{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
微博客用户特性及动机分析*——以和讯财经微博为例
引用本文
赵文兵, 朱庆华, 吴克文, 黄奇. 微博客用户特性及动机分析*——以和讯财经微博为例 . 现代图书情报技术, 2011, 27(2): 69-75
Zhao Wenbing, Zhu Qinghua, Wu Kewen, Huang Qi. Analysis of Micro-blogging User Character and Motivation —— Take Micro-blogging of Hexun.com as an Example. 现代图书情报技术, 2011, 27(2): 69-75
Permissions
Zhao Wenbing, Zhu Qinghua, Wu Kewen, Huang Qi. Analysis of Micro-blogging User Character and Motivation —— Take Micro-blogging of Hexun.com as an Example. 现代图书情报技术, 2011, 27(2): 69-75
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
微博客用户特性及动机分析*——以和讯财经微博为例
摘要
以国内财经网站和讯微博为例,使用计量学方法,对用户特性进行统计分析,并使用可视化软件Pajek进行可视化分析。研究表明,微博客用户的特性,关注者数、被关注者数和博文数均具有统计特性,地域差异明显;另外,两种类型的用户群体之和占用户总体的近90%,具有很强的代表性,为深入研究微博客用户行为提供参考。
关键词:
微博客; 用户特性; 用户动机; 社会网络分析; 幂律分布
中图分类号:G203
Analysis of Micro-blogging User Character and Motivation —— Take Micro-blogging of Hexun.com as an Example
Abstract
Using metrological methods, this paper analyzes data crawled from micro-blogging of Hexun.com and also uses Pajek to view the social network structure of Hexun micro-blogging. The result shows that, the characters of micro-blogging users have favorable statistic characteristics, and the regional disparities between micro-blogging users are quite remarkable. Moreover, two kinds of micro-blogging users account for almost 90% of the total users. This paper is helpful for other researchers to study micro-blogging users behavior.
Keyword:
Micro-blogging; User character User motivation; Social network analysis; Power-law distribution
1 引 言
微博客是一种允许用户及时更新简短文本(通常少于200字)并可以公开发布的博客形式,它允许任何人阅读或者只能由用户选择的群组阅读。这些消息可以被很多方式传送,包括短信、实时消息软件、电子邮件、MP3 或网页[ 1]。可以认为微博客是一种思想,也可以理解为一种交流的方法,而大多数情况是作为一种网络应用技术而存在。
2006年10月,首个微博客网站——Twitter诞生。经过发展,Twitter日均访问量在欧美等地的网站排名中均列前15位[ 2]。至此,Twitter已经成为微博客的代名词。除了Twitter外,国外著名的微博客网站还有Jaiku、Plurk、Juick、Google Buzz和Yahoo!Meme等。国内著名的微博客有新浪微博、腾讯微博、网易微博、人民微博以及本文涉及的和讯财经微博等。 微博客之所以流行主要有以下三个方面的原因:
(1)易用性,门槛低。微博客的一条信息最长为140字,只言片语即能表达简要信息。
(2)持续增长的用户信息需求以及即时更新的信息资讯。
(3)Web2.0时代的到来以及智能手持设备的普及。
微博客作为Web2.0环境下最具竞争力的网络应用,正受到世界范围内的关注。因此,有必要针对微博客的用户特性、使用动机以及行为等进行深入研究,从而为微博客的发展提供可信的理论支撑和实践指导。
2 研究现状
国外对微博客的研究体现出了多样性。对于网站链接以及博客的分析则可作为微博客研究的基础,具有很高的参考价值。Broder等发现网站链接等属性的度分布遵循幂律分布[ 3]; Nardi等探讨了博客用户的使用动机,认为博客是人们分享经验、观点和评价的工具[ 4]。这些研究都为后续对微博客的研究提供了宝贵的借鉴。Honeycutt等以Twitter为例,研究用户沟通协作的程度,并为微博客的设计提供借鉴[ 5]。Java等研究了微博客的使用,利用HITS算法计算Twitter上用户的中心度和权威度,将用户分为信息共享、信息搜集和朋友关系三类,发现微博客用户的目的主要是谈论日常的活动以及寻找、共享有价值的信息[ 6]。 Naaman等根据Twitter用户发布的状态信息,进行内容分析,将用户分成9大类,其中IS (信息共享)、 OC (意见/抱怨)、 RT (随机想法)和ME (关于我的一切)4大类占据主体部分[ 7]。
国内关于微博客的研究以定性方法为主,内容上则主要侧重信息传播和微博客的应用两个方面。从传播学角度出发,黄朔认为微博客在进行信息传播时,自身跨媒介传播的特点使其传播阶段和模式呈现出多级化状态[ 8]。卢金珠对微博客的传播特性和盈利模式进行了相关研究,认为短信分成、广告、品牌服务、电子商务和虚拟产品可能是微博客可行的几类盈利模式[ 9]。从微博客的应用角度出发,王树义等介绍了Twitter在竞争情报工作中的两类实际应用,并通过实例证明了Twitter能够在竞争情报工作中发挥重要的作用[ 10]。崔争艳探讨了微博客中短信息的分类,结合《知网》本体库,将关键词映射到语义概念,并用语义分类算法KNN实现对短信息的分类,得到很好的准确率和召回率[ 11]。
国内微博客服务近几年发展迅速,综合性的微博网站如新浪微博,以及专业性的如和讯财经微博等,都拥有了成熟的用户群,这为国内研究微博客提供了很好的数据来源。目前定量的实证研究还比较少,可以查阅到的只有基于新浪微博的两篇实证文章[ 12, 13],但这两篇文章使用简单随机抽样和分层抽样方式,样本量分别只有3 000条记录和438条记录,相对新浪微博5 000万注册数的总体,样本容量略显不足。
本文以和讯财经微博为例,采用滚雪球抽样方法(保证样本量足够大),对微博客用户使用特性进行统计分析,再进行用户类别归类及动机分析,弥补国内对于微博客用户特性及动机进行实证研究的不足,为进一步研究用户行为以及社区知识共享提供参考。
3 数据采集
国内发展较好的微博客以新浪微博、腾讯微博、网易微博和人民微博等综合性微博客为代表,专业性很强的比如财经类微博客有掌牛微博和和讯财经微博等。本文之所以选择和讯财经微博作为分析对象,是因为综合性微博客用户量大,用户信息需求各不相同,且开放性不好,而和讯微博由于是专业性财经微博,用户数虽然没有综合性微博多,但已经形成一个比较成熟的用户群,数据量相对较小且纯度高,便于分析。
由于和讯微博并没有像Twitter那样提供应用程序接口(API),所以本文的数据采集工具是基于Java语言自行编写的爬虫程序,采用滚雪球抽样方法,从一个起始页面开始抓取,然后使用正则表达式匹配算法抽取出所需数据信息存入数据库,再从关注者和被关注者链接爬取下一层页面,这样循环往复,直至遍历网络中所有相连的节点。这种机制可以遍历网络中所有相连的节点,但会漏掉孤立的节点以及和主题网络不相连的独立子网络,但由于网络中孤立的节点实际上是没有意义的,可以忽略,且独立的子网络理论上可能存在,但实际环境下这种概率很小,可以忽略不计。这样,不考虑时间因素的干扰,使用这种滚雪球抽样方法抽出的样本容量实际上和总体数量几乎接近,基于样本的研究也就能充分代表总体的规律。这里需要声明,考虑到程序爬取页面过程中在目标服务器中占用一定的服务资源,爬虫程序设计时设定了休眠时间,这样不会给目标服务器造成拥堵现象。
本文的数据采集工作历时两周,以滚雪球的方式进行最大化收集。数据库表结构如下:
UserDetail(userid,myfollow,followmy,article,address)
UserRelation(id,item,input)
有下划线的属性作为表的主属性。用户资料表UserDetail包含用户的各项数据信息,包括用户账号、关注数、被关注数、博文数、地区。例如记录(lxfsun,15,324,844,辽宁省)表示来自辽宁的用户lxfsun关注15位其他用户,被324位其他用户关注,发表了844篇微博;用户关系表UserRelation记录用户之间相互关注的关系,包括记录ID、用户本身以及指向该用户本身的用户。例如记录(284651,lxfsun,15116582)表示第284 651条记录,用户15116582关注用户lxfsun,也即用户15116582指向用户lxfsun。其中用户资料表UserDetail含有72 068条记录,用户关系表UserRelation含有364 028条记录。
4 用户特性分析
本文就用户表中用户的关注数、被关注数、博文数和地区进行统计分析,同时就关注数、被关注数和博文数三者进行两两之间的相关分析。
4.1 关注数
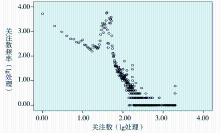
关注数是某用户关注微博客网络上其他用户的数量特征,例如某用户的关注数是67,说明该用户自注册微博客账号起到笔者抓取数据当日止,一共关注了67位其他用户。由于不经过处理的数据散点图不能很好地揭示数据呈现的幂律特征,所以需要先进行对数处理。本文利用SPSS软件对关注数和关注数频率进行10的对数处理(lg处理),再绘制散点图,如图1所示。
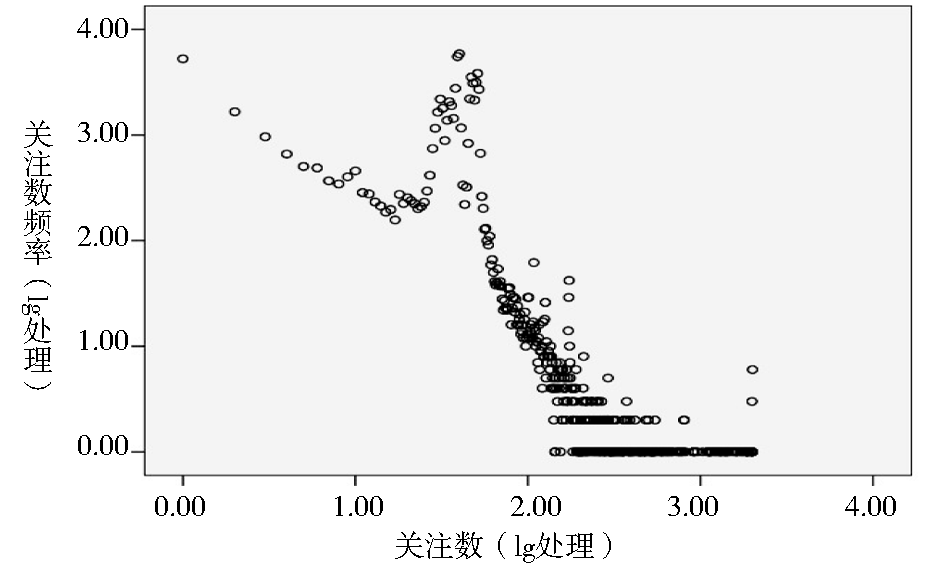 | 图1 关注数和关注数频率散点图 |
图1中,单个散点代表的意思是关注数是a个的用户有b个。经统计分析发现,用户关注数总体上存在长尾现象,13.86%的高关注数用户占据了总关注数的28.07%,说明剩余71.93%的关注数其实是由86.14%的长尾占据的。中间凸出的部分对应于X轴所对应的关注数的范围在30到50之间,所有用户关注数平均值是38.39,说明大多数用户喜欢将自己关注其他用户的数目控制在30到50人之间,因为这些已经足够自己获取相关信息,而更多的关注者则会增加自己获取有效信息的时间以及降低获取所需信息的效率,同时太少的关注者则不能获取足够的信息。关注数体现用户获取信息的动机,处在长尾区域的用户虽然单体的关注数并不高,但总体却很大,他们贡献了总关注数的主要部分。
4.2 被关注数
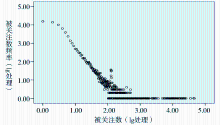
被关注数是某用户被微博客网络上其他用户关注的数量特征,例如某位用户的被关注数是1 250,说明该用户自注册微博客账号起到笔者抓取数据当日止,一共被1 250位其他用户关注。本文利用SPSS软件对被关注数和被关注数频率先进行10的对数处理(lg处理),再绘制散点图,如图2所示:
 | 图2 被关注数和被关注数频率散点图 |
由图2可以看出,用户被关注数遵循幂律分布,进一步统计分析发现,所有用户被关注数平均值是15.11,其中2.78%的用户的被关注数之和占总被关注数的80.6%,说明存在“明星”现象,即极少数的一部分用户获得了广泛的关注。这与新浪微博中的超高人气的少数明星用户特性相吻合,说明微博客中少数的权威用户的影响非常大,而大多数用户的影响力只局限在很小的范围内。结合上面描述的对关注者的分析,少数的用户超高的被关注数则是由整个微博客网络中大多数用户贡献的。这些大多数用户单个的关注数并不高,只是总量很大,从而创造了少部分明星用户超高的被关注数。被关注数体现了用户的影响力,那些拥有很高被关注数的用户发布信息已经不再是简单的自我需求,而体现了一定规模的媒体作用。
4.3 博文数
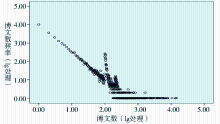
博文数是某用户发布微博次数的数量特征,例如某位用户的博文数是150,说明该用户自注册微博客账号起到笔者抓取数据当日止,一共发布了150篇微博信息。本文利用SPSS软件对博文数和博文数频率先进行10的对数处理(lg处理),再绘制散点图,如图3所示:
 | 图3 博文数和博文数频率散点图 |
由图3可以看出,用户博文数近似遵循幂律分布,进一步统计分析发现,所有用户博文数的平均值是12.25,其中4.44%的用户创造的博文数占总体博文数的81.4%,即很少的一部分用户创造了总博文数的大多数,而很多用户只写了很少的博文,有很大一部分甚至只写了1篇博文。博文数体现用户使用微博客过程中信息创造和共享的活跃程度,和讯微博用户的平均信息创造和共享活跃程度相对较低,很大一部分用户只是为了获取信息而使用微博,而对自身信息创造和共享不够重视。
4.4 地区分布
利用SPSS对用户所在地区按省、市、自治区等进行统计,并按一般的划分方法将各省、市、自治区分别归属于9大地区,如表1所示。
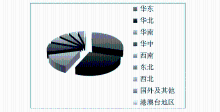
得到不同地区用户数的统计饼图,如图4所示。
| 表1 9大地区及其所包括区域 |
 | 图4 用户地区分布示意图 |
排名从高到底依次是:华东、华北、华南、华中、西南、东北、西北、港澳台地区和国外及其他。其中华东、华北和华南三个地区加起来的用户数占总用户数的71%,而剩下的6个地区加起来只占总用户数的29%,说明微博客,特别是财经类微博客在沿海发达城市发展较好,而在我国中西部地区发展则较为缓慢,这和我国地区经济发展水平以及信息技术教育普及程度有很大的关系。
4.5 相关分析
对用户关注数、被关注数、博文数三者使用Bivariate过程计算两两之间的Pearson系数,得到结果如表2所示:
| 表2 用户关注数、被关注数、博文数三者两两之间的相关性 |
被关注数和博文数之间的相关系数为0.435(0.00显著水平),Pearson相关认为,相关系数0.4至0.5表示比较相关,即被关注数和博文数之间存在比较相关,即博文数越多,被关注的概率越大;关注数和博文数之间的相关系数为0.385(0.00显著水平),Pearson相关认为,相关系数0.2至0.4表示正弱相关,即关注数和博文数之间存在正弱相关,即博文数越多,关注数越大的可能性很弱;关注数和被关注数之间的相关系数为0.122(0.00显著水平),Pearson相关认为,相关系数0至0.2表示几乎不相关,即关注数和博文数之间几乎不存在相关关系,关注数越多并不代表被关注数就多。这在现实中也很好理解,比如一些权威人士,他们发布的信息可能具有指引作用,被关注数很大,但他自己并不怎么关心其他人发布的信息,关注数就小,而有些人为了搜集尽可能全的信息,关注数很大,但由于自身影响不够,被关注数可能很小。综上所述,用户关注数、被关注数、博文数三者两两之间并不存在很强的相关性,否则用户可以为了使某项指数得到较高的关注而采取提高和它很相关的另一个指数,这样不利于微博客的健康发展。
5 用户类型及动机分析
5.1 用户分类及分析
上述对用户特性进行的统计分析,包括关注数、被关注数、博文数和地区分布,都是单独作为一个变量进行的统计分析,为了能更好地理解用户使用动机,本文综合关注数、被关注数和博文数三个变量,先进行用户分类,再根据分类讨论用户动机。
关于微博客用户分类,不同的研究使用的分类方法以及分类的角度都不尽相同。Java等的分类[ 6]和Naaman等的分类[ 7]均以Twitter为例。Twitter属于综合性微博客服务,而和讯财经微博则属于专业性微博,所以之前研究的分类方法和结果可能不适合本文的研究。本文采用的分类方法是综合关注数、被关注数和博文数三个用户特性变量,进行统计分析,希望识别出占总体数量比重较大的用户群体,并分析他们的使用动机。具体做法是:对关注数、被关注数和博文数三个变量分别设定一个衡量值,这里选用每个变量的平均值作为衡量值(关注数、被关注数和博文数的平均值分别为38.39、15.11、12.25),每个变量大于衡量值的取1,小于衡量值的取0,这样对用户表中的每一条记录的三个变量进行运算,得到每条记录根据关注数、被关注数和博文数三个变量定义的类型。本文选取每个变量的平均值作为衡量值,而不选其他集中趋势统计量例如中位数、众数等作为衡量值,因为希望得到每个变量的平均水平,而不是居于中间位置的或者重复次数多的数据,这样有利于分类的准确性和合理性。
这样,三个变量每个变量只能取0或1,所以共有8种类型,分别记作(1,0,0)、(0,0,0)、(1,0,1)、(0,0,1)、(1,1,1)、(0,1,1)、(0,1,0)、(1,1,0)。统计得到类型数量和所占比例如表3所示:
| 表3 8种不同的用户类型及所占比重 |
可以看出,类型(1,0,0)所占比重最大,为52.12%,类型(0,0,0)所占比重次之,为37.47%,二者之和占据总体的89.59%。类型(1,0,0)超过总体的一半,属于关注数相对较多,但自身被关注较少,且博文数也较少的用户,这种类型的用户使用微博客的主要动机是搜寻信息,这其实也是使用微博客的初衷,即获取有价值的信息;类型(0,0,0)占总体的数量大于三分之一,属于网络游民,他们可能从某种渠道得知和讯微博提供某类他们想要了解的专业信息,于是注册账号开始使用和讯微博,但只是偶尔登录浏览一下信息,并没有真正使用起来(比如发布博文,关注更多的人并增加自己的影响力,从而使自己的被关注数提高),这种类型的用户的动机来源于一时兴起的冲动,并没有真正频繁地使用微博客。其他6类用户都有各自的特点,比如类型(1,1,1)属于和讯微博的忠实粉丝,影响力以及自己的活跃程度都非常高,这类用户的动机是做和讯微博的专业用户。类型(0,0,1)属于Naaman等的分类中的ME型[ 7],他们只关注与自己有关的一切,并且积极地发布在微博客上,并不关心别人会不会关注,这样他们的被关注数自然也会比较少。由于这6种类型所占比例较低,代表性有限,这里不再讨论。
5.2 可视化分析
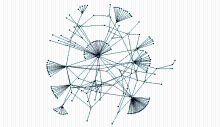
通过关于微博客用户类型的统计分析发现,类型(1,0,0)和类型(0,0,0)占用户总体的绝大多数。应用社会网络分析软件Pajek对网络进行可视化分析。本文在采样的数据中随机抽取330个节点(330个节点已经足够揭示其网络分布特征,且太多的节点则会由于太多边而看不清具体结构),使用Fruchterman Reingold方式绘制3D网络图,调整后得到如图5所示:
 | 图5 随机抽取的部分节点组成的3D网络图 |
从图5可以看出这是一种典型的无标度网络[ 14],并且出现核心-边缘现象:很多个节点同时关注某一个节点,这些核心的节点很可能是注册网站系统自动推荐给新用户以供关注的明星用户,而这些边缘节点就属于(0,0,0)型用户,他们不常用微博,可以看出,这部分用户所占比例相当大。
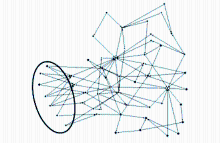
进一步分析,使用Pajek对图5的网络做节点的删减,去除度小于2的节点和相连的边,剩下53个节点及其相连的边,得到如图6所示:
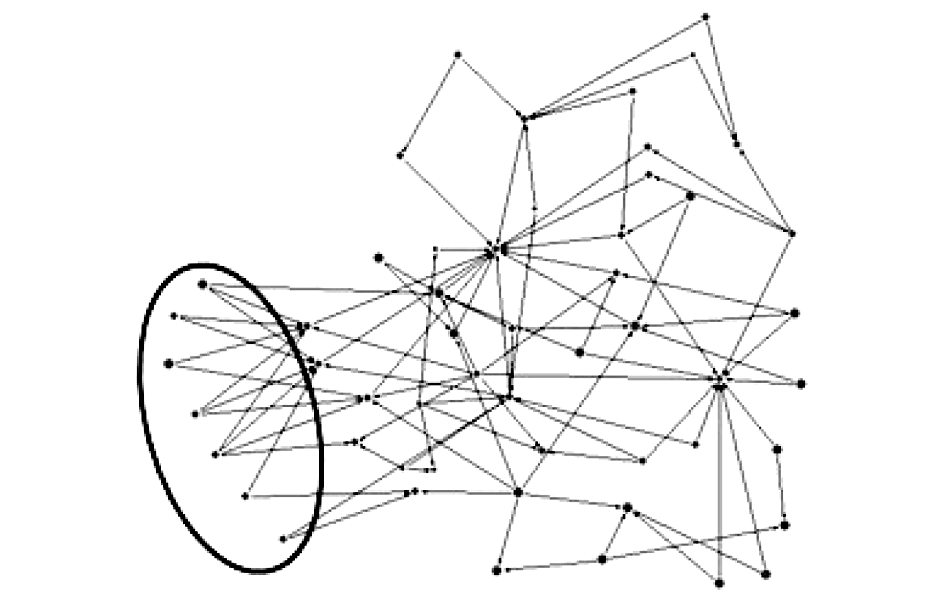 | 图6 删除度为2的节点后的3D网络图 |
可以看出,去除图5中的边缘节点后,整个网络变得相对紧凑,但仍有部分节点表现出只关注某些节点但很少被关注的现象。图6中圈出来的部分中的节点,只有出度,没有入度,这部分节点属于(1,0,0)型用户,他们以搜寻信息为动机,关注数比较大,但被关注数和博文都比较少,自然不能成为网络中的中心,但这样的节点在整个网络中很多,这也间接说明类型(1,0,0)所占比例为52.12%是可信的,在现实网络微博用户中,具有这种动机的用户占总体的一半左右。
6 结 论
本文在国内外微博客研究的基础上,采用统计学和社会网络分析方法,以国内专业性财经微博客和讯微博为例,通过对用户特性和动机的分析,得出以下结论:
(1)用户关注数体现用户搜寻信息的动机,研究发现,用户关注数分布呈现长尾现象;
(2)用户被关注数遵循幂律分布,并体现用户的影响力,明星用户发布信息已经不是简单的自我需求,而表现出一定规模的媒体作用;
(3)博文数体现用户信息创造和共享活跃程度,用户博文数近似遵循幂律分布,很少的用户创造出了很大部分的博文;
(4)用户分布在地区上存在明显的差异,华北、华东和华南三个地区的用户数占总用户数的71%,这和我国各地区经济发展水平以及信息技术教育普及程度有很大的关系;
(5)综合关注数、被关注数和博文数,得出8种不同的用户类型。其中(1,0,0)和(0,0,0)两种类型占总体用户数的将近90%;
(6)(1,0,0)和(0,0,0)分别对应网络中两种普遍的用户,前一种以信息搜寻为动机,后一种则是微博客的新手,不经常使用微博客,这两种普遍类型用户的存在及动机可以通过Pajek生成的可视化网络图得以证明。
本文的不足体现在以下两方面:
(1)只对一种微博客网站进行研究,可能会忽视不同类型的微博客网站之间的差异,从而影响得出结论的代表性;
(2)只从信息传递角度研究用户的动机,缺少针对用户心理、社会网络环境因素的考虑。这些问题在今后的研究中有待改进和完善。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|