

{kind=link}
{kind=link}
{kind=link}
{kind=link}
专利技术功效矩阵构建研究进展
引用本文
陈颖, 张晓林. 专利技术功效矩阵构建研究进展. 现代图书情报技术, 2011, 27(11): 1-8
Chen Ying, Zhang Xiaolin. Research Progress on Construction of Patent Technology-effect Matrix. 现代图书情报技术, 2011, 27(11): 1-8
Permissions
Chen Ying, Zhang Xiaolin. Research Progress on Construction of Patent Technology-effect Matrix. 现代图书情报技术, 2011, 27(11): 1-8
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
专利技术功效矩阵构建研究进展
关键词:
专利分析; 技术功效矩阵; 专利地图; 专利工具; 专利软件
中图分类号:G350
Research Progress on Construction of Patent Technology-effect Matrix
Abstract
This paper discusses and analyzes the current research status from the following three aspects: the construction process and lexical source of the matrix; the definition, differentiation and extraction of the technical and effect words in patents; words clustering and the generation of matrix structure. Then, it points out the problems and challenges of current research.
Keyword:
Patent analysis; Technology-effect matrix; Patent map; Patent tool; Patent software
1 引 言
专利技术功效矩阵分析,能通过专利文献反映的主题技术内容和技术方案的主要技术功能之间的特征研究来揭示技术和功效二者之间的关系。因此,能较好解析专利中较隐晦信息内容和潜在技术特征,掌握技术重点或空白点,规避技术雷区。
专利技术功效矩阵的构建是专利技术功效矩阵分析的前提。由于专利技术功效矩阵的制作需要情报分析人员、领域专家或企业技术人员对每篇专利文献详细解读,了解其中的技术、功效信息后才能进行,因此很难直接用专利分析软件生成。从现有研究来看,专利技术功效矩阵结构构建还存在很多需深入探讨的问题。本文从三方面总结研究现状,分别是:专利技术功效矩阵构建流程和矩阵词汇来源;专利中技术词、功效词的界定、区分、抽取;词聚类及专利技术功效矩阵结构生成。
2 专利技术功效矩阵构建流程和矩阵词汇来源
2.1 专利技术功效矩阵构建流程
专利组织与主题分析的步骤与专利技术功效矩阵的制作密切相关。曾元显[ 1]将其分为选题、筛选、转换、摘要、归类、呈现、解读几个步骤,如图1所示。其中,摘要、归类和呈现与专利技术功效矩阵构建密切相关。
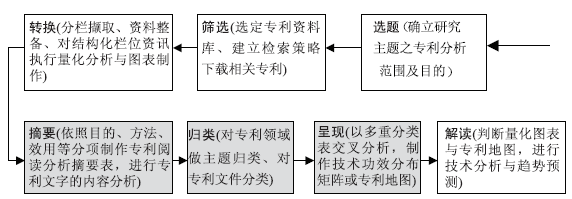 | 图 1 专利组织与主题分析步骤[ 1] |
从掌握资料看,矩阵构建总体上分为以下步骤[ 2]:
(1)拟定技术及功效分类架构;
(2)专利文献解读分析;
(3)制作专利文献摘要分析表(专利标的、目的、功效、技术及专利要件);
(4)数据归纳整理(技术图表、功效图表);
(5)技术功效矩阵图。
其中,步骤(1)、(2)是前提和关键,目前主要由人工完成。
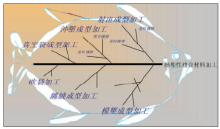
专利分析家依据知识背景对要分析的专利数据资料库形成专利技术分类和专利功效分类,此步骤可生成鱼骨图[ 3],如图2所示:
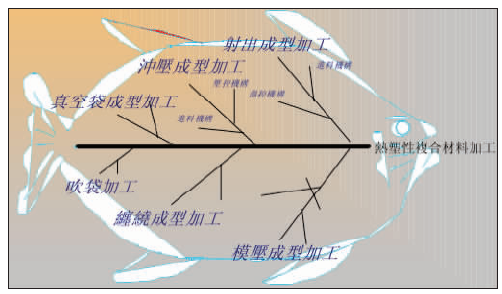 | 图 2 热塑性复合材料加工专利技术功效鱼骨图[ 4] |
根据鱼骨分类阅读专利说明书完成技术、功效分类勾选清单。当前这两步研究较少,大多集中在后三步自动实现上。
王圣顺[ 5]利用人工定义技术功效相关词并建立本体,用于后续抽取摘要及语义分析。其思路为:人工定义专利技术、功效分类,将其作为系统资料库;在此基础上建立本体论分类架构,实现本体语义分析,并利用本体知识层级关系来建立专利组件与技术、功效词间的对应模式。进而缩短专利分析人员解析专利核心价值的时间,提高专利搜寻准确性和效率。
2.2 专利技术功效矩阵词汇来源
专利信息内容庞杂,词汇生僻,技术、法律、经济术语较多。现有研究中,专利技术功效矩阵的技术、功效分类用词直接由人工给出,其逻辑依据、词汇选取标准等问题尚不明确。了解专利的技术和功效分类体系有助于分析专利技术功效矩阵的词汇来源及构成。
(1)专利技术分类体系
发明的技术主题或者是与某物的本质属性或功能相关,或者是与使用或应用某物的方法有关,其中,“物”指任何技术事物,不论其有形或无形,例如,方法、产品或设备[ 6]。此思想体现在IPC设计中, IPC遵循“功能分类”和“应用分类”规则。但IPC的分类即使到小组也很难体现具体的、适于做专利技术功效矩阵结构的技术词,主要原因在于IPC强调整体性分类,较少考虑物的构成细分,还在于其功能性分类和应用性分类中所用的词汇较为概括和宽泛,难以体现具体的技术点。
日本FI(File Index)分类法是将IPC细分和扩展得到的,用于扩展IPC在某些技术领域的功能。FI分类号由细分号、文档细分号和方面分类号构成[ 6]。其中,方面分类号是从技术主题的不同技术特征,在IPC下以不同角度细分的类号。FI的方面分类号覆盖类别不全面,也没有进一步的细分,因此也不适于直接构建矩阵结构。
日本F-term分类法[ 7]在IPC和FI基础上再分类或细分类,适于多角度检索。F-term从多角度技术主题(也称为技术视点)对专利进行分类。技术主题下又可细分为若干个子主题,从多方面展现专利技术特征,如目的、用途、结构、材料、制造方法、使用或运行方法、控制装置等。图3为“碳,碳化合物”专利的F-term分类表,分类号为4G046,有27个大技术视点(代号为AA, AB, BA等),每个大视点又可细分[ 8]。F-term分类法中的部分技术主题及其子主题可用于构建专利技术功效矩阵结构,但F-term没有区分技术和功效,且很多主题内容适于多个领域,较为宽泛,仍需进一步人工判读和细化。
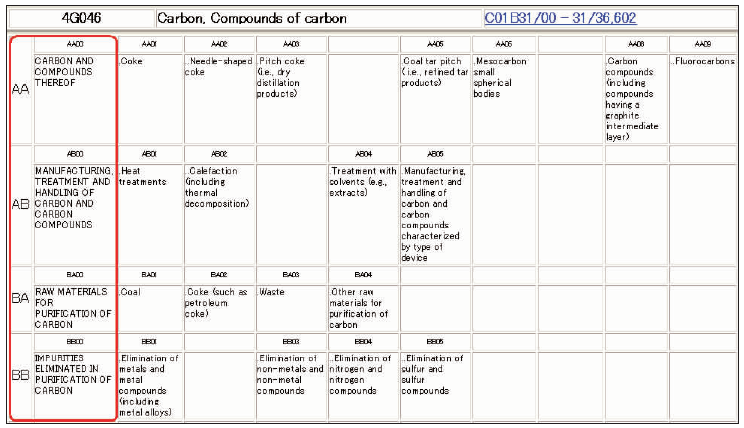 | 图 3 “碳,碳化合物”专利的F-term分类表[ 8] |
国外研究, NTCIR会议的“专利挖掘与翻译”任务[ 10]发表了大量相关研究论文,并利用IPC、F-term来辅助检索和分类。这些研究大部分结合实际专利数据集讨论利用IPC、F-term进行分类算法改进。
国内研究,赖士焕[ 4]将商品/制品分类体系作为上位概念;技术体系作为下位概念;技术体系又以关键技术作为分类依据,进而建立阶层式技术分类体系。高佐良[ 2]说明了可用IPC、UPC、产业分类、自定义分类或上述分类的组合作为专利地图的分类法则,并给出锂二次电池电极的专利技术分类架构。
(2)专利功效分类体系
NTCIR-4中“可行性研究”任务[ 11]的主题是提供某一特定技术领域内对自动生成的专利地图的鸟瞰,专利地图是包括“要解决的问题”、“解决方案”两个维度的矩阵,“要解决的问题”类似于功效。
国内研究方面,赖士焕[ 4]提出功效分类基准:制程简化;降低成本;节省能源;提高良率;提升性能;提升安全性、稳定性等。更多学者针对不同领域提出相关功效分类,如黄海[ 12]把门座起重机的总功能分为物质功能和精神功能。
陈明原[ 13]透过专利资料库搜集相关知识的专利资料内容,经由人工整理出其所属的知识领域分类,从其内容过滤出相关代表词汇,进一步构成以本体论为精神的阶层式分类模型。其技术及功效分类是人工分析专利得到的,是建立专利分类系统的基础。
陈冠帆[ 14]利用本体论观念建立动力手工具的知识结构,通过分析专利文件定义其技术、功效的类别,同时找出对应的关键词汇;应用贝氏理论技术,建构出一个专利文件的技术、功效分类系统;再配合利用TRIZ理论(发明问题解决理论)发展出TRIZ-PHT矛盾冲突矩阵表,利用其特性找出建议方法来达到创研效果。其研究与陈明原的研究大体相似,都通过人工分析专利来定义技术、功效类别。
专利功能归纳方面。TRIZ理论[ 15]将高难度问题和要实现功能归纳总结,并赋予每个功能一个代码。也有网站或软件通过分析大量专利,总结归纳出专利中主要的功能和功效列表。如CREAX网站提供功能数据库[ 16]查询,系统会列出Solid、Liquid、Gas和Field 4种处理对象所选功能的专利案例。More Inspiration网站提供专利创新性检索服务,并按产业分类提供相应功能列表。汽车、自动产业的功能列表如图4所示:
 | 图 4 More Inspiration网站功能列表[ 17] |
3 技术词、功效词的区分和抽取
3.1 技术词、功效词的区分
专利中技术词、功效词的界定和区分是矩阵构建的关键,很大程度上决定矩阵结构的合理性。目前相关研究主要有专利内容结构、专利语义特征和专利用词特征三方面。
张惠等[ 18]分析了USPTO专利内容结构,指出功能和结构知识主要分布于专利摘要、权利要求书部分。知识类型中没有明确划分技术知识和功效知识,而是依据目的、手段、原理、结构、功能结构等方面阐述。这反映出专利中技术和功效没有明确区分,要视专利分析任务来确定。
Tseng等[ 19]将专利内容分为8个子部分,进一步判断技术词、功效词的分布,认为人工分析和自动分析情况下技术词、功效词分别主要分布于摘要及各部分摘要中。可见,单独依据专利内容结构来区分技术和功效过于粗略。
林士能[ 20]对专利声明进行语义结构分析,在建立领域知识本体的基础上,利用自然语言处理技术标记专利申请,用正则表达式撷取专利的重要信息;Cascini 等[ 21]、刘翰卿[ 22]利用英文SAO结构句型(主词、动词和受词)判断专利的主要功能结构,并抽取专利摘要。所抽取的语句虽不能直接作为矩阵的技术分类和功效分类,仍需专家判读,但在一定程度上减轻了专家的工作量。
专利用词方面, Shinmori等[ 23]提出基于“Cue-phrases”的修辞结构分析法,并对日本专利的句式及专利声明中的修辞关系进行说明。Tseng等[ 19]提出“Clue Words”概念,认为其是揭示专利目的、功能和目标或专利改进的词列表,并基于专家经验提出25个主要与专利背景有关的线索词:
| Advantage | Difficult | Improved | Overhead | Shorten |
|---|---|---|---|---|
| Avoid | Effectiveness | Increase | Performance | Simplify |
| Cost | Efficiency | Issue | Problem | Suffer |
| Costly | Goal | Limit | Reduced | Superior |
| Decrease | Important | Needed | Resolve | Weakness |
这些词有利于生成专利摘要,可较好提取出专利背景、目的和功效信息。也有学者指出依据“a, an”等冠词来判断专利组件所在位置,依据“for”来判断专利的用途等。
TRIZ理论把专利的功能高度概括化,使得所有专利的功能本质上都表现为物-场模型中三元素的相互作用与组合。因此,可通过分析词属于哪种基本元素来判断技术相关或功效相关。
3.2 技术词、功效词的抽取
识别出专利中技术词、功效词后,要利用相应算法和规则将其抽取出来。和信息抽取有关的消息理解会议[ 24](Message Understanding Conference, MUC)、自动内容抽取会议[ 25](Automatic Content Extraction, ACE)极大推动了信息抽取领域的发展。
(1)语言规则识别方面,史东娜[ 26]通过对科技论文语言学特点和文档结构的分析,指出文本的“兴趣领域”和“敏感区域”,进而抽取候选术语。Hulth[ 27]指出利用语言知识能改善自动抽取,并提出可用于抽取名词或名词短语的常用语法标识序列模式。Revere等[ 28]以基于机制的文本代理(Document Surrogate)方式表达科研论文中的知识,但这种方式要有相应词表的支持。
(2)基于特征词抽取方面, Sarkar[ 29]定义了针对医学领域的线索词、线索短语列表用来生成文本摘要,线索短语如“We report”, “We present”, “World Health Organization”, “Prevention of”等。Todirascu等[ 30]利用语法信息和领域本体知识来识别特定领域的本体元素(术语及概念),其所用领域知识由专家构建,由专家列出功能词列表,并赋重要性数值。此外,还有Chan[ 31]的研究等。杨陟卓等[ 32]提出基于特征抽取的文档信息过滤匹配算法,通过基于标题的特征词提取(由用户提供需求特征词库),使用改进的TF-IDF对各个特征进行加权合成;并利用过滤不符合条件的特征词等技术提高信息检索质量。仲兆满等[ 33]提出“结构关键词”概念来描述文章的逻辑结构,依据所构造的包括11个类型的结构词词表提取结构关键词,从而在信息抽取中增加了对文档结构的语义理解。此外,还有基于事件特征词的信息抽取,如邓擘等[ 34]的研究。
上述研究主要针对科研论文的信息抽取,对专利的信息抽取还应结合专利特征深入研究。目前,相比专利号、申请人等结构化信息,对专利摘要、专利声明等非结构化信息抽取的研究相对较少。然而,正是这些非结构化信息记录了大量关键的技术、功效信息和创新点。现有研究主要有以下几方面:
(1)基于统计方法的专利术语抽取。刘磊[ 35]在手工构建双语术语语料的基础上,采用条件随机场分析自动抽取中英双语术语,其不足是需大量人工标注语料支持,对于临时性专利分析任务来说获取标注语料存在困难。
(2)基于领域本体知识的专利中重要概念抽取。如姜彩红等[ 36]、王圣顺[ 5]、吕祥惠等[ 37]的研究。姜彩红等[ 36]采用知识工程方法,分析“新能源汽车”中文专利摘要,提出基于本体的中文专利摘要抽取模型。其不足是需建立领域本体,工作量大,本体质量难以保证,分析方法依附于本体,难以大范围适用。
(3)基于专利撰写规则的抽取。Hui等[ 38]提出适于非结构化信息抽取的概念模型来处理表达层次和技术复杂度的问题。模型着眼于“问题——解决方案”之间的关联,设计考虑了科研论文和专利两种文献,并通过原型系统验证了方法的有效性。Shinmori等[ 23]将日本专利声明划分为三种基本描述模式,分别为“Process Sequence Style”、“ Element Enumeration Style”和“Jepson-like Style”,并总结了可用于专利声明分析的线索词,探讨了利用线索词对专利进行修辞结构分析。类似的还有Yang等[ 39]的研究。
(4)基于专利语法结构的方法。如Cascini等[ 40]较好地对专利声明进行语义分析,通过语法分析器鉴别句子三元组中的主题、行为和对象。主题和对象指系统组件,行为指组件完成的功能,依据分析目的不同,对Subject、Verb和Object给予不同的权重有可能建立一个可信的术语间的功能关联。Parapatics等[ 41]分析了专利声明的结构,并使用一系列的规则和启发式将其分解为若干单元,进而改进自然语言处理的效果。
(5)在专利术语抽取方面也涌现出一些软件工具。Invention Machine's Knowledgist[ 42]利用语义技术阅读分析专利文献,从中抽取出技术知识,并将其以“问题-解决方案”索引的形式呈现。KeyPat[ 43]可从专利中抽取名词关键词和名词短语,主要面向专利翻译中的资源重用,此工具主要由术语抽取模块和调整过滤模块构成,不依赖术语库,而只依靠单一文本中的统计信息进行抽取。上述工具侧重对专利中术语及名词类关键词的抽取,与表达技术点、功效点的词汇抽取不完全相同。
4 词聚类及阶层式概念结构生成
4.1 词聚类
词聚类(Word Clustering)相关研究分布较为广泛。其中很多研究对专利中技术词、功效词的聚类及其优化有借鉴作用。
(1)领域术语筛选方面,李勇[ 44]提出一种利用CBC聚类方法从抽取的术语文本中自动剔除非领域术语的方法,但并不适用于专利中技术词和功效词术语性不强的情况,而且此方法还需训练语料库的支持。
(2)文本特征向量降维方面, Saha等[ 45]提出包含多个词相似度计算方法的词聚类技术,并基于统计方法生成一个用于重要词选择的语料库。
(3)基于规则聚类方面, Han等[ 46]提出基于规则的领域词汇聚类方法,用来进行聚类特征的表达,但这些规则要依据不同的领域数据进行归纳总结。
(4)基于语义聚类方面, Tseng等[ 19]改进了特征词的共现范围,将其由全文共现缩小到概念所在段落共现,从而提高了概念间共现的相关度。Khelif等[ 47]针对生物医学专利提出由语义注释驱动的专利聚类技术,此种技术要建立领域本体并对专利进行语义标识,需UMLS词表支持。
(5)利用WordNet语义词典优化聚类的研究也引起了人们关注。如 Sedding等[ 48]指出用WordNet查找上位词只在5层之内有聚类优化的效果,并指出深入研究这一现象有助于确定能产生最好优化效果的层数。Chow等[ 49] 研究了利用WordNet辅助动词聚类。Recupero[ 50]将WordNet应用于WLC(WordNet Lexical Categories)技术和WO(WordNet Ontology)技术为文档聚类创建低维、结构好的向量空间,说明其在特征向量降维及利用同义关系上的作用。当然,也有研究认为利用WordNet不一定能优化聚类[ 51]。
4.2 阶层式概念结构生成
阶层式概念结构生成主要应用在叙词表生成中。此外,利用层次聚类也能大致体现聚类词汇之间的上下级关系,但此种关系仍要由专家辅助判断。相关研究主要有杜慧平等[ 52]提出一种基于聚类的词表等级关系自动识别方法,利用基于语义相似度的词聚类方法把不同主题的词汇聚集成簇。张琪玉[ 53]提出可依据具有相同语素的词和词组之间的聚类现象,利用字面相似聚类法辅助构造词族表。仲云云[ 54]用Dice测度算法结合字面相似度算法计算词汇间相似度,进而聚集词汇,并默认词长短的词汇为上位词,包含该词汇的词汇为下位词,其余作为相关词汇来识别等级关系。Dhillon等[ 55]针对词聚类中存在的次佳词聚类及计算花费高的问题,提出一个用于特征选择的总体准则,优化了层级文本共词聚类的效率。
5 问题与挑战
专利技术功效矩阵构建尚存在很多问题值得深入研究,给广大专利分析人员和情报专家提出了挑战。
5.1 专利技术功效矩阵构建流程和矩阵词汇来源方面
目前矩阵构建的关键步骤——“拟定技术及功效分类架构”研究尚浅。虽有研究由人工列出矩阵的技术分类和功效分类,但列出依据、考虑因素等问题尚不明确。矩阵技术词、功效词来源方面,虽有大量与专利技术和功效分类相关研究,但分类标准不统一,现有技术、功效分类用词不能直接用于构建矩阵结构。技术分类或者过于宽泛,或者只适用于具体领域。功效类别有的与具体领域相关、不具有普适性,有的概括性强、不完全适用于具体技术主题专利。
构建流程方面,虽有研究指出矩阵构建的步骤,但对关键的矩阵结构构建少有明确、详细的说明。而且,构建中涉及的关键技术也少有系统研究。
5.2 技术词、功效词的区分和抽取方面
现有区分方法主要用于生成专利摘要,而针对专利技术功效矩阵分析的区分方法不系统、不完善。
(1)抽取方面,现有专利信息抽取的规则总结不完善;SAO语法结构要求具备专利领域词条,对专业背景知识有一定要求;基于线索词的抽取主要针对网页或特定领域科研论文,少有普适性、可用于专利文献的线索词列表。现有抽取技术侧重对名词类术语、名词短语与固定搭配、实体及实体间关系的抽取,对动词类及其他词性类别的专利信息抽取没有深入探讨。
(2)专利中技术词、功效词的区分抽取与术语和概念抽取有很大不同。因此,现有研究不完全符合专利技术功效分析中对技术词、功效词的鉴别与抽取要求,这一特殊问题需要结合信息抽取技术的发展及专利文献的特殊性进行深入探讨。
5.3 词聚类及阶层式概念结构生成方面
目前关于词聚类及阶层式概念结构生成的研究较多,但针对专利中技术词、功效词的相关研究仍较少。如专利技术功效分析对聚类有何要求,相关词汇如何形成技术点、功效点,如何形成矩阵结构等问题有待深入研究。
(1)词聚类方面,针对科研论文中词聚类研究较多,针对专利中非名词类术语聚类研究较少;现有的基于规则聚类方法主要面对特定领域,且大多需要语料库的支持;基于语义聚类的方法要有领域词表支持,难以直接应用在用词较专业、生僻的专利文本中。
(2)阶层式概念结构生成方面,研究较少,现有的基于词表方法、基于词相似度方法、基于词形方法有待深入研究。此外,虽然有部分软件声称可制作专利技术功效矩阵,但其矩阵结构的定义及专利所属技术类别和功效类别的判断仍由人工完成,工具只是在此基础上绘制矩阵结构图。例如, TDA[ 56]、恒库[ 57]、台湾连颖的PatentTech技术领航员[ 58]等。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|