{kind=link}
专业概念机器辅助分类方法研究*
引用本文
常春, 赖院根. 专业概念机器辅助分类方法研究* . 现代图书情报技术, 2011, 27(10): 34-39
Chang Chun, Lai Yuangen. Research on Machine-aided Classification Methods of Domain Concepts. 现代图书情报技术, 2011, 27(10): 34-39
Permissions
Chang Chun, Lai Yuangen. Research on Machine-aided Classification Methods of Domain Concepts. 现代图书情报技术, 2011, 27(10): 34-39
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
专业概念机器辅助分类方法研究*
摘要
使用万方数据1987-2009年的专业文献数据,抽取所有工业技术类的16个二级类文献,随机统计这些文献中作者关键词的专业词频与类目间相对词频值的标准差。实验结果为50%以上的关键词可以归到1个类目中,将近90%的关键词可以归到1-3个类目中;如果关键词属于3个或3个以上的类目,当词频小于11时,16%的词可归类,当词频等于大于11时,49%的词可归类。实验结论认为,通过词频统计与标准差计算可以实现机器辅助的关键词快速分类,显著减轻传统人工分类方法的工作量。
关键词:
叙词表; 本体; 概念; 分类; 词频
中图分类号:G254
Research on Machine-aided Classification Methods of Domain Concepts
Abstract
With 1987-2009 documents in Wanfang Data, the paper collects all documents of industrial technology. Within 16 second categories, it computes the keywords frequency, and calculates the standard deviation of keywords within relative categories. There are more than 50% keywords can be attributed to one category, and nearly 90% keywords can be put in 1-3 categories. If keywords belong to 3 or more than 3 categories, when the word frequency is less than 11, 16% of the words can be categorized; when word frequency is equal or greater than 11, and 49% of the words can be categorized. Test concludes that keywords can be classified by machine-aided with keyword frequency statistics and standard deviation, which is better than traditional classification method.
Keyword:
Thesaurus; Ontology; Concept; Classificationfrequency
1 引 言
1980年,我国完成《汉语主题词表》(简称《汉表》)的编制,1991年,对自然科学部分进行了修订,《汉表》对我国信息组织与情报检索发挥了不可磨灭的作用[ 1]。2010年,中国科学技术信息研究所在全国相关科研机构和领域专家的参与下,启动了《汉表》(工程技术版)的编制与修订工作,项目的重要特点是探索网络环境下叙词表的编制方法,主要包括工程技术领域叙词表的选词和词间关系建立方法。其中词汇资源除了继承传统叙词表的规范术语外,还包括来自万方、维普等学术文献的300多万关键词。叙词表编制重要工作包括同义词归并、概念凝练与遴选、建立词间关系等,这些工作都需要对300多万词汇资源进行专业分类,然后在相应专业大类内,通过领域专家选择词频较高关键词作为叙词表的侯选词汇。概念分类的传统方法主要由人工完成,对数量如此庞大的词汇进行人工专业分类,既不现实也不可能。在网络环境下,基于海量文献属性,可以借助词汇词频、文献分类等统计信息,使用标准差寻找显著归类信息,通过机器辅助完成概念术语的基本分类,并加以人工判断,快速实现概念的准确分类。本文是关键词机器辅助分类研究的实验探索,创新地使用标准差的方法,基本实现了机器辅助的专业术语分类,为叙词表等知识组织体系的构建奠定了基础。
2 术语词汇分类方法研究进展
自从人类有了文明记载以后,就有了通过分类去组织和管理各类信息的思想。信息通常具有一定的主题,可以通过一些概念去描述和表达,对概念的分类是信息组织与知识服务的基础。目前常见的概念分类,例如分类表的类目编排,每个类目可以理解为一个学科分类概念;叙词表的范畴归类,每个范畴号下可以包含一系列相关的概念;本体的不同概念也可以通过概念的不同属性进行多维的分类[ 2]。根据概念的使用范围大小,可以将概念分为专业概念与通用概念,专业概念主要用于表达文献的专业主题,通用概念是那些专指度浅、可在不同专业中通用的泛指词[ 3]。
不同研究领域、不同机构分别对概念、术语和语词给出了不同的定义和解释。本文认为,“概念”是某一具体事物或抽象事物在人类思维中的总体反映,是一类事物在人脑中的概括总结,通过“概念”的理解可以在思维中还原具体事物或抽象事物。“术语”是用于表达领域概念的专门语词,其特征是具有一定的专业性和规范性。“语词”是构成语句的基本单元,可以是自然语言,也可以是人工语言,不同“语词”在句子中具有不同的功能和作用,也可以分成不同的词性,例如名词、动词、形容词、数词、量词等。无论是“概念”还是“术语”,都可以通过“语词”进行描述和表达,当然也可以使用各类编码或符号表达,实质上“语词”同样可以理解为是某种“符号”或“编码”。通常情况下,“概念”含义具有唯一性,即一个概念表达一种或一类事物;“术语”和“语词”可以是一词一义,也可以是一词多义,例如“运动”在不同的语境下,可以是“体育运动”,也可以是社会活动中的“革命运动”[ 4]。
在叙词表、本体等主题法知识组织体系的编制过程中,规范术语的选择与分类非常重要,传统叙词表的词汇分类主要通过人工完成,在网络环境下,词汇分类完全通过人工完成具有较大困难。概念通过一定的术语来表达,在文献中,关键词通常是表达文献主题的常用术语。选择词频比较高的专业术语,表达相应的概念,是构建各类知识组织工具的基础,Crouch等[ 5, 6]报道过使用文本关键词自动生成叙词类别,但没有解决概念词汇分类问题;侯汉清等[ 7, 8]在知识组织系统的互操作中对概念间映射、类目与概念映射等有大量报道,研究了基于受控词表互操作的集成词库构建方法,设计了中文信息自动分类用知识库,使用的数据是具有人工标引分类、主题、关键词信息的文献记录,与关键词分类有部分知识关联[ 9],其中关键词分类方法主要依靠人工完成;知识组织体系自动构建方面,也有大量报道,例如在建立叙词表词间关系等方面[ 10, 11],Bechhofer等[ 12]论述过关键词收集在数字图书馆语义检索中的重要性,但没有研究关键词的分类问题, Wartena等[ 13]研究了通过关键词将叙词表与大众分类法进行映射,实现方法中也涉及关键词分类问题。
3 研究过程与方法
3.1 专业概念机器辅助分类方法思路设计
基于网络环境构建知识组织体系中,对词汇的专业分类非常重要。将大规模的词汇按专业分类归入不同的专业类目,在专业类目内,领域专家可以对可控数量的词汇进行概念凝练,建立词间关系等。传统方法对专业词汇的归类主要通过人工实现,但在网络环境下,面对海量的词汇资源,人工方法费时费力,几乎无法完成。本文设计了基于专业词汇的文献分类信息、词频统计、类目间相对词频标准差等,通过计算寻找专业词汇可能属于的主要类目,从而利用计算机辅助自动解决词汇的分类问题。
3.2 实验材料与统计方法
(1)实验材料与类目统计
实验材料使用万方数据学术论文库,该库基本采用《中图法》的分类体系,文献共分22个一级大类。一级大类“工业技术”下分16个二级大类,分别是一般工业技术(TB),矿业工程(TD),石油、天然气工业(TE),冶金工业(TF),金属学与金属工艺(TG),机械、仪表工业(TH),武器工业(TJ),能源与动力工程(TK),原子能技术(TL),电工技术(TM),无线电电子学、电信技术(TN),自动化技术、计算机技术(TP),化学工业(TQ),轻工业、手工业(TS),建筑科学(TU),水利工程(TV)[ 14]。
抽取1987-2009年所有学术论文文献数据,提取论文的关键词,经过去重、去掉词频为1的关键词等数据清洗工作,得到总量约300多万个关键词,从这些词中随机抽取1万个关键词,用于本实验。由于课题是《汉语主题词表》(工程技术版)的编制,所以抽取的关键词必须是在一级大类“工业技术”下的文献中出现过的关键词。
为了探索一个概念通常情况下出现在几个类目中,统计了这1万个关键词在16个二级类目文献数据库中的类目分布情况。例如,1个关键词只在一个类目文献中出现过,则其分类类目是1;如果一个关键词在5个二级类目文献中出现过,则该关键词的分类类目为5。
(2)词频与标准差统计
二级大类文献中的词频统计方法:统计了每个词在万方数据16个工业技术的二级大类文献中关键词字段出现的频次,通过这个数据,可以大致了解每个关键词在各个专业文献主题大类中的分布情况。二级大类词频代号为DF(Department Frequency)。将每个关键词在16个类目下出现的词频(DF)求和作为该词的总词频。总词频代号为TF(Total Frequency)。
相对词频值统计方法:考虑到关键词词频数值差异较大,所以针对每个关键词,又计算了相对词频值,对数据进行了归一化处理。方法是用每个关键词分别在16个二级类目中的词频除以各自的总词频,其值保留4位小数。相对词频值代号为DF/TF。
标准差统计:使用SPSS统计软件,统计每个关键词在二级类目间的标准差。由于关键词通常是一个或多个类目,所以实际统计的标准差包括在16个类目间相对词频值的“所有类目标准差”;也统计了每个关键词在二级类目下词频不是0的类目间的“相关类目标准差”。
3.3 结果与分析
(1)关键词类目数量分布及单一类目归类
实验用的1万个关键词分别在16个二级类目文献数据库中分布情况如表1所示。
| 表1 拥有不同类目数量的关键词分布情况 |
可以看出,有将近一半的关键词(43.45%)只出现在1类文献中,30%以上的关键词出现在2类文献中,在1个、2个或3个类目文献中出现的关键词总体比例将近87%,这三种情况比例大约为4:3:1。表1中少量的关键词在多数类目文献中同时存在,例如,19个关键词在16个文献类目中都出现过,1.5%的关键词具有10-16个类目,约10%的关键词有4个以上的类目。分析以上数据,得出基本结论为代表文献主题的关键词可以按专业进行分类,90%左右的词主要集中在1-3个类中,10%的词具有可以归到多个类目的可能。
可以直接对将近一半的只在1个类目文献中出现的关键词进行初步分类,出现在哪类文献中,关键词就归到该类目中。浏览具体数据,也基本符合以上判断。例如,4 345个只在1个类目文献中出现的关键词,词频高的词例如“硬盘保护卡”(词频51),全部出现在TP类(自动化技术、计算机技术)文献中;词频适中的关键词“河势控制”(词频10),全部出现在TV类(水利工程)文献中;词频低的关键词“软土下卧层”(词频3),全部出现在TU类(建筑科学)文献中。无论词频高低,这些关键词多数都可以归到相应的类目中。
关键词浏览与判定中也发现个别例外情况,例如“甘薯茎尖”(词频8),全部出现在TS类(轻工业、手工业)文献中,按学科分类“甘薯”本应该属于“农业科学”。这种例外也属于正常现象,即这个概念同时出现在不同的一级大类中,按主题属于农业科学范畴,但实际应用或研究也会出现在食品加工的文献中。叙词表中对于这样的概念分类,需要根据叙词表的使用目的与应用领域,在领域专家的参与下具体给予合适的范畴号。
(2)在两个类目中出现的关键词归类
表1中有32%的关键词、约3 246个关键词在2个类目的文献中出现过,以下为具体数据的统计与分析。
对于关键词在2个类目文献中出现的情况,统计了每个关键词在二级类目下词频不是0的类目间的“相关类目标准差”。标准差范围大小与对应的词汇及累计比例分布情况如表2所示:
| 表2 在2个类目文献中出现的关键词标准差分布情况 |
基本假设是标准差越大,则该关键词在不同类目出现频次差异越大,或分布越集中。观察具体统计数据,发现一些对关键词分类具有参考价值的特征。
表2中3 246个在2个类目文献中出现过的关键词,有1 389个关键词(约43%)的标准差为0,这些词的特征为在2类文献中出现的次数相等,即没有差异,所以标准差等于0。对于这些词,可以基本判断应该同时归到2个类中。例如“建筑结构胶”词频为16,在TQ(化学工业)类文献中出现8次,在TU(建筑科学)类文献中出现过8次,对于这类在2个类目中词频较高的词,基本可以直接认定同时属于2个类目。另一些词频较低的词,例如“硫醚化”,词频为2,在TQ(化学工业)类文献中出现1次,在TE(石油、天然气工业)类文献中出现过1次,具体如何归类,更多情况下需要人工判断。
对于表2中标准差不等于0的关键词,根据人工力量的投入情况,分段进行人工浏览判定与语词归类。例如标准差大于0.25的约20%的语词,假定这些词可以明显归到1个类中,浏览分析这些语词并人工辅助分类,经过具体语词观察与判定,这些词多数应该归到1个类中,标准差高的具体例子如“浅埋煤层”,标准差为0.48,词频为87,85次出现在TD(矿业工程)类文献中,2次出现在TU(建筑科学)类文献中,基本可以判定该关键词属于TD类;标准差次高的例子如“拨号”,标准差为0.25,词频为28,21次出现在TP(自动化技术、计算机技术)类文献中,7次出现在TN(无线电电子学、电信技术)类文献中,也可以判定该关键词主要属于TP类。
以上数据说明,标准差大于0.25的关键词,多数可以归到1个类目中,这类词约占20%,共650个左右关键词,与前面的4 300多关键词相加,总体关键词中50%的关键词可以放到唯一的类目中。标准差等于0或小于0.25的关键词,词频相对高时这些关键词应该归到2个类中,词频低时需要人工判断。
(3)在3个及3个以上类目中出现的关键词归类
在3个或3个以上的文献类目中出现的关键词(共2 409个),同样可以将关键词归入到一个类或几个类中,使用标准差作参考去判断。即如果标准差为0,则意味着该关键词可以平行地给定几个类号,1个关键词拥有的类号越多,该词有两种较大的可能性,要么是通用词,要么是专业词,但应用领域相当普及,会应用到所有的专业领域中。前者例如“调节”、“优化”、“设计”等,标准差都小于0.07,在16个文献类目中都有分布,属于通用词。如果标准差不为0,则在相同类目的条件下,标准差越大,类目会越集中,这样的例子在不同级别的类目中都可以找到,例如“变压器”在16个类目中都有分布,标准差约为0.21,通过相对词频值可以发现,该词在TM类中值显著高,达到了3 634/4 144,即该词多数分布在TM文献中,而且具体分类应该只给定1个TM类号更恰当,其他词如在15类中都有分布的“数学形态学”、14个类目中都有分布的“聚丙烯”、13个类目中都有分布的“知识获取”、12个类目中都有分布的“乙二醇”等,虽然在多个类目中都有分布,但均应该只给定1个类号。
在3个或3个以上的文献类目中出现的关键词中,最大词频为21 252,最小词频为3,中位数为11,也就是说50%的关键词总词频小于11。为了了解在多个类目中出现的关键词分类分布特征,统计了每个关键词在类目间词频不是0的“相关类目标准差”。词频与标准差两维信息关键词分布如表3所示:
| 表3 总词频与标准差两维信息下关键词分布 |
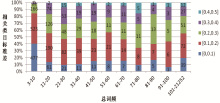
对应数据的比例分布如图1所示:
 | 图1 总词频与标准差状态下关键词数量分布 |
可以看出,低频词(词频3-10,关键词数1 187个)占50%,这些词与词频等于大于中位数11的关键词特征有着显著的不同,表现为词频低,标准差大于0.2的关键词只有16%,说明这些概念使用频次低,在不同类目文献中出现偶然性大,多数概念没有明显的归类特征。对于大于词频中位数11的关键词,不同级别标准差关键词分布比例基本相同,标准差大于0.2的关键词约占49%,说明这些概念使用频次较高,虽然在不同类目文献中都有可能分布,但有接近一半的概念有明显的归类特征,可以归入1个类或少数类。
以上统计数据基本结论为,在3个或3个以上的文献类目中出现的关键词,词频低时归类特征不明显,词频高时有一半的关键词可以归入一个类或少数类中。这也表明,随着词频的增大,概念的使用领域越明显,即一半概念趋向成为专业概念,另一半则趋向为通用概念或专业通用概念。
4 讨 论
通过以上结果分析可以认定,通过关键词的词频、标准差等信息,可以将关键词所代表的概念进行机器分类,再辅以人工判定,基本上可以将表达专业术语的关键词进行分类,大大简化了依靠人工分类的传统方法,降低了选词的工作量。
4.1 词频统计归类阈值分析
Salton[ 15, 16]报道了自动标引与信息检索中,基于个体文献关键词词频统计特征,包括取对数等计算方法,用于表达文献主题,实现对文献的标引与检索。本文统计分析了关键词在专业分类文献中的词频及标准差,通过标准差大小确定关键词的归类,是概念主题研究中的不同探索方式。标准差方法涉及到阈值问题,数值越接近0.5,则关键词越集中在一个类中。从实验数据可以发现,标准差是一个从0到0.5的渐变过程,这样,选择数据时就存在一个阈值问题,例如选择标准差大于0.2的所有关键词,或选择大于0.25的关键词,难以判断哪种效果好。这需要根据具体数据进行反复实验,阈值高,则选定词的类目判断工作量小,但低于阈值的词的分类工作量就大,阈值低则正好相反。探索出合适的阈值后,领域专家人工判定仍然非常重要,即使是阈值相同,也会出现按主题归类时是一种归类方法,按应用归类时是另一种方法的现象,所以阈值与人工判断是协作完成的。
4.2 关键词分类与概念分类
通过关键词在不同类目文献中出现的词频与标准统计,进行关键词归类。从定义可以看出,关键词、专业术语、概念有一定的区别。但对于叙词表编制,对关键词进行分类,实现概念的分类,理论上是可行的,因为概念也是使用语词表达的,如果是一个特定的语词,则可以理解为专业术语,如果是唯一的术语,则可以代表专业概念。所以可以从关键词分类出发,研究叙词表概念术语的分类问题。关键词词频统计实际上是使用了该关键词作为主题的文献数的统计,是文献数量的统计,按照经验理解,一篇文献的主题通常情况下是利用几个关键词组合表达的,所以,从关键词表达的主题到文献的分类主题,决定了关键词的分类会有一些误差。本文认为词频可以解决主要问题,即只要在专业类目文献内关键词的词频高,则该关键词基本上属于这个类。
在已有报道中,使用Dice测度方法计算类目与关键词的共现频率,通过相关度大小进行加权计算,实现关键词分类,或者通过计算关键词的相关度,去识别同义词[ 7, 8],共现的部位不同,计算效果会有差异。标准差作为一种常见的数学统计方法,更加简单、容易实现,标准差方法是实现关键词分类的一种方法。
4.3 专业概念术语在分类等级体系中进行细分及类目过少问题
无论是传统分类法还是叙词表的范畴表,一般都是多级分类,传统分类法可以分到6级以上,范畴表通常也有2-3级。所以将概念分到工业技术的16个二级大类以后,下一步工作是如何分到更合适的分类级别中,这部分工作理论上可以通过词频与标准差统计获得一些帮助,例如,在每个二级大类下,统计语词在三级大类文献中出现的词频大小,以及统计相关类目的标准差。但在具体分类中,概念越向下细分,词频越小,统计数值参考性降低,所以需要更多领域专家人工参与分类,或者说人工作用更大一些;另外,往三级以下分类,已经基本集中到某一专业,因此专业人员人工分类更加准确、快捷。
标准差方法更适合同级类目是几个或以上的类目间统计实验,不适合类目过少的情况。类目少时其实可使用更简单的方法,例如,如果只有A和B两个类,而某关键词全部出现在A类分类文献中,则该关键词直接属于A类,不用标准差去判断,当然,即使是这样,用标准差也可以进行区别和分类。在本文实验中,“工程技术”二级大类部分,有16个二级类目,可以使用标准差方法。事实上,如果是使用《中国图书资料分类法》[ 17],整部分类法共有5.6万个类目,所以标准差方法有很大的适用范围。
5 结 语
通过专业文献数据库关键词的词频与类目间相对词频值标准差统计,可以自动将表达概念的语词进行分类,实现对专业概念的机器辅助分类,找出代表专业概念的核心专业语词,从而显著减轻人工分类工作量。基于词频的分类,使概念分类具备了文献和词频的数据支持,具有统计数据依据,加上专业领域人员人工判断与细分,可以实现对专业概念在机器辅助下的精确分类,从而为知识组织体系的快速构建奠定基础。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|