

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
中文叙词表本体概念定义注释的自动构建研究*
引用本文
田金凤, 曾新红, 黄华军, 林伟明. 中文叙词表本体概念定义注释的自动构建研究* . 现代图书情报技术, 2011, 27(11): 9-16
Tian Jinfeng, Zeng Xinhong, Huang Huajun, Lin Weiming. Research on Automatic Construction of Definition Notes for Concepts in OntoThesaurus. 现代图书情报技术, 2011, 27(11): 9-16
Permissions
Tian Jinfeng, Zeng Xinhong, Huang Huajun, Lin Weiming. Research on Automatic Construction of Definition Notes for Concepts in OntoThesaurus. 现代图书情报技术, 2011, 27(11): 9-16
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
中文叙词表本体概念定义注释的自动构建研究*
摘要
设计面向综合性中文叙词表本体的叙词概念定义抽取方法,获得良好的实验效果并已投入实际应用。其中,基于“高频词与句子向量”和“TF*IDF向量”两种定义抽取算法提出的二维相对量的融合算法,能够更有效地抽取出前两种方法的良好结果,有效信息提高比一般可达到60%。
关键词:
中文叙词表本体; OTCSS; 定义抽取; 向量空间模型; 高频词与句子向量; TF*IDF向量; 二维相对量
中图分类号:TP18 TP301.6
Research on Automatic Construction of Definition Notes for Concepts in OntoThesaurus
Abstract
The paper proposes some methods of definition extraction for concepts in the comprehensive OntoThesaurus. They achieve good experiment effects and are applied to the actual OTCSS. Among them, an integrated algorithm named “two-dimensional relative quantity” based on “high-frequency words vector”and “TF*IDF vector”is presented. This algorithm can much effectively extract good results from that of the first two methods, and the effective information improving ratio can reach 60% generally.
Keyword:
OntoThesaurus; OTCSS; Definition extraction; VSM High-frequency words vector; TF*IDF vector; Two-dimensional relative quantity
1 引 言
概念的定义是人们理解该概念最直接、最清晰的信息。W3C的推荐标准SKOS(简单知识组织系统)为概念的定义专门设置了一个注释属性skos:definition进行描述,以提供一个概念的本意的完整解释[ 1]。
中文叙词表本体(OntoThesaurus)融合了叙词表与本体[ 2],是一种同时具备二者特征的知识组织系统[ 3]。综合性中文叙词表本体包含了各个领域的词汇,其中不乏一些专业术语,一般用户在使用和参与其建设时可能会遇到障碍。如果单纯依靠修订专家手工添加叙词的定义注释将是一项非常耗时耗力的任务。因此,自动构建叙词概念的定义注释成为中文叙词表本体共建共享系统(OntoThesaurus Co-construction and Sharing System, OTCSS)[ 4, 5]需要具备的功能。这一功能的实现可以极大地减轻修订专家的负担,也可以进一步给广大的网络用户带来方便。
针对上述问题,本文力求找到一种解决OTCSS中叙词定义注释自动构建的方法。以《中国分类主题词表》为例,设计了面向综合性中文叙词表本体中叙词概念的定义注释语句抽取方法,获得了良好的实验效果,且已应用于实际的OTCSS系统。
2 研究背景及本文的主要工作
2.1 定义抽取研究现状
定义抽取是一个较新的研究课题,是信息抽取[ 6]的一个新的分支,其目的是使人们在网络搜索时能迅速定位到词语的定义信息,提高信息抽取的有效性和实用性。国内外在这方面的研究起步都较晚,但是也取得了一定的研究成果[ 7, 8, 9, 10, 11, 12, 13, 14],主要集中于自然科学领域,对于人文领域的术语定义抽取还鲜有涉及。主要研究成果包括:
(1)定义规则匹配模式
贾爱平[ 7]提出了关于术语定义的识别研究课题,通过对大量科技文献真实语料的阅读,总结出了8种定义语言模式和5种定义排除语言模式,并提出了定义抽取的评价方法。这些定义规则的总结为后来的定义自动抽取奠定了形式化的基础。很多人利用这些规则对定义进行自动化抽取,并得到了不错的结果。
(2)智能匹配
张榕等[ 8]提出了结合句子术语定义隶属度和高频词与句子向量的智能匹配算法。该算法首先通过计算词语的术语定义隶属度来计算句子的术语定义隶属度,根据所得的结果对句子降序排列,取前5个;在所有候选定义语句中选取出现频率最高的15个词作为一个向量,即高频词向量。然后将候选定义语句作为另一个向量,计算两个向量之间的余弦相似度。同样根据计算结果对句子降序排列,取前5个;最后将这两者计算结果结合起来,取综合值最高的一个句子。这种方法适合领域性强的术语,但对于综合性的词表作用有限。
(3)SP
其核心算法是质心算法[ 9]。主要思想是通过计算术语在句子中的位置得到统一的模式,模式中包含有槽,为每一种位置的槽中可能出现的词语加权。利用训练集得到模式和权值,再将训练得到的模式和权值应用到网络中去。这种方法是建立在英文语法的基础上,中文定义语句中术语出现位置灵活,且已有贾爱平[ 7]总结了符合中文语法习惯的定义规则模式,所以该算法对本文帮助有限。
(4)最大熵分类器
将目标术语(Target Term)提交给搜索引擎;返回以目标术语为中心的250字长度的片段,称作窗口(Window);将窗口分类成可接受的语句和不可接受的语句两种类型;系统返回定义语句[ 10]。同SP方法一样,都是建立在英文语法的基础上。
(5)SVM分类器
该算法需要两类特征量:术语特征量,指术语词频、术语长度、术语内部连接度及术语邻接上下文的信息熵等;术语定义中的词汇特征,它是利用句子的术语定义隶属度来描述的[ 11]。这种词汇特征与张榕等[ 8]提出的方法类似。SVM分类器根据这两个特征量进行计算,筛选得到最终结果。这种方法的主要目的是利用已有的定义模式发现伴随着定义语句出现的新术语,与本文出发点不同。
2.2 主要工作
本文以网络为语料来源,利用搜索引擎从网络中获取所需的定义注释信息,寻找合适的定义匹配模式;根据中文叙词表本体的相关理论,设计了面向以中国分类主题词表为代表的综合性叙词表中的叙词抽取定义注释语句的方法。
主要创新点在于:
(1)在借鉴前人研究成果的基础之上,做了以下改进:在抽取实际语料的过程中,针对历史叙词和地理叙词,分别提出了一种新的抽取模式:String+[“,”]+“[“]史称”+theme+[”]和theme+[“,”]+[“是|就”]+(“位于”|“坐落”)+String;在前人基础上扩展了高频词向量的计算范围,使其计算可以灵活使用。
(2)将文本检索领域的TF*IDF算法引入定义抽取领域,以弥补仅使用高频词造成的抽取结果具有片面性。
(3)提出了基于高频词与句子向量和TF*IDF向量两种定义抽取算法的二维相对量的融合算法,更有效地抽取良好的定义语句。
3 面向综合性中文叙词表本体的叙词概念定义抽取方法
3.1 叙词定义规则匹配
通过对网络数据和规则模板的研究与分析,构建了符合本系统要求的定义模板,即定义句子匹配规则。两个句子的结束符,包括句号、问号和感叹号之间的字符串,如果能有一个字符串同以下某一个模板匹配,则这个字符串就是要抽取的候选定义句子。
定义注释规则的匹配模式用类似正则表达式的方式来表达。将句子分为几个可选的匹配项,每一项之间用加号(+)连接,其中方括号表示里面的内容可以出现也可以不出现,圆括号表示里面的内容必须出现一项,圆括号中用竖线分开的内容表示可选项,即只出现其中一项即可。String表示出现在句子中的词语串,不限定其内容。双引号(“”)表示里面的内容必须与原文中的内容一致。theme表示需要抽取其定义注释信息的叙词。
本文所使用的定义注释抽取规则如表1所示[ 7](其中加下划线的为叙词):
| 表1 本文所用的定义规则匹配模式及例句 |
其中,模式8和模式9是在实际语料的抽取过程中总结得出的,而模式1至模式7均改编于贾爱平[ 7]总结的定义规则模式。
除了使用定义注释抽取规则以外,还使用了以下定义注释排除规则:
(1)String(?|!)
以问号结尾的句子和以感叹号结尾的句子往往都不能清晰地解释一个词语。
(2)|String|<15 或 >500
这个规则对句子的长度做了一个限制。
(3)|letter|>100
如果一句话中的英文字母连续超过100个,说明这句话的杂乱信息较多。
3.2 向量空间模型
(1)理论基础
向量空间模型[ 15, 16, 17](Vector-Space Model, VSM)因为将文档的内容形式化为多维向量空间中的一个点,将文档以向量的形式定义到实数域中,使模式识别中的各种成熟算法得以采用,提高了自然语言文档的可计算性与可操作性,所以成为最常用的文本表示模型。
①文档:通常指文章中一定长度的片断,如句子、段落或整篇文章。本文将句子看作文档,因此在下文中句子和文档不加区分。
②特征项:通常使用VSM中语言单元,如字、词、词组等,则文档就被看作是由其包含的特征项所组成的集合。本文将词看作文档的特征项。
③权重:特征项的权值。本文为此设计了两种表征权重的方法。
④相似度:有任意两个文档D1(w11,w12,…w1k…,w1n)和D2(w21,w22,…w2k…,w2n),它们的相似度记作Sim(D1,D2)。向量空间模型的相似度也有多种计算方法,如内积、余弦值等[ 15, 16]。最常用的是余弦系数,这也是本文采用的方法,公式如下[ 15]:
Sim(D1,D2)=cosθ=
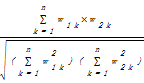 | (1) |
(2)高频词与句子向量
记作hifre*sent权值法,利用高频词向量与句子向量的余弦值来衡量定义语句。其主要思想是以一句话为单位,把每一句话看作一个文档D,对其进行分词、停用词过滤等处理,将文档D中的每一个词作为一个特征项tk,统计所有经过处理后的文档中的词语出现的次数Ntk,即把所有词语都记录在一个Hifre_word数组中,然后统计它们在文档集C中出现的频率ftk,用词频ftk作为特征项的权值,并按照降序排列,即高频词向量hifre(ftk1,ftk2,…ftki…,ftkn)。进而统计所有词语在每一个文档中的出现次数N′tk,将词语出现在单个文档中的频率f′tk作为特征项的权值,计算出每个文档的权值,作为句子向量sent(f′tk1,f′tk2,…f′i…,f′tkn),其中1≤i≤n。最后计算出高频词向量与句子向量之间的相似度,并按照降序排列。两者相似性越大,权值越高,公式如下[ 8]:
Sim(hifre,sent)=cosθ=
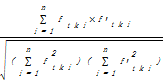 | (2) |
本文中并没有限制高频词的个数,根据句子的实际情况灵活调整向量,不拘泥于一个限定值,计算更方便、灵活,同时得出的结果也更具有参考价值。
(3) TF*IDF向量
记作TF*IDF权值法,利用特征词的频率及逆文档频率来衡量定义语句。
①TF(Term Frequency)[ 15]:词频,表示特征词tk在某文档D中的出现频率,表征一个词语与某个文档的相关性。一个特征词的TF向量记作tf(ftk1,ftk2,…ftki…,ftkn)。
②IDF(Inverse Document Frequency)[ 15]:逆向文档频率,表示特征词tk在整个文档集C中的出现频率,表征了一个词语普遍重要性的度量。IDF值越大,说明特征词tk对文档D的代表性越强,反之,则越弱。一个特征词的IDF向量记作idf(dt1,dt2,…dti…,dtn)。
③计算出TF向量与IDF向量之间的相似度,并按照降序排列。两者相似性越大,权值越高,公式如下:
Sim(tf,idf)=
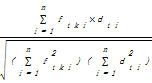 | (3) |
3.3 二维相对量融合算法
hirfre*sent量算法和TF*IDF算法从两种不同角度计算得到良好的定义语句,并且每一个候选定义语句权值的取值范围也有所区别。笔者提出了二维相对量的融合算法,从这两种算法的计算结果中得到更好的定义语句。
二维相对量采用了数学中向量基的概念,把hifre*sent看作一个平面的向量hs,将权值最小的向量值作为该平面的基e1,则句子i在此方向上的坐标值为该句子向量的权值与基e1的差值hi,这样利用hifre*sent向量的权值与基e1的差值组成了新的向量hs(h1,h2,…hi…,hn);同样地,把TF*IDF看作是另一个平面的向量,将权值最小的向量权值作为该平面的基e2,则句子i在此方向上的坐标值为该句子向量的权值与基e2的差值di,这样利用TF*IDF向量的权值与基e2的差值又组成一个新的向量td(d1,d2,…d3…,dn)。由于在平面中向量的平移不影响向量的值,可以将这两个平面的基平移到一起,利用它们组成一个坐标系。由于是利用向量值最小的句子作为基,从理论上来讲,在这个坐标系里,距离原点最远的点就是此叙词最好的定义语句。根据平面上的点的距离公式 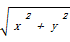
two_d=
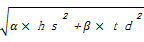 | (4) |
其中,α和β是调整系数。通过式(4)可以抽取两种算法中较好的定义注释语句。根据实验分析, hifre*sent向量值的取值范围在0.8到0之间,而TF*IDF向量值的取值范围在0.5到0之间,α和β取值范围为(0.3,0.7)得到的效果最好。
4 中文叙词表本体概念定义注释的自动构建方案及系统实现
4.1 自动构建方案
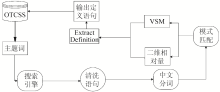
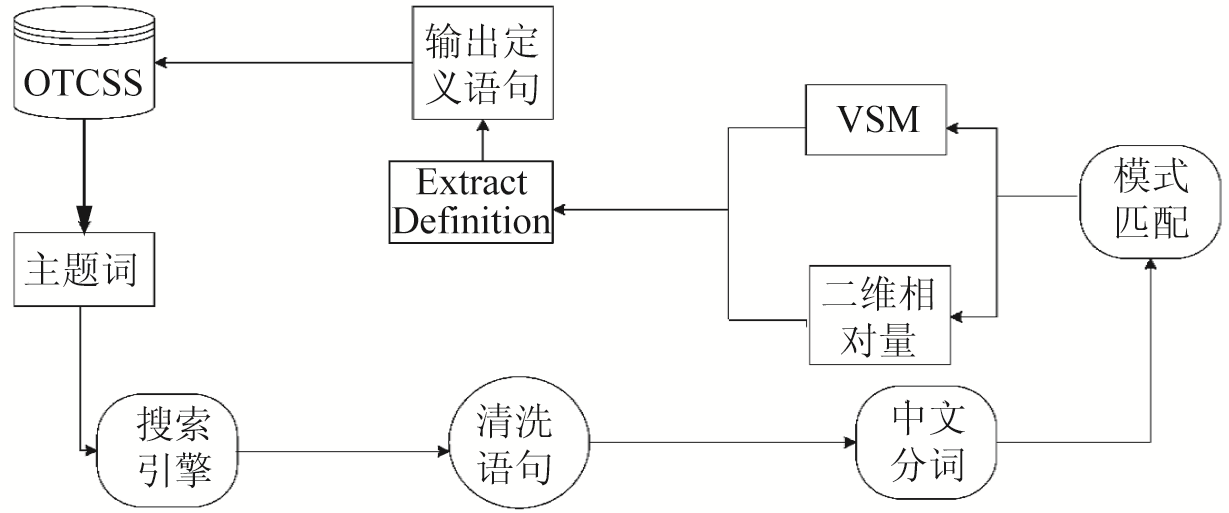
根据 OTCSS[ 4]的特点,提出了符合OTCSS需要的定义注释信息自动构建方案,如图1所示:
 | 图1 中文叙词表本体概念定义注释自动构建方案 |
该方案主要分为两个部分:
(1)数据准备与清理:从OTCSS中接收叙词,将接收到的叙词交给成熟的商业搜索引擎去搜索并下载与此叙词有关的语句,剥离下载的语句信息中的网页标记等。
(2)数据筛选与抽取:将上一步骤得到的数据进行分词等处理,利用合适的规则对语句进行筛选,并利用向量空间模型算法和二维相对量融合算法抽取良好的定义语句。
4.2 系统实现
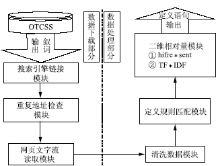
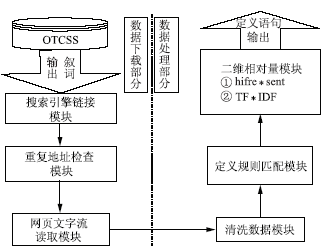
本系统有两大功能模块:数据下载部分主要实现叙词的抽取,通过商用搜索引擎来搜索与叙词有关的定义信息;数据处理部分主要实现通过算法来筛选在网络上搜索到的定义语句。系统流程如图2所示:
 | 图2 系统流程图 |
5 实验结果及分析
本研究从“中国分类主题词表本体共建共享系统”(CCT1_OTCSS[ 5])提供的OWL文件中共选取了650个叙词作为实验词汇。该语料中的叙词涉及领域宽广,重点选取了法学、地理、宗教三个人文社科领域的叙词和计算机、工业技术、手工业三个自然科学领域的叙词。其中地理领域120个,法学领域100个,宗教领域100个,计算机领域110个,工业技术领域110个,手工业领域110个。
由于是借助商业搜索引擎返回相关网页,所以查全率不是笔者关心的问题,此处只评价查准率。本系统是为完善OTCSS的功能而实现,需要给修订专家推荐抽取出的叙词的前三个(或更多)定义注释语句,因此对查准率做了细微的区分:
(1)精确查准率(Accurate Precision Rate,APR):对所有叙词而言,定义注释语句排在第一位所占的比率。
(2)粗略查准率(Rough Precision Rate,RPR):对所有叙词而言,定义注释语句排在前三位所占的比率。两种评价方法的计算公式规定如下:
APR= 
RPR= 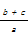
其中,a表示实验语料中所有叙词的数目;b表示实验结果中,叙词的定义注释语句排在其所有抽出语句第一位的数目;c表示实验结果中,叙词的定义注释语句排在其所有抽出语句第二位或第三位的数目。
为了考察使用二维相对量融合算法对提高查准率有多少帮助,还引入了一个指标——有效信息提高比(Effective Information Improving Rate,EIR),公式如下:
EIR= 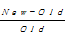
其中,New表示新算法得出的实验结果数目, Old表示原算法得出的实验结果数目。有效信息提高比考察新算法相对于原算法的有效程度,其比值越大,表明新算法的有效性越高,反之,则表示新算法的有效性越低。
本文中原算法有两种:hifre*sent向量与TF*IDF向量,新算法为二维相对量融合算法。需要分别计算新算法相对于两种原算法的有效信息提高比。二维相对量融合算法相对于hifre*sent算法有效信息提高比,记作H_EIR;二维相对量融合算法相对于TF*IDF算法有效信息提高比,记作T_EIR。公式如下:
H_EIR= 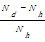
T_EIR= 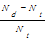
其中,Nd表示二维相对量融合算法得到的实验结果中,定义注释语句排第一位的数目;Nh表示hifre*sent算法得到的实验结果中,定义注释语句排第一位的数目;Nt表示TF*IDF算法得到的实验结果中,定义注释语句排第一位的数目。
需要强调的是,这里只针对定义语句排名第一的情况计算有效信息提高比,其原因有两点:在统计定义语句排名时比较容易,且最能体现算法的有效性;三种排名顺序全部考虑进去,分析时比较复杂,无法一概而论。
二维相对量融合算法的实验结果,包括定义注释语句的数目分布,以及每个领域的精确查准率与粗略查准率,如表2所示:
| 表2 叙词的定义注释语句分布及查准率 |
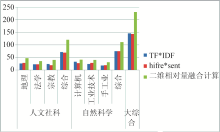
为计算有效信息提高比,分别统计得到hifre*sent向量、TF*IDF向量以及二维相对量三种算法所得到的排名第一的定义注释语句的数目。为对比起见,还统计了三种算法得到的排名第一的定义注释语句中,其重合的语句数目及分布情况,并计算出每一种算法在各个领域的有效信息提高比,如图5和表3所示。部分实验结果如表4所示。
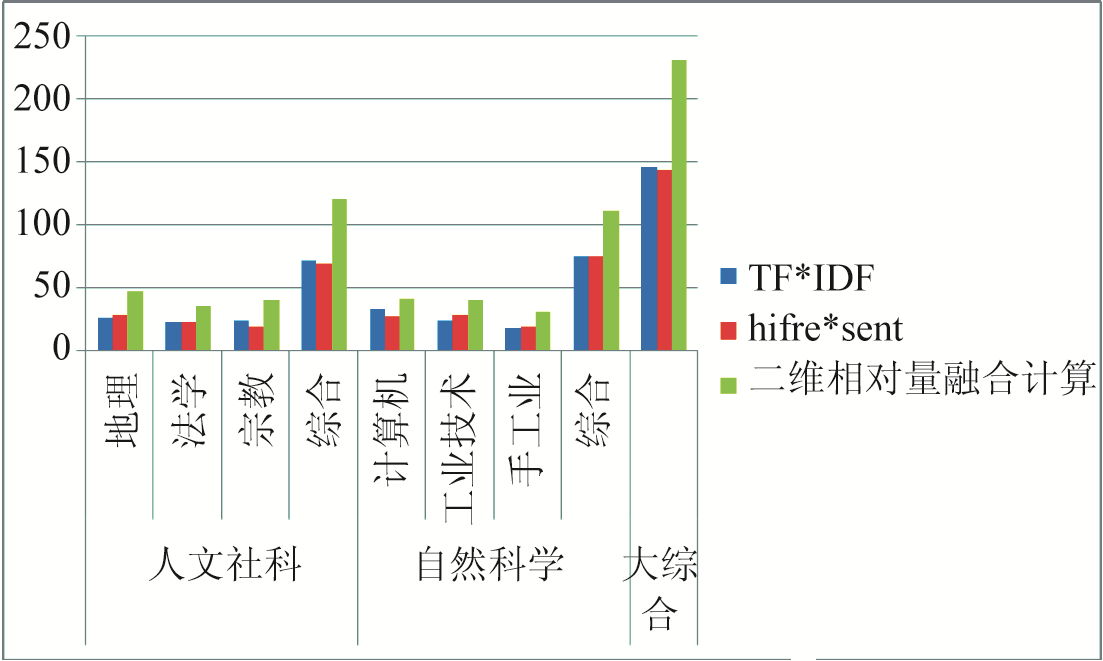 | 图5 排名第一的定义注释语句的数目对比 |
| 表3 叙词的定义注释语句抽取情况及有效信息提高比 |
| 表4 部分实验结果 |
6 结 语
本文针对OTCSS系统存在的大部分叙词概念缺少定义注释的不足,提出了可以缓解上述问题的概念定义注释自动构建方案,获得了良好的实验效果:对于实验语料,提取前三个句子,人文社科领域的叙词定义查准率可达到80%以上,自然科学领域的叙词定义查准率也能达到60%以上;且随着提取数量的增加,查准率也会随之提高。
将其整合到OTCSS系统后,实践证明,本文提出的解决方案具有实用价值,系统可在后台批量地从网络中搜索和筛选出概念的定义注释信息,修订专家可以灵活使用文中提到的三种算法对候选定义语句进行提取,为需要释义的叙词概念增加定义注释。欢迎登录深圳大学图书馆NKOS研究室网站(http://nkos.lib.szu.edu.cn)进行实际操作[ 5]。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|