



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
专利中技术词和功效词识别方法研究
引用本文
陈颖, 张晓林. 专利中技术词和功效词识别方法研究. 现代图书情报技术, 2011, 27(12): 24-30
Chen Ying, Zhang Xiaolin. Study on the Differentiating Method of Technical and Effect Words in Patent. 现代图书情报技术, 2011, 27(12): 24-30
Permissions
Chen Ying, Zhang Xiaolin. Study on the Differentiating Method of Technical and Effect Words in Patent. 现代图书情报技术, 2011, 27(12): 24-30
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
专利中技术词和功效词识别方法研究
摘要
针对目前专利非结构化信息分析任务中存在的不易鉴别和界定专利创新技术和专利所达功效的问题,提出一种基于专利结构-语法-线索词特征的技术词、功效词识别方法。此方法能综合考虑专利结构、语法和线索词三种特征因素,进而在整体上提高专利中技术词、功效词识别效果。
关键词:
专利分析; 技术功效矩阵; 语法分析; 结构分析; 专利工具; 专利软件
中图分类号:G350
Study on the Differentiating Method of Technical and Effect Words in Patent
Abstract
In analyzing unstructured information of patents, there is a problem in identifying and defining the technology innovations and the effect of patent currently.This paper puts forward a method to differentiate technical and effect words in patent,based on the features of patents’ structure-grammar-clue word.The method can synthetically consider three feature factors: the structure, the grammar and clues word, then improve the recognition result of the technical and effect words in patents.
Keyword:
Patent analysis; Technology-effect matrix; Syntax analysis; Structural analysis; Patent tools Patent software
1 引 言
专利文献非结构化信息的挖掘与分析日益成为专利研究的热点,对于制定专利战略、发现技术雷区有重要意义。其中,技术功效矩阵分析、技术角度分析、技术解决方案分析等专利分析方法由于能揭示专利中隐藏的重要信息内容,因而在近几年得到了更多关注。上述分析方法的前提和关键是对专利技术创新点和专利所达功效相关信息的准确识别和界定。目前,此项工作主要以人工为主,缺少系统、深入的研究。这与专利的技术主题、专利分析目的以及领域专家的主观判断有关,也与技术、功效只是在概念上加以界定、在实际应用中没有特别严格的差异有关。同样,由于词在专利中所处位置及所起作用不同,也会存在难以判断其是技术还是功效的情况。
本文依据专利特性、领域特征及专家访谈将技术定义为专利组件、技术词语;将功效定义为专利应用场合、技术所达功效。进而在分析专利的结构特征、语法特征和线索词特征的基础上提出基于专利结构-语法-线索词特征的识别方法,依据专利结构、语法及撰写遵循一定规范的现实,从三个角度来识别和界定专利技术词和功效词。
2 专利结构特征分析
专利是一种具有显著结构特征的科技文献,基于专利结构特征方面的研究较多,如专利文本的结构聚类[ 1]、将专利结构分析用于专利检索[ 2]、用专利权利要求书构建专利地图[ 3]等。
2.1 专利说明书中技术词、功效词分布分析
张惠等[ 4]对专利组成部分与产品设计知识之间的对应关系进行了说明,分析出产品设计知识主要分布在摘要、权利要求书、背景技术、发明内容、实施方式和附图中,且上述各部分知识描述的侧重点不同。摘要是包含专利各项信息比较全面的标引项,但为了保证专利权人的利益,通常只用比较概括性的词汇来简要说明专利的技术和功效;权利要求书是专利说明书中最重要的部分,其内容受到专利法的保护,所包含的技术功效信息也较为全面、具体;背景技术中包括很多专利的背景技术,将其与所分析专利的核心技术点和功效点相区别较为困难;发明内容和实施方式是对权利要求书的另一种形式描述,但更注重实现的方案和细节;附图是发明的技术图纸,无法进行文本处理。
将上述分析以表1表示(“+”表示存在)如下:
| 表1 专利各项包含本文定义的技术词、功效词情况 |
摘要和权利要求书是分析专利技术词、功效词的较好来源。更重要的是,在权利要求书中包含详细的专利组件信息和专利组件间功能信息,且与发明内容和实施方式相比噪声较少。
2.2 DII摘要中技术词、功效词分布分析
德温特创新索引数据库(Derwent Innovation Index, DII)[ 5]是专利分析的一个重要的数据库,为包括30多种非英语文本专利提供250-500字左右的摘要,详细介绍专利的权利声明、发明内容、主要用途和技术优势等。DII摘要经德温特专家判读后改写,将难懂的专业术语用通俗易懂的方式表达,便于专利分析人员理解。改写使得专利的核心内容,如主要技术、达到功效及其他重要信息更易彰显出来。虽然改写后的DII摘要可能存在与专利原文不符的情况,但在大量专利摘要数据集中,其比率基本上不会对专利分析造成很大影响。
基于以上因素,本文分析DII摘要结构特征,并提出相应处理方案。DII摘要的NOVELTY、USE/ADVANTAGE字段较好地对应专利三性的要求(新颖性、创新性、应用性)。NOVELTY包含专利主要创新性、专利组件,作为技术词来源;USE主要是专利应用场合,ADVANTAGE主要是专利性能效果,作为功效词来源。
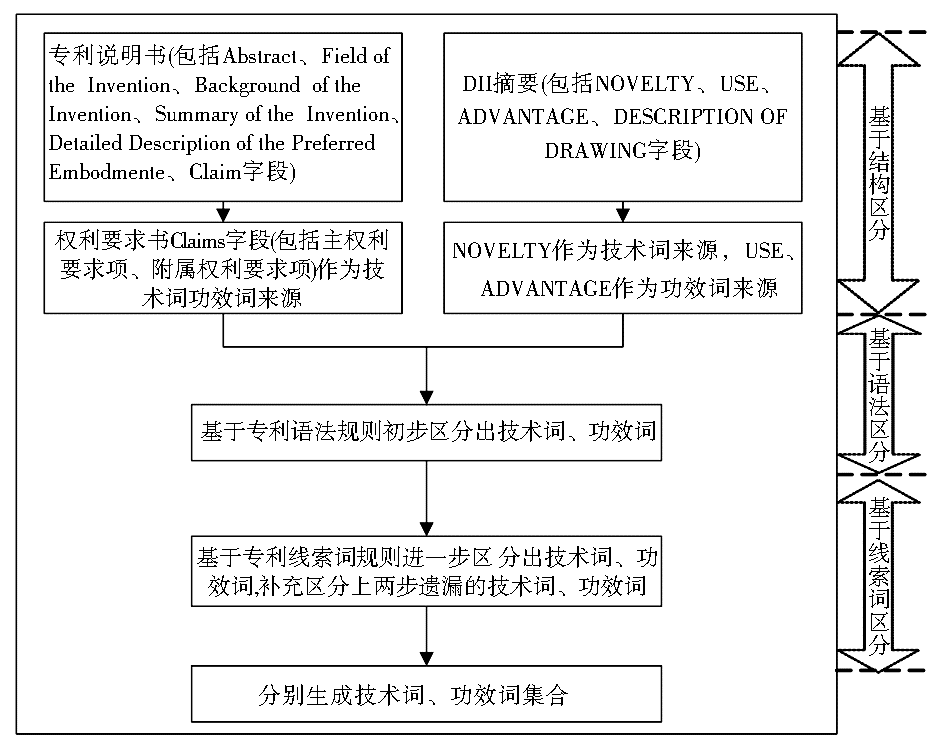
基于专利结构特征的识别是本识别方法的第一步。由于权利要求书和DII摘要包含技术词、功效词信息较多,因此作为本文研究对象,并据此提出基于专利结构特征的识别规则。
2.3 基于专利结构特征的识别规则(规则一)
(1)将专利说明书中权利要求书(包括主权利项和附属权利项)作为专利的技术词、功效词来源。
(2)将DII摘要的NOVELTY字段作为专利技术词主要来源;USE和ADVANTAGE字段作为专利功效词主要来源。其中,USE侧重与专利应用场合相关,ADVANTAGE侧重与专利性能效果相关。
3 专利语法特征分析
语法知识在自然语言处理系统中的应用就是处理文本的结构特性,称为语法分析[ 6]。 随着专利内容挖掘的深入,对专利语法结构及语义分析的研究渐渐受到重视。Indukuri等[ 5]基于语法语义信息计算专利声明之间的相似性;Shinmori 等[ 7]指出专利通常使用特殊句式和词汇,导致普通读者难以理解;进而提出了呈现专利声明结构的框架和自动分析框架的方法,其词汇框架与Shinmori等[ 8]的研究类似。同时还指出明晰化专利声明中的词汇,从专利特殊性的细节描述中发现解释部分,进而改善专利声明的可读性。
3.1 专利语法分析
TRIZ理论[ 9]的物-场模型(Substance-Field Model)把专利的功能高度概括化,把物质看作与专利中的部件相关,把场看作与专利的技术相关。相应地,可从这一视角审视专利中技术词、功效词的语法特征。
与之类似的是专利中“主词、动词与受词”句型(Subject-Action-Object,SAO)的研究。刘翰卿[ 10]对英文的基本结构和句型进行分析,认为句子基本架构是“主词(Subject)与动词(Verb)”,由动词启动可衍生成5大基本动词句型,形成简单句的内在基本结构,在此基础上可分析复杂句。
从语法特征角度分析技术词、功效词的语法特征,通常以SAO结构句型作为参考,可通过名词和动词的关系来理解句子的语意。在分析前人工作及调研基础上,发现技术词主要是名词或名词短语,功效词主要是动词+名词、形容词短语、副词短语及部分表示性能的名词。但这种划分仍过于宽泛,不能满足专利内容分析的要求。因此,有必要在此基础上细化技术词、功效词的语法特征。
3.2 专利组件分析
TRIZ理论中的物-场模型中的物质可看作专利的子系统,类似于专利组件。依据专利设计知识的特点,产品功能可通过特征零部件(专利组件)来实现。专利组件是完成专利功能的基础,专利组件间的协作和关联可看作专利的功能。前人研究中对此也有类似说明和定义,于立彪等[ 11]认为“一项产品权利要求应由反映该产品结构或组成的技术特征组成,一项方法权利要求应由实施该方法的具体步骤或操作方式的技术特征组成”;并指出如果没有采用这两种方式来定义,而是采用零部件或步骤在发明中所起的作用、功能或者所产生的效果来定义,则该款特征称为功能性限定特征,即“功能性特征”。可见,专利结构、专利零部件或步骤是专利声明的重要内容,从另一个角度体现了专利的技术特征。
分析发现,专利组件通常是以冠词(a, an, the)、“said”、“wherein”开头的名词和名词短语,也可以是括号开头的短语,如“(a)组件名”。
3.3 基于专利语法特征的识别规则(规则二)
总结技术词的语法特征,使用Brown语料库标记集来标识词性,常用词性如表2所示。
(1)基于语法特征的技术词识别规则(规则二之1)
参考文献[13],基于语法特征的技术词识别规则具体如表3所示。
| 表2 Brown语料库标记集说明(部分)[ 12] |
| 表3 规则二之1基于语法特征的技术词识别规则[ 13] |
(2)基于语法特征的功效词识别规则(规则二之2)
功效词的表述方式比技术词丰富,通常有以下几种形式:
①动词+形容词的名词形式(排除组件的情况),如“reduce difficulty”;
②形容词比较级形式,如 more+形容词比较级、特殊形容词的比较级等;
③形容词比较级+名词短语等。
通过阅读权利要求书及DII摘要对上述形式进行总结和扩展,提出基于语法特征的功效词识别规则,如表4所示:
| 表4 规则二之2基于语法特征的功效词识别规则 |
(3)基于语法特征的专利组件识别规则(规则二之3)
将与语法特征相关的专利组件(看作技术)识别规则概括如表 5所示:
| 表5 规则二之3基于语法特征的专利组件识别规则 |
其中,“at/.../cd”主要适用于DII摘要。
4 专利线索词特征分析
4.1 线索词界定
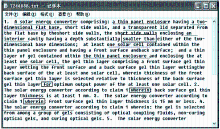
本文认为线索词包含专利特定用语和专利描述用语两种。专利特定用语是专利文本中特有的、用于辅助专利描述的、没有实质含义的词。这些词虽无实质含义,但能起到指示专利组件、功效或技术的作用。如“said”、“wherein”后面所接名词或名词短语是对组件或技术的重复;“for”、“used to”用于说明专利用途和应用场合等。专利描述用语用于揭示专利所采用的技术方案及所达到目标、效果的情况,如“improve”、“more”、“further”、“increase”、“reduce”、“performance”等。通过对这些词的分析可判断技术词、功效词的大致位置和功效改进的方向。权利要求书及DII摘要的线索词分析如图1和图2所示。 其中,框线内为线索词,下划线为组件词。
 | 图1 专利权利要求书线索词分析 |
 | 图2 DII摘要线索词分析 |
4.2 基于专利线索词特征的识别规则(规则三)
基于“线索词”概念,分析权利要求书及DII摘要中的线索词,提出基于线索词的技术词、功效词识别规则。
(1)技术词识别规则(规则三之1)
①“said”、“the”、“that”、“wherein”后的名词短语。
②位置关系词“contain”、“consisting of”、“ one end of…”、“ upper side of…”、“ comprise”、“ be constituted by”、“ be made of”、“ be provided with”、“ include”、“ be formed by”、“ of”、“ have” 前后的名词或名词短语(斜体部分参考了文献[14])。
(2)功效词识别规则 (规则三之2)
①与工程量有关的动词,如“shorten”、“lower”、“enhance”、“reliability”, “ increase”、“ decrease”、“ reduce”。如词是主动式,则抽取词后面的名词短语;如词是被动式,则抽取词及其前面的名词短语(斜体部分参考了文献[15])。
②与判断有关的动词,如“limit”、“optimizes”、“overcome”、“simplify”、“implemented”、“avoid”、“optimize”、“ improve”、“ worsen”。如词是主动式,则抽取词后面的名词短语;如词是被动式,则抽取词及其前面的名词短语(斜体部分参考了文献[15])。
③表明性能的名词,如“efficiency”、“feasibility”、“precision”、“requirements”、“reduction”、“quality”、“weakness”、“advantage”、“performance”。抽取词及其前面的限定词。
④表示目的、用途的短语,如“use for”、“to”、“for”、“achieve”、“ in order to”、“ with the aim of”、“ aiming at”、“ scope of”、“ thus+verb, ing form”、“ described-as”、“ conditioned-by”、“ decomposed-into”。抽取词及其后面的名词短语(斜体部分参考了文献[14]和[15])。
⑤表示操作状态优化的形容词, 如“rapid”、“accurate”、“simple”、“easy”、“effective”、“defining”、“superior”、“important”、“needed”。抽取词及其后面所修饰的词,如名词短语。
⑥表示程度的副词,如“further”、“ more”、“ less”、“ most”及“ [ adj] -er( comparative)”、“[ adj] -est( superlative)”。抽取词及其后面所修饰的词(斜体部分参考了文献[15])。
可依据专利工作不断充实完善线索词,并适当考虑将上述线索词的同义词加入规则中。需注意,专利对语言的表述要求比较严谨,并不是所有的同义词都能加入规则,更实际和科学的做法是从专利工作中积累完善。
5 基于专利结构-语法-线索词特征的技术词、功效词识别规则
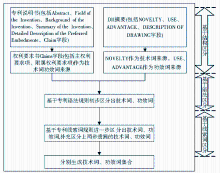
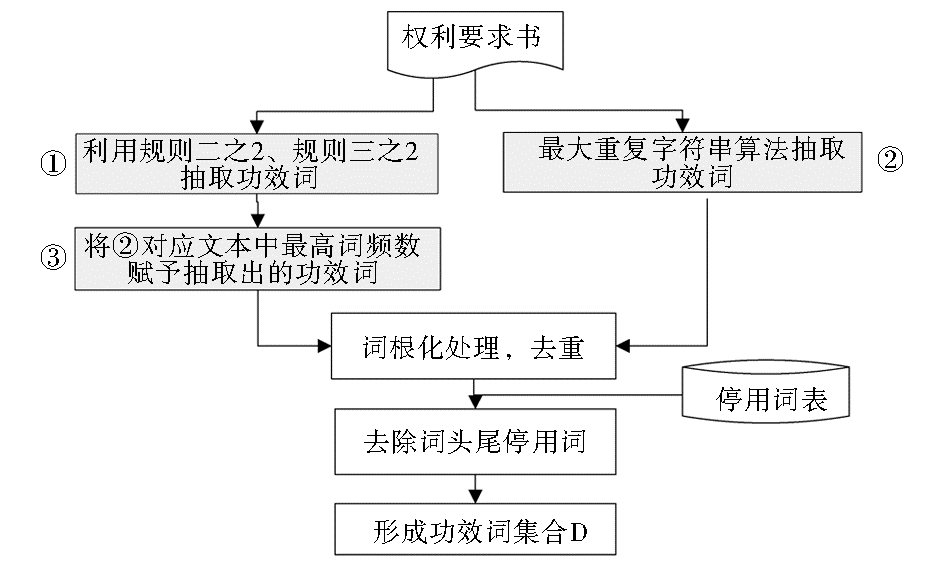
定义基于专利结构、语法和线索词特征的识别规则,依次递进地识别,可有效防止信息遗漏、误分等情况。规则流程如图3所示:
 | 图3 识别规则的流程 |
5.1 利用规则处理DII摘要的算法
处理DII摘要相应要完成技术词、功效词识别,词频统计,非技术词、功效词过滤等工作。
(1)识别技术词算法
算法所需外部资源:Onix Text Retrieval Toolkit停用词表[ 16]、词性标注工具LingPipe[ 17]。
算法主要操作:识别出DII摘要中的专利组件和重复名词、名词类词组;对识别出的词进行词频调整和合并去重,形成候选技术词集合。
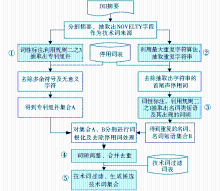
算法流程如图4所示。
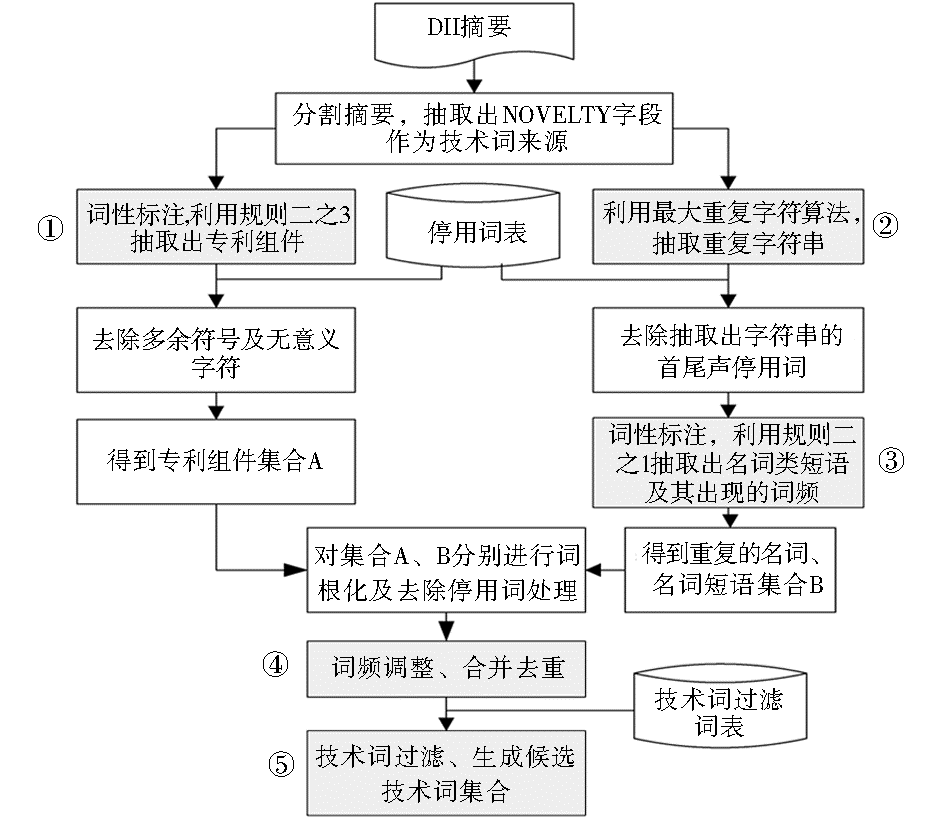 | 图4 利用规则识别DII摘要技术词的算法流程 |
①利用规则二之3抽取专利组件
DII摘要中组件常有两种表达形式:以冠词开头,以带括号数字结尾,如“A controller (20)”;不一定以冠词开头,但以带括号大写英文字母结尾,如“Step-up device (H)”。因此,要抽取这些结尾标志之前的名词或名词短语。
②最大重复字符串
本文假设“专利中重要的技术点和功效点通常都会在专利中重复出现”。采用改进的“最大重复串算法”[ 18]抽取重复串,限定n小于等于5。利用词频调整和技术词过滤规则将不太重要的以及非技术点、功效点相关词的重复词去除,从而降低这类噪声词对后续分析工作的影响。
③利用规则二之1抽取名词类词汇
抽取除组件外其他可能的技术词,主要是名词及名词短语。
④词频调整及合并去除
集合A代表抽取出的专利组件(词频为1);集合B代表利用最大重复字符串算法抽取出的技术词(词频为重复词出现频次)。集合A、B重叠情况如图5所示,最后生成的技术词集合为C=A∪B。基于本文 “专利组件在专利技术词中占有较高优先级” 的假设,应当对不同集合中词元素赋予不同权重。
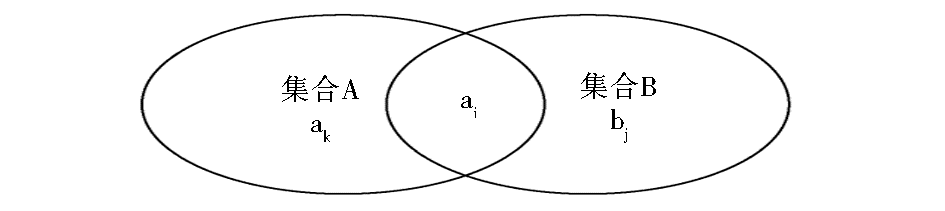 | 图5 抽取出技术词集合重叠情况 |
i, ak, bj分别代表集合中的元素。其中,ai∈A, ai∈B; ak∈A,ak∉B; bj∈B,bj∉A。则ai, ak, bj在最后形成的技术词集合C中的重要性为ai≥ak≥ bj。因此,本文在合并集合A、B时,认为词权重w应满足]]>
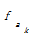
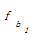
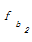
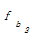
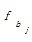
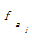
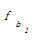
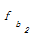


设定抽取重复字串的阈值为2,相应将式(2)的权重增加2以示区别。bj没有出现在集合A中,不是专利组件,因此,保持原有词频不变。
⑤技术词过滤算法
算法虽能抽取出大部分技术词,但也包含部分对技术功效分析没有意义的词,主要有非实意词(如“second”、“method”、“way”等)和专利描述词(如“claims”、“claim”、“wherein”、“said”等)。需针对实验情况编制程序将其去除。
本文发现检索系统中禁用词[ 19]和要过滤掉的词有相似之处,因此,在美国专利全文数据库禁用词表[ 20]基础上,补充从实验中发现的非实意词形成技术词、功效词过滤词表,详见附录I。
(2)识别功效词算法
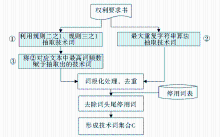
本算法与识别技术词算法类似,但识别规则不同,流程如图 6所示:
 | 图6 利用规则识别DII摘要功效词算法流程 |
①利用规则二之2抽取功效类短语
抽取USE/ADVANTAGE字段作为功效词来源。USE为专利应用场合,ADVANTAGE为专利所达功效。
②去除字符串首尾停用词
利用停用词表去除对分析功效点没有意义的词。
③功效词过滤规则
利用功效词过滤词表(附录I)去除非实意词和专利描述词。
USE、ADVANTAGE字段包含足够多的功效信息,二者结合可达到较好的分析效果。USE字段之前的信息基本描述专利组件及专利原理,对功效分析意义不大。因此不再对DII摘要抽取重复字符串。此外,有的专利中USE、ADVANTAGE字段是合一的,在DII摘要中表述为“USE/ADVANTAGE”,此种情况下将其算作ADVANTAGE字段。另外,没有USE字段的专利一般都有ADVANTAGE字段,此种情况对分析影响不大。
6 结 语
专利中技术词、功效词的识别区分是专利内容分析的一个难题。本文通过分析专利的结构、语法和线索词特征,提出基于专利结构-语法-线索词特征的技术词、功效词识别方法,有效地解决了此难题。此外,将专利技术词、功效词识别与抽取看作两个紧密相关的步骤,识别是抽取的依据,抽取是识别的目的,抽取的结果可验证和改进识别的效果。笔者利用“光伏系统逆变器”专利的DII摘要和权利要求书验证本方法的准确率和重复率,具体将另撰文详述。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|