
{kind=link}
{kind=link}
{kind=link}
PDF过量下载监测的设计与原型实现
引用本文
李宇, 王威. PDF过量下载监测的设计与原型实现. 现代图书情报技术, 2011, 27(4): 71-76
Li Yu, Wang Wei. Design and Prototype Implementation of PDF Downloading Abuse Warning System. 现代图书情报技术, 2011, 27(4): 71-76
Permissions
Li Yu, Wang Wei. Design and Prototype Implementation of PDF Downloading Abuse Warning System. 现代图书情报技术, 2011, 27(4): 71-76
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
PDF过量下载监测的设计与原型实现
关键词:
预警; 网络监测; PDF过量下载; 开源软件
中图分类号:G250
Design and Prototype Implementation of PDF Downloading Abuse Warning System
Abstract
Excessive PDF downloading is likely to cause service disruption of electronic resources. Based on network analysis of PDF downloading behavior, a prototype monitoring system is designed and implemented with open source software. The accuracy of the system is proved by one year of actual operation.
Keyword:
Warning; Network monitoring; Excessive; PDF downloading; Open source software
1 引 言
电子资源出版商,例如Elsevier、Blackwell、John Wiley、Springer、ACS等,使用DOI[ 1]作为唯一标识符,以PDF[ 2]为封装形式,为科技工作者及高校师生提供旗下期刊、文章、会议录等电子资源,供用户下载使用。在这个过程中,合理使用是出版商及图书馆最常见的话题之一,为了遵循相关使用合同,保障所有用户都能按需随时获取数字资源,需要不断对用户进行合理使用的宣传。数据库厂商对于数字资源的使用有比较严格的规定。绝大多数用户在了解厂商的授权规定以后,都能够按照要求进行资源的浏览和下载。但极个别的用户为了追求方便或者因为其他原因,使用工具软件批量下载以PDF文件形式封装的期刊及文章。短时间内大量的下载违反了厂商关于合理使用的要求,最直接的后果是导致数据库厂商的自动滥用监测系统直接封锁过量下载的IP地址。如果情节严重的话,厂商甚至会采取封锁整个IP段的严厉措施,这将导致大面积的用户无法正常使用数字资源。
出现过量下载的三种典型的情况为:
(1)极个别的读者在使用相关资源时,为图便利,使用图书馆计算机进行批量下载,导致数据库商封锁该IP地址。
(2)为了节约IP地址资源,同时增加网络安全保障,使用网络地址翻译技术(Network Address Translation, NAT)将多个内网地址转化为一个外网地址,当有多个用户同时使用某一个厂商的资源时,由于对外显示是一个IP地址,可能导致多个用户总的下载数量超过厂商设定的阈值,从而导致该外网IP地址被判断为过量下载。
(3)代理服务器同时为多个用户服务时,也容易造成过量下载。多个用户在使用系统时,容易在代理服务器环节造成下载数量超过厂商设定的阈值,从而导致该代理服务器IP地址被判断为过量下载。
清华大学网络中心为其图书馆专门定制开发了一套PDF超量下载监测系统,与其网络管理功能结合。在发现用户的超量行为后,可以停止用户的访问权限,其实现机制为网络数据包过滤。
2 过量下载行为的判定依据
过量下载是指某个IP地址短时间内大量下载特定出版商电子资源的行为。电子资源出版商设立了自动滥用监测系统,当某个IP地址在某个时间段内对电子资源进行集中下载的时候,出版商系统会自动记录下载的具体的电子资源并实时进行是否滥用的评估。不同的厂商对于资源是否被滥用和过量下载有不同的定义,出于保护自动滥用监测系统的考虑,出版商不对用户说明具体的阈值,以防止用户略低于阈值进行持续下载。
通常情况下,用户在检索后,会对题名、作者、机构、文摘进行浏览,从而决定是否下载某篇感兴趣的PDF文献。在正常使用浏览器浏览出版商资源的时候,如果用户面对会议录、分章节的电子书、特定的检索产生的列表等情况,则倾向于“整包”下载。无论是哪种情况,只要用户在单位时间内以单个IP地址下载PDF文件的次数过多,就应当被判定为过量下载。
在不可能获得厂商的详尽数据和具体判定规则时,要想获得准确的下载情况,只能通过对网络传输的数据包按传输协议进行分析,从而获得可靠的统计数据。
超文本传输协议(HyperText Transfer Protocol,HTTP)[ 3]是基于请求/响应范式的客户机/服务器模式的协议。从实际的统计中,没有一家出版商使用安全超文本传输协议(Secure HyperText Transfer Protocol,HTTPS)协议来支持PDF下载。HTTPS协议运算量大[ 4],主要用于加密保护敏感信息,在PDF文件下载时,通常不使用HTTPS协议。
MIME类型[ 5](Multipurpose Internet Mail Extensions)使得HTTP传输变得丰富多彩,而不仅是普通的文本。 每个MIME类型由两部分组成,一部分是数据的大类别,例如声音Audio、图像Image等,另一部分是定义具体的种类。常见的MIME类型如下:
| 表1 常见的MIME类型 |
Internet专门组织IANA[ 6](Internet Assigned Numbers Authority)负责确认标准的MIME类型。服务器在发送真正的数据之前,要先发送标志数据的MIME类型的信息,这个信息使用Content-type关键字进行定义。根据RFC3778的规定[ 7],服务器在向客户机应答PDF文件时,服务器将使用简单的ASCII文本发送PDF文件的MIME标识信息“Content-type: application/pdf”,这个标识并不是真正的数据文件的一部分。以这种方式通知客户机文件类型,方便客户机进行相应的处理。绝大部分国外数据库厂商均遵循RFC3778。在发送数据流之前,标明其MIME类型为“application/pdf”。
一些数据库厂商没有遵循RFC3778,而是使用二进制文件下载的方式,其主要特点是:在HTTP应答头中使用“Content-type: application/octet-stream”来标明将要开始二进制文件下载;同时添加具体下载文件名“Content-Disposition: attachment; filename=XXX.pdf”,其中XXX就是用服务器发送并由用户接收的PDF文件名。
3 监测系统设计
笔者选择FreeBSD[ 8]作为本监测系统的底层操作系统,全部使用开源软件辅助开发和建设。
3.1 监测系统结构
监测系统采用模块化设计,从软件层面主要分为三个主要部分:
(1)数据采集层,负责网络数据包的截获和实时分析,并采集PDF下载情况送入内存暂时存储;
(2)实时预警层,基于滑动时间窗对已经采集的PDF流量数据进行实时分析,并对超过预警阈值的行为发送邮件及时通知相应的管理员;
(3)Web界面管理及应用统计层,通过Web方式管理系统的配置以及查看系统相应的统计并形成报表。
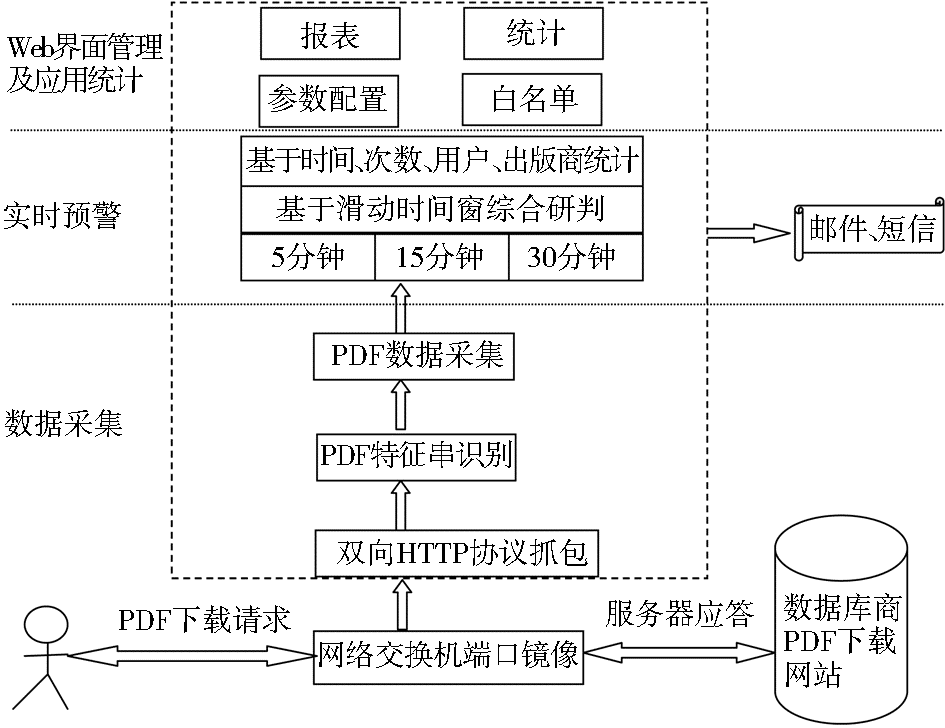 | 图1 监测系统结构示意图 |
3.2 可配置参数
由于采用网络三层交换数据流抓取HTTP协议数据包,监测系统记录的主要是IP地址、域名及部分HTTP协议的内容。因此,需要配置域名——数据库商对应表、请求IP——管理员对应表、每个域名的预警阈值、管理用户名及密码。正如域名和出版商的关系一样,请求的IP地址段与对应的管理员需要一个对应表,从而方便预警信息的发送。
3.3 白名单功能
在网络实际使用过程中,会出现大量的PDF文献被下载,但并不需要预警的情况。典型的例子包括:放置在网络中供公众自由下载的PDF资源[ 9],自身有预警及记录的镜像服务器[ 10],因Web Archive或者情报监测等目的使用网络爬虫抓取网络PDF资源等情况。因此,在监测系统中,需要提供服务器白名单、请求IP白名单,所有添加到白名单中的IP均不需要进行预警。它们的下载速度和并发数只需要考虑服务器是否允许爬取以及可承载的压力上限即可。
3.4 统计及报表功能
统计数据只有4个维度:时间维度(分、时、天)、请求IP、服务器、下载次数。
(1)按数据库商(用户可在参数配置中选择多个服务器域名对应一个出版商,从而获得更宏观的统计情况),分别按时、日、周、月、年、PDF下载次数的使用情况统计并生成报表。
(2)按请求IP、分别按时、日、周、月、年、PDF下载次数的使用情况统计并生成报表。
(3)按数据库下载数量降序排列,并对超过预警阈值的数据库打上明显标记。
(4)按机构内IP地址对PDF下载情况降序排列。
(5)按数据库-请求IP地址对降序排列。
3.5 预警功能
发生过量下载时,应及时向负责资源管理的人员,以及IP地址使用者对应的管理员发送预警信息。超量预警的消息内容包括:数据库商名字、超量的IP地址、发生的时间段以及具体的PDF下载数量。支持电子邮件及手机短消息方式进行及时通知。
4 技术实现
本文仅阐述监测系统关键的数据包抓取、实时分析及预警部分的实现。
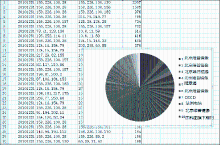
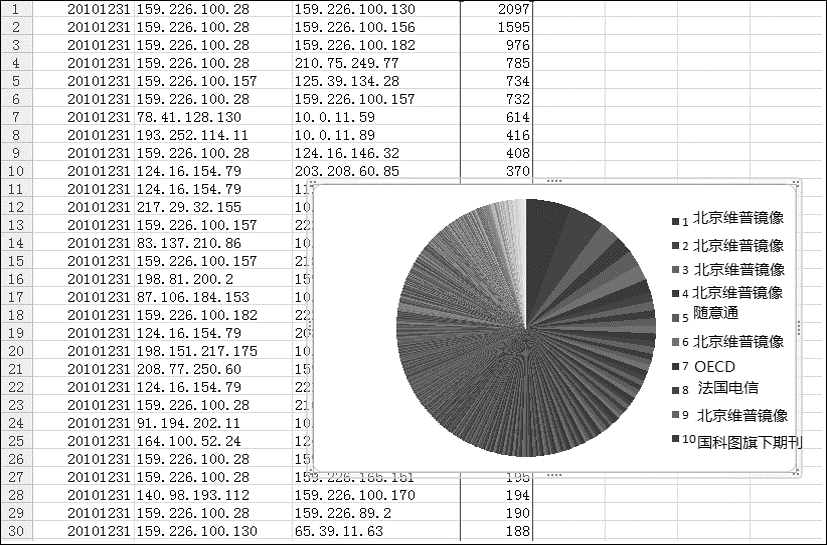
通过三个月的网络流量数据采集和数据统计,PDF下载的基本情况如下:所有数据库商的PDF文件应答均通过HTTP协议;每天每对客户机/服务器的平均PDF下载数量为15篇;其总体标准偏差为0.29。图2是下载数量的分布饼图,背景是其中一天的具体下载量排名。从中可以看出,大部分下载是合理和均匀的,其中份额较大的PDF下载是维普中文期刊北京镜像站中的中文期刊。
在实际统计中,每天被单个IP下载300多篇PDF的ACS,被下载近300篇的ScienceDirect,出版商均未判定其为过量下载。在技术实现中,对每天总下载数量较大的IP地址向管理员发送通知邮件即可。预警应将监测单个IP单位时间内的下载篇数为主要目标。
4.1 网络监听及数据包抓取
一次成功的PDF下载,应当是一个完整的请求和应答。通过交换机端口镜像方式对网络进出边界上流经的所有数据包进行包过滤,抓取双向的数据包并对其进行分析。经过对数据包的初步统计,数据库商的PDF文件应答均通过HTTP协议且全部通过80端口向客户机IP地址发送。在数据包抓取过程中,只对这些数据包进行分析判断,抽取需要的HTTP数据包,经过转换以后提取到Redis 1.4.2服务器中的预警队列,很大程度上降低了海量数据包带来的计算压力。
 | 图2 Stream数据分析 |
监测系统数据包抓取基于以太网结构进行设计和实现。本文参照深度包检测技术[ 11, 12]通过抓取进出80端口的TCP数据包,截获HTTP协议内容并捕捉关键字“Content-type: application/pdf”来获得服务器的PDF应答。服务器的PDF应答如下:
2010/03/11 08:48:22.578449 159.226.100.130:80 ->123.116.121.138:3590 HTTP/1.1 200 OK..Server: Microsoft-IIS/6.0..X-Powered-By: ASP.NET..X-AspNet-Version: 2.0.50727..Content-Length: 498854..Accept-Ranges: bytes..Cache-Control: private, max-age=0..Expires: Fri, 11 Mar 2010 00:48:21 GMT..Last-Modified: Sat, 06 May 2006 03:13:20 GMT..Content-Type: application/pdf..Date: Fri, 11 Mar 2010 00:48:22 GMT..Connection: close....
使用Shell脚本同时直接调用Redis 1.4.2的客户端读取命名管道文件。对所有HTTP应答进行抽取、转换,并存储到Redis当中名为1minutequeue的List数据结构(时间、服务器IP、客户机IP、请求次数)中,具体如下:
ngrep-q -d fxp1 -t -W single "Content-Type: application/pdf.." tcp src port 80
|grep"HTTP/1.[0-9] 2[0-9]* OK" >fifofile &
while read line
do
time=′echo $line | awk ′{print $2,$3}′ | tr -d "/" | sed -e ′s/.[0-9]*$//g′ | aw
k -F: ′{print $1,$2}′′
ymd=′echo $time|awk ′{print $1}′′
server=′echo $line | awk ′{ print $4}′|awk -F: ′{ print $1}′′
client=′echo $line | awk ′{ print $6}′|awk -F: ′{ print $1}′′
redis-cli rpush $1minutequeue "$time $server $client 1" >/dev/null 2>&1
done< fifofile
当用户选择下载PDF文件并由浏览器发送HTTP请求时,数据库商的服务器会遵循RFC3778应答客户机。这些客户机的请求,需要进行记录,方便与服务器的应答进行数据比对,以提高预警的准确率。同时,截取“Host:”字段的内容,将对应的IP地址及域名以键值对的方式存储在Redis当中,从而保证使用相对较快的响应速度提供准确的服务器域名及IP地址对应关系。客户机PDF请求具体如下:
2010/03/11 08:49:42.388720 159.226.100.42:49284 ->12.161.242.20:80 [AP] GET /doi/10.1002/(SICI)1521-4095(199808)10:11&lt;827::AID-ADMA827&gt;3.0.CO;2-L/pdf HTTP/1.0..User-Agent: EndNote..Host: onlinelibrary.wiley.com..Cookie: WOLSIGNATURE=fe5d9305-89a5-43ef-9819-0c2d88f63d87; utma=235730399.671048027.1299461493.1299568733.1299652261.4; utmz=235730399.1299461493.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); JSESSIONID=B23E35A502EB7ABC5B8EE255079DBE7D.d02t01; OLProdServerID=1025.. Cache-Control: max-age=259200..Connection: keep-alive....
4.2 基于消息队列的PDF下载行为判定
参照Unix系统CPU负载三个时间点设计,监测系统也采用了5分钟、10分钟、15分钟三个时间段,使用Redis的List数据结构[ 13]实现了三个基于内存的先进先出数据队列,保证了数据包抓取的可持续性,同时也降低了程序实现的复杂性。
使用Crontab定时器每分钟唤醒程序,程序唤醒时立即处理1minutequeue,对其进行扫描并检查是否存在爆发下载。如果有,则立即调用预警模块;否则,使用Redis的RPOPLPUSH指令将该List中的数据全部转移到5 minutequeue。当前时间能够被5整除时,使用Redis的RPOPLPUSH对List操作,将整个队列进行迁移,并扫描三个链表获得对应的统计数据。从这些统计数据中找出系统最近5分钟、最近10分钟、最近15分钟下载数量是否超过了阈值。
4.3 半自动步进阈值
为得到本系统的初始全边界,笔者首先选择管理政策较为严厉的出版商ACS以及APS进行了实际下载的实验。笔者选取了特定专题,在半小时内使用浏览器边浏览边下载了30篇PDF文献,未收到停用警告。此外,笔者选择Springer和Elsevier进行了相同的实验,同样出版商系统判定为合理使用。
根据上述实验,笔者初步假设“每分钟下载一篇PDF是合理的”。在设置每个出版商的初始安全边界以后,系统在实际使用过程中,会随着时间流逝产生各个IP地址访问出版商的记录。通过对这些访问记录进行统计,对已经超过初始阈值的PDF下载峰值进行记录,并在两周后提醒管理员是否可以提升该资源预警阈值,如果管理员没有收到数据库商的警告,说明此阈值是对方系统允许的。国家科学图书馆总馆2010年收到的8次滥用通知中,出版商的滥用监测系统均在自动封锁超量下载IP地址后同时将警告邮件发到管理人员邮箱。
通过这种半自动人工确认的方式进行预警阈值的逐步逼近。为简化实现,本文实现的监测系统原型没有针对性区分不同资源出版商的不同管理政策,仅使用单一预警阈值逐步逼近。经过半年运行步进后,预警阈值已经逼近到4篇/分钟,相当于每15秒下载一篇PDF全文,持续半小时达到120篇的水平。从实际使用角度看,达到此预警阈值的使用行为不再是按需下载,而是持续的、有规模的批量下载。笔者将原型系统预警阈值锁定在平均4篇/分钟、并且半小时内总数达到120篇。
4.4 预 警
采用开源软件Redis的内存List队列,通过队列的RPOPLPUSH左进右出指令操作来实现时间窗的滑动。使用LRANGE指令获得单队列的全部内容,对PDF下载情况进行统计,按照下载数量-服务器/客户机进行排序。计算单位时间均值,并与预设的阈值进行比较,对于超过阈值的IP地址,如果不在白名单范围之内,立即发送邮件通知,从而实现实时预警。
原型系统主要的判定数据来源类似HTTP应答数据。该数据包不包含服务器域名,需要取得IP对应的域名,以方便和预警阈值调用比对。从IP到域名有两种办法,一种是进行DNS域名反解析[ 14],另一种是从HTTP请求中提取Host字段(如客户机PDF请求中的onlinelibrary.wiley.com)。提取已经存入Redis的IP/域名对照键值对的速度大约为每秒8万次[ 15],而单个DNS域名反解析的响应时间需要几秒钟。从效率上来说,DNS域名反解析是无法接受的。
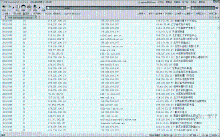
当计算比对完成后,如果当前时间窗中的服务器/客户机PDF下载数量超过了预警阈值,则调用对应客户机的管理员的邮件列表,发送邮件通知。通知中包含时间、服务器域名、客户机IP地址及其地理位置、具体的下载次数,如图3所示:
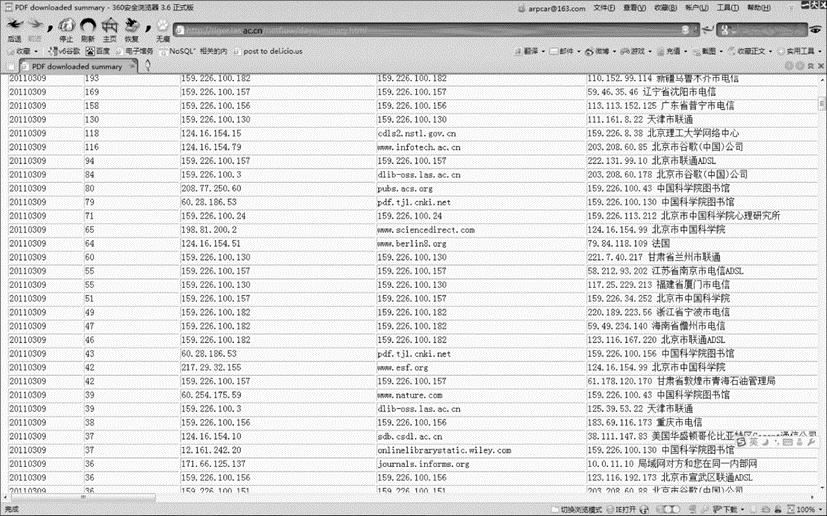 | 图3 PDF下载情况汇总 |
如果发送邮件到绑定手机号的中国移动139邮箱,利用公共平台可以接收零费用的短信通知。
客户机的IP地址地理位置是利用纯真网络[ 16]的IP地址数据库,撰写了一个基于REST风格的PHP程序(调用格式为http://monitor.las.ac.cn/iplocation/ipl.php?IPV4=$client),能够快速获得对应IP地址的大概地理位置。
4.5 小 结
通过分析网络数据包规律及厂商过量下载通知函,明确PDF过量下载监测的重点在于PDF下载状态的实时监测及预警。根据实际的运行数据提出PDF过量下载监测软件系统的功能需求,设计了针对该问题的软件系统架构,以开源软件作为基础进行了二次开发,构建并实现了基于开源软件的PDF过量下载监测原型系统。
原型实现主要依靠服务器的HTTP应答数据包中单位时间内PDF下载数量作为主要的判定依据,通过半自动步进获得相对稳定的预警阈值,当出现疑似超量时,发送预警信息。 同时记录各IP地址对各个数据库商的PDF下载次数。
系统软件成本低廉,运行稳定,能够完成实时监测、跟踪PDF下载使用趋势并迅速定位异常点。经过一年的实际运行,期间发生过量下载行为8次,没有出现过误报。
5 结 语
本文通过抓取HTTP协议网络数据包进行特征值匹配从而判定PDF超量下载;采用半自动步进阈值方式,获得了超量下载阈值;实现了原型系统,经实际运行,数据采集准确,PDF超量下载判定有效。
使用开源软件进行二次开发构建PDF过量下载监测系统设计思想可行、原型实现可靠。通过使用FreeBSD、TCPDump、Java、JavaScript、Ngrep、PHP等开源软件、开发工具的组合,从而形成满足特定功能需求的PDF过量下载监测系统的原型。
遵循相应的版权授权[ 17],只要进行适当的二次开发,就可以较为快速地获得比较满意的应用系统。但开源软件不是完全免费的,除了遵守软件开发者的版权要求外,二次开发的成本、效率以及系统投入使用后的后继维护成本也是需要考虑的因素。
PDF过量下载监测系统的下一步开发工作,主要集中在三个方面:
(1)提高实时分析效率,以支持千兆网络上的网络数据包分析;
(2)自动阻断异常用户网络访问权,而不仅仅是预警,同时能够联动其他网络设备从而阻断异常访问(例如:通过实时写网络交换机ACL方式、添加网络防火墙黑名单等),制止过量下载行为;
(3)提供多角度的报表和统计,展示较全面的使用情况及趋势。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|