

{kind=link}
{kind=link}
{kind=link}
基于关联规则综合评价的图书推荐模型
引用本文
路永和, 曹利朝. 基于关联规则综合评价的图书推荐模型. 现代图书情报技术, 2011, 27(2): 81-86
Lu Yonghe, Cao Lichao. Books Recommended Model Based on Association Rules Comprehensive Evaluation. 现代图书情报技术, 2011, 27(2): 81-86
Permissions
Lu Yonghe, Cao Lichao. Books Recommended Model Based on Association Rules Comprehensive Evaluation. 现代图书情报技术, 2011, 27(2): 81-86
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于关联规则综合评价的图书推荐模型
摘要
通过对关联规则综合评价的探讨,提出基于支持度、置信度、Jaccard兴趣度、吸引度和收益因素,面向网上书店和数字图书馆的图书推荐模型,运用熵权法和相对比较法确定模型中指标的权重,并对模型的算法进行研究。通过开发的网上书店系统对模型的功能进行验证,结果表明:该模型能够很好地为用户提供推荐图书。
关键词:
关联规则综合评价; 图书推荐模型; 网上书店; 数字图书馆; 熵权法
中图分类号:TP391
Books Recommended Model Based on Association Rules Comprehensive Evaluation
Abstract
With the research of association rules comprehensive evaluation, this article proposes a books recommended model based on the factors of Support, Confidence, Jaccard Interestingness, Attraction and Profit, and it is also oriented to online bookstores and digital libraries. At the same time, this article determines the weights of the factors in the model by the entropy method and the relative comparison method, and research on the algorithm of the model. Finally, it verifies the function of the model by the developed online bookstore system. The running results of the online bookstore system show that the model can provide the recommended book for users excellently.
Keyword:
Association rules comprehensive evaluation; Book recommended model; Online bookstore; Digital library; Entropy method
图书推荐不论是对于网上书店还是对于数字图书馆建设都是很有意义的,在网上书店中它可以为用户提供购书的参考意见,也能为书店管理员进货、促销以及组合销售提供决策支持;在数字图书馆中,图书推荐即为书目推荐,是书目检索服务的有益补充,能为用户提供个性化服务。
1 需求及技术思路
1.1 国内外的应用现状
李凯敏[ 1]提到了将关联规则挖掘运用到网上书店系统中挖掘出不同图书之间的关联性,以实现图书推荐,但是没有给出具体算法的描述。高彩霞[ 2]提出了将关联规则挖掘应用于网上书店系统中为用户提供个性化图书推荐,该文献单纯使用支持度和置信度来衡量规则的优劣,存在缺陷。丁雪[ 3]将关联规则运用于图书馆为用户提供图书推荐,并给出了图书智能推荐系统的框架设计,该研究使用数据挖掘软件Weka来进行实验,没有对底层的关联规则算法进行研究。赵麟[ 4]使用最大频繁模式挖掘算法进行图书推荐,对FP-max算法进行分析,并设计实现了书目推荐系统。徐嘉莉等[ 5]通过对Apriori算法改进,提出一种快速的个性化书目推荐方法。Liu等[ 6]使用关联规则挖掘来构建推荐系统,Kim等[ 7]使用多层次关联规则来实现推荐功能。
1.2 现实工作中的应用需求
前人已就图书推荐做了很多探索,大多是使用关联规则挖掘来实现的,在应用的过程中缺少关联规则的评价,在实际系统中的运行效果还有待提高,目前还没有运用关联规则综合评价思想来进行图书推荐的研究,本文尝试在这方面进行一些探索,以期能得到更好的图书推荐结果。
1.3 技术思路及技术方法
在已有的关联规则挖掘与综合评价研究的基础上,结合具体的应用背景,从多个方面对规则进行分析,确定对规则进行评价的指标,并对指标权值进行确定,得出综合模型和兴趣度最大的规则,从而得到推荐图书。本文还将给出具体的算法描述以及对模型的验证。
2 关联规则综合评价
关联规则算法挖掘出来的满足支持度和置信度阈值的强规则并不都是有用的、用户感兴趣的规则,有些甚至是错误的规则,一个较为经典的例子是牛奶和咖啡的销售统计,如表1所示:
| 表1 牛奶和咖啡销售统计表 |
设minsup=0.2,minconf=0.8;考虑规则{牛奶}→{咖啡},该规则的支持度s=20/100=0.2,置信度c=20/25=0.8,该规则在支持度-置信度框架下是强规则,因此有可能认为购买牛奶增加了购买咖啡的可能性,从而把牛奶和咖啡放在一起销售,但是再计算购买咖啡的可能性为90/100=0.9,大于置信度0.8,也就是说购买牛奶非但没有增加购买咖啡的可能性,还减少了购买咖啡的可能性,因此单纯使用支持度和置信度来评价关联规则存在着一些缺陷,必须采用一些新的评价指标来评价关联规则。
关联规则综合评价是将关联规则的客观评价指标与主观评价指标结合起来对规则进行评价,客观评价指标主要有支持度、置信度、相关度。苏占东等[ 8]将相关度的计算公式定义为:
correlativity=P(X⋃Y)P(X)P(Y) (1)
如果correlativity等于1,则X和Y之间没有相关性;如果correlativity小于1,则X和Y是负相关的;如果correlativity大于1,则X和Y是正相关的。在表1的例子中,牛奶和咖啡的相关度为20×100/(90×25)≈0.89,因此牛奶和咖啡是负相关的。王剑等[ 9] 从数学上推导出X和Y正相关等价于X和Y负相关,等价于X和Y负相关,等价于X和Y正相关,并在此基础上给出了对强相关规则进一步过滤的算法,优化了对强相关规则的处理过程。谭学清等[ 10]对关联规则的客观兴趣度度量方法进行了比较研究,研究结果显示任何一个单一的客观兴趣度度量指标都不能决定规则的兴趣度,必须将多个不同指标组合来决定哪些是真正有兴趣的规则。
主观评价指标主要有新颖度、简洁度、可行性等。苏占东等[ 8]提出了关联规则的综合评价模型,对于支持度s、置信度c、相关度corrR、新颖度Wi、用户感兴趣度USI、简洁度CN,规则的综合评价指标——综合评价度应定义为这几个评价指标的几何加权平均:
RI=sw1×cw2×corrRw3×Wiw4×USIw5×(1CN)w6(2)
其中:wi≥0 (i=1,2,…,6),∑i=16wi=1。
但该方法没有给出权值的确定方法。
3 基于关联规则综合评价的图书推荐模型
3.1 模型的提出
定义1:图书组合是指由两本不相同的书组成的集合,设有图书组合S={A,B},A的组合图书即为图书B。
定义2:组合兴趣度(Combination Interestingness)是指对图书组合的合适程度的度量,它是对图书关联性、用户态度以及收益等多种因素的综合考虑。
(1)客观度量
组合兴趣度受多种因素的影响,首先是规则的客观兴趣度,在基于关联规则寻找关联图书的前提下,给定一本书作为规则前提,将会得到很多个结果,每个结果都是一本与之关联的图书(这里的规则前提和结果都是单项的),要寻找哪一本图书与给定图书最合适,最基本应该考虑规则的支持度和置信度,支持度越大说明该图书与给定图书关联的次数越多,置信度越大说明该图书与给定图书组合在一起的可信度越大。置信度没有考虑P(Y)因素的影响,文献[11]提到了包括支持度和置信度在内的21种衡量规则兴趣度的方法,在衡量组合兴趣度时选用支持度、置信度和Jaccard三种,Jaccard衡量的兴趣度JI定义如下:
JI=P(X⋃Y)P(X)+P(Y)-P(X⋃Y) (3)
其中:JI∈[0,1]。
JI与相关系数ρxy近似线性相关,JI越大表示X与Y越相关,图书X与图书Y组合的兴趣度也就越大。
(2)吸引度
在网上书店中,图书组合的目的是为了刺激用户在购买一本书后再购买与之组合的图书,考虑图书组合还需要考虑用户对组合的主观态度,即组合对用户的吸引度(Attraction)。不同的用户看到组合有不同的感受,有的用户会认为组合中的两本书是配套图书,用户本身也打算购买组合中的另一本书,现在如果出现在组合中,则用户肯定会够买该组合图书,当用户做出购买图书组合的行动时,组合对用户吸引度是最高的。有的用户看到组合可能有一点吸引,但由于已经购买了一本或者由于价格等因素最终没有购买组合,只购买了原来那一本。有的用户可能认为组合中的图书价格、图书的关联程度都一般。有的用户可能认为组合中的图书价格高、图书不太相关,因此不太情愿购买组合。有的用户可能很不情愿购买,这时候组合对用户的吸引度是最低的。根据五点量表的做法,将吸引度划分为5个等级:
①做出购买组合的行动,
②有购买意愿但最终没有购买,
③对组合的吸引度感觉一般,
④不太情愿购买组合,
⑤很不情愿购买组合。
在数字图书馆中,图书组合的目的是给用户提供借书参考,吸引用户借阅相关图书。吸引度同样可以划分为5个等级:
①做出借阅组合图书的行动,
②有借阅意愿但最终没有借,
③对组合的吸引度感觉一般,
④不太情愿借阅组合,
⑤很不情愿借阅该组合。
用户对组合的主观态度从网页上获取,从第1等级到第5等级打分,依次是5分、4分、3分、2分、1分,设Si为第i等级的分数,Ci为统计打分属于第i等级的人数,则吸引度attraction定义为:
attraction=∑i=15SiCi∑i=15Ci (4)
(3)收益
Cabena等指出,关联规则的缺点是没有考虑关联规则的商业价值[ 12],从微观经济学的角度来考虑图书组合,该组合必须是使网上书店收益最大化的组合,在这里把收益因素作为衡量组合兴趣度的一个指标。对于网上书店而言,收益即为利润,黄嘉满[ 13]提出了计算频繁集利润的方法,在此对该计算方法进行简化,为计算图书X和Yi组合后带来的利润,设图书X的进货价为p、销售价为sp,设图书Yi的进货价为pi、销售价为spi,规则X→Yi的支持度计数为SCi,规则X→Yi或者图书组合{X,Yi}的收益profit为:
profit=(sp-p+spi-pi)×SCi sp-p+spi-pi>00 其他 (5)
对于数字图书馆而言,收益即为资源的性价比,图书馆的资源要达到最大的性价比,实现资源的最大化利用,规则X→Yi的收益profit定义为:
profit=SCip+pi (6)
(4)模型的确定
组合兴趣度CI的前三个指标可以进行综合,得到组合强度的客观度量OM。
OM=k1×s+k2×c+k3×JI (7)
其中:ki≥0 (i=1,2,3),∑i=13ki=1。
结合客观度量OM、吸引度attraction、收益profit,在关联规则综合评价模型的基础上,将组合兴趣度CI的计算公式定义为:
CI=OMw1×attractionw2×profitw3 (8)
其中:wi≥0 (i=1,2,3),∑i=13wi=1。
将OM代入式(8)可以得到:
CI=(k1×s+k2×c+k3×JI)w1×attractionw2×profitw3 (9)
其中:ki≥0 (i=1,2,3),∑i=13ki=1;wi≥0 (i=1,2,3),∑i=13wi=1。
模型的确定主要采用多指标综合评价、关联规则综合评价的思想,从支持度、置信度和Jaccard兴趣度的表达式上看三者之间是独立的,三者采用加权平均产生客观度量OM,从而实现互补,例如某些规则的支持度很低但置信度却可能很高;三者的取值范围均为[0,1],因此适合采用加权平均来反映客观事实。从直观上看客观度量与吸引度、收益存在着内在的相关性,例如当用户选择购买组合的时候,对组合的打分即为5分,而这一购买组合的事件也已经更新了交易数据库,客观度量也会受到影响;收益是通过组合的支持度计数乘以其他的一些变量计算出来的,因此利润与客观度量也存在着内在的相关性,适合采用非线性加权的形式,这里对客观度量、吸引度和收益采用几何加权平均,对吸引度和收益值不需要进行无量纲化操作,消除了无量纲化操作对客观事实可能造成的影响。
3.2 模型中指标权值的确定
对于支持度、置信度和Jaccard兴趣度三个指标的权值采用主观赋权的方法确定权重,对于图书组合而言,置信度和Jaccard兴趣度比支持度更为重要,因此将支持度权值赋为0.2,置信度权值赋为0.4,Jaccard兴趣度的权值赋为0.4。
对于客观度量、吸引度和收益三个指标采用客观赋权与主观赋权相结合的方法来确定权值,采用熵权法[ 14]来确定OM、attraction以及profit的客观权值。下面以网上书店为例计算各项指标的权重。
(1)计算OM、attraction以及profit的客观权值
笔者根据自己在网上书店的购书记录以及同学的购书记录,再结合软件随机生成部分记录,得到图书交易事务数据,如表2所示:
| 表2 事务数据库 |
假设给定图书A,寻找A的组合图书。设置较低的支持度和置信度,使用关联规则挖掘算法得到前件和后件均为单项的强规则,保留前件为图书A的所有正相关强规则。由于吸引度需要由用户在网页上的输入来获取,这里采用伪随机数序列来代替用户的输入,伪随机数发生器随机产生1,2,3,4,5作为用户对图书组合的打分,设定对一个图书组合进行6次打分,求得分数的平均值作为图书组合的吸引度。
对得到的正相关强规则计算吸引度及收益,再结合客观度量得到信息矩阵,将信息矩阵中的数据进行标准化和归一化,如表3所示:
| 表3 归一化操作后的结果汇总表 |
使用熵权法计算客观度量、吸引度和收益的指标权重,得到结果如表4所示:
| 表4 指标的客观权重 |
通过取多组随机数计算吸引度的值,发现吸引度的熵值均比客观度量和收益的熵值要大,说明吸引度的不确定性较大。
(2)计算OM、attraction以及profit的主观权值
这里采用相对比较法[ 14]来计算OM、attraction以及profit的主观权值。图书组合的吸引度是最重要的,在网上书店中,只有对用户有吸引力的图书组合用户才会去购买,从而增加销售额,最终提高书店的整体收益;其次重要的是收益,当用户在浏览一本图书时,店家总倾向于选择与之组合后带来的收益最大的图书作为该图书的组合图书;最后是客观度量。根据相对比较法,OM、attraction以及profit三个指标评分构成的矩阵A=(aij)m×n如下:
A=0.50010.51100.5
由公式wi=∑j=13aij∑i=13∑j=13aij (i=1,2,3),得到客观度量、吸引度和收益三个指标的主观权重,将对应指标的客观权重与主观权重求平均值,得到综合权值,将综合权重四舍五入保留小数点后4位,代入式(9)得到组合兴趣度的数学表达式为:
CI=(0.2×s+0.4×c+0.4×JI)0.2304×attraction0.4135
×profit0.3561(10)
3.3 算法研究
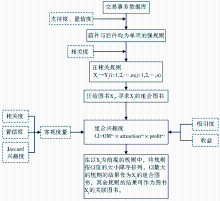
图1给出了图书推荐模型在产生图书组合中应用的全过程。
 | 图1 产生所有图书组合的全过程 |
在Apriori算法以及图1的基础上,设计基于图书推荐模型产生图书组合的算法。算法分两步进行,第一步的伪代码如下所示:
输入:交易数据库D;最小支持度阈值minsup;最小置信度阈值minconf。
输出:所有符合条件的关联规则及规则的属性值。
方法:
L1=find_frequent_1_itemset (D);/*找出频繁1-项集*/
C2=apriori_gen(L1, minsup) /*连接和剪枝。产生候选2项集*/
L2={ c (C2 | Sup(c) > minsup} /*由C2生成L2*/
for each l∈L2
for each b∈l
cb=l-b;
s=Sup(l); /*计算l的支持度*/
c= Conf(b→cb); /*计算规则的置信度*/
if(c>minconf)
if(CorrR(b→cb)>1) /*相关度大于1为正相关规则*/
{
JI=CountJaccard(b→cb); /*计算Jaccard兴趣度*/
attraction=CountAttraction(b→cb); /*计算吸引度*/
profit=CountProfit(b→cb); /*计算图书b和cb组合在一起的收益*/
CI=CountCI(s,c,JI,attraction,profit); /*计算组合兴趣度*/
Save(b→cb,s, c,JI,attraction,profit,CI); /*将规则以及规则的属性值存入数据库*/
}
end
end
第二步的伪代码如下所示:
输入:图书X。
输出:X的组合图书Y。
方法:
List=FindAR(X); /*找出规则前件为图书X的所有规则*/
Y=MaxCI(List); /*从规则列表中找出CI值最大的规则的结果作为X的组合图书*/
4 模型验证
下面给出模型在网上书店中应用的验证,笔者使用J2EE技术开发了一个网上书店系统,并实现了以上所述的模型。当用户购买图书进行多次交易后,管理员可进行关联规则挖掘,通过图书组合模型求得每本图书与其关联图书的组合兴趣度,如图2所示:
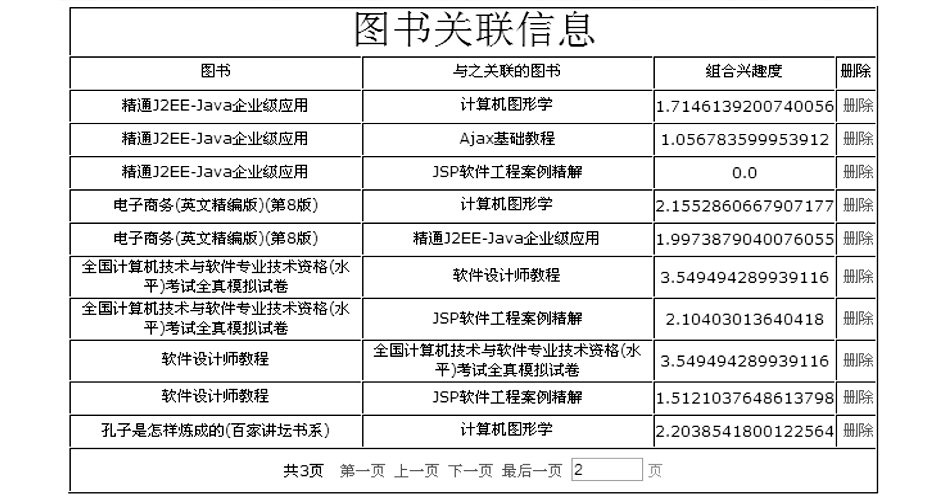 | 图2 图书关联信息页面 |
对图书《全国计算机技术与软件专业技术资格(水平)考试全真模拟试卷》而言,与《软件设计师教程》组合的兴趣度高于《JSP软件工程案例精解》,系统选择《软件设计师教程》作为《全国计算机技术与软件专业技术资格(水平)考试全真模拟试卷》的组合图书,这合乎人们的购书习惯,因为两者是配套图书,用户购书时会同时购买。当用户浏览或购买《孔子是怎样炼成的(百家讲坛书系)》时,发现该图书的组合图书《计算机图形学》并不是他感兴趣的,当他点击其他链接离开该页面时,系统将弹出窗体,如图3所示,一方面请用户为该组合打分,另一方面也起到挽留用户购买组合图书的作用。当用户选择“很不想买”,用户打分后系统会重新计算各图书组合的组合兴趣度CI值,当用户重新浏览《孔子是怎样炼成的(百家讲坛书系)》时,它的组合图书变成了《我在回忆里等你》。
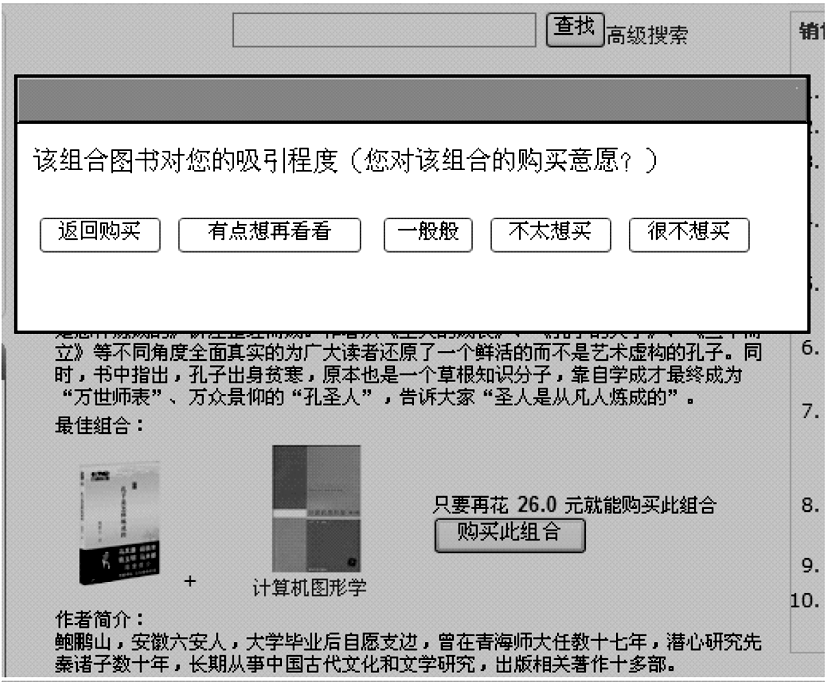 | 图3 组合图书评分窗体 |
《孔子是怎样炼成的(百家讲坛书系)》与《我在回忆里等你》组合更加合理,通过用户打分从组合对用户的吸引度方面衡量了图书组合。通过操作可以看出图书组合模型能够很好地为用户寻找出组合图书,系统的应用验证了图书推荐模型的合理性与有效性。
5 结 语
本文提出了一个基于关联规则综合评价的图书推荐模型,该模型面向网上书店和数字图书馆。模型中综合运用了关联规则综合评价以及多指标综合评价的思想,本文中指标权值的确定过程具有一定的方法论意义。在建立图书推荐模型的过程中,由于无法获取到实际平台(如卓越、当当等)批量的购书交易记录,小样本数据的偏差可能会影响到模型中指标权值的确定。进一步的研究和实践将围绕以下两个方面展开:
(1) 进一步完善图书推荐模型,对模型中指标和权值进行深层次的探讨,尝试与Web日志挖掘结合起来进行研究。
(2) 进一步在实践中探讨关联规则算法,解决算法计算量大的问题。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|