了时间表达式的语义计算,但并没有深入研究时间短语、事件短语间的映射关系。赵国荣[ 8]对事件类时间短语的特点进行了重点研究、并通过规则匹配树的方法进行了实验验证,但受训练语料库的限制,该方法的扩展性有限。
关于时间信息抽取的主要方法有:基于规则的方法、基于词典和自动机的方法、基于错误驱动的方法和基于机器学习的方法[ 9]。由于时间表达式具有种类多样性、属性多样性、无规则等特点,基于规则的方法很难处理大规模复杂语料,因此,基于统计的方法的优势比较明显,本文采用基于CRF模型的方法进行复杂时间信息的抽取研究。将通过时间信息的分类研究引出复杂时间信息的定义,从而为实验研究提供理论基础。
2.2 时间信息的分类
从宏观上来分,时间信息可分为显性时间信息和隐性时间信息。显性时间信息如“2008年8月”、“今年夏天”等,这一类时间信息可以很容易地被识别出来,而隐性时间信息如“当地震发生的时候”、“树木发芽”等,这一类文本信息虽然描述的是一个事件,但是其中包含着丰富的时间信息,因此,识别并标识隐性时间信息是时间信息抽取的关键。
从这种分析出发,可以将时间信息细化为绝对时间、时间短语和事件类时间短语,其中确定时间-事件的映射关系是时间信息识别和抽取中的难点,王昀等[ 10]采用基于错误驱动的方法进行了时间-事件关系映射的研究,通过从名词短语、介词短语和动词短语中抽取事件并运用最小距离原则来确定时间,但并没有解决时间类事件的识别问题;同时,识别时间信息,还必须对句法成分进行深入剖析,在句法成分中包含的时间信息有:时间短语(TNP)、时间前置短语(TPP)和时间从句及时间副词[ 11],识别并标记这些信息对时间信息的抽取有重要意义。
由于时间是一个比较复杂的概念,有静止的时间点和连续的时间段,因此,处理时间信息时还必须要考虑这一层意思,这就为抽取时间信息带来一定的复杂度。本文总结的时间信息分类如图1所示:
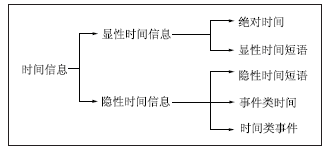 | 图1 时间信息分类 |
2.3 复杂时间信息的定义
在时间信息抽取中,关于显性时间的研究已相对比较成熟,特别是对显性时间信息中的绝对时间,一般的切词工具或词性标注工具都做得比较完善,特别是中国科学院计算技术研究所的3GWS和哈尔滨工业大学的中文语言技术平台[ 12]。 因此,本文重点研究复杂时间信息的抽取。
定义:复杂时间信息,即相对于绝对事件而言的、隐性的、不能直接识别的时间信息,对此信息的识别要依赖于事件映射、前后触发词和上下文关联词等。
通过复杂时间信息的定义可知,识别并抽取复杂时间信息需要依赖于对其时间触发词及其所有的修饰成分的良好标识,时间触发词主要有以下三种:时间触发词;时间表达式的前缀和后缀;时间停用词。
根据训练语料中切分出来的时间表达式及时间信息标注规范的定义,半自动总结出时间触发词表、时间表达式的前缀和后缀及时间停用词表,用于后续训练语料的标注。本文研究抽取的复杂时间表达式包括:
(1)日期+复合时间名词短语 (+动词)
例如: “2010年第一季度(开始)”
(2)介词+日期/时间词(+助词)
例如:“将于今年(内)”
(3)介词+日期/时间词/特殊名词+助词
例如: “自…之后”
(4)介词+日期/时间词/特殊名词+动词
例如: “从昨天开始”
(5)事件类时间短语
例如:“北京奥运会举办期间”
3 基于CRF的复杂时间信息抽取实验
3.1 CRF基本理论介绍
条件随机场(Conditional Random Fields,CRFs)[ 13]最早由Lafferty等于2001年提出的,其模型思想的主要来源是最大熵模型,可以把条件随机场看成是一个无向图模型或马尔可夫随机场,它是一种用来标记和切分序列化数据的统计模型。
条件随机场定义:令G=(V,E)表示一个无向图,Y=(Yv)v∈V,Y中元素与无向图G中的顶点一一对应。当在条件X下,随机变量Yv的条件概率分布服从图的马尔可夫属性:p(Yv|X,Yw,w≠v)=p(Yv|X,Yw,w~v),其中(w~v)表示(w,v)是无向图G的边。这时称(X,Y)是一个条件随机场。
条件随机场模型是一种典型的判别式模型,它在观测序列的基础上对目标序列进行建模,重点解决序列化标注的问题。该模型既具有判别式模型的优点,又具有产生式模型考虑到上下文标记间的转移概率,以序列化形式进行全局参数优化和解码的特点,解决了其他判别式模型(如最大熵、隐马尔可夫模型)难以避免的标记偏置问题[ 14]。
基于CRFs 的主要系统实现有Flex CRF,Pocket CRF和CRF++。Flex CRF只能直接指定最大迭代次数,没有使用CRF++那样用梯度+特征权值之和的稳定性作为迭代结束的标志,可以在每个训练迭代后进行即时的测试评估,但这也加重了系统的负担,降低了系统性能。Pocket CRF输入输出和CRF++非常类似,但不同在于Pocket CRF严格要求输入文件各列必须用0x09隔开,无法识别空格[ 15]。因此,相比Flex CRF和Pocket CRF,CRF++在易用性、稳定性和准确性上表现都较为出色。
3.2 基于CRF的复杂时间信息抽取模型
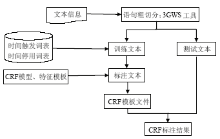
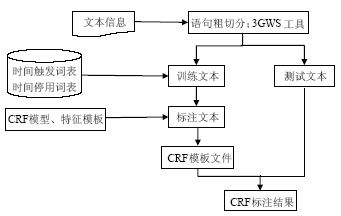
基于CRF模型的复杂信息抽取模型如图2所示:
 | 图2 基于CRF模型的复杂信息抽取模型 |
基于CRF模型的复杂信息抽取模型的实现步骤如下:
(1)构建时间触发词表、时间停用词表、时间短语的前缀和后缀,用于标注训练文本;
(2)利用智能分词系统3GWS对语料进行切词和词性标注,并制作成CRF语料格式;
(3)根据词表对训练文本进行标注,B表示时间短语开始位置、E表示时间短语结束位置、I表示时间短语的中间部分、BE表示单个词为时间短语、O表示其他(非时间短语信息);
(4)制作特征模板并用CRF++工具训练标注后文本,生成CRF模板文件;
(5)用训练好的模板文件对测试文本进行标注,形成标注结果。
3.3 复杂时间信息特征选取及特征模板设计
针对信息抽取的特征选择主要集中在词、词性及其二元组合上。丁晟春等[ 16]通过规则的方法研究了信息抽取中词性组合模板的组合规则,探索了基于词性合并获取语块的可行性。本文也从词和词性特征出发,运用统计的方法探索词、词性及其组合在复杂时间信息识别中的规律,并制作特征模板来进行复杂时间信息的抽取。
本实验语料粗切分后并进行人工标注后的标注语料如图3所示:
 | 图3 CRF语料标注结果 |
针对该实验语料特点,本文考虑的特征选取包括上下文特征(词特征)和词性特征。进而通过它们之间的组合可分为一元特征、复合一元特征和二元特征[ 17],并采用窗口为2进行实验,即(w-2,w-1,w0,w1,w2)。假设图3中当前词为的“开始”,该特征模板举例如表1所示:
| 表1 部分模板项举例 |
4 实验结果分析与评测
本实验采用的文本语料来自我国南方特大洪水灾害期间的部分新浪新闻,本文所研究的时间信息提取可以为灾情进展和监控提供变化依据,具有一定的现实意义。本文采用CRF++工具包来进行训练和测试数据,该工具包的具体使用方法参见文献[18]。
实验中采用了三个评测指标:P代表准确率(Precision),R代表召回率(Recall),F代表F-值(F-measure),定义如下:
R= 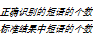
P= 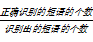
F-值= 
本文对实验结果评测采用的工具是CoNLL-2000所用的conlleval.pl[ 19]。它是用来评分的,所以要求测试文件中本身带有答案,这样解码后生成的结果会在答案的后一列。CoNLL-2000将最后一列与倒数第二列进行对比,从而统计出最后各类的准确率、召回率、F-值等。需要注意的是在使用评测工具前要将评测文件中的所有制表位转换成空格,否则评测工具会出错。
本次实验选取了新闻语料526条,其中350条语料经过粗切分和人工标注后形成如图3所示的训练语料,约占总语料的2/3,176条用于测试,约占总语料的1/3。每条语料约包含2-3个时间信息,经实验评测,该模型的抽取实验结果如表2所示:
| 表2 复杂时间信息抽取实验效果 |
从实验结果可以看出,单纯考虑词特征(上下文特征)时系统的准确率和召回率都较低,而引入词性特征之后,系统的结果有明显提高。
进一步对表2的结果进行分析时发现,加入词性特征之后,召回率大幅度提升,而准确率仅仅增加了3%左右,其原因在于这里存在一个“过学习”的问题,例如训练语料中有“北京奥运会期间”(词性组合为:ns+n+f)此处的词性标注结果为3GWS切分词结果。,在测试语料“北京人民中间涌现了一批劳动模范”识别中会出现“北京人民中间”(词性组合为:ns+n+f),导致系统识别出的短语个数明显增加,但这样的语块组合显然不包含时间信息。
5 结 语
通过对中文时间信息的分类和时间信息抽取研究现状的分析,引出了复杂时间信息抽取的研究思路,并基于CRF模型设计了一个复杂时间信息抽取系统,选取了词特征和词性特征来进行实验验证,结果表明该思路是可行的,对复杂时间信息抽取的识别和抽取是有效的。但是由于中文文本信息其表达方式的随意性和语法结构的多态性,往往一个短语能表达多重含义,因此在后续研究中还需要解决以下问题:
(1)进一步分析时间信息的内部结构,选择除词特征、词性特征之外的其他特征,解决统计学习中的“过学习”问题。
(2)深化语料制作、完善语料种类,建立全面准确的训练语料库,进而为复杂时间信息抽取提供一个完备的良好的学习训练环境,同时解决未登录短语的识别问题。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|