
{kind=link}
{kind=link}
基于主题句相似度的标题党新闻鉴别技术研究
引用本文
王志超, 翁楠, 王宇. 基于主题句相似度的标题党新闻鉴别技术研究. 现代图书情报技术, 2011, 27(11): 48-53
Wang Zhichao, Weng Nan, Wang Yu. Research of Title Party News Identification Technology Based on Topic Sentence Similarity. 现代图书情报技术, 2011, 27(11): 48-53
Permissions
Wang Zhichao, Weng Nan, Wang Yu. Research of Title Party News Identification Technology Based on Topic Sentence Similarity. 现代图书情报技术, 2011, 27(11): 48-53
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于主题句相似度的标题党新闻鉴别技术研究
摘要
针对目前网络上的标题党新闻,提出一种标题党新闻自动识别的算法。通过分析新闻网页构成的特点,抽取出新闻标题和新闻正文;以句子关系矩阵为基础,提出一种以语句为单位的主题句抽取算法;根据句子相似度计算结果来进行判断。实验表明,本方法的识别精度可达到80%,是一种有效的方法。
关键词:
标题党新闻; 新闻标题抽取; 新闻正文信息抽取; 句子相似度计算; 主题句抽取
中图分类号:TP391
Research of Title Party News Identification Technology Based on Topic Sentence Similarity
Abstract
Concerning the issues of the more and more title party news in the Web,this paper presents a new algorithm of title party news identification. Firstly, it analyzes the composition of the news page, then puts forward an approach of news title extraction and information extraction based on the features of news page. Secondly, considering the problem of extracting coherent topic sentences from news pages, starting with the relationship matrix of sentences, it puts forward an algorithm of topic sentence extraction. Then, according to the extracted news title and the candidate set of topic sentences, it can compute the similarity value, which is the main basis for judging the title party. Finally, the experiment results show that this method is effective and feasible.
Keyword:
Title party news; News title extraction; News information extraction; Sentence similarity computing; Topic sentence extraction
1 引 言
随着信息科技的进步和互联网技术的日益普及, Web新闻已经成为人们获取信息的主要途径之一。但是,目前网络上出现了很多标题党新闻,即是无法直接从新闻标题正确地了解文章内容的新闻网页。
近期,标题党新闻越来越盛行,已引起社会各界的强烈不满。但是由于网络上的新闻数量十分庞大,不可能对每篇网络新闻人工地去判断是否符合要求,这就需要一种能够自动识别标题党新闻的方法,即标题党新闻鉴别技术。
由于中文与英文在词语组成与句子结构上存在一定的差别,所以本文提出的算法只适用于中文新闻网页。目前,对于标题党新闻的自动识别国内外学者还没有提出一个有效的方法,但在该领域中常用的处理技术,例如网页信息抽取、相似度计算、文本主题句抽取等,国内外学者已经做了很多基础而重要的研究工作,也取得了一定的成果。
在网页信息抽取方面,蒲宇达等[ 1]将数据挖掘技术应用到网页文本处理中,提出了一种基于数据挖掘思想的网页正文抽取方法;Moorn[ 2]在信息抽取方法中引入了隐马尔科夫模型,提出了一种基于隐马尔科夫模型的信息抽取技术;Marlin[ 3]提出了基于模式匹配的信息抽取技术,通过大量实例学习归纳出待抽取的语法结构模式,并根据这些模式匹配出网页中待抽取的信息。
在句子相似度计算方面,李彬等[ 4] 把语义与依存文法分析结合起来,提出了一种基于语义依存的汉语句子相似度计算方法;车万翔等[ 5]根据中文句子相似度计算的特殊要求,提出了一种基于改进编辑距离的中文相似句子检索方法,在使用信息检索技术提高检索效率的同时,以普通编辑距离算法为基础,加入了词汇的语义信息;杨思春等[ 6]将模式应用于汉语句子相似度计算,提出了一种基于模式的汉语句子相似度计算方法。
在主题句抽取方面,李芳等[ 7]从语义相关性的角度分析,提出了一种基于切平面的主题抽取算法;石晶等[ 8]利用小世界模型对文本进行分割,进而提出了基于小世界模型的中文文本主题分析方法;李楠[ 9]将遗传算法应用到文本主题提取上,提出了一种基于遗传算法的汉语文本主题词提取方法。
在此基础上,针对中文标题党新闻网页的构成特点,本文提出了一种基于主题句相似度的标题党新闻鉴别算法。该方法抽取出新闻网页的标题和正文信息,然后利用主题句抽取算法对正文信息的主题句进行抽取,将得到的主题句与新闻标题进行句子相似度计算,根据相似度计算结果进而判断一篇新闻是否为标题党新闻。
2 新闻网页预处理
由于新闻网页中包含大量的广告、相关链接等无用信息,这些无用信息充斥在整个网页中,影响了对新闻网页主题句抽取的精度。为了能够取得理想的实验效果,达到一定的精度要求,本文先对新闻网页进行预处理,主要目的是提取新闻标题和新闻正文部分,有利于提高标题党新闻识别的准确性。
通过观察可以发现,互联网上每个新闻网页基本由以下几类内容构成:新闻导航栏、新闻标题、新闻正文、广告信息、相关链接等,如图1所示:
 | 图1 新闻页面构成示意图 |
本文只关注新闻标题和正文内容,因此只对这两方面进行抽取。新闻标题的抽取方法利用罗永莲等[ 10]提出的基于新闻标题结构的抽取方法,对新闻标题的HTML标记和出现的位置进行分析,从而通过计分的方法抽取出新闻标题。该方法对新闻标题的抽取具有一定的有效性。新闻正文内容的抽取方法利用孙承杰等[ 11]提出的一种基于统计的网页正文抽取方法,该方法根据网页的HTML标记将网页表示成一棵树,然后对每个节点进行遍历并根据每个节点包含的中文字符数选出正文节点。该方法克服了传统方法需要针对不同的数据源构造不同的包装器的缺点,具有一定的普遍性。
3 标题党新闻识别算法
新闻网页的主题句是对新闻主题思想的简短性总结,它在一定程度上反映了新闻所要讲述的内容。所以在新闻正文较长,不便于直接参与句子相似度计算的情况下,可以利用主题句抽取算法提取出新闻主题,然后再与新闻标题进行相似度计算,根据计算结果来判断一篇新闻是否为标题党新闻。
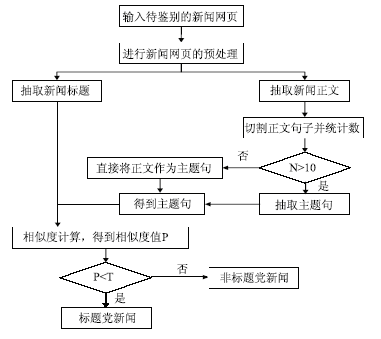
标题党新闻识别算法的主要步骤如下:
(1)对新闻网页进行预处理,主要目的是提取新闻标题和新闻正文。
(2)对经过预处理之后得到的新闻正文进行句子分割,并统计正文句子数。
(3)如果正文句子数大于10,则按本文中提出的方法进行主题句抽取,得到新闻主题句集合TS。否则直接将正文内容作为TS,并转到步骤(4)。
(4)对经过以上步骤处理之后得到的新闻标题与新闻正文主题句集合TS进行句子相似度计算,得到相似度值P。
(5)将得到的P值与T值比较,即可判断一篇新闻是否为标题党新闻。
算法流程如图2所示:
 | 图2 算法流程图 |
3.1 句子相似度的计算方法
句子相似度是两个句子在语义上的匹配程度,取值为[0,1]之间的实数,数值越大,表明两个句子在语义层面上越相似。本文采用的句子相似度计算方法是一种基于语义的计算方法。王森等[ 12]根据中文语句的特点,提出句子相似度由主题相似度和词形相似度决定,主题相似度由名词的语义相似度定义,词形相似度由除名词外的词的词形相似度定义,从而给出了一种基于句子语义的相似度计算方法,公式如下[ 12]:
SentenceSim(A,B)=θ1WordSim(A,B)+θ2SenmanticSim(A,B)(1)
其中,θ1、θ2∈[0,1]且θ1+θ2=1。SentenceSim(A,B)表示句子A和B的相似度, WordSim(A,B)表示句子A和B的词形相似度,SenmanticSim(A,B)表示句子A和B的主题相似度。
3.2 主题句抽取算法
主题句不仅应该是被作者重复描述最多的句子,同时也应该能够尽可能广泛地分布在新闻的各个段落中。为了提高主题句抽取的准确性,将所有与主题相关的句子作为候选主题句,通过计算比较各个候选句子的重要程度,最终建立一个尽可能广泛包含主题意义的主题句集合。
首先定义两个语句参数评估概念,然后根据两个评估参数的结果,综合计算句子的重要程度,并最终确定出文本主题句集合。
定义1:正文句子S或S的相关同义句在正文文本中出现的次数定义为句子S的重复频率,用符号FS表示。经分析发现,一个句子重要与否,很大程度上取决于该句子在文中出现的次数。因为如果一个句子被重复的次数越多,也就表明该句包含作者反复强调的对象,因而很可能与正文的主题相关,作为主题句的概率也就越大。
定义2:正文句子S或S的相关同义句在正文文本段落中分布的稀疏程度定义为句子S的分布广度,用符号DS表示。一个句子在正文中跨越的段落数越多、分布越广,说明该句子的贯穿性越强,越有可能与主题相关,作为主题句的概率越大。
明确了以上定义后,给出主题句权值计算公式:
TopicSentenc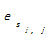 =α× =α× 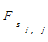 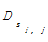 | (2) |
其中,α+β=1, s(i,j)表示新闻正文中第i段,第j个句子。TopicSentenc 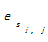

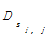
α和β的取值范围易知,0≤α、β≤1且α+β=1,其大小分别表示句子重复频度 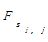

网页新闻正文主题句抽取算法如下:
(1)将提取出来的新闻正文以段落为单位进行划分,设共可分成m段。
(2)以段落为单位将正文按{“,”,“。”,“?”,“!”}等句子结束符切分成N个句子。例如:设一篇文章共分成m个段落,每个段落包含n1、n2…nm个句子,则第i段第j句可表示为si,j,其中i, j均为整数,且0
(3)假设正文共可分为{s1,1,…, 

(4)确定一个阈值Q1,以相似度矩阵SN*N为初始矩阵进行变换,将相似度矩阵SN*N按照规则变换成矩阵Sk*k,令k=N,变换规则如下:
Si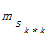 (si,j,sp,q)= (si,j,sp,q)= 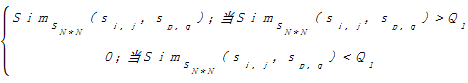 | (3) |
在这里,显然Q1∈ [0,1]。Q1所表征的是两个句子可以认为相关或相似程度的大小。Q1的取值越大,要求两个句子越相似,提取出的候选句子会越少,同时会降低主题句集合对文本主题的覆盖广度;Q1的取值越小,要求句子间相关度低,则提取出的主题句不能很好地反映主题内容。所以为了尽可能让候选句子覆盖主题内容,同时又保证一定的实验精度,根据实验结果令Q1=0.3。
(5)这时经式(3)变换得到矩阵Sk*k的每一行向量中不为0的元素的个数即可代表该句子的重复频度,即行向量si,j中不为0的元素个数就代表第i段第j个句子在全部文本中出现的重复频度 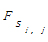
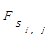
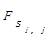 = =  | (4) |
其中, SimilarCountsi,j为矩阵Sm*m中行向量si,j中元素不为0的个数, N为正文中包含总句子数。
(6)记录下行向量si,j中每个不全为0的元素所对应的列向量,统计出该列向量所在的段落位置,最后算出列向量所在不同段落位置的总数,记为DifferentParagraphCountsi,j,该参数在一定程度上反映了句子si,j在文中的分布情况,根据其可以得到句子si,j的分布广度 
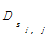 = = 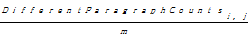 | (5) |
其中, m为正文总段落数。
(7)根据以上步骤计算出的句子重复频度 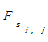
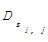
(8)根据主题句计算公式,在矩阵Sk*k筛选出元素不全为0的行向量,分别计算每个句子的主题句权值,然后根据主题句权值大小将句子从大到小进行排列,最后抽取出前R个不同的句子构成主题句集合。其中, R=[0.1×N](中括号表示取整),即抽取正文全部句子数的10%作为候选主题句,这样保证了抽取的主题句能够尽可能广泛地反映正文主题内容。
关于主题句抽取算法的几点说明:
在本算法的步骤(2)中,需要对分句得到的N个句子进行短句过滤处理,目的是过滤掉一些经常出现在新闻中但却与新闻主题无关的短语或句子,例如:“目前”、“近日”、“有报道称”等。短句过滤处理规则本文用下面的文本作为示例:
“目前,大楼内大火已被扑灭,现场救助、案件调查及追捕犯罪嫌疑人等项工作正在紧张有序进行中。”
这段文本在语法上是一个句子,但利用步骤(2)中的句子分割方法将本句进行拆分,可以得到三个句子。“目前”,“大楼内大火已被扑灭”,“现场救助、案件调查及追捕犯罪嫌疑人等项工作正在紧张有序进行中”。
在本文中,把短句定义为句子中汉语字符数少于5的句子。因此,在上面的例句中,第一个句子“目前”(汉语字符数为2,小于5)将会被过滤掉,而第二和第三个句子汉语字符数均大于5,予以保留。
此外,如果最后得到的正文总句子数小于10,由于正文的句子数较少,不适合利用本方法进行主题句抽取,则可以直接将正文内容进行分句处理,然后再与新闻标题进行相似度计算,从而判断新闻是否为标题党新闻。
在得到每个句子的主题句权值后,可以继续对主题句进行抽取。由于抽取的主题句不能重复,所以每抽取一个句子都需要与已抽取的主题句进行相似度计算,如果结果大于0.6,则认为两个句子表达基本相同的含义,不予以重复抽取。
3.3 主题句相似度计算
本文对一篇网页新闻是否为标题党新闻判别的主要指标是主题句相似度计算所得到的结果。在本算法中,相似度值P的计算方法分为两种,主要以新闻正文句子数为依据。当正文句子数大于10时,首先对正文进行主题句抽取,得到候选主题句集合。在该主题句集合中,主题句按照权值大小依次排列。在得到新闻标题与主题句之后,相似度值P计算方法如下:
P=Max{SentenceSim(TopicSentencei,j,title)}(6)
其中, TopicSentencei,j为候选主题句集合中第i个段第j个句子, title表示新闻标题内容, SentenceSim(TopicSentencei,j,title)为主题句TopicSentencei,j与新闻标题title的语义相似度。
当正文句子数小于10时,无需再进行主题句抽取,而是直接将正文句子作为主题句。此时,相似度值P计算方法如下:
P=Max{SentenceSim(NewsSentencei,title)}(7)
其中, NewsSentencei代表新闻正文中第i个句子,在这里,相似度值P取新闻正文句子与新闻标题相似度的最大值。
3.4 标题党新闻的判断标准
在得到主题句相似度值P之后,可以进一步进行标题党新闻的判定。设定参数T为判别一篇网页新闻是否为标题党新闻的阈值。在本算法中,很容易得到T的取值范围应该在[0,1]之间。当T的取值较小时,表明标题党新闻的判别标准比较宽泛,只要新闻主题与新闻标题有一定的联系即可,同时会增大算法将标题党新闻误判为正常新闻的概率。当T的取值较大时,则表示要求新闻主题能够较为具体准确地解释新闻标题内容,此时也会增大算法将正常新闻误判为标题党新闻的概率。为了达到理想的实验效果,同时又兼顾两方面的影响因素,令T=0.2。此时,当一篇新闻的相似度值P大于0.2时,认为此新闻为非标题党新闻;反之,则为标题党新闻。
4 实验与分析
为了验证本文提出的基于主题句相似度的标题党新闻鉴别技术的有效性,选取国内主要新闻网站100篇新闻作为实验数据,其中非标题党类新闻75篇,标题党新闻25篇。然后,请相关领域的研究人员对100篇网页新闻是否为标题党新闻进行判断,再用本文提出的方法对这些新闻网页进行鉴别。最后,将两种方法结果进行比较得到实验结果,如表1所示:
| 表1 标题党新闻鉴别实验结果 |
可以看出,本文提出的标题党新闻鉴别算法的综合平均准确率可以达到80%。其中,对非标题党新闻网页的判断准确率为82.7%,对标题党新闻网页的判别准确率为72%。
进一步分析发现,本算法的误差主要来源于以下几个方面:
(1)网页新闻正文抽取的误差。
(2)网页新闻正文主题句抽取算法存在一定的误差。
(3)由于句子相似度计算中所使用的《同义词词林扩展版》收录的词是有限的,存在一些专有名词没有收录或者专有名词的同义词无法正确识别的现象,如果这样的专有名词出现在标题和主题句中会造成较大的误差。比如:标题中出现“刘德华”,而主题句中出现“华仔”,本来是同一个人,但在实际计算中两个词却被认为是不相关的,导致句子相似度计算结果不理想。
5 结 语
本文针对新闻网页结构的特点,研究并实现了一种基于主题句相似度的标题党新闻鉴别方法。该方法以网页信息抽取、句子相似度计算和主题句抽取为基础,通过计算新闻标题与新闻主题内容的相似度来判断一篇新闻网页是否为标题党,能够较为准确地对标题党新闻进行识别,实验结果验证了该方法的有效性。
本研究工作接下来将完善句子相似度计算与主题句抽取算法,提高识别效果;融入对图片信息的识别,实现对包含图片信息的标题党新闻的识别。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|