{kind=link}
{kind=link}
{kind=link}
面向汉语自动句法分析的语法知识库构建*
引用本文
王东波, 朱丹浩, 谢靖. 面向汉语自动句法分析的语法知识库构建* . 现代图书情报技术, 2011, 27(4): 42-47
Wang Dongbo, Zhu Danhao, Xie Jing. Constructing the Grammar Knowledge Database Orienting Chinese Automatic Sentence Analysis. 现代图书情报技术, 2011, 27(4): 42-47
Permissions
Wang Dongbo, Zhu Danhao, Xie Jing. Constructing the Grammar Knowledge Database Orienting Chinese Automatic Sentence Analysis. 现代图书情报技术, 2011, 27(4): 42-47
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
面向汉语自动句法分析的语法知识库构建*
摘要
基于100万字的973汉语树库,按照语法功能分布的理论,从汉语自动句法分析和语言知识库构建的角度,构建一个相对系统化和多层次的语法知识库。该语法知识库由汉语词语、短语实例、短语结构、句法规则等知识组成。汉语词语知识共统计51 390个汉语词汇的58种语法知识,短语实例知识共获取3 836个汉语短语实例的58种语法知识,短语结构知识共抽取26种短语结构的58种知识,句法规则共有900条记录知识组成。该语法知识库的构建不仅为汉语自动句法分析和语言学研究提供语法知识,而且为更大规模的语法知识库构建打下基础。
关键词:
汉语自动句法分析; 语法知识库; 语法功能分布; 973汉语树库
中图分类号:TP391
Constructing the Grammar Knowledge Database Orienting Chinese Automatic Sentence Analysis
Abstract
According to grammar function distribution, a relatively multilevel and systematic grammar knowledge database based on 973 Treebank is constructed from the standpoint of Chinese parser and linguistic knowledge database construction. The grammar knowledge database consists of Chinese syntax knowledge, instance functions of syntax structure and structures’ syntax knowledge. The 51 390 Chinese word’s functions which include 58 kinds of function are gained. The 3 836 instance functions of syntax structure with 58 kinds of function are extracted. The 26 structures’ with 58 kinds of function syntax function are got. There are 900 Chinese sentences rules in the knowledge database. The grammar knowledge database not only offers the syntax knowledge to the Chinese automatic sentence analysis and linguistic researches, but also provides a model for the large-scale linguistic knowledge database construction.
Keyword:
Chinese automatic sentence analysis; Grammar knowledge database; Grammar function distribution; 973 Treebank
1 引 言
在汉语分词、词性标注研究取得重大突破的前提下,汉语自动句法分析的研究日益受到关注,并在借鉴印欧语言尤其是英语自动句法分析的基础上取得了一定的进展。但从汉语机器翻译、信息检索和篇章分析与生成的效果上看,汉语自动句法分析的精确率和召回率相对比较低。造成汉语自动句法分析效果差的一个重要原因是缺乏句子自动生成的语言知识,因此本文面向汉语自动句法分析,构建一个相对系统化和多层次的语法知识库。
关于语法知识库,国内外的研究者进行了一系列的研究并构建了相应的知识库。为了整合英语的词汇知识并使之系统化和条理化,在Miller的带领下,普林斯顿大学构建了一个英语同义词知识库WordNet[ 1],该知识库目前有95 600个不同的词型,同时组成了70 100个词义。围绕该知识库,语言学和计算机专家进行了一系列的研究,如词典编纂、语义自动获取、聚类分类等。本文在构建词汇知识功能的过程中,借鉴了WordNet的设计理念。以汉语的特征为出发点,董振东等[ 2]构建了HowNet知识库,该库是一个以汉语和英语的词语所代表的概念为描述对象,并揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。HowNet是一个网络化知识系统,着力要反映的是概念的共性和个性。自从HowNet推出以来,被广泛地应用到汉语自然语言处理的方方面面,如语义知识获取、英汉双语自动翻译和语义角色标注。本文在汉语词汇的确定过程中参考了HowNet。在借鉴WordNet构建的相关经验基础上,北京大学计算语言研究所提出了中文概念词典(Chinese Concept Dictionary, CCD)[ 3]构建模型并在一定词汇的基础上进行了实验。中文概念词典的模型主要是基于双语词典中的继承和转换理念,实现由WorNet到CCD的转换,进而得到一个汉英对照的双语语义词典。中文概念词典的设计理念以及通过已有语言知识获取相应新知识的设想给本文知识库的构建提供了一定的借鉴。在北京大学计算语言研究所俞士汶的主导下,面向汉语信息处理的《现代汉语语法信息词典》[ 4]于1998年推出。该语言知识库共包含了约7.3万个汉语词条,并对每一词汇的语法属性进行了相对精确的描述。该知识库无论是在中文信息处理领域,还是在汉语研究领域都得到了相当广泛的应用。本文在确定语法知识库的58种语法属性的过程中,参考了《现代汉语语法信息词典》确定语言属性的方法。在HNC(Hierarchical Network of Concepts)概念体系的3 000多个概念基元上,通用型概念层面知识库被构建出来,并得到了一定程度上的应用[ 5]。刘亮[ 6]从计算语言学的角度,基于人民日报语料库,构建了现代汉语广义助词知识库。彭爽等[ 7]从现代汉语介词与广义虚词库的关系这一角度出发,构建了现代汉语介词知识库。
在前人研究的基础上,本文基于973树库,在语法功能分布的理论下,构建了由汉语词汇语法知识、短语实例语法知识、短语结构语法知识、语法规则知识等相关知识组成的语法知识库。
2 973汉语树库和语法功能分布理论
2.1 973汉语树库
在11种语法功能和16种语法结构的基础上,清华大学计算机系智能技术与系统国家重点实验室构建了一个100万字的汉语973树库。该库对每个句子都进行了全面的句法分析,并标出了每一个词汇和短语的句法功能和句法结构。973树库的详细信息如表1和表2所示:
| 表1 973汉语树库的基本统计数据 |
| 表2 973汉语树库的句子长度分布数据① |
本文所构建的语法知识库中的语法知识都是基于973汉语树库进行统计的。973汉语树库的具体标注例子如下:
[zj-XX [dj-ZW 报名者/n [vp-XX [vp-ZZ 须/d [vp-ZZ 正楷/n [vp-PO 填写/v [np-LH 姓名/n 、/、 [np-DZ 通信/vN 地址/n ] 和/c 邮编/n ] ] ] ] [dlc-BC (/( [vp-ZZ [vp-ZZ 不/dN 要/vM ] [vp-ZZ 另/rD [vp-PO 写/v 信/n ] ] ])/) ] ] ]。/。 ]
2.2 语法功能分布
朱德熙[ 8]提出按照词的语法功能对汉语的词进行分类,这一设想的实施必须获取词汇的各种语法功能。陈小荷[ 9]进一步从汉语自动句法分析的角度,提出完全按照词汇的语法功能分布对汉语的词汇进行分类的理念,这一理念从一定程度上强化了语法功能分布在自然语言处理中的作用。由于当时没有大规模的语料库,该理念一直没有得到有效的验证。随着大规模语料库和相应语言知识库的构建,这一理念被证实的条件基本具备。在此基础上,徐艳华[ 10]按照汉语语法功能分布的理念,借助大规模语料库,详细考察了3 514个汉语词汇的语法功能,并对这些词汇进行了重新分类。在其实验中,基于语法功能分布获取的词类,在消除自然语言处理中的歧义问题上,获取了非常好的效果。这在一定程度上证明了语法功能分布理念的合理性和有效性。在上述关于语法功能分布研究的基础上,本文基于973汉语树库,不仅全面、详细地考察了词汇、具体短语、短语结构的语法分布,并且在获取各种语法知识的基础上初步构建了汉语语法知识库,以期为汉语的分词、词性标注和自动句法分析提供一定的汉语语言知识。
3 语法功能的确定
973树库的所有句子中共有16种结构,这些结构共充当了16种词性类的语法成份。本文在973汉语树库的基础上,按照汉语语法功能分布的理论,根据构建语法知识库的需要,重新确定了汉语词汇、具体短语实例、短语结构的语法功能成份。
在973汉语树库16种语法结构的基础上,重新调整后的汉语语法知识库的语法结构如表3所示。
在16种语法结构的基础上,经过归并和调整,最后变成了26种语法结构,本文在调整的过程中主要是细化和优化部分语法结构,使语法知识库中的语法分布更加合理和有效。如述补结构,973树库中只有一种述补结构,而本文按照述补结构的内部具体分布情况,把述补结构分成了简单述补结构、带“得”述补结构、带“不”述补结构三类。为了更直观地称呼和便于在程序中统一地描述具体的语法结构及其语法功能,本文使用具体结构的拼音大写首写字母来称呼各种结构。其中“2、3、≥2”分别表示某一结构可以分出2种、3种和2种以上的语法功能。
在26种语法结构的基础上,结合汉语语法功能分布的特征,本文确定了58种语法功能,具体如表4所示。
| 表3 语法知识库的基本语法结构 |
| 表4 语法功能的具体成份 |
在获取词汇、短语实例和短语结构的具体语法知识的过程中,为了更直观地描述具体的语法功能,本文把带“的”定中结构、无“的”定中结构、带“地”状中结构、无“地”状中结构、简单述补结构、带“得”述补结构和带“不”述补结构等7种结构统一称为定中类、状中类和述补类。
4 语法知识的统计
4.1 语法结构转换
在973树库的基础上,参照重新制定的26种语法结构,本文通过程序对973树库中的相应语法结构进行了转换,如把附加结构(AD)转换为7种对应的语法结构。具体规则如下:
(1)如果词汇是具体的人名、地名和数字,则统一标注为抽象的“0人名”、“0地名”、“0数字”。
(2)如果语法结构是定中结构(DZ),则把定中结构分为带“的”定中结构和不带“的”定中结构,即:DZ = 1DZ + 2DZ 或DZ
(3)如果语法结构是状中结构(ZZ),则把状中结构分为带“地”状中结构和不带“地”状中结构,即:ZZ = 1ZZ + 2ZZ或ZZ
(4)如果语法结构是述补结构(SB),则把述补结构分为一般述补结构、带“得”述补结构、带“不”述补结构,即:SB = 1SB + 2SB或SB
(5)如果语法结构是附加结构(AD)而且是动词式附加结构,并且动词紧接着的是“了,着,过”这三个助词,则把整个附加结构看作一个词语来处理。
(6)如果语法结构是附加结构(AD),而且附加结构后面以“似的,似地,样,一样,一般”等词结尾,则把该类附加结构转换为比况结构,即:BK=1BK + 2BK。
(7)如果语法结构是附加结构(AD),而且附加结构后面以“的、者”结尾,则把该类附加结构转换为“的”或“者”字结构,即:DE=1DE+“的”|“者”。
(8)如果语法结构是附加结构(AD)或者是状中结构(ZZ),而且两类结构前面以“所”字开头,则把这两类结构转换为“所”字结构,即:SZ = “所” + 2SZ。
(9)如果语法结构是附加结构(AD),而且该结构以“云云、等、等等、一类、之类”等词汇结尾,则把该结构称为枚举结构,即:MJ=1MJ+2MJ。
(10)如果语法结构是附加结构(AD),而且该结构以“之余、之久、许、之际、之时、时”等词汇结尾,则把该结构称为时间结构,即:SJ= 1SJ + 2SJ。
(11)如果语法结构是附加结构(AD),而且该结构以语气词结尾,则把该结构称为语气结构,即:YQ= 1YQ + 2YQ。
在上述11条规则的基础上,通过程序,本文完成了对973树库的结构转换,使树库中的语法结构更加符合汉语语法分布的规律。
4.2 语法知识统计
本文定义了一个多叉树来存放973树库中的每一个句子,用来存储句法树的短语结构或词汇,具体流程如下:
(1)在读入每个句子的过程中,去除句子编号,并压缩掉句子前后的空格、制表符等符号;
(2)在处理好的句子基础上,建立一棵多叉树;
(3)输出短语结构或词汇等相应数据,创建节点;
(4)先根序列遍历树,输出节点的指针序列;
(5)求临近左节点,即前一短语或词;求临近右节点,即后一短语或词;
(6)插入新节点为上一个节点的一棵子树;
(7)删除节点上一个节点的一棵子树;
(8)返回节点上一节点下的所有词或短语。
经过上述处理,获取每一个词汇、短语实例、短语结构的语法知识和整个句子的组成规则序列,并存储到语法知识库中。
5 语法知识库的分析和应用
在26种语法结构和58种语法功能的基础上,本文获取了4种汉语的语法知识,即汉语词汇的语法知识、短语实例的语法知识、短语结构的语法知识和句法规则知识,并由这4种知识组成了汉语语法知识库。
5.1 词汇的语法知识
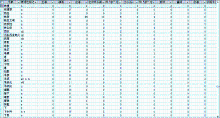
基于973树库,本文共获取了51 390个词汇的58种语法知识,为了便于后续的分析和研究,同时增加了该词的词性知识。在具体的统计过程中,标点符号也被列入统计的范围。具体的汉语词汇语法知识示例,如图1所示。
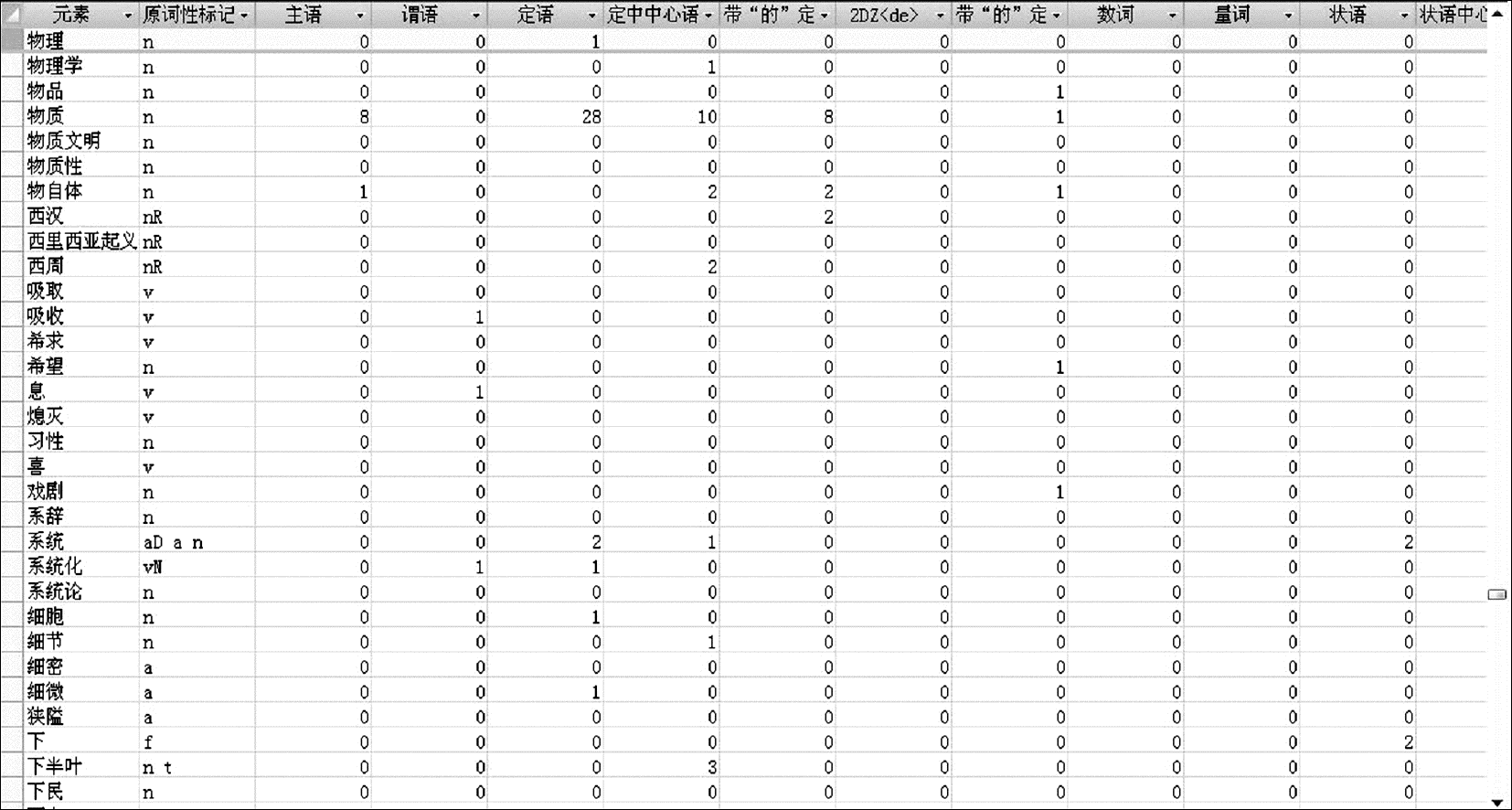 | 图1 词汇的语法知识分布 |
图1中选取了词汇的部分语法知识分布情况,主要是一些高频词的分布情况。尽管词汇语法知识统计的语料库规模并不是很大,但获取的词汇语法知识分布情况在一定程度上反映了汉语词汇的某些特征,如“物质”与“精神”这两个词无论是从概念类别上还是概念属性上都属于同一个类属,而这两个词的语法功能分别是74和73,并且这两个词的具体语法分布区间也一致。
5.2 短语实例的语法知识
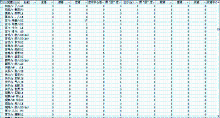
本文共获取了3 836个短语结构的语法知识,短语结构的语法知识类别与词汇一样,也是58种。短语实例的语法知识示例,如图2所示:
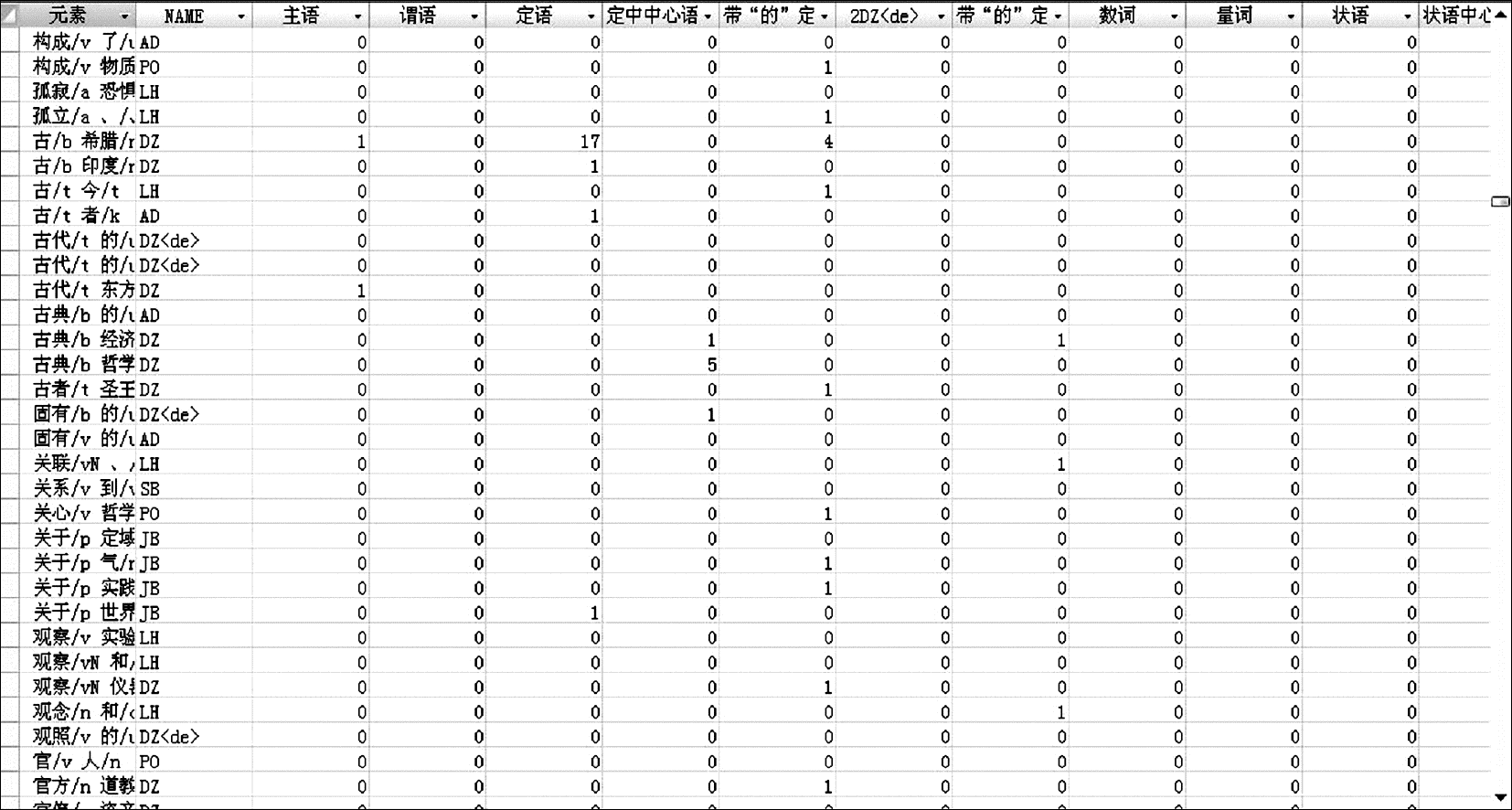 | 图2 短语实例的语法知识分布 |
相对词汇的语法知识分布情况,短语实例的语法知识分布数据相对稀疏,因为短语实例无论从语法单位级别还是从具体的长度来看都是更大的一个单位,在100万字的树库中不可能获取到充分的语法知识分布情况。本文通过获取具体短语实例的语法功能,为下一步在更大树库基础上获取充分的语法知识分布情况打下基础。
6 结 语
本文从汉语自动句法分析的角度,基于973树库,获取了汉语词汇、短语实例、短语结构和语法规则的相应知识,并构建了语法知识库。在构建语法知识库的过程中,结合具体的情况,本文对已有973树库的结构进行了转换,同时设计了相应的多叉树存储数据结构来统计相应的语法知识。虽然汉语各层级上的语法知识在一定程度上反映了汉语的特征,但由于973树库的规模比较小,获取的数据存在一定的稀疏性,下一步工作将在一般语料库的基础上,通过搭配来弥补这一问题。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|