{kind=link}
{kind=link}
{kind=link}
基于查询意图聚类的实时搜索建议*
引用本文
周之诚. 基于查询意图聚类的实时搜索建议* . 现代图书情报技术, 2011, 27(2): 87-93
Zhou Zhicheng. Real-Time Search Suggestions Based on the Clustering of the User’s Query Intent. 现代图书情报技术, 2011, 27(2): 87-93
Permissions
Zhou Zhicheng. Real-Time Search Suggestions Based on the Clustering of the User’s Query Intent. 现代图书情报技术, 2011, 27(2): 87-93
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于查询意图聚类的实时搜索建议*
摘要
对于搜索引擎返回的结果太多且较少考虑用户个性差异等缺陷,提出根据用户查询意图,实时给予多个主题的搜索建议,帮助用户更准确地描述所需信息,修正查询词与真实意图之间的差距,提高检索效率。同时运用K-means算法,对资源类别的意图特征值相似用户进行聚类,缩小查找目标对象最近邻居的范围,提高搜索建议的实时响应速度。实验结果表明,该方法是可行的。
关键词:
聚类; 搜索建议; 查询意图; 搜索引擎
中图分类号:G354
Real-Time Search Suggestions Based on the Clustering of the User’s Query Intent
Abstract
Aimed at the defects that the search engine offers too many results and is lack of considering the differences between the user’s personalities, this paper offers a way to give users real-time search suggestions of multi theme according to the user’s search intent in order to help the users describe the information in need more accurately, as well as narrow the gap between the query word and the user’s real intentions to increase the search efficiency. At the same time, it uses K-means to cluster users who are similar in their intent eigenvalue of resources categories, narrow the range of the nearest neighbor of the searching target, as well as to speed up the real-time response of the search suggestions. The experiment result shows that this method is practical.
Keyword:
Clustering; Search suggestions; Query intent; Search engine
1 引 言
随着信息资源几何级的增长,人们通过搜索引擎获取目标信息与排除信息噪音的成本也快速上升。搜寻成本提高的主要原因是在检索信息时使用关键字的匹配方法。搜索引擎对于查询返回结果的差异依赖于用户输入的查询词,相同查询词返回相同的结果,不能真正感知用户的检索意图。实际上,用户信息需求存在一定的个性差异。对于一个词,不同学科、不同专业背景的用户会有不同的查询意图。比如检索词“间硝基甲苯”(CH3C6H4NO2),对于精细化工、有机化工、农药应用、技术经济、市场营销等不同专业背景的用户,查询的侧重点有较大的区别。此外,用户在检索策略和技巧上存在不足,不能精确表达自身需求,检索系统又缺乏与读者建立良好的交互渠道,以致搜索引擎无法满足用户需求,只有返回大量的查询结果供用户选择。
本文提出基于用户意图聚类的实时搜索建议,目的是在用户提交查询请求前,尝试理解其可能的查询意图,实时给予用户多个主题的搜索提示,用于修复查询词和用户真实意图之间的差距,引导用户修改和调整查询的方向与手段,更加准确地对信息需求进行概括,提高检索速度与准确性。同时运用K-means算法,对资源类别的意图特征值相似用户进行聚类,缩小查找目标对象最近邻居的范围,提高搜索建议的实时响应速度。实验结果表明,本文提出的方法实时效果较好,并可以有效提高检索效率。
2 相关研究概况
检索过程中的查询意图是用户输入查询条件进行搜索并关注其中某些结果的行为。这些行为本身记录着用户最真实的信息需求倾向,揭示了人们内心潜藏的意图,也就是用户想要获得怎样的信息[ 1]。
查询意图可以通过一些能反映用户兴趣特征的评分数据表示。数据获取并不困难,难点在于意图的量化方式。一些学者在研究中利用用户浏览行为计算用户隐性兴趣度[ 2]或者根据用户在页面停留时间和访问次数等特征,提出兴趣强度及度量方法[ 3],但这些方法仅揭示了用户兴趣的一部分,不能完全表示用户的查询意图,同时计算中也忽略了兴趣偏好随时间变化的特性。本文试图从用户查询行为中挖掘其潜藏的意图,并根据已评分数字资源对资源类别的隶属度,以及兴趣的时间权重,提出意图特征值的概念,目的是为了更好地描述用户的查询意图。
基于用户行为的信息检索近年来受到了广泛关注,国内外学者也对其进行了大量的研究和实验。如文献[4]提出一种查询请求聚类方法,通过分析、挖掘用户的检索行为,将搜索结果按兴趣特征聚类后返回给用户,从而减少了大量不相关的匹配,提高检索速度;文献[5]采用搜索结果价值评定方法,提出首先由用户对检索结果的相关性进行判别、评分,系统再根据这些用户反馈的信息,生成新的查询,提高最终结果的准确性;文献[6]通过对用户浏览行为、服务器日志等数据分析处理,建立一种用户兴趣模型,并在检索中计算其与结果文档的相关性,再返回根据相关性排序的搜索结果。目前对于查询意图在信息检索领域中应用的研究还相对较少,本文在总结前人相关成果的基础上,提出对相似查询意图的用户进行聚类,在用户信息检索时,通过相似性计算,实时为其提供多个主题的搜索建议,帮助用户更准确地描述所需信息,改善检索效果。
K-means算法以较快的聚类速度、较好的可伸缩性而被广泛采用,但其效果依赖于初始聚类中心k的取值。文献[7]在使用K-means 算法对评分数据集进行用户聚类时,以访问量最多的用户数作为初始k个聚类中心,经过实验验证效果较好;文献[8]通过对最小最大选取原则的改进,采用样本个数的平方根作为初始k个聚类中心,达到改善聚类效果的目的。本文参照文献[7]中k的取值方法,以评分(有效数据)最多的k个用户作为初始k个聚类中心,来消除孤立点对聚类结果产生的负面影响。
3 查询意图聚类的实时搜索建议实现
3.1 实时搜索建议的工作流程
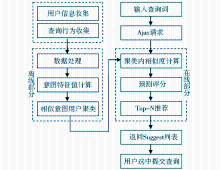
基于用户查询意图聚类的实时搜索建议可以用图1表示,对于图中涉及Web2.0的Ajax技术及其框架[ 9],本文不作讨论。
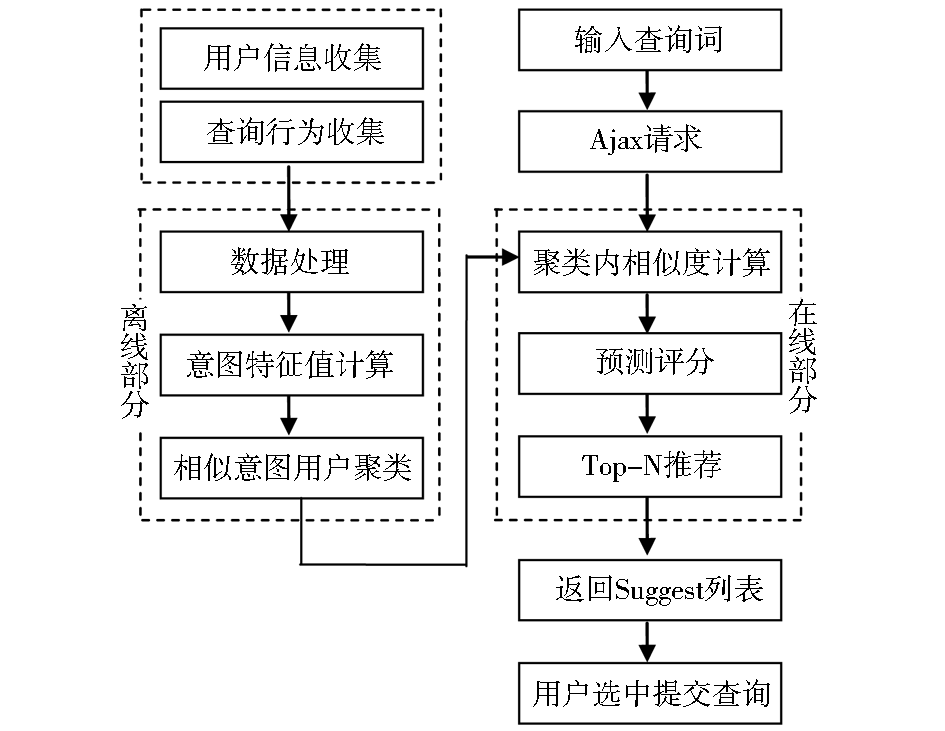 | 图1 基于查询意图聚类的实时搜索建议流程 |
系统采用隐式跟踪方法,通过收集访问者的查询行为并测量其对数字资源类别的意图特征值,获取用户查询意图所在。结合用户专业背景,利用K-means算法对相似查询意图的用户聚类。当用户输入查询词时,通过相似度计算在目标用户所属聚类内搜索其最近邻居集,并从最近邻居评价信息中预测目标用户对未评分数字资源类别的兴趣程度,选择评分最高的前N个类别,实时显示在搜索框下方的“Suggest”列表中,供用户选择最匹配的查询主题后提交。
类别按主题内容标引。如果数字资源有两个以上的主题内容,可先对其中一个主题进行标引,再对另一个标引,以此类推。一个类别最多不超过3个主题词。比如期刊数据库中“零价铁还原土壤中邻硝基甲苯的实验研究”的类别为{环境化学,还原},“毛细管柱气相色谱法测定水中12种硝基苯类化合物” 的类别为{分析化学,环境化学,硝基苯类化合物}。
3.2 用户查询意图获取与表示方法
实时搜索建议的目标是降低搜索引擎的信息过载,使用户快速、准确定位自己所需内容的主题,缩小检索范围,因此取得用户查询意图是最终满足该目标至关重要的前提。在系统中,用户意图通过一些能反映其兴趣特征的评分数据表示。由于反馈评价需要较多的人力与时间,且大部分用户并不愿意主动提供评分信息,因此难以大规模展开。而用户查询行为蕴含了其对结果的相关性评价,因此本文根据图书馆数字资源特点采用隐式评分[ 10, 11]。
服务器端日志文件数据量庞大且存在大量冗余数据、噪声信息,无法精确展示访问者在网上的实际行为,因此通过日志方法来追踪、分析用户的查询行为,难度较大,操作也比较繁琐。目前校园网普遍采用上网认证客户端,并且为了延伸服务空间,拓展馆藏资源利用率,大部分高校都建立了数字图书馆远程接入系统,使客户端数据技术有了应用基础。本文通过客户端收集用户的行为特征,解决了以往数据分析中用户识别方法的缺陷以及用户查询行为收集不便等问题。
数据分析中最能反映用户意图的行为有两类:
(1)用户对页面或文档的浏览时间,时间越长表示用户对该文档的关注度越高;
(2)用户复制、保存、下载、打印等操作行为,这类行为往往代表用户对该数字资源内容具有很高的兴趣度。
系统在跟踪用户过程中,首先赋予身份识别,记录其与服务器交互产生的请求,通过数据分析给予用户行为一个评分值,用于计算其兴趣偏好程度。
每个查询都具有可以被预测的类别,而数字资源类别在一定程度上可以反映用户的意图[ 12]。如果用户对一些资源给予了高低不等的评分(隐式评分),则可以根据这些已评分的数字资源对资源类别的隶属度,计算得到用户对不同资源类别的意图特征值来衡量其对某类资源的偏好程度。由于用户兴趣偏好具有随时间变化的特性,因此在对意图特征值的计算中加入了时间权重。
设DL是一个数字图书馆,C=C1,C2…,Cn为DL中所有数字资源类别的集合,∀cj∈C,用cj=cj1,cj2…,cjm表示j类别数字资源中所有资源的集合,则用户u对j类别资源的意图特征值Cu,j为:
Cu,j=∑i∈IuIu,i×γjxi∑i∈Iuγjxi×e-t i=1,2,…,n (1)
其中:Iu,i代表用户u对资源i的评分值;Iu代表用户u已评价的数字资源;γjxi代表资源i对类别j的隶属度;t代表行为特征发生时间与当前时间差值。
由式(1)计算形成一个用户-数字资源类别矩阵C如下:
C=Cu,jm×n u=1,2…,n;j=1,2…,m
其中,m是用户数,n是资源类别数。
对不同资源类别的意图特征值测量是为了获取用户意图所在,也是用户提交查询请求前,系统有针对性地给予其动态搜索建议的基础。
3.3 相似度函数
采用Pearson相关系数方法[ 13]对用户意图特征值进行比较,获得用户间的相似度评价值。
设Ii、Ij分别表示用户i与用户j已评分的数字资源类别集合,评分值通过式(1)计算得到。Ii,j表示用户i与用户j有相同评分的资源类别集合,Ii,j=Ii∩Ij,则用户i和用户j之间的相似性simi,j如下:
simi,j=∑c∈Ii,jRi,c-R-iRj,c-R-j∑c∈Ii,jRi,c-R-i2∑c∈Ii,jRj,c-R-j2 (2)
R-i=∑c∈Ii,jRi,ck (3)
R-j=∑c∈Ii,jRj,ck (4)
其中:c属于Ii与Ij的交集,Ri,c、Rj,c分别表示用户i和j对数字资源类别c的评分;R-i和R-j由式(3)、式(4)计算得到,分别表示Ii,j中用户i和用户j的评分均值;k是Ii,j中元素的个数。
3.4 用户查询意图聚类
实时搜索建议关键在于其提示内容是否具有针对性。当目标用户输入查询词时,搜索引擎感知其查询意图的方法是通过相似系数的计算找到与他兴趣相似的用户,然后将这些用户感兴趣的内容通过搜索建议方式,动态推荐给目标用户,供其选择提交。在这一过程中,如果对全部数据集进行相似性计算,开销极大,且识别最近邻居算法的计算量也随着项目(图书馆数字资源)的增加成线性加大,计算复杂度最终成为系统性能的瓶颈,直接影响搜索建议的实时性。
基于查询意图聚类的算法提出一种解决方案。在整个用户空间,通过意图特征值相似性比较,把用户聚类为若干个不同数据对象集合[ 14]。由于聚类可以离线进行,且查找目标对象最近邻居的范围缩小到与目标对象相似性程度最高的几个聚类,因此降低了实时计算压力,提高了搜索建议的动态响应速度。在相似性比较中,表示用户查询意图的意图特征值之间产生的相似交集远大于已评分的数字资源间产生的交集,解决了相同偏好特征用户可能有不相似的表面评分问题,保证搜索建议的准确度。
聚类采用K-means算法。本文参照文献[7]中k的取值方法,以评分(有效数据)最多的k个用户作为初始k个聚类中心,来消除孤立点对聚类结果产生的负面影响。
设数据集是由n个数据对象组成。k是K-means算法的输人参数,k≤n且每个聚类至少包含一个对象,每个对象属于且仅属于一个聚类。算法主要步骤描述如下:
输入:聚类数目k以及由式(1)计算形成的用户-数字资源类别矩阵C=Cu,jm×n
输出:k个意图特征值相似的用户聚类
主要步骤:
(1)从用户意图特征值数据库中检索所有n个数字资源类别,记为集合I=i1,i2,…,in;以及检索所有m个用户,记为集合U=u1,u2,…,um;
(2)从m个用户中选择评分最多的k个用户作为种子节点,将k个用户对资源类别的意图特征值数据作为初始聚类中心,记为集合CC=cc1,cc2,…,cck;将k个聚类初始化为空,记为集合C=c1,c2,…,ck;
(3)对剩余用户ui∈U,由式(2)计算其与k个聚类中心ccj∈CC的相似性simui,ccj;
(4)将每个用户分配到相似性最高的聚类中,simui,ccj=maxsimui,cc1,…,simui,cck,聚类cm=cm∪ui,且cm∈C;
(5)聚类生成后,计算类中对象的平均值,作为新的初始聚类中心;
(6)重复步骤(3)至步骤(5),直到聚类结果基本不发生变化、准则函数收敛。准则函数采用平方误差准则,公式如下:
E=∑i=1k∑p∈cip-mi2 (5)
其中:E是所有对象的平方误差总和,p表示给定的数据对象,mi是聚类ci的重心(平均值)。
3.5 实时搜索建议的产生
实时搜索建议产生是在聚类结果的基础上,由式(2)计算得到最近邻居集合,完成从最近邻居评价信息中获得目标用户对未评分数字资源类别的兴趣程度预测。
设最近邻居查询个数为n,目标用户u的最近邻居集合Mi=m1,m2,…,mn,其相似度{sim(u,m1),sim(u,m2),…,sim(u,mn)}按从大到小的顺序排列。用户m∈Mi。用户u对数字资源类别i的预测评分Pu,i可以通过计算得到,公式如下[ 15]:
Pu,i=R-u+∑m∈MiRm,i-R-m×simu,m∑m∈Misimu,m (6)
其中:R-u、R-m分别为用户u与m对数字资源类别的平均评分,Rm,i为用户m对数字资源类别i的评分, 评分值由式(1)计算得到;simu,m为用户u和m的相似度,由式(2)计算得到。
目标用户u完成对所有未评分数字资源类别的兴趣程度预测后,选择预测评分最高的前N个类别(Top-N)[ 16],实时给予用户搜索建议,供其选择最匹配的查询主题后提交。
4 实验结果及分析
4.1 实验环境及数据集
实验在CPU为Intel Core2 Duo E8200、主频为2.66GHz、内存为2GB DDR2 800的机器上运行,在Microsoft Windows XP Professional+MyEclipse平台上使用Java语言开发。
实验数据来自Minnesota大学GroupLens项目组开发并公布的三个MovieLens数据集中的“100k Ratings Data Set”[ 17]。该数据集包含了943位用户对1 682部影片的100 000条评分数据,评分采用5分制且每个用户至少对20部影片进行了评分,其中评分数值越大,表明用户对该电影的偏爱程度越高。
本文对19个大类的全部影片,根据MovieLens数据集提供的u.item中的影片描述信息,按主题内容标引为219个类别。比如把Movie ID为802的影片《Hard Target》标引为{Action,Crime,Thriller};把Movie ID为1065的影片《Koyaanisqatsi》标引为{Documentary,History,War}。219个类别分别用0到218表示。
4.2 搜索建议的实时性及精度对比实验
实验选取MovieLens数据集提供的u.data中的全部原始评分数据。为了有效降低数据集对实验结果的影响,实验采用5折交叉验证法。将实验数据集平均分成5个互不相交的子集,每份数据子集包含20%的评分数据。每次实验选择其中一个数据子集作为测试集,其余4个合为一个训练集(包含80%的评分数据),把训练集中的记录作为基本用户,对测试集中的目标用户进行推荐测试,循环5次,取5组实验数据的平均值作为最终结果。
(1)搜索建议的实时性实验
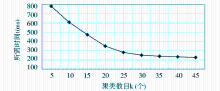
以不同的聚类数目k,完成给予目标用户N个主题的搜索提示所耗费的时间来衡量搜索建议的实时性效果。聚类离线计算,k值以评分量最多的45个用户作为取值范围,从5增加到45,间隔为5。采用Top-5(实时给予5个主题的搜索提示),最近邻居查询个数为15。实验结果如图2所示:
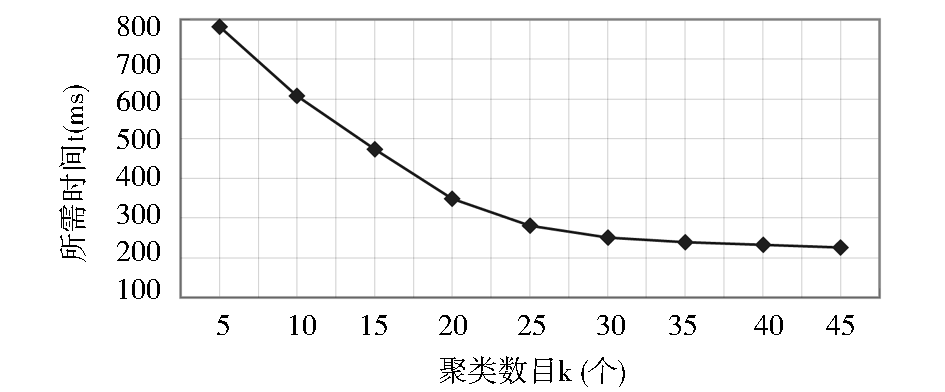 | 图2 实时搜索建议所需时间 |
图2中,实时搜索建议所需时间随聚类数目增大而减少。当聚类数目k大于25时,完成搜索建议所需时间t小于300ms,实时性效果较好。
(2)搜索建议精度对比实验
通过与传统协同过滤算法对照实验,来验证基于查询意图聚类的实时搜索建议效果。评价指标采用平均绝对偏差MAE方法。
设预测的用户评分集合表示为p1,p2,…,pn,对应的实际用户评分集合为q1,q2,…,qn,则平均绝对偏差MAE为:
MAE=∑i=1Npi-qiN (7)
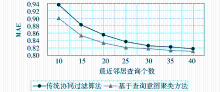
实验中,初始聚类数目k值取30,目标用户的最近邻居个数从10增加到40,间隔为5,分别计算本文提出的方法与传统的协同过滤算法的MAE。对照实验均采用式(2)计算相似性,式(6)预测用户评分,式(7)作为评价指标。实验结果如图3所示:
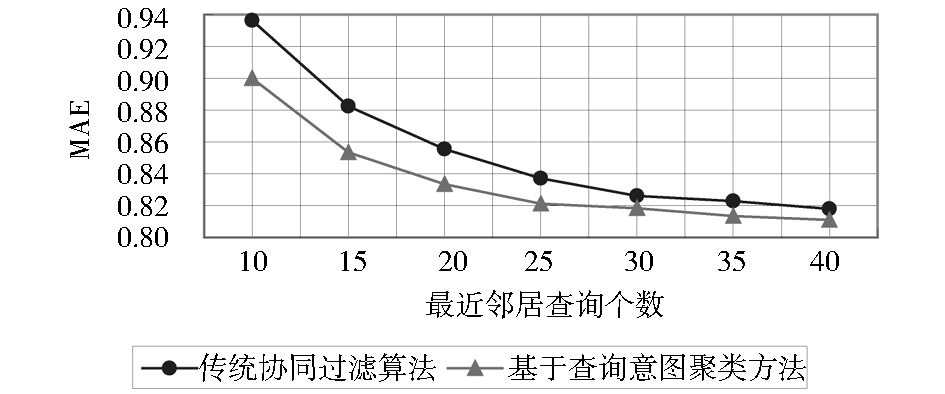 | 图3 基于查询意图聚类与传统协同过滤算法的实验结果对比 |
从图3可以看出,当最近邻居查询个数小于30时,基于查询意图聚类方法的评分预测偏差明显小于传统协同过滤算法。当最近邻居查询个数超过30时,二者的MAE值开始接近,但基于查询意图聚类的预测评分与实际用户评分之间的偏差还是小于传统协同过滤。
实验结果表明,基于查询意图聚类的实时搜索建议比传统协同过滤算法具有较小的MAE值,推荐精度也有所改善。
4.3 检索性能对比实验
通过用户u在传统向量空间模型(TF-IDF算法)与本文方法中查询Qu,i的比较,验证基于查询意图聚类的实时搜索建议的检索性能。评测指标采用平均查全率与平均查准率,计算公式如下:
Ru,q(i)=∑i=1nq(Qu,i)ni×100% i=1,2,…,m (8)
pu,q(i)=∑i=1nq(Qu,i)Ni×100% i=1,2,…,m (9)
其中:Qu为仅属于用户u使用的查询词集合,Qu=Qu,1,Qu,2…,Qu,m,∀Qu,i∈Qu;Ru,q(i)、Pu,q(i)分别为用户u查询Qu,i的平均查全率与查准率;N、n分别为查询Qu,i检索出的文献(影片)总量和用户u的实际评分集合中的相关影片总量;nq(Qu,i)为N与n的交集;i为被分别检索的查询词个数。
检索性能由检出相关信息的能力与信息准确度来衡量。但目前在评估算法性能的实验中,被检索出的相关信息量和系统中的相关信息总量并不来自于用户认为最符合其查询意向的文档,而是根据查询结果、查询词与测试集中文档的相关性匹配,是基于一种信息相关程度的“假设”且存在各种主观因素的影响,没有考虑用户信息需求存在的个性差异,因此不能保证评价数据的真实性。本文采用与查询用户实际评分集的文档匹配方法,获取最符合用户查询意图的文档数。
实验以u.item作为测试集。同时对u.data进行处理,去除其中评分小于3的44 625条数据,保证数据能反映用户真实的兴趣。之后,在余留的55 375条数据中按用户分类,组成943个评分集,并抽取评分量最多且评分对象差别较大的10位用户进行查询测试,用户信息描述如表1所示:
| 表1 查询测试用户信息 |
在测试集u.item中,根据用户所属评分集中的评分影片类别描述,提取查询词并组成仅属于该用户的查询集Qu,查询采用短查询式。实验中只对前50个查询结果进行统计,其余忽略。i取值为10,即在每个用户的查询集Qu中随机抽取10个查询词用于查询测试。
在使用本文方法进行查询测试时,初始聚类数目k值取30,最近邻居查询个数为15。采用Top-5(给予目标用户5个主题的搜索提示),并取其中查全率最高的一个搜索提示作为该用户的查询,与传统向量空间模型对比。实验结果如表2所示。
从表2可以看出,与传统向量空间模型相比,使用本文方法查询Qu,i的查全率平均提高14.70%,查准率平均提高27.55%。实验结果表明,基于查询意图聚类的实时搜索建议能够较好地提高检索性能。
| 表2 检索性能对比实验结果 |
值得注意的是实验中不管采用哪种查询方法,得到的查准率都相对较低,原因在于n为用户u评分集合中的相关影片数量,其值远小于整个数据集中所有相关影片的总量,以至于N与n的交集nq(Qu,i)变小,造成式(9)查准率较低的假象。此外,User9的查全率与查准率分别接近、小于传统向量空间模型,通过分析此用户评分集后,发现是由于其兴趣频繁改变所致,个别现象并不影响实时搜索建议的整体检索性能。
5 结 语
对于现有搜索引擎存在的缺陷,提出一种基于用户意图聚类的实时搜索建议方法,帮助用户更准确地描述信息,提高检索的效率。同时通过对意图特征值相似性比较,把用户聚类为若干个不同数据对象集合,缩小查找目标对象的最近邻居范围,有效提高搜索建议的实时响应速度。实验结果表明,该方法实时效果较好,并可以有效提高检索效率。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|