




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
利用关联数据实现机构知识库的语义扩展研究*
引用本文
王思丽, 祝忠明. 利用关联数据实现机构知识库的语义扩展研究* . 现代图书情报技术, 2011, 27(11): 17-23
Wang Sili, Zhu Zhongming. Study on the Semantic Expansion of Institutional Repository Based on Linked Data. 现代图书情报技术, 2011, 27(11): 17-23
Permissions
Wang Sili, Zhu Zhongming. Study on the Semantic Expansion of Institutional Repository Based on Linked Data. 现代图书情报技术, 2011, 27(11): 17-23
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
利用关联数据实现机构知识库的语义扩展研究*
摘要
研究利用关联数据实现机构知识库语义扩展的关键技术,并以中国科学院机构知识库平台CASIR为例,抽取其实体关系并添加约束规则,应用D2R工具进行RDF化的知识呈现和语义标注,最终将其扩展到DC、FOAF、SKOS、ISWC、VCARD等关联数据源。该方法合理可行,为加速实现机构知识库从基础服务版到语义集成资源服务版的发展转变奠定基础。
关键词:
关联数据; 机构知识库; 语义扩展; RDF; D2R
中图分类号:G250.76
Study on the Semantic Expansion of Institutional Repository Based on Linked Data
Abstract
The paper studies on the key technology for realizing the semantic expansion of institutional repository based on linked data. Taking the CASIR for example, the authors extract the entity relationship of the CASIR and add some constraint rules to it, use the D2R to carry out the knowledge representation and semantic annotation as RDF format. Finally, it can expand the CASIR to DC、FOAF、ISWC、VCARD, and so on. In fact, the method lays a good foundation in making CASIR provide not only the basic service but also a real semantic integration service with its rationality and feasibility in the future.
Keyword:
Linked data; Institutional repository; Semantic expansion; RDF; D2R
1 引 言
机构知识库(Institutional Repository,IR)[ 1]是知识开放获取的产物,是大学以及科研机构对其知识资产进行有效管理的工具,也是机构知识能力建设和服务能力提升的重要机制。随着语义网技术的不断推进和发展,从“面向用户”到“面向机器”,从信息描述到知识呈现,从语义隐含到语义揭示,从以概念为中心到以“概念-关系”为中心,面对越来越高的科研需求,传统的机构知识库愈发显得责任重大。因此,必须考虑进行机构知识库的语义扩展,从根本上拓展和丰富机构知识库的服务方式,提高内容发现和传递服务质量,以确保机构知识库的服务比网络上其他信息提供者更具竞争力。
关联数据(Linked Data)[ 2]是语义网技术的核心和关键,它提供了在语义网中使用URI和RDF发布、分享、连接各类数据、信息和知识,部署实例数据和类数据的方法,从而使得人们可以通过HTTP协议揭示并获取这些数据。它强调通过建立已有信息的语义标注和实现数据之间的相互关联,进而形成有益于人机理解的语境信息。基于对机构知识库和关联数据的深入研究,可发现两者是相辅相成的。资源发现对机构知识库建设极其重要,而关联数据的优越性则为机构知识库的资源发现服务提供了增强的途径和可行的方法。因此,利用关联数据来实现机构知识库的语义扩展是一个必然选择。
综上所述,本文主要有以下两个研究目标:
(1)分析机构知识库中数字对象间的知识组织关系,研究利用关联数据实现机构知识库语义扩展的关键技术,为实现机构知识库的语义扩展奠定知识基础。
(2)以中国科学院研究所机构知识库平台(Chinese Academy of Sciences Institutional Repository,CASIR)[ 3]为例,抽取其可扩展的实体关系添加约束规则,同时选择合适的关联数据源,利用RDF进行知识呈现和语义标注,最终实现其和外部数据源间的关联映射。
2 研究现状和关键技术
2.1 研究现状
在过去的几年里,图书馆机构知识库主要通过主题标目和MARC记录数据去实现资源的发现服务,但浏览和精炼结果的深度具有相当大的局限性。
2008年,瑞典联合目录LIBRIS[ 4]率先将国家图书馆级书目数据全部发布为关联数据,使用了FOAF、SKOS、BIBO的混合体,为关联数据的应用提供了方向。此后,英国的哈德斯菲尔德大学[ 5]、美国国会图书馆LCSH[ 6]、OCLC[ 7]、德国国家图书馆、英国国家图书馆、匈牙利国家图书馆[ 8]等都先后将其部分图书馆目录、相关主题规范等发布为关联数据,将关联数据在机构知识库知识组织体系中的应用推向了高潮。同时一些关联数据索引引擎也随之出现,如Sindice[ 9]、Swoogle[ 10]、Waston[ 11]等,它们均提供可以对RDF文档进行关联访问的API。国内相继出现了Arnetminer[ 12]、 Falcons[ 13]等语义搜索引擎。这都为机构知识库的语义扩展奠定了技术基础。
2.2 关键技术
通过上述研究,关联数据在机构知识库方面应用的关键技术总结如下:
(1)利用关联数据技术将机构知识库中的实体关系发布为能够进行语义揭示的关联数据格式。CASIR是围绕研究部门来进行知识组织的,每个研究部门又可分为多个子部门和专题,其数量不受限制。每个专题的内容类型又包含着中国科学院各个研究所存缴的会议论文、期刊论文、学位论文、专著、专利、演示报告等多种数据集。从长远的发展角度来考虑,为满足科研用户尤其是机器用户快速、明确地找到所需资源并获取其语义,机构知识库必须能够提供高质量的语义化访问服务,而不仅仅是普通HTML网页的信息描述。例如,机构知识库可以为不同的研究社群之间以及同一个研究社群的不同子社群之间,提供动态的链接,描述其归属关系;同一个作者的不同科研成果之间、同一个科研成果的合作者之间、同一个资源所属学科主题的上下位关系之间等都可以通过关联数据来关联扩展到这些资源的上下文信息,从而不仅能够让用户更快地获得更多更全面的相关知识,同时还可以增加用户回到机构知识库服务的途径,而且也方便外部关联数据源能够主动地关联到机构知识库。
(2)利用关联数据技术将机构知识库中数字对象间的知识组织体系扩展到已有的关联词表。关联数据构建的基本原则之一就是尽可能地复用已有的关联词表或本体模型。一般最常用在数字图书馆领域的是DC、FOAF、SKOS、LCSH,它们均已实现了全面的关联数据化,搭建了知识组织系统(如分类表、词表)到关联数据之间的桥梁。CASIR自身的知识组织体系虽然不是标准的关联数据组织模式,但是它在建立之初已复用了DC元数据的部分词表规范。因而,进一步的工作便显得十分可行,只需要为已有的类以及属性选择最合适的关联词表源,并明确建立两者之间的词汇映射关系,最终使得机构知识库能够在关联词表的帮助下支持基于SPARQL模式的语义查询和推理。
(3)利用关联数据技术将机构知识库中的实体数据进行语义标注,并扩展到外部关联数据源。关联数据可以为机构知识库扩展资源信息提供结构化的数据基础,提供多个分布式异构数据源整合的关联访问,将来自不同数据源的同一个实体数据进行整合,返回给用户关于该实体的尽可能多的相关信息的统一视图,从而为用户提供资源发现和访问服务的新视角。简单来说,就是关联数据允许机构知识库关联到更广泛的信息资源,并不局限于资源本身的信息,可以扩充科研人员、所属机构、科研成果以及其所属学科主题等其他信息到其他任何一个存在该信息描述的数据源。
以上三点关键技术形成了本文利用关联数据实现机构知识库语义扩展的核心方法。
3 机构知识库语义扩展模块的设计和实现
3.1 抽取实体关系和添加约束
以CASIR中软件研究所的会议论文为例,主要抽取了科研人员(Person)、研究部门(Organization)、会议论文(Paper)、会议(Conference)、学科主题(Topic)这5种核心实体类,其关系如图1所示:
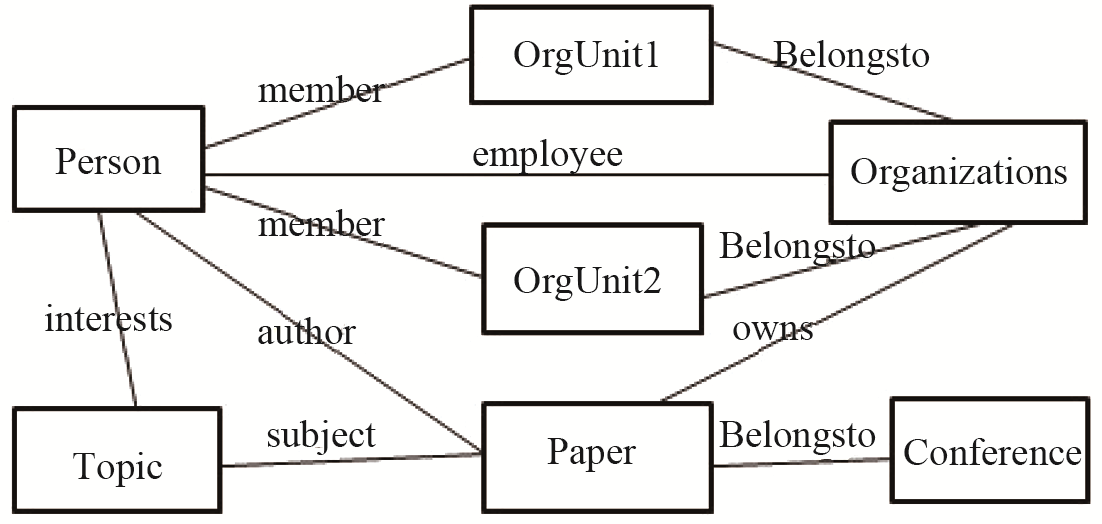 | 图1 CASIR中的实体类及关系 |
可为该实体类及关系添加如下隐性约束:
(1)对研究部门及其子部门的约束。一个研究部门可以包含1个或N个子部门。相反,这N个子部门从属于该研究部门。对于软件研究所来说,作为中国科学院的一个研究部门,它自身又包含计算机科学国家重点实验室、软件工程技术研究开发中心、并行计算实验室等多个子部门。
(2)对科研人员和研究部门的约束。一个研究部门可有N个科研人员。反之,这N个科研人员都是该研究部门的成员。
(3)对科研人员及其会议论文的约束。一位科研人员可能是多篇会议论文的作者。同时,一篇会议论文可以由多位科研人员合作完成。
(4)对会议论文及其所属学科主题的约束。一篇会议论文必然属于某一个学科主题或者相近的学科主题。同一个学科主题下必然会包含多篇相关会议论文。 (5)对科研人员及其学科主题的约束。一个科研人员肯定有自己的研究方向,该研究方向必然归属于某一个或多个学科主题。
(6)对会议论文和会议的约束。一篇会议论文必定对应一次会议。某一次会议下必然包含N篇会议论文。
基于MySQL的数据库编程,在设计底层数据模式时,可将该隐性约束转化为如下外键关联条件(部分):
#Foreign keys for table rel_paper_topic
ALTER TABLE ′rel_paper_topic′
ADD CONSTRAINT ′rel_paper_topic_ibfk_1′ FOREIGN KEY (′PaperID′) REFERENCES ′papers′ (′PaperID′),
ADD CONSTRAINT ′rel_paper_topic_ibfk_2′ FOREIGN KEY (′TopicID′) REFERENCES ′topics′ (′TopicID′);
#Foreign keys for table rel_person_organization
ALTER TABLE ′rel_person_organization′
ADD CONSTRAINT ′rel_person_organization_ibfk_1′ FOREIGN KEY (′PersonID′) REFERENCES ′persons′ (′PerID′),
ADD CONSTRAINT ′rel_person_organization_ibfk_2′ FOREIGN KEY (′OrganizationID′) REFERENCES ′organizations′ (′OrgID′);
#Foreign keys for table rel_person_paper
ALTER TABLE ′rel_person_paper′
ADD CONSTRAINT ′rel_person_paper_ibfk_1′ FOREIGN KEY (′PersonID′) REFERENCES ′persons′ (′PerID′),
ADD CONSTRAINT ′rel_person_paper_ibfk_2′ FOREIGN KEY (′PaperID′) REFERENCES ′papers′ (′PaperID′);
#Foreign keys for table rel_person_topic
ALTER TABLE ′rel_person_topic′
ADD CONSTRAINT ′rel_person_topic_ibfk_1′ FOREIGN KEY (′PersonID′) REFERENCES ′persons′ (′PerID′),
ADD CONSTRAINT ′rel_person_topic_ibfk_2′ FOREIGN KEY (′TopicID′) REFERENCES ′topics′ (′TopicID′);
3.2 利用RDF进行语义标注和关联
语义标注是使用计算机可理解的属性来描述资源的相关陈述[ 14]。这些属性可以用于本体中的任何资源或公理,包括本体本身。类、属性和实体标注都是通过创建一些陈述来实现的,而且标注属性在该陈述中充当谓语。在OWL标准本体语言中预定义的基本标注属性有很多种,本文是基于RDF+OWL语言进行知识呈现,主要用到以下几种,如表1所示。
| 表1 OWL中定义的基本标注属性 |
根据上文所抽取的实体关系,复用的关联词表主要有DC、DCTERMS、FOAF、SKOS、ISWC、VCARD,选择的关联数据源主要有DBpedia Ontology、DBLP Bibliography,并基于D2R[ 15]这一个将关系型数据库发布为关联数据格式的主流工具作为开发平台。D2R的映射语言D2RQ Mapping是基于RDFS和OWL进行描述的,自身生成的映射相当简单,无法覆盖到所关联的全部词表,而且部分约束关系也无法直接映射生成。因此必须通过人工干预,构建符合机构知识库语义扩展的映射模式,最终形成的词表映射和语义扩展方案,如表2所示:
| 表2 CASIR的语义扩展方案 |
基于表2的方案,在MyEclipse的Java开发环境中对D2RQ Mapping进行编程,主要示例如下:
(1)基于CASIR核心实体类的RDF语义标注,以会议论文实体(Paper)为例,选取部分代表性的代码如下:
#Table papers
map:papers a d2rq:ClassMap;
d2rq:dataStorage map:database;
d2rq:uriPattern "papers/@@papers.PaperID@@";
d2rq:class iswc:InProceedings;
d2rq:class foaf:Document;
map:papers_Title a d2rq:PropertyBridge;
d2rq:belongsToClassMap map:papers;
d2rq:property dc:title;
d2rq:property rdfs:label;
d2rq:column "papers.Title";
d2rq:lang "en";
map:papers_URI a d2rq:PropertyBridge;
d2rq:belongsToClassMap map:papers;
d2rq:property dc:identifier;
d2rq:uriColumn "papers.URI";
map:papers_Conference a d2rq:PropertyBridge;
d2rq:belongsToClassMap map:papers;
d2rq:property iswc:conference;
d2rq:refersToClassMap map:conferences;
d2rq:join "papers.Conference => conferences.ConfID";
(2)基于CASIR实体关系的RDF关联转换。主要是针对所述的几种实体关系进行编程转换,部分代码如下:
#n:m table rel_person_paper
map:rel_person_paper a d2rq:PropertyBridge;
d2rq:belongsToClassMap map:papers;
d2rq:property dc:creator;
d2rq:refersToClassMap map:persons;
d2rq:join "persons.PerID = rel_person_paper.PersonID";
d2rq:join "rel_person_paper.PaperID = papers.PaperID";
#n:m table rel_person_organization
map:rel_person_organization a d2rq:PropertyBridge;
d2rq:belongsToClassMap map:persons;
d2rq:property iswc:has_affiliation;
d2rq:refersToClassMap map:organizations;
d2rq:join "persons.PerID = rel_person_organization.PersonID";
d2rq:join "rel_person_organization.OrganizationID = organizations.OrgID";
(3)将CASIR实体元数据关联到外部数据源的RDF呈现,仍以Paper实体为例,选取部分代表性的代码如下:
#Table papers
map:papers_Seealso a d2rq:PropertyBridge;
d2rq:belongsToClassMap map:papers;
d2rq:property rdfs:seealso;
d2rq:uriColumn "papers.Seealso";
map:papers_Sameas a d2rq:PropertyBridge;
d2rq:belongsToClassMap map:papers;
d2rq:property owl:sameas;
d2rq:uriColumn "papers.Sameas";
CASIR中的会议论文元数据提供了对作者、论文名称、会议名称以及ISBN号的准确记录, ISBN作为会议论文的唯一标示符,为关联到外部数据源提供了方便。在实例化时,只需要判断两个资源的ISBN是否一致,即可获得该会议论文元数据在DBLP关联数据源中的描述URL,此外也可以根据作者以及对应的机构,获得作者的其他论文资源信息。
3.3 语义扩展模块测试和运行
在D2R的DOS路径下,以#d2r-server iswc.n3的命令行启动D2R Server,然后在浏览器中输入地址:http://210.77.64.53:2020/。可看到已将上述数据发布为含有语义的关联数据源。以CASIR中的一篇会议论文元数据为例,如图2所示。
 | 图2 CASIR中会议元数据描述示例 |
经过RDF语义标注和关联扩展的同一篇会议论文元数据如图3所示。
 | 图3 语义化的论文元数据 |
通过对比发现,语义扩展后的论文元数据中的属性和实体数据都是灵活的,可通过众多URI标示获得该论文元数据的合作者、会议、学科主题等具体信息。
(1)点击图3中< http://localhost:2020/page/conferences/2 >,可得到该论文所属的会议信息,如图4所示:
 | 图4 语义化的会议元数据 |
(2)点击图3中的< http://localhost:2020/persons/2 >,可得到该论文其中一个作者的详细信息,如图5所示:
 | 图5 语义化的作者元数据 |
(3)点击图5 < http://localhost:2020/page/organizations/10 >,可得到该作者所属的研究部门信息,如图6所示:
 | 图6 语义化的机构元数据 |
(4)本语义扩展模块还开放了基于SPARQL的语义查询服务端点http://210.77.64.53:2020/snorql/,能够进行基于类和属性的浏览,以及进行基于实体关系的检索和推理,如图7(部分)所示:
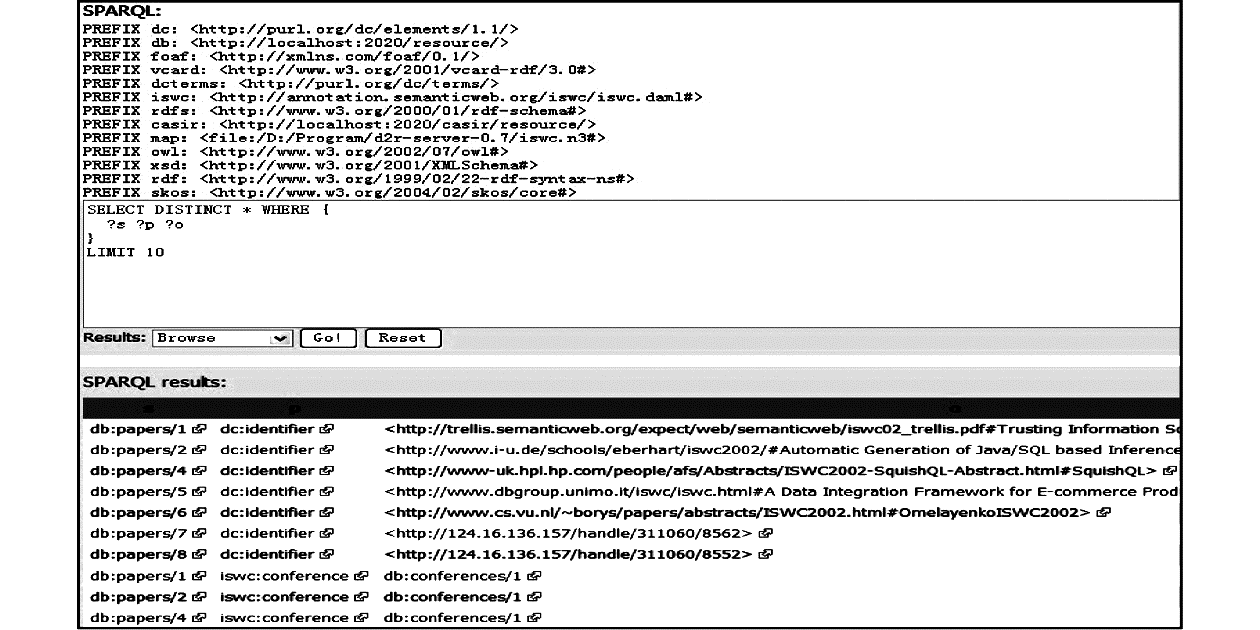 | 图7 SPARQL查询点 |
点击各个图中的相关链接都可以得到对应元数据的详细信息,这些信息,有的来自CASIR本身,有的来自外部数据源,但却相互关联在一起,构成了一个轻量级的关联数据网络。
4 结 语
当前,关联数据的急剧增长与越来越多成熟化关联数据转换工具的出现更进一步地加快了语义网普及的步伐。中国科学院机构知识库以发展机构知识能力和知识管理能力为目标,能够实现对机构知识资产的收集、长期保存、合理传播利用,这是它自身的优越性。但在越来越综合和复杂的信息环境中,仍迫切需要增强语义扩展,积极建设对知识内容进行捕获、转化、传播、利用和审计的能力。而机构知识库在建立最初,自身已经复用了DC的部分词表规范。此外,在CASIR中,当用户提交的条目成为CASIR的一部分时,系统会分配给它一个永久URL。与大多数的URL不同,当系统移到新的硬件设施上时,这一标识符将不必改变;或者当系统发生变化时, CASIR仍会维护该标识符的完整性。因此,在出版物或其他交流活动中引用该条目时,用户可以安全地利用此标识符找到该条目。CASIR的永久URL是通过句柄系统注册的。句柄系统[ 16]是一个分配、管理和解析互联网上数字对象及其他资源的永久标识符的包容性系统。基于以上这些优势,对机构知识库进行语义扩展变得切实可行,并能够在很大程度上保证关联数据源的稳定性和长久性服务。笔者的实验系统也表明,基于语义扩展的机构知识库与传统的知识库相比,在内容组织、资源组织方式上能够提供更为丰富的功能支持和语义发现服务,这无疑为加速CASIR从基础服务版到语义集成资源服务版的发展转变奠定了基础。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献