{kind=link}
大众标注系统中基于本体的语义检索研究综述*
引用本文
何继媛, 窦永香, 刘东苏. 大众标注系统中基于本体的语义检索研究综述* . 现代图书情报技术, 2011, 27(3): 51-56
He Jiyuan, Dou Yongxiang, Liu Dongsu. Survey of Ontology-based Semantic Retrieval in Folksonomy. 现代图书情报技术, 2011, 27(3): 51-56
Permissions
He Jiyuan, Dou Yongxiang, Liu Dongsu. Survey of Ontology-based Semantic Retrieval in Folksonomy. 现代图书情报技术, 2011, 27(3): 51-56
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
大众标注系统中基于本体的语义检索研究综述*
摘要
针对大众标注系统中由于用户添加标签的多样性和模糊性导致的检索准确性问题,建立基于本体的大众标注系统语义检索模型,分析需要解决的关键问题,如基于社会化标签建立系统专用的本体和利用构建的本体实现语义检索,据此详细分类并阐述当前研究,并对未来研究进行展望。
关键词:
大众标注; 本体; 语义检索
中图分类号:G354
Survey of Ontology-based Semantic Retrieval in Folksonomy
Abstract
For retrieval accuracy problems is due to the diversity and ambiguity of the tags created by users in Folksonomy system,this paper builds a model of Ontology-based Folksonomy semantic retrieval, and analyzes the key problems,such as building Ontology based on Folksonomy and using Ontology-built to implement semantic retrieval.Then current researches are classified and introduced in detail, and finally it makes a prospect for research trends.
Keyword:
Folksonomy; Ontology; Semantic retrieval
1 引 言
现有的大众标注系统中,由于标签的多样性(对于同一个概念,不同的用户会有不同的表达方式,就会添加不同的标签)和模糊性(一个标签可能表示不同的含义)[ 1],用户自由添加的标签不能满足其他用户的检索需求,而且由于标签缺乏明确的语义,更不利于用户准确、高效地获取所需要的资源。因此,将本体引入大众标注系统,利用本体提供的明确语义实现大众标注系统的语义检索成为国内外学者关注的研究热点。
本文构建了基于本体的大众标注系统语义检索模型,通过对国内外文献的深入分析,总结了基于社会化标签建立系统专用本体的方法,以及利用构建的本体实现大众标注系统中资源的语义检索的相关研究——前者主要涉及分析标注行为获得标签本体、推理标签关系提取本体、与已知本体映射形成本体等方法;后者主要涉及利用本体实现资源标注时的标签推荐、提问处理时的语义扩展等研究内容。
2 大众标注系统中基于本体的检索模型
在大众标注系统中,用户对资源添加标签,系统通过标签与本体的映射进行标签推荐,扩充标签的语义;检索时,用户输入关键字,系统通过与本体映射进行关键字的语义扩展;资源检索模块处理关键字与资源的语义推理匹配,实现语义检索;最后将检索结果返回给用户,如图1所示:
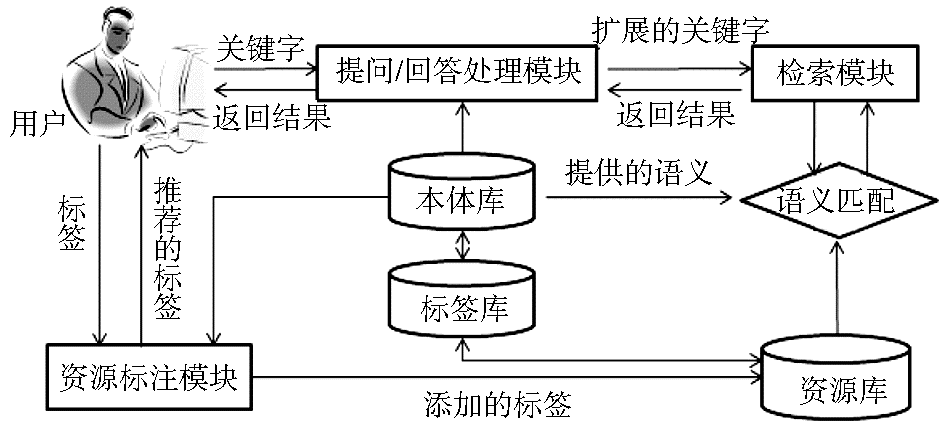 | 图1 基于本体的大众标注系统检索模型 |
各模块的功能如下:
(1)资源标注模块:管理用户对资源的标注。用户分享资源后,对资源添加标签,利用本体提供的语义获得相关标签,将标签推荐给用户,供用户选择。
(2)提问/回答处理模块:对用户的提问进行处理。用户输入关键字后,对关键字进行处理,例如检查拼写错误等;根据本体提供的语义对关键字的语义扩展,例如增加相关的关键字等;将检索结果返回给用户,包括结果的排序及用户的相关反馈处理等。
(3)检索模块:利用语义扩展后的关键字检索资源。通过本体提供的语义将关键字与资源进行语义推理匹配,实现语义检索。
在大众标注系统中引入本体实现资源的语义检索需要解决的关键问题有:建立基于社会化标签的本体,实现大众标注系统中标签与本体的关联;利用构建的本体实现资源标注模块的标签推荐;利用本体实现提问处理模块关键字的语义扩展;利用本体实现检索模块的语义推理。
3 由社会化标签获得本体
由于标签的多样性和模糊性,使大众标注系统的检索效率比较低,只能检索到用户输入的关键字所标注的资源,造成较高的漏检率。将本体引入到大众标注系统后,可以利用本体来实现检索系统的语义扩展、推理等功能,提高检索效率。大众标注是自下而上的分类法,标签具有很大的不确定性,没有等级结构。而本体是自上而下的分类法,具有层次结构和语义性。将这两者建立联系是一个很复杂的过程,可以通过分析用户的标注行为获得标签本体,也可以通过推理标签间的关系提取微量本体或者与已知本体映射形成本体。
3.1 分析标注行为获得标签本体
标签本体(TagOntology)是利用本体的概念对用户的标注行为进行明确的规范化的说明,也就是从语义的角度来表示标注行为,一般采用n元组的形式来描述标注行为,较为广泛的应用有:Tag Ontology、TagOntology、MOAT(Meaning Of A Tag)、以及SCOT(Social Semantic Cloud Of Tags)[ 2]。
Newman[ 3]提出的标签本体刻画了用户、资源和标签集间的关系,这种关系隐含在标注行为中。用户是FOAF本体中的Agent概念,标注行为表示了用户、标签、资源和时间的关系,标签定义为Tag类,通过Tag的属性来建立标注行为的关系,该方法已经应用在实际的软件中。Gruber[ 4]早在2005年就提出了标注行为的概念模型,并将其定义为Tagging:(Object,Tag,Tagger,Source,Polarity),前三项是大众标注系统中标签的元素,Source表示标签的来源,即哪个大众标注系统,Polarity表示基于标注行为的协同过滤。这个模型只是概念模型,并没有实际的应用,但是它首次提出协同标注的概念,可以方便在不同大众标注系统中的资源共享。MOAT[ 5]扩展了Newman标签本体的相关概念,并将大众标注系统的三元组模型扩展为四元组,添加了Meaning元素,由用户添加标签的语义,通过提供标签的语义标注实现内容的语义标注。SCOT[ 6]通过定义标签数据来表示标注行为,还可以为数据共享和复用提供互操作。SCOT建立在Newman标签本体的概念之上,核心概念是标签云(TagCloud),通过URI识别资源,也可以表示其他元素和属性的关系。由于可实现不同用户和系统的互操作,SCOT得到广泛的应用。
此外,通过分析标注行为获得本体的方法, Zhang等[ 7]提出用Probabilistic Generative Model模拟用户的标注行为,建立标签、文档间的语义关系,于是具有相同语义的标签聚集在同一个概念下,即本体中的类。
标注行为是大众标注系统中用户为分享的资源添加标签的基本活动,通过分析标注行为获得的本体是基于用户、资源和标签三者间的关系,本质是建立这三个要素的语义网,获得大众标注系统的本体。
3.2 推理标签关系提取本体
标签本体是基于用户的标注行为建立的本体,也可以从大众标注系统的标签中提取本体,即以标签为研究对象,通过推理标签间的关系、标签聚类等建立本体。推理标签关系是实现标签语义关系提取的基本环节,标签可能的关系为同义词、上位词或者无关联,现有的推测标签间关系的方法有很多种:
(1)三元组推测法
Mika[ 8]将传统的本体二元组扩展为三元组O(Actors,Concepts,Instances),利用标签间的同现建立标签的关系;为使用同一标签的用户建立联系。这种做法可以描述大众标注系统中的语义关系,建立大众标注的微量本体。
(2)基于FolkRank算法的相似性测量
Hotho等[ 9]提出用FolkRank算法测量标签的相关性,FolkRank算法由PageRank算法[ 10]发展而来,主要思想是不同用户标签的权重不同,对于给定的标签,给出相关标签的排名,最靠前的标签与已知标签最相关。
(3)条件概率法
Schmitz[ 11]和Damme等[ 12]利用标签的同现关系和条件概率模型,确定标签间的包含关系,即若条件概率P(x|y≥0.8)并且P(y|x < 1),则将x包含于y。建立可能表示父子关系的图,形成树状结构,具有一定的语义层次。
(4)Levenshtein Metric方法
Damme等[ 12]提出通过Stemming算法将变形词转化为原词,例如将links、linked还原为link,再利用Levenshtein Metric计算两个相似词间的相异距离,设定临界值来判定词是否相同,例如Green和Groen两个词。
(5)余弦距离
Limpens等[ 13]提出根据标签的同现关系计算Tag1、Tag2的相关向量V1、V2;再计算余弦距离Cos(V1,V2),根据实验,余弦距离大于临界值0.7的标签,即视为是关联标签。
(6)利用WordNet提供的语义关系
Cattuto等[ 14]提出利用WordNet提供的语义关系来获得标签的同义和上位关系,这样就获得了层次结构。
通过推理标签间的关系,即可获得标签集中标签间简单的语义关系,也就是微量本体,但是这种语义关系只是简单描述了标签间的关系,层次关系并不明确,因此有学者应用层次聚类技术,获得明确的层次结构。Wu等[ 15]将本体的生成过程看成层次聚类问题,利用层次聚类算法产生层次结构。Tomuro等[ 16]将Wikipedia作为外部知识源,利用DSCBC算法获得意义明确的标签集,最后利用一个改进的层次聚类算法获得本体。
推理标签关系获得本体是基于大众标注系统中的标签集生成本体的方法,研究对象是标签集,通过分析标签间的关系,建立标签的语义联系,再通过层次聚类等方法获得本体。这种方法类似于数据挖掘技术,即挖掘出标签间隐含的语义关系,所以会涉及到语言词汇方面的匹配等问题。
3.3 与已知本体映射形成本体
通过推理标签间关系提取的本体能够提供一定的语义关系,但是由于标签的多义性、模糊性等因素,使得标签语义关系并不一定准确,而且大众标注系统中的标签不一定包含领域内所有的词汇,而已存在的本体是由领域专家构建的,包含领域内所有的概念且具有明确的语义关系,因此,有人提出将标签进行一定的处理后与已知本体映射形成本体,更能满足用户检索的需要。
Specia等[ 17]通过标签同现关系将标签进行聚类后,再将相关联的标签对与语义网或本体资源进行匹配,具体做法是:Swoogle搜索引擎确认聚类中生成的标签对的关系是否存在,通过遍历本体资源Wikipedia 和 Google的概念、类和实例等,实现标签与本体的匹配。Baldoni等[ 18]通过给网站添加一个语义层,引入统计工具——相关系数,即基于相应词在Google中出现的频率,计算两个随机词汇间的关联强度,以此计算网站中的标签与已知本体OntoEmotions的概念术语间的关联强度,将标签映射到已存在的OWL本体。Han等[ 19]通过将用户标注的标签与领域本体ODP(Open Directory Project)映射来获得标签间的语义,并通过同现标签环境来限定标签的意义,映射过程由基于概率的算法实现。
将标签与已知本体映射是大众标注系统中获得本体最有效的方式,但也是最复杂的方法,现有的研究只提及了可以应用标签映射到本体的方法来实现大众标注系统的语义检索,并没有具体的解决方案。
3.4 其他方法
除了以上所介绍的方法,从大众标注系统获得本体还有很多方法,比如由用户生成本体、整合方法等。Gendarmi等[ 20]提出利用大众标注来生成本体。给定一个初始的本体,允许用户以本体词汇表为基础、根据需要自由地编辑本体,本体生成实质是“投票”过程,类似于大众标注中的标签云,最终根据权重和次数来确定本体的概念和实例等。Damme等[ 21]通过整合多种资源从大众标注中获得本体:分析标签和相关数据以确定标签的关联;使用Wikipedia、Google等在线词典资源来弥补不足之处;利用开放的本体及语义网资源提供的语义;本体映像和匹配技术鉴定标签间及标签和元素间关系。Lin等[ 22]将标签词汇归纳为4种形式:标准词、复合词、术语和错词,针对不同类的词进行不同的处理来获得本体。Angeletou[ 23]提出了一个语义丰富大众标注的算法工具FLOR,输入一组标签,通过自动与在线本体定义的语义实体建立联系,输出具有语义层次的标签集合。Chen等[ 24]从认知心理学的角度出发,将资源作为实例、标签作为实例的属性,利用算法实现基本层次概念的识别以及生成一个包含所有实例的根概念,将基本层次概念添加为根的子概念,反复进行,最后生成基本的本体。
综上所述,从大众标注系统中获得本体的方法有很多,并且大部分方法利用现有的大众标注网站获得的数据进行实验,证明了获得本体的可行性和有效性,虽然实验用的标签数据只是系统中的部分标签,有一定的限制条件,但是至少从理论上证明了建立基于大众标注系统的本体是可行的。
4 利用本体实现大众标注系统的语义检索
将本体引入到大众标注系统中的目的是利用本体建立标签间明确的语义关系,实现准确、高效的检索。现有研究从实现资源标注模块的标签推荐、提问处理模块的语义扩展两方面来研究如何利用本体实现大众标注系统的语义检索。
4.1 资源标注模块的标签推荐
传统的大众标注系统中,用户不受任何受控或非受控词汇表的限制、自由地对资源添加标签,标签的模糊性导致了检索结果不理想,引入本体后,可以利用本体提供的语义在用户标注资源时进行标签推荐、对标签语义扩展或者将标签与本体关联。相关的实现方法有:
Laniado等[ 25]提出为大众标注系统添加一个语义层,为用户提供标签推荐。建立一个C/S模型,服务器端包含一个核心模块,当用户输入标签后,自动地基于WordNet的层次概念,建立相关标签的语义树。客户端嵌入JavaScript程序,将标签推荐结果动态地展示给用户,供用户选择。该方法也可以应用于查询处理模块输入关键字后进行的标签推荐,限定标签的语义,消除模糊性。Lee等[ 26] 提出将领域本体和通用本体结合应用在图片检索领域。将Flickr中的标签进行手工分类,建立了微型领域本体,并利用通用本体WordNet提供的语义,在用户为图片添加标签时,对标签进行语义扩展,丰富了标签内容,使描述更详细,便于其他用户的检索。Passant[ 27]在博客平台的基础上,利用SIOC本体将标签和本体建立联系,用户在输入标签时需要选择要关联的本体概念或实例,这样可检索与输入的关键字相关的本体概念或实例,提高检索的查全率。
这些方法是利用已知本体WordNet或者SIOC本体来实现资源标注时的标签推荐,利用基于大众标注系统构建的专用本体来实现标签推荐更能满足用户的需求。利用本体进行的标签推荐,实际上是对用户标注行为的规范化处理,能够提高标签的语义性,使标注的标签与资源更相关,更利于资源的检索。
4.2 提问处理模块的语义扩展
现有的大众标注系统,只对用户输入的关键字与标签库中的标签进行简单的匹配,漏检很多语义相关的标签所标注的资源,通过本体对关键字进行查询扩展,可提高检索的查全率。相关研究有:
Bindelli等[ 28]建立了TagOnto系统。当用户输入关键字查询时,激发查询改善程序,将标签与领域本体进行匹配,搜索与标签匹配的本体概念,找到能改善查询的相关术语,将结果可视化显示在页面上,供用户选择。Angeletou等[ 29]获得本体后,当用户输入一个关键字进行查询时,将会返回三种结果:以用户关键字为标签的资源;与关键字同义的标签所标注的资源;与关键字在语义上相关的标签所标注的资源。Pan等[ 30]提出使用领域本体MusicOntology扩展大众标注系统的检索过程,以消除标签模糊性的方法,而且对用户是透明的。用户输入关键字以后,系统自动关联关键字和领域本体的类、属性和个体;然后,关联搜索关键字和领域本体中的相关关键字——个体属性值、个体类和个体属性,以获得更多的关键字。
用户输入关键字以后,查询处理模块实际上是将关键字与本体中的概念、类或实例匹配,返回相关联的术语,也就是扩展了检索关键字,系统可以综合这几个关键字进行检索,提高了查全率。
5 总结及展望
随着信息技术的不断发展,大众标注系统语义检索的研究会受到更广泛的关注,笔者认为未来的研究趋势主要体现在:
(1)本体的维护、更新问题
由于新标签不断地加入,大众标注系统一直处于动态变化中,新加入的标签更能体现某个领域的最新发展,因此,将新标签补充更新到已建立的本体是很重要的过程,而当前的研究还仅处于本体的构建阶段,未来的本体学习还需要更深入的研究。
(2)检索模块的语义匹配
现有研究提出了利用本体实现资源标注模块的标签推荐和提问处理模块的语义扩展等方法,而对于检索模块的语义匹配问题涉及较少。只有利用本体实现检索模块的语义匹配,才是真正地实现了大众标注系统中基于本体的语义检索,但真正实现这一过程有待进一步研究。
(3)利用本体实现大众标注系统间的语义检索
当前的大众标注系统都通过自己的数据库来存储用户、标签和资源等信息,没有一个统一的标准来描述标签的语义,使系统间的交互很难实现。虽然有学者提出可以通过建立一个大众标注系统通用的本体来描述标签在特定大众标注系统中的语义,检索时通过限定标签的语义范围实现跨系统间的语义检索,但实施起来难度较大。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|