{kind=link}
{kind=link}
利用遗传算法确定医学文献的研究热点
引用本文
张晗, 韩爽, 白星, 崔雷. 利用遗传算法确定医学文献的研究热点. 现代图书情报技术, 2011, 27(3): 57-61
Zhang Han, Han Shuang, Bai Xing, Cui Lei. Application of Genetic Algorithm to Identify Hot Topics from Medical Literature. 现代图书情报技术, 2011, 27(3): 57-61
Permissions
Zhang Han, Han Shuang, Bai Xing, Cui Lei. Application of Genetic Algorithm to Identify Hot Topics from Medical Literature. 现代图书情报技术, 2011, 27(3): 57-61
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
利用遗传算法确定医学文献的研究热点
摘要
提取医学文献的主题词特征向量,检索文献在发表两年后的最新被引次数,以此作为热点文献的指标,利用遗传算法编程,优化提取出能表达热点文献内容的主题词组合。以肿瘤干细胞为测试对象,以词频分析所得的结果作为基准线,并请相关领域专家对两组结果进行评价比较,结果显示遗传算法所得到的结果优于词频分析。
结果显示其引用高峰为2008年,选取2008年1月1日至3月1日的被引次数作为其热点的指标。经过多次实验,本研究交叉概率确定为0.7,突变概率确定为0.015。
关键词:
遗传算法; 学科前沿; 医学
中图分类号:TP18
Application of Genetic Algorithm to Identify Hot Topics from Medical Literature
Abstract
This paper firstly creates Medical Subject Headings (MeSH) feature vector for medical literature, then searches for the latest cited times of each paper after published two years, which serves as the indicator for hot papers. Using a genetic program, a group of MeSH terms representing the content of hot papers are extracted. The method is tested on the topic of neoplastic stem cells,and the results from term frequency analysis are served as a baseline. The outputs of two methods are evaluated by domain experts,and the results show that genetic algorithm based method has a better performance than term frequency based method.
Keyword:
Genetic algorithm; Research fronts; Medical subject heading
1 引 言
如何在世界范围内遴选某一学科领域当前的前沿和热点一直是科学研究的关键问题。传统上,当情报人员想了解有关学科研究的发展动态和研究热点时,往往采用征询少数专家的意见的方式,一般利用专家调查法来完成任务。尽管这种方法比较实用,但是也存在着种种弊端,例如花费较大、操作复杂、专家意见存在主观性等。
近年来,采用科学计量学方法来描述科学研究的结构和热点问题引起了广泛关注。由根据被引次数[ 1]、词频统计[ 2],到近年来通过分析款目对的共现情况(文献共现、关键词/主题词共现等),利用聚类分析[ 3, 4]等方法,以及知识图谱[ 5, 6]等手段确定研究前沿并将之可视化地呈现给用户。 尽管这些方法具备各自的优点,但同时也存在诸如部分高被引文献发表年代较早;关键词的选择存在用户偏好,造成相同主题分散在不同关键词中;词共现分析偏重于高频词,忽略了低频词在确定研究热点内容中的作用等。为了避免上述问题,本研究采用遗传算法,从文献内容的全局出发,选择能代表研究热点的最适宜的词。
本研究借鉴了美国科学信息研究所(ISI)评价热点文献的方法以及利用即年指标评价期刊的思想,将热点文献定位为近年发表,并在近期被引用次数较高的文献,利用遗传算法,获取热点文献的主题内容。
遗传算法是受达尔文自然选择理论的启发,即适应性高的个体存活时间更长,能产生更多的后代,使得优良的特性被保留下来,经过一代代的优选进化,使得最终产生的个体达到最优。目前遗传算法被广泛应用于信息检索、文本聚类、文献标引等方面。例如利用遗传算法为用于检索的关键词的权值进行优化,从而为关键词分配最佳的权值,或选择适宜的关键词进行查询扩展以及查询优化[ 7, 8, 9],或以类内个体差异最小、类间个体差异最大为约束条件,利用遗传算法寻求文本的最优聚类结果[ 10]。
本研究正是利用遗传算法这种随机搜索和全局优化的特点,以肿瘤干细胞为研究主题,在表达文献内容的概念集这个大的解空间中搜索最能表达热点文献内容的最优的概念表达,进而获得该领域的研究热点,为研究热点发现提供新的思路和解决之道。
2 研究框架与方法
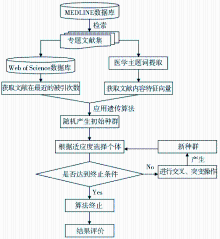
本研究首先在MEDLINE数据库中检索某专题的医学文献,利用文献学指标逐篇统计文献最近的被引次数,然后利用医学主题词对文献的特征内容进行提取,建立文献的特征向量。再根据遗传算法编程,获取热点文献内容的优化表达,并对结果进行评价。研究的流程如图1所示。
2.1 文献热度打分
ISI在评价热点论文和测定期刊的即年指标时都考虑到两个因素:被引次数及时间,期刊/文献的发表时间。本研究借鉴该思想,综合考虑文献的发表时间及被引次数的时效性,将热点文献定义为近年发表的并在最近被引次数高的文献。
本研究的目的在于验证遗传算法对发现研究热点问题的可靠性,侧重方法学的研究,而非对研究主题的内容进行具体分析。因此本研究的数据集并未选取最新文献,而是选择了一个完整的时间段,对方法进行测试。
在MEDLINE数据库中下载2005年某专题的医学文献,然后利用Web of Science数据库逐篇检索文献在最近的被引次数。鉴于文献在发表2-6年后才能达到引用高峰[ 11],本研究将最近被引次数定为达到引用高峰年的前两个月的被引次数。文献的热度Ei的计算公式为:
Ei= 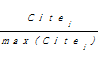
其中,Ei表示第i篇文献的热点打分,i为第i篇文献,Citei为第i篇文献的被引次数,max (Citei)为所有文献中被引次数的最大值。Ei为0-1之间的数,越接近1,该文献的热度越高。
2.2 文献内容特征的提取
本研究文献内容特征的提取借助于医学主题词,MEDLINE数据库对其所有文献的内容进行了主题标引,对于每篇文献,MEDLINE通常提供10个以上的主题词及主题词组配副主题词的组合来表达文献的主要内容。与关键词相比,主题词最大的优点在于对标引词进行了规范,对多个同义词统一用一个规范的术语进行表达;另外在标引过程中加入了人工校对,使标引词对文献内容的表达更加详尽准确。
利用医学主题词对文献的内容特征进行提取,建立文献集的向量空间模型,即如表1的文献-主题词词篇矩阵。
| 表1 文献-主题词词篇矩阵 |
其中,Ci为第i篇文献,Mj为第j个主题词,矩阵中的数字为0或1,0代表第i篇文献中不存在第j个主题词,相反,1则表示存在。
利用Ochiai[ 12]系数对矩阵进行标准化,则文献i的特征向量可以表示为:Di= {(Ci1,Wi1), (Ci2,Wi2), ……,(Cim,Wim)},其中Cij(j=1, 2, ……,m) 为Di中出现频率最高的前m个主题词,Wij为Cij的权值。
2.3 遗传算法的设计
遗传算法包括4个基本要素,为基因、基因位点、染色体和种群,各要素的含义及对应关系如下:
基因:染色体中的元素,为二进制数,在本研究中为表达文献内容的主题词,一个基因代表一个主题词。
基因位点:基因位点的取值决定主题词是否在文献中存在,0表示不存在,1表示存在。
染色体:由基因编码,为二进制串,是问题的一个解,在本研究中代表热点内容的不同表达形式,由一组赋予权值的主题词表示。
种群:染色体的集合,染色体的个数称为种群规模。
(1) 问题模型构建
本研究最终的目的是获取热点内容的最优概念表达,问题模型构建如下:
以F = {(C1,WF1), (C2,WF2)……(Cm, WFm)}表示研究热点初始种群,其中Cm表示主题词,WFm表示主题词对应的权值,从中抽取一个向量f=(WFm)。
以D = {(C1,WD1), (C2,WD2)……(Cm, WDm)}表示文献集中任一文献,从中抽取一个向量d =(WDm),则两个向量f和d之间的相似度为[ 13]:
Similarity(f,d)= 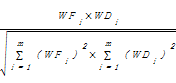
相似度是一个0-1之间的小数。相似度越接近于1,表示所选概念概括文章的能力越好,反之,则越差。
对于每篇文献,均有热度的打分Ei,则该问题可以转化为求向量f,使得对于每一篇文献di,都有 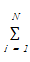
(2)程序设计
在具体的实施上,本研究采用MATLAB7.0软件包提供的遗传算法工具箱编程,程序设计如下:
①初始种群的产生及编码
将提取的主题词组成一个MeSH词集合,在集合中随机抽取15个词组成一个个体,共计100个个体组成初始种群。然后对每个个体进行编码并随机赋予权重。具体编码方法为:将所有主题词用十进制数按序编号,每随机抽取15个主题词产生一个个体,这15个词的序号就是这个个体的编码。
以F={(C1,WF1), (C2,WF2)……(Cm, WFm)}表示随机生成的初始种群。其中,C1表示一个概念向量,即一个个体。WF1表示与之相对应的权值,这些权值随机生成。
②选择
利用适应度函数,计算每个个体的适应度,选择适应度高的个体为父代,产生新个体。适应度函数的计算公式为:
Fitness= 
其中,N为文献集中文献的篇数, 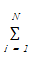
③重 组
对选中的个体进行重组操作以产生后代,包括交叉和突变。
交叉是两个父代个体f1和f2在某一相同基因位点互相交换部分基因,产生两个新的后代。交叉操作按照交叉概率Pc完成,即有Pc×n个个体进行交叉操作。
突变是父代个体在某一基因位点,基因的取值发生反转,即由0变为1,或由1变为0。突变按照突变概率Pm发生。
④收敛
算法在进化代数达到150时终止。此时,保留最优解。
3 实验数据及结果
3.1 数据集及参数设定
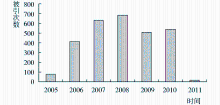
本研究选择2005年MEDLINE数据库中肿瘤干细胞的文献(排除综述文献)作为研究样本。利用Web of Science数据库检索2005年该主题的文献在其后各年的被引次数,如图2所示:
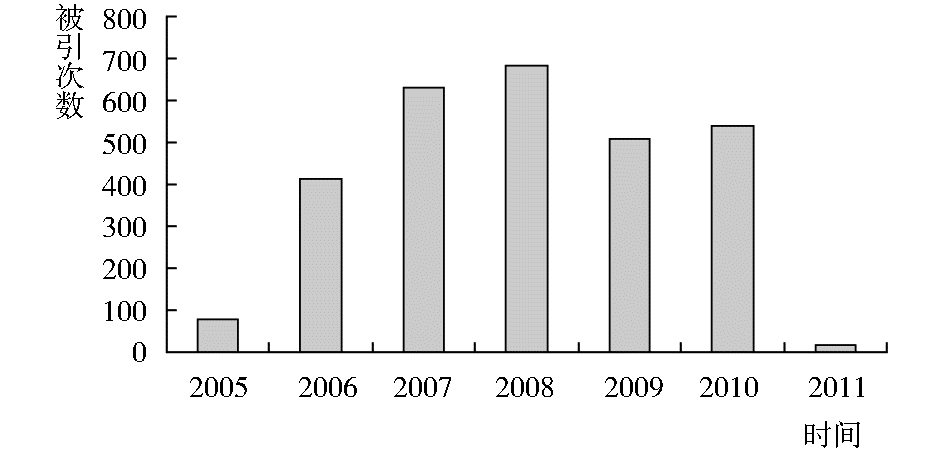 | 图2 数据集逐年被引次数 |
结果显示其引用高峰为2008年,选取2008年1月1日至3月1日的被引次数作为其热点的指标。经过多次实验,本研究交叉概率确定为0.7,突变概率确定为0.015。
3.2 结 果
MEDLINE数据库的检索结果为61篇,其中在2008年1月1日至3月1日两个月间,被引最高的前5篇文献被引次数为20,15,11,9,8。61篇文献共提取出208个主题词,用序号对208个主题词进行编码,在运行遗传算法后,最终产生的最优个体为:97 167 1 1 4 4 2 1 164 208 1 1 1 1 180。其中数字所对应的主题词内容见表2。
将本研究所得的肿瘤干细胞热点内容制作成调查问卷,同时与利用词频统计确定的研究热点作对比,请相关学科领域专家对结果进行评价。其中,词频统计法为:检索实验数据文献发表年后三年(2006年至2008年)发表的肿瘤干细胞的文献,统计主题词出现的频次,以前9个高频主题词作为词频统计法的研究热点内容,如表2所示:
| 表2 两种方法所得的热点内容 |
将上述两种方法产生的结果提交给学科专家(未参与实验的设计与实施),并请学科专家按照热点内容为:非常热点、比较热点、一般热点、不是热点4个等级逐条评价。评价结果如表3所示:
| 表3 两种方法热点内容等级比例 |
用遗传算法进行优化选择得到的结果均为热点内容,而用词频统计法得到的结果有1/3不是热点。
4 结 语
由专家评价可以看出遗传算法能够发现学科的研究热点,尽管程度不同,但所得的结果均为热点。与遗传算法结果相比,尽管词频统计法所采用的数据新于遗传算法的文献,其所发现的比较热点和一般热点均少于遗传算法,并且有1/3的结果为阴性。因此,通过以近期被引次数为标准,对文献内容进行全局优化能够发现研究的热点内容。同时结果也显示词频统计所得的非常热点比遗传算法多1个,究其原因可能为词频统计所分析的文献发表时间为2006年-2008年,而遗传算法所采用的文献发表时间为2005年,尽管遗传算法能优选出文献集中具有热点性质的主题词,但仅能反映出2005年发表文献的内容。
本研究也存在一定的局限性,例如利用主题词反映文献内容可能会比较宽泛,仅能反映研究的大方向,不够具体。同时一些参数的选择,例如检索时间的选择、交叉概率及突变概率的选择是基于预实验的基础,比较主观。在未来的研究中,将尝试用自然语言处理技术结合目前的医学本体——一体化医学语言系统(UMLS)对文献内容进行更加详细、具体的表达,同时在文献数据的采集上,选用多个不同主题的数据集以建立训练集,并在此基础上对实验参数进行确定。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|