
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种提高过滤用户偏好精度的数据采集方法*
引用本文
赵妍, 苏玉召, 管涛. 一种提高过滤用户偏好精度的数据采集方法* . 现代图书情报技术, 2011, 27(11): 31-37
Zhao Yan, Su Yuzhao, Guan Tao. A Method of Data Collecting to Improve the Precision of Filtering User Preference. 现代图书情报技术, 2011, 27(11): 31-37
Permissions
Zhao Yan, Su Yuzhao, Guan Tao. A Method of Data Collecting to Improve the Precision of Filtering User Preference. 现代图书情报技术, 2011, 27(11): 31-37
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
一种提高过滤用户偏好精度的数据采集方法*
摘要
采用数据挖掘技术中的关联分析和聚类方法,重点研究Web日志兴趣发现的理论和方法,指出普通日志记录方法的局限性,提出过滤用户偏好的定制Web日志方法,实验结果验证通过该方法采集的数据,可以发现隐藏在日志数据中的关联规则,同时找到相似用户的兴趣和偏好,并且能够提高过滤用户兴趣偏好的精度。
关键词:
信息过滤; 用户偏好; 个性化推荐系统; 数据采集; 定制Web日志
中图分类号:G350 TP311
A Method of Data Collecting to Improve the Precision of Filtering User Preference
Abstract
Using the methods of association analysis and clustering in the field of data mining, the paper focuses on the theories and methods of discovering user interests and points out the limitations of standard Web log. So it proposes a method of customized Web log in order to enhance the precision of user interests and preferences. The outcome of experiment shows that,by the method,Web log data hidden in the association rules as well as interests and preferences of similar users can be found, the precision of filtering user interest can be improved at the same time.
Keyword:
Information filtering; User preferences; Personalization recommending system; Data collecting; Customized Web log
1 引 言
在知识发现(Knowledge Discovery)研究中,根据用户偏好需求,通过信息过滤能够实现用户感兴趣的知识获取。特别是网络普适计算的研究发展,无处不在的网络链接,极大地提高了用户获取信息的能力。但是,面对海量的信息,这种方法同时增加了用户找到特定需求知识的难度。因此,信息过滤技术的研究随着用户需求的变化而不断发展。ACM(Association for Computing Machinery)主席Peter J. Denning[ 1]认为信息过滤(Information Filtering)系统是信息源与用户之间的中介器(Mediator),信息过滤的功能是实现信息的定向传播与裁剪(Tailored)的服务。Web日志记录了用户的信息和访问内容的数据,可用于跟踪和分析用户的兴趣和偏好。有选择地记录用户信息和访问内容的信息过滤系统是网站和用户之间实现信息过滤功能的中介器。在信息过滤技术中,用户偏好(User Preferences)的定义非常重要,从信息定向传播角度看,如果信息源不具备用户偏好的知识,它将会失去传播的目标;从信息裁剪角度看,信息过滤根据用户偏好选择用户需要的特定信息,并以用户感兴趣的方式呈现出来。
许多学者认为,Etzioni[ 2]是第一个提出Web挖掘技术的人,他在1996年的描述中认为,Web挖掘是应用数据挖掘技术,从Web文档和服务内容里自动发现并抽取有用信息。一般情况下,Web挖掘技术可以分为三种类型:Web内容挖掘、Web结构挖掘和Web用法挖掘。Web挖掘技术是在现有的和新的数据挖掘算法基础上,应用Web数据技术,通过Web日志挖掘的方法可以发现用户兴趣偏好。近年来,关于Web挖掘的研究活动大部分集中在Web用法挖掘方面。Web使用挖掘技术广泛地应用于从Web服务器日志文件中发现用户兴趣使用模式。土耳其埃拉泽的弗拉特大学信息系及电子和计算机科学系的一个关于Web日志分析研究项目[ 3],通过对用户访问该网站路径进行分析的方法,旨在帮助网站设计者和管理者改进网站服务、提高其网站的吸引力。
Web日志数据的内容是做好个性化推荐的事实基础,好的数据质量才可能会有好的推荐结果。在Web服务器上可以由系统自动捕获用户访问行为并保存在日志文件中[ 4, 5],也可以通过在应用程序中嵌入捕获信息的代码的方式记录用户操作行为。目前常见的Web日志格式主要有两类:Apache的NCSA日志格式[ 6]和IIS的W3C日志格式[ 7]。比较Apache和IIS的日志格式发现,使用这些标准的日志格式具有以下优点:通用性;简便性;可分析性。但是,这些日志格式也有其缺点:针对性差;数据杂乱;缺失关键性数据。
对于进行日志挖掘的个性化推荐系统来说,使用何种日志数据进行用户建模直接影响到推荐的精度,进而会影响到用户对个性化推荐的满意度。基于以上问题分析,本文认为定制Web日志收集的数据能够更好地实现用户兴趣发现,进而提出采集定制Web日志数据原型系统,并通过数据挖掘分析其性能。
2 系统原型
2.1 问题描述
从不同的视角看, 数据采集技术主要有几种分类方法[ 8]:根据发现知识的种类分类、根据采集的数据库的种类分类和根据采用的技术分类。
(1)根据发现知识的种类进行分类有:总结(Summarization)规则、特征(Characterization) 规则、关联(Association)规则、分类(Classification)规则、聚类(Clustering)规则、趋势(Trend)分析、偏差(Deviation)分析、模式分析(Pattern Analysis)等。
(2)根据挖掘的数据库进行分类有:关系型(Relational)、事务型(Transactional)、面向对象型(Objected-Oriented)、主动型(Active)、空间型(Spatial)、时间型(Temporal)、文本型(Textual)、多媒体(Multi-Media)、异构(Heterogeneous) 数据库等。
(3)根据采用的技术进行分类有[ 9]:
①人工神经网络,是一种通过训练来学习的非线性预测模型,从结构上模仿生物神经网络,可以完成分类、聚类、特征采集等多种数据采集任务[ 10];
②决策树,用树形结构来表示决策集合,这些决策集合通过对数据集的分类产生规则,典型的决策树方法有分类回归树(CART );
③遗传算法,是一种基于生物进化的概念,设计了一系列的过程来达到优化的目的;
④最近邻技术,这种技术通过K个最与之相近的历史记录的组合来辨别新的记录,有时也称为K-最近邻算法,这种技术可以用作聚类[ 11 ]、偏差分析[ 12]等采集任务;
⑤规则归纳,通过统计方法归纳、提取有价值的If-Then 规则,规则归纳的技术在数据挖掘中被广泛使用, 例如关联规则的挖掘;
⑥可视化,采用直观的图形方式将信息模式、数据的关联或趋势呈现给决策者, 决策者可以通过可视化技术交互式地分析数据关系。
个性化推荐系统是采用机器学习、知识发现、Web挖掘和人工智能等领域的技术,满足用户偏好,并为用户推荐可能感兴趣的内容。因此,个性化推荐服务的关键是找到用户的兴趣。一般情况下,Web用户兴趣的发现有两种方式:分析用户定制内容和挖掘用户访问日志。
个性化的目的是重点为特定、具体的用户提供满足其个人兴趣偏好的内容。就一些公共和商业性的网站来说,对注册用户进行关联分析、分类和聚类挖掘,根据历史数据找到其访问该网站的内在关联、关注的焦点。而对于一些非注册用户,由于没有一种唯一的标识号表示用户的唯一身份,无法发现该用户的历史数据,这将无法准确定位其兴趣偏好。因此,通过分析注册用户的历史数据和相关用户的数据,能够准确发现该用户的兴趣偏好,并推荐相似用户及其感兴趣的内容。
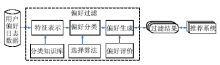
根据系统预设的一些功能,用户自己设定偏好,例如:用户收藏、加入购物车和定制更新等。挖掘日志是通过分析用户历史记录的方法,发现用户的兴趣。Mostafa等[ 13]根据用户兴趣的变化和文档内容的更新对信息过滤模型、系统和评价的方法进行研究。本文在其研究的基础上提出一种用户偏好信息过滤模型,如图1所示:
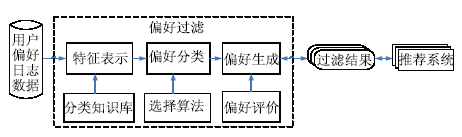 | 图1 用户偏好信息过滤模型 |
本文以中国国家科技图书文献中心(National Science and Technology Library,NSTL)嵌入式系统为研究对象[ 14],针对满足用户偏好需要的个性化服务定制用户访问日志格式。为了更好地捕获实现个性化服务需要的日志数据,需要针对特定的系统和用户需求,定制Web日志数据格式。本文提出一种数字图书馆个性化服务需要的定制Web日志格式原型,目的是通过数据挖掘技术,利用机器学习发现用户兴趣和偏好,并希望进一步改进定制Web日志数据格式。考虑到该系统属于提供检索和下载服务的应用,记录的日志数据能够满足以下功能的需求:
(1)记录用户检索记录、点击率、浏览历史;
(2)帮助NSTL嵌入式系统实现针对Web用户浏览行为和习惯用法的分析,挖掘用户感兴趣内容,并为用户提供个性化推荐内容;
(3)生成日志报表;
(4)帮助NSTL嵌入式系统管理Web网站内容,提高服务质量和水平,增强用户吸引力。
NSTL既可以为非注册用户提供文献检索和下载的普通任务,也可以为注册用户提供文献传递、馆际互借和咨询图书馆员的服务,系统会将图书馆员的处理和问答结果发送到注册用户的邮箱。同时,对于一些收费文献下载和传递等事务,可以通过注册用户的账号进行管理,提高了用户需要的及时反馈和服务获得。
2.2 定制日志
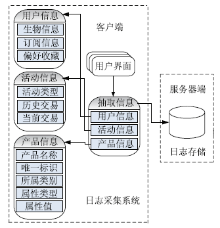
根据以上需求分析,NSTL嵌入式系统平台定制Web日志的数据采集系统如图2所示:
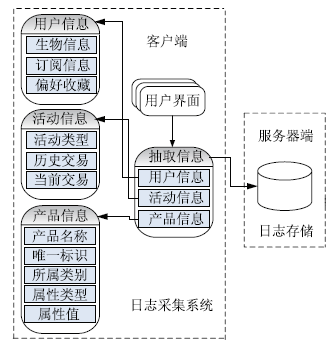 | 图2 NSTL定制日志采集系统 |
用户日志数据采集系统包括三个部分:用户信息、操作活动和操作对象等信息的收集。其中,用户信息包括用户个人的姓名、性别、职业、职称和联系方式等生物信息,兴趣和偏好设置,收藏内容,历史交易和时间;操作活动指的是用户访问类型,例如浏览、下载和订购等;操作对象的信息包括属性、属性值和所属类别等。日志记录系统采集的是每一个用户单独活动的数据,每个用户都具有相同的日志格式,区别只是内容的不同。通过收集这些信息,有助于建立用户模型,弄清楚用户是谁、做了什么,并推测其可能感兴趣的内容,由智能推荐系统实现推荐内容的发送和呈现。其特点是:在客户端捕获用户当前访问行为,发现用户兴趣内容,能够保证日志数据的准确性、不影响服务器性能;以日志记录的方式写入日志表的尾部,不会影响数据库性能,有助于快速获取用户最新偏好信息。
该日志采集系统的特点是:
(1)采集的日志主要是结构化数据,在数据库表中能够找到记录对象的所有属性,记录的数据精确,能够准确定位用户操作的对象;
(2)简练记录了对象名称或者每次用户交易成功后系统生成的交易号,存储空间小,便于计算,能够节省时间和空间,提高系统效率;
(3)及时性和准确性强,当时记录的数据最能反映出该用户关注的焦点;
(4)记录过滤掉了影响分析用户偏好的信息,采集到的数据与用户偏好有较强的关联性。
2.3 日志数据
实验采用的数据挖掘工具是开源软件怀卡托智能分析环境,简称Weka。Web日志数据来自NSTL嵌入式资源服务实验平台,系统在本地服务器模拟真实环境,采集了两周内中国科学院国家科学图书馆研究生用户访问日志数据,日志记录总数2 351条,有21个有效注册用户,经过清洗后有效记录数目1 575条,有效用户15个,采集的日志数据主要是学术研究相关文献的检索、浏览、下载和文献传递等操作记录,其格式及定义如表1所示:
| 表1 Web日志格式定义及属性说明 |
本文以数字图书馆领域的读者访问行为为研究对象,捕获的日志数据主要包含以下几种类型:用户生物信息、操作方法和数据对象。其中,用户生物信息包括用户姓名、性别、职业、职称和研究方向;操作方法主要包括简单搜索、高级搜索、关键词搜索、下载、浏览和订购等操作行为,这些信息体现了用户访问方式的习惯和偏好;数据对象包括用户访问文献的类型(例如期刊、会议、专著、专利或者是报告),文献的物理属性(例如标题、作者、所属学科领域、关键词、出版日期和价格等信息),这些数据可以用于发现用户对访问文献的兴趣和研究内容的偏好。
3 实验结果及分析
Web使用挖掘是应用数据挖掘技术,发现Web数据的使用模式,从而更好地理解和满足用户服务的需要[ 15]。利用Web日志数据关联分析的挖掘技术,发现用户兴趣偏好关联规则,聚类的目的是找到相似用户的兴趣偏好。本文实验目的是发现用户的访问行为和兴趣偏好,通过采集用户偏好,分析定制日志的方法对提高发现用户偏好精度的影响和作用。
3.1 关联规则分析
关联规则分析的目的是找出数据中存在的关系,便于识别出用户的习惯和偏好。关联分析实验内容主要分析用户操作和操作、项目和项目、操作和访问项目之间的关系。实验采用PredictiveApriori算法[ 16],该算法是在Apriori算法基础上的改进,其特点是:在正确置信度范围内,随着设置阈值的增长找出n条最好的规则。因此,根据这些规则,最好的n条规则预测精度相对要高。Scheffer等[ 17]进一步研究了在知识发现领域的应用,提出一种通过使用序列样本算法,发现最感兴趣的模式。García等[ 18]应用关联规则挖掘技术建立了学习管理系统的指导模型,用于提高Web网站的用户满意度。近年来,也有一些综合了聚类和关联技术的研究,建立关联规则模型,随着数据集记录的增加,这种方法能够快速实现建模,精度也会提高。
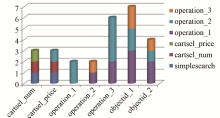
实验进行了日志数据预处理,涉及的操作属性及意义说明如表2所示。实验结果如图3所示。
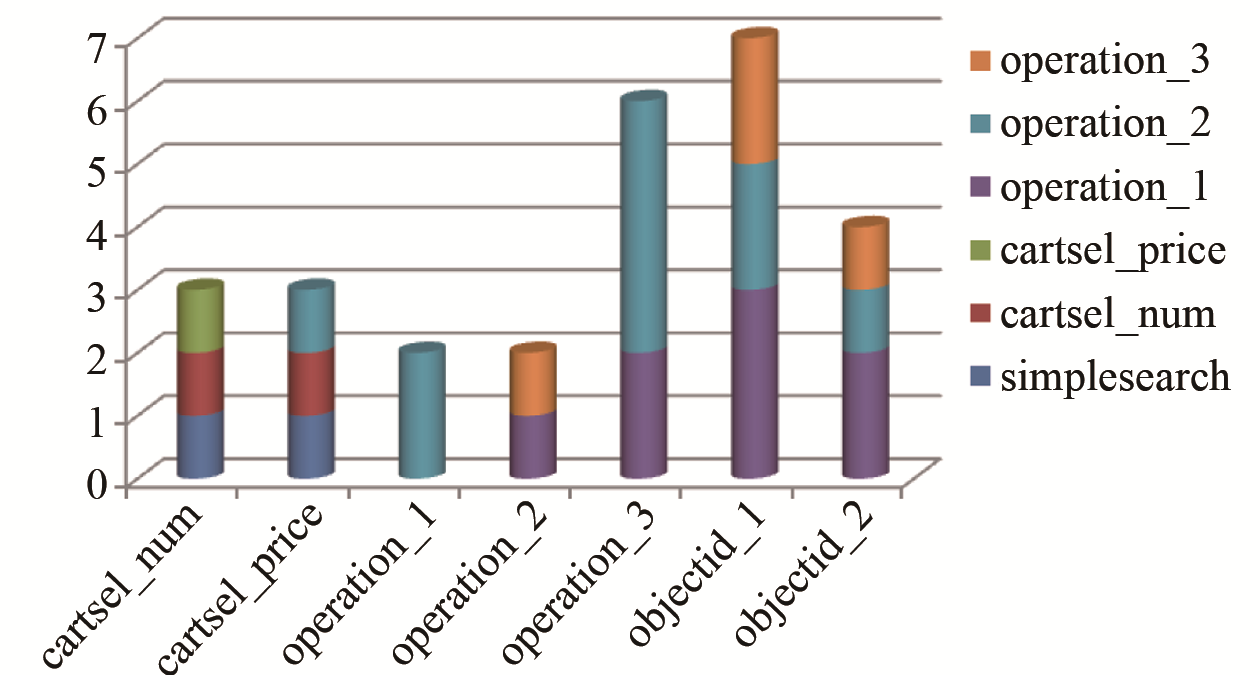 | 图 3 PredictiveApriori找到的前10条关联规则 |
可以看出,用户购买的文献数目、价格和操作类型有着密切的关系,与用户购买的实际情况相符,用户越是使用高级搜索就越能证明其研究的内容深入和对文献需要的期望值越高,也说明用户对这些文献越有兴趣。用户对文献类型、数目和操作类型关系密切,这样能够证明用户对搜索文献类型相关的文献数目有着明显的兴趣偏好。用户更多情况下喜欢使用简单搜索操作查找期刊类型的文献,并且偏向于喜欢期刊类型的文献。
| 表2 操作属性及访问对象标识意义说明 |
3.2 聚类分析
通过聚类分析可以找到用户相似的兴趣和偏好,发现具有相似访问习惯、操作方式和检索内容的用户。许多商务网站通过其他用户交易记录,进行相似用户聚类分析,将用户可能感兴趣的内容以用户偏好的方式推荐展现出来,从而实现增值服务,达到获取收益的目的。实验采用CLOPE算法[ 19],提供一种适用于交易型数据进行快速聚类的方法。本文研究中,定制的Web日志数据是一种交易型数据,采用CLOPE算法的目的是发现用户兴趣和偏好,提供数字图书馆领域满足用户特定需求的个性化服务。实验对用户操作类型和对象聚类的结果如图4所示,横向坐标表示用户标识,纵向坐标表示日志数据实例。
 | 图 4 用户访问行为聚类结果 |
在图4中,横坐标表示聚类类别,纵坐标表示日志数据记录数目,在同一个层次的水平方向表示用户具有相似的访问行为。从1 575条日志记录中,用户聚类大致可以将用户划分为5个类型,能够较为准确地将相似用户分类,体现他们相似的偏好和兴趣,有助于个性化相似内容的推荐。
3.3 性能评价
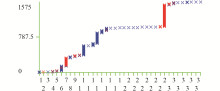
实验过程中,分别选取了几个操作类型进行记录日志前后计算时间的对比,结果如图5所示:
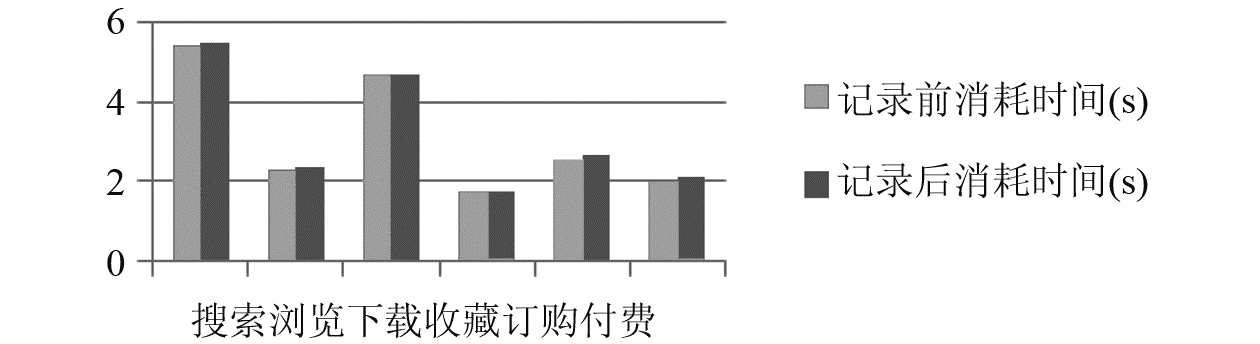 | 图5 记录日志前后时间对比 |
可以看出,记录日志前后消耗的时间差别不明显。实际上,由于记录是在用户客户端收集信息,不消耗服务器的资源。同时,在日志采集系统的抽取信息模块,将采集到的信息通过后台日志记录的方式写回到服务器端日志存储系统的数据库表中,执行的是在表尾部的插入操作,不需要执行查找的操作。因此,记录日志的代价很小。
为了更具体地分析本文提出方法的有效性,通过访问的方式人工采集了用户访问NSTL嵌入式系统实验平台网站的用户信息,包括用户的研究方向或者关注的主要内容,如表3所示,以便于将采集到的日志数据和用户的实际需求进行对比,来分析本文采集日志的方法是否能够满足用户需求。
| 表3 用户研究方向/关注内容 |
分析原始日志内容,发现记录的信息与表3中的内容很相近,可以得出以下结论:
(1)日志采集系统准确地记录了用户访问内容;
(2)记录的日志信息符合用户关注/需要的内容。
通过定制Web日志的方式采集数据,进行关联分析和用户聚类的数据挖掘技术,目的是能够在数据质量方面提高用户偏好过滤的精度。根据实验结果和分析,这种定制Web日志采集数据的方式,能够满足过滤用户偏好的需求,并且准确性高,能够提高发现用户偏好的精度。
因此,这种定制的日志格式具有以下优点:
(1)日志格式设计原则实现冗余最小化,在保证推荐系统呈现的内容能够满足用户偏好需求的情况下,使得生成的Web日志内容最少,从而降低服务器性能损耗和提高Web数据挖掘效率。原型系统定制的Web日志主要针对数字图书馆领域个性化用户的特定需求,捕获能够体现用户偏好的用户个人、操作活动和操作对象的信息。
(2)在构建Web日志格式的时候,应当充分考虑记录到Web日志文件中信息的必要性。考虑构建类似于NSTL的Web日志格式,关注的重点是用户对哪些文章和主题感兴趣,通过对其购买、收藏和定制喜爱的文章分析该用户最近从事哪方面的研究,预测其可能还会感兴趣的文章和主题。把关键的信息记录到Web日志文件,删除其他非关键信息,进行有针对性的数据挖掘计算。这样,推荐系统呈现给用户的内容能够获得较高的用户满意度。
(3)在捕获日志数据的时候,系统先对数据进行格式化处理,这样有助于减少日志数据预处理阶段的复杂性和降低时间消耗。
4 结 语
本文通过采用定制日志的原型系统研究,提高用户偏好信息的数据采集方法和技术,其贡献有三点:
(1)通过用户标识号就可以获取数据库表中准确的用户信息,不必在日志数据中重复记录,简化了日志内容,减轻了系统负载;
(2)记录的对象是结构化或者半结构化的数据,提高了记录信息的准确性,这些数据可以在数据库表中比较精确地找到,同时,可以采用标签的方式表示数据对象,在数据挖掘阶段节省了计算机内存空间,提高了计算速度;
(3)利用记录对象的属性在数据库中找到对象的所有属性,根据用户兴趣和偏好,准确地进行内容推荐。
研究过程中采用数据挖掘技术,分别使用了关联规则算法和聚类算法对Web日志数据进行分析。实验结果验证了通过定制Web日志采集数据的方法,能够发现隐藏在日志数据中的关联规则,找到相似用户的兴趣和偏好,采集日志数据的方法能够提高过滤用户兴趣偏好的精度。但是,通过实验结果分析发现,采集的日志数据还存在诸多问题,例如,非结构化数据问题、操作类型和对象属性还没有标准化、结构化等问题。还需要更深入地研究日志数据建模理论,实现捕获完整性、一致性和唯一性强的日志数据。同时,用户最常使用的操作方式是简单搜索,推测其原因可能有两个:用户对本系统提供的高级检索功能不熟悉,或者是用户对研究的内容还不深入;系统没有提供更好的个性化服务,无法准确识别出用户的真正需求。因此,系统需要进一步增强服务功能,提供个性化服务。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|