
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于协同过滤算法的高校图书馆图书推荐系统研究*
引用本文
董坤. 基于协同过滤算法的高校图书馆图书推荐系统研究* . 现代图书情报技术, 2011, 27(11): 44-47
Dong Kun. Research of Personalized Book Recommender System of University Library Based on Collaborative Filter. 现代图书情报技术, 2011, 27(11): 44-47
Permissions
Dong Kun. Research of Personalized Book Recommender System of University Library Based on Collaborative Filter. 现代图书情报技术, 2011, 27(11): 44-47
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于协同过滤算法的高校图书馆图书推荐系统研究*
摘要
针对当前高校图书馆主动式图书推荐服务存在的对服务对象信息需求挖掘、分析不足的问题,提出构建基于协同过滤算法的个性化图书推荐系统。通过引入读者专业、角色、学历、借阅记录等影响和反映读者信息需求的因素构建读者特征模型,基于该模型采用优化的协同过滤算法挖掘读者信息需求并产生个性化图书推荐信息,并通过实验证明该方法的有效性和实用性。
关键词:
协同过滤; 信息服务; 数据挖掘; 数据仓储
中图分类号:G205.7
Research of Personalized Book Recommender System of University Library Based on Collaborative Filter
Abstract
Aiming at the disadvantages of insufficient mining and analysis of readers’ information needs existing in the active book recommendation service of university library, the paper brings forward a construction of personalized book recommender system based on collaborative filter. The system imports the factors of faculty, role, education and the readers’ records of visiting the reading rooms to construct the reader’s characteristic model. By mining and analyzing the characteristic model which uses optimized collaboration filter algorithm, the system can produce the personalized book recommendation to reader.And the experiment proves that the system is efficient and practical.
Keyword:
Collaborative filter; Information service; Data mining; Data warehouse
1 引 言
如何利用现代信息技术更好地满足师生在教学、科研、学习过程中所产生的多样化的信息需求是当前高校图书馆面临的一个亟待解决的问题。随着OPAC等信息资源管理系统在高校图书馆的普及,对OPAC中的海量信息进行数据挖掘并基于挖掘出的知识来开展个性化主动式的信息服务已经成为当前高校图书馆转变服务方式,提高服务质量的有效手段之一[ 1, 2]。
协同过滤算法[ 3]无需对信息资源知识内涵进行分析,仅对读者阅读行为及特征进行挖掘,即可得到包含读者潜在兴趣在内的个性化信息需求,因其较低的计算复杂度和较高的挖掘质量在高校图书馆个性化服务领域具有广泛的应用前景。本文提出一种图书推荐系统,引入读者专业、学历、角色、借阅记录等因素,基于改进的协同过滤算法实现以读者信息需求为中心的个性化图书推荐服务。
2 高校图书馆图书推荐服务现状分析
根据产生推荐信息实现技术的不同,当前高校图书馆主流的非结构化文本数据推荐服务可分为基于内容的推荐、基于关联规则[ 4]的推荐和基于协同过滤的推荐等三类。各类推荐算法的性能比较如表1所示:
| 表1 高校图书馆主流推荐技术性能比较 |
在高校特定信息环境中,馆藏资源数量庞大、类型各异且学科覆盖广泛,大量跨学科、跨专业乃至新兴学科、边缘学科图书的存在造成基于内容的图书推荐系统所构建的模型很难全面准确地表征图书资源内容,因此推荐质量较低,难以满足高校师生对推荐资源的准确性、实时性需求。高校图书馆读者较高的借阅频次、相似的知识结构以及共同的知识学习引动力使得高校图书馆存在大量相似度较高的借阅记录,基于规则的推荐难以产生真正有价值的且具备一定新意的关联性规则,难以进而提供面向高校读者的有价值的个性化信息服务。
通过分析发现,相同的年龄层、相似的知识结构、角色的一致性使得高校读者的信息获取行为有明显的类聚特性,同一专业、同一角色的读者其阅读行为较为相似,且在很大程度上受其学科专业背景和所承担角色的影响。因此笔者引入对高校读者阅读行为产生较大影响的专业、学历、角色等因素建立读者特征模型,并基于该模型采用改良的协同过滤算法开展个性化的图书推荐工作,以较低的计算复杂度挖掘出包含读者潜在兴趣在内的个性化信息需求,实现针对高校读者的高质量个性化图书推荐服务。
3 基于协同过滤的图书推荐系统
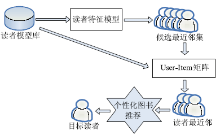
传统的基于项目评分的协同过滤算法仅依据用户的信息获取行为及评分情况进行预测,缺乏对触发用户信息需求动因的深层次分析,因此无法从本质上保证预测结果的准确性且易造成数据稀疏。本文提出一种改进的基于协同过滤的图书推荐算法,通过引入读者专业学科信息、学历信息、角色信息等对高校读者信息需求起本质引动作用的影响因子来构建读者特征模型,并通过改进最近邻产生流程在提高系统性能的同时降低系统计算复杂度。基于协同过滤的个性化图书推荐算法如图1所示:
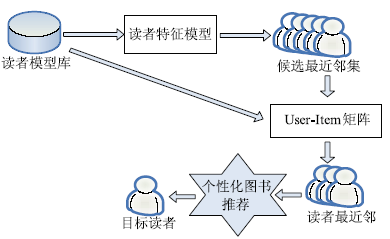 | 图1 基于协同过滤的图书推荐流程 |
从OPAC库中提取读者借阅事务信息、学科专业信息、学历信息、角色信息并在其基础上建立读者特征模型,根据读者特征模型计算产生目标读者的候选最近邻集[ 5]。基于目标读者候选最近邻集构建User-Item矩阵,并产生目标读者最近邻。根据目标读者最近邻的阅读行为挖掘分析出与读者信息需求相适应的推荐图书,实现对目标读者的个性化推荐。
3.1 读者特征模型构建及候选最近邻生成
中南民族大学图书馆设有法律、通信、文学等23个专业学科阅览室,各学科阅览室库藏内容明确,学科界限清晰。全部阅览室平均每天接待读者量达到2 000人次以上,借阅事务发生频繁。通过分析读者阅读行为特征,笔者认为:
(1)在以知识学习作为信息需求主要引动力的客观条件下,高校图书馆读者信息需求在很大程度上受其专业知识背景和所担任角色的影响;
(2)读者对学科阅览室的访问情况能够反映出读者信息需求的大致方向,可通过读者阅览室访问记录对读者最近邻进行初次过滤以降低计算复杂度。
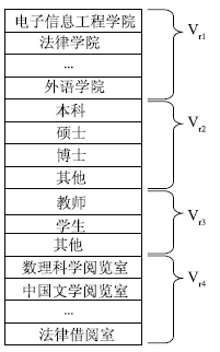
基于以上认识创建了一个取值为0、1的多维读者特征模型 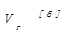
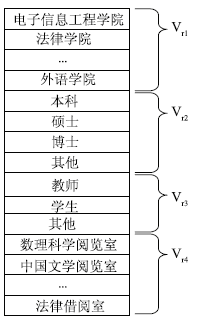 | 图2 读者特征模型结构图 |
每个院系、学历、角色都用向量的一个维度表示,读者与之相符则取值为1,否则取值为0。按学校实际情况,学历向量Vr2分为本科、硕士、博士与其他4类,角色向量Vr3分为教师、学生、其他三类。学科阅览室访问向量每个维度对应一个学科阅览室,在一定时间范围内有目标读者访问记录则取值为1,否则取值为0。
数据源来自本馆OPAC系统。该系统包括馆藏书目信息表(书名、作者、版本、出版社、标准书号、索取号、分类号、馆藏地、书目记录号)、读者信息表(读者证号、姓名、工作单位、学历、流通类型、启用日、停用日)以及借阅信息表(借阅时间、馆藏地点、读者证号、书目记录号)。在其基础上做如下处理:
(1)对原表中无效数据、冗余数据进行删除操作。
(2)对原表中一些取值混乱的字段做规范性操作,使其定义域统一规范,便于后续挖掘。统一读者信息表中各工作单位名称,将流通类型列重命名为角色列并将其取值统一规范为学生、教师或其他,学历列取值统一为博士、硕士、本科或其他。
(3)数据添加。读者信息表添加Reading room1, Reading room2,…,Reading room23等列用来记录读者对本校图书馆23个学科阅览室的访问情况,若读者在统计时间段内对该阅览室有访问记录则对应阅览室列赋值1,否则为0。
(4)字段删除。删除各表中对数据挖掘以及信息服务无用的字段信息。
基于读者特征模型,根据余弦相似性公式计算读者之间的相似性,并选出一定数量的相似读者作为目标读者的候选最近邻MC。
3.2 读者最近邻生成
对于每个读者ui∈Mc,从OPAC数据库中得到其和目标读者在一定期限内借阅图书的并集,用Un表示。基于Mc和Un建立User-Item矩阵A(m, n),它包含m个候选最近邻和目标读者的集合U=(u1, u2,…,um)和n个图书资源的集合I=(i1, i2,…,in)。
矩阵元素Rui表示读者u对于图书i的评分。当读者u在统计时间段内对i无借阅记录,则Rui=0。由于借阅时间能反映出读者信息需求的紧迫程度,因此统计时间段内若有借阅事务发生, Rui分值的计算方法如下:
设读者u在指定时间段内借阅图书序列为(item1,item2,…,itemi,…,itemn),其对应的借阅时间序列为(t1,t2,…,ti,…,tn),设Tmin为统计时间段开始时间, Tmax为截止时间,则读者u对图书资源itemi的评分值计算公式如下:
Rui=
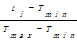 | (1) |
在产生的User-Item矩阵基础上利用修正的余弦相似性公式计算与读者最为相似的Top-N个读者作为目标读者的最近邻[ 7]。公式如下:
sim(u1,u2) =
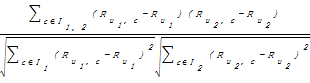 | (2) |
其中,sim(u1, u2)表示读者u1和u2的相似度, I1,2表示读者u1、u2共同产生评分的图书, Ru1,c表示读者u1对图书c的评分, 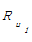
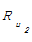
3.3 产生推荐书目
根据基于项目均值的加权平均值公式在最近邻范围内对图书进行预测评分。设目标读者最近邻居集用U表示,则目标读者u对图书i的评分Pu,i可通过最近邻居集对i的评分得到。公式如下:
Pu,i= Ru+
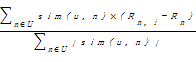 | (3) |
根据最近邻居集对图书的评分数据预测目标读者对图书的兴趣度Pu,i,通过设置兴趣度阈值或设置信息资源数量产生目标读者推荐资源。
4 实验及分析
为验证图书推荐系统性能,构建了一个具备个性化图书推荐功能的学科信息服务平台,读者通过登录该平台查看推荐图书信息并对推送的每本图书给予接受或不接受的信息反馈,根据读者反馈来评估系统性能。图书推荐系统如图3所示:
 | 图3 图书推荐系统页面 |
从本校电信学院、计算机学院、文学院、法学院各抽取本科生200人、研究生50人、教师30人,共计1 120人,将其2010-2011年间发生的38 078条借阅记录导入系统中,其中候选最近邻个数设置为40,最近邻个数设置为20,推荐资源数量设置为10。
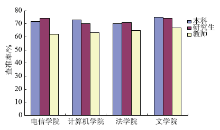
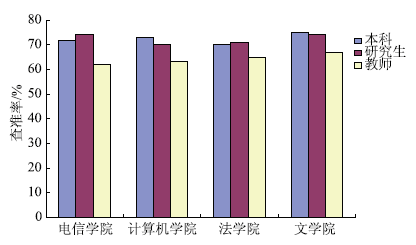
根据读者对推送信息的反馈,计算推送资源的“查准率”[ 8]来评估系统服务质量,实验结果如图4所示:
 | 图4 “查准率”统计图 |
实验结果表明,面向本科生、研究生、教师的推荐图书平均查准率分别达到73%、72%和64%,具有较好的推送质量。差异原因在于本科生、研究生所属群体借阅频次较高且同一群体成员之间在知识结构、信息需求上较为相似,而教师群体因知识结构复杂、认知水平高的特点使得其信息需求的广度和深度都要高于本科生和研究生,造成其查准率低于二者。 对受调查师生的借阅情况进一步分析,根据借阅次数对其进行聚类,分别统计系统对不同类别读者群的信息推送质量,实验结果如表2所示:
| 表2 读者查准率聚类统计表 |
可以看出,系统推荐效果随着读者借阅次数的增加而逐步提高,即使在用户借阅数据较为稀疏的情况下,系统也具有较好的推荐质量。
5 结 语
本文构建了一个基于协同过滤算法的高校图书推荐系统。通过建立包含触发及影响读者信息需求的一系列因素在内的读者特征模型,深层次、多角度对读者信息需求进行挖掘,有效地改善了信息服务质量,实现了高校图书推荐的个性化与准确性的统一。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|