

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
结合商品标题和描述的在线评论特征词选择方法研究*
引用本文
梁昌勇, 王倩倩, 陆文星, 丁勇. 结合商品标题和描述的在线评论特征词选择方法研究* . 现代图书情报技术, 2011, 27(5): 49-54
Liang Changyong, Wang Qianqian, Lu Wenxing Ding Yong. The Online Comments Signature Words Selection with the Title and Description of Goods. 现代图书情报技术, 2011, 27(5): 49-54
Permissions
Liang Changyong, Wang Qianqian, Lu Wenxing Ding Yong. The Online Comments Signature Words Selection with the Title and Description of Goods. 现代图书情报技术, 2011, 27(5): 49-54
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
结合商品标题和描述的在线评论特征词选择方法研究*
摘要
目前,国内外对在线评论特征词的研究很少考虑到卖家发布的商品标题和描述信息,这使得数据挖掘过程盲目,挖掘结果准确率不高。采用聚类分析方法,把商品标题和描述考虑进来,搭建三层挖掘模型对在线评论进行研究和分析,提出定位L-K-中心点算法。实验结果证明,该方法能提高挖掘的准确率,减少挖掘时间。
关键词:
聚类; 特征词; 定位; K-中心点算法
中图分类号:TP391
The Online Comments Signature Words Selection with the Title and Description of Goods
Abstract
At present, title and description of goods are rarely considered in the research of online reviews at home and abroad, this makes the mining process blindly and mining results are not high accurate. In this article, the authors use the cluster analysis method, consider the title and description, set up a three-level mining model to analyze the online comments, at the same time, a location-clustering-algorithm is proposed. Experimental results show that the method improves the accuracy of mining and reduces the mining time.
Keyword:
Cluster analysis; Signature words; Location; K-center-algorithm
1 引 言
抽取产品特征词是为了更直接地了解用户最关心的产品功能及性能,进而便于下一步分析评论的褒贬性,帮助商家改进产品来满足用户的需求,同时对其他用户的购买提供参考帮助。已有的研究中,特征词的抽取分为自动提取和人工定义两类。在自动提取方面,主要使用词性标注、句法分析和文本模式等自然语言技术对评论进行分析,从中自动发现产品特征。如Nicholls等提出了一个文档频差自动识别特征选择方法,它可以帮助改善分类性能[ 1]。Li等提出了一种提取特征词与词资源的自动算法,用自然语言处理技术和统计方法,抽取网络评论中的特征词[ 2]。Yang等提到建立矢量模型和特征词提取,分析高发生率来抽取语义特征词[ 3]。余传明在抽取饮食行业的产品属性中,在现有产品属性识别方法不足的基础上,提出一种利用自组织映射进行属性识别的新方法,从中抽取饮食行业的产品属性[ 4]。文献[5]提到了一种基于伪反馈的XML查询扩展方法,将初始检索结果聚类, 获得与查询请求最为相关的文档簇,在文档簇中抽取特征词。在人工定义方面, Kobayashi等人工定义了汽车特征,每一个特征使用(Attribute, Subject,Value)这样的三元组来表示[ 6]。文献[7]中提到利用本体构建产品特征,得到了较为满意的结果。
人工方式对每个产品特征的抽取比较准确,但不具有可移植性和扩展性。当产品增加新属性时,又需要召集人员再次抽取;自动方式虽减少了人力,但对于大量评论,如何快速准确地挖掘出特征词仍是一个难题。目前的研究中无论是人工方式还是自动方式,都没有考虑到商品标题和描述,这使得挖掘过程盲目,迭代次数较多,挖掘结果准确率不高。研究发现,目前的电子商务网站(如“淘宝”、“卓越”)在商品的购买页面大多会有商品标题、商品描述和买家评论三部分内容,这三部分很好地对产品进行了说明,通常对消费者的购买起到关键性的作用。基于上述问题,笔者将商品标题和商品特征考虑进来,搭建三层挖掘模型,使特征词的选择变得有据可依,节约了挖掘时间,提高了挖掘的准确率。
2 L-K-中心点算法
本文采用自动挖掘的方式,聚类分析抽取产品特征词。K-中心点方法是聚类分析典型的划分方法。本文基于K-中心点算法提出了一种结合商品标题和描述的L-K-中心点聚类算法,对含有商品描述和标题的电子商务网站上的评论具有很好的适用性。
2.1 K-中心点算法介绍
K-中心点算法的基础思想是:随机地选择k个对象为初始中心点,其余的对象根据其与簇中心点的距离分配给最近的一个簇,然后重新计算每个簇中心点的目标函数值。这个过程不断重复,直到目标函数最小,算法收敛。通常采用平方误差准则,目标函数定义如下:
E= 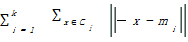
其中,E是所有对象与其所归属的簇中心点之间的偏差的总和;x是空间中的点,表示给定的数据对象;mi是簇Ci的平均值; 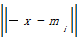
d= 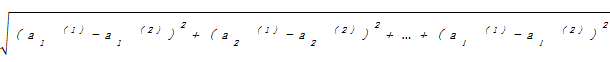
其中,d表示两个不同对象之间的距离;l表示每个对象的属性个数; 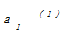
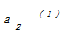
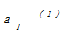
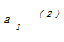

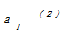
2.2 L-K-中心点算法
在K-中心点算法的基础上提出了L-K-中心点算法,即定位的Location-K-中心点算法,避免了上述局限性,即不必用户事先给出结果簇数目并能够减少计算代价,使其具有更好的适用性。
其基础思想是:将挖掘过程分为“商品标题”、“商品描述”、“商品评论”三层进行,逐层定位中心点,这就使得簇的数目k不必由用户事先指定。第一层的k个一级特征词作为第二层的初始中心点,将第二层的对象根据其与中心点的距离分配给最近的一个簇,重新计算每个簇中心点的目标函数值。迭代二层所有对象直到目标函数值最小,得到k个结果簇。在这k个结果簇中,采用人工标注的方法在每个簇中选择一个或多个代表词作为二级特征词。再次指定这些二级特征词作为第三层的初始中心点,步骤相同,算法收敛时得到三级特征词。同时挖掘的评论样本注重时间性,例如对最近一个月的评论进行挖掘,样本训练集新鲜,n和k的值也不会很大。
L-K-中心点算法挖掘过程如下:
(1)每一层都会从上一层的挖掘结果中得到k个中心点,不需要用户自己指定。
(2)每一层反复用非代表对象来代替代表对象,以改进聚类质量。
(3)聚类质量用目标函数来估算,度量对象与其参照对象之间的平均相异度。
为了判断非代表对象Orandom是否是当前一个代表对象Oj的好的替代,有4种情况需要被考虑[ 8]:
(1)p当前隶属于中心点对象Oj,如果Oj被Orandom所替代作为中心点,且p离一个Oi最近,i≠j,那么p被重新分配给Oi。
(2)p当前隶属于中心点对象Oj,如果Oj被Orandom所替代作为一个中心点,且p离一个Orandom最近,那么p被重新分配给Orandom。
(3)p当前隶属于中心点对象Oi,i≠j,如果Oj被Orandom所替代作为一个中心点,而p仍离Oi最近,那么对象的隶属度不发生变化。
(4)p当前隶属于中心点对象Oi,i≠j,如果Oj被Orandom所替代作为一个中心点,且p离Orandom最近,那么p被重新分配给Orandom。
每当重新分配发生时,误差所产生的差别会对代价函数有影响。如果总代价是负的,那么实际的平方-误差将会减少,Oj可以被Orandom替代。如果代价是正的,则当前的中心点Oj被认为是可接受的,在本次迭代中没有发生变化。其中,“p离Orandom最近”指的是对象与簇的距离最小,在距离空间中采用欧氏距离的平方(p=2)来度量。
L-K-心中点算法具体描述如下:
输入:结果簇数目k(由上一层挖掘结果指定)
输出:k个结果簇,使得所有对象与其最近中心点的相异度总和最小
方法:
①选取上一层特征词k个对象作为初始中心点
②Repeat
③指派每个剩余的对象给离它最近的中心点所代表的簇
④随机选定非代表对象Orandom,当前代表对象Oj
⑤计算用Orandom代替Oj的总代价S
⑥if S<0,then Orandom代替Oj,形成新的k个中心点的集合
⑦Until 不发生变化,所有对象均找到自己的簇
3 三层特征词的抽取流程
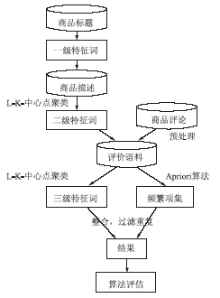
三层特征词的抽取流程如图1所示:
 | 图1 评价特征词挖掘流程 |
3.1 商品标题中一级特征词的抽取
对商品标题用中国科学院计算技术研究所提供的单词切分器进行切分,保留描述商品特征的词,称为一级特征词,作为第二层商品描述部分聚类算法的中心点。例如商品的标题“苏格兰风情格子荷叶肩蝴蝶腰带羊毛呢连衣裙”,得到一级特征词“格子/n. 连衣裙/n. 荷叶肩/n. 腰带/n. 羊毛/n. 呢/n.”。
3.2 商品描述中二级特征词的抽取
商品描述是卖家对商品进行的详细介绍,如服装类,一般对用料、材质、做工等进行说明。此类说明是非常必要的,便于购买者了解商品的性能,对于消除买卖双方信息不对称具有一定的贡献。
此过程是用单词切分器对商品描述文本进行切分,切分出的单词运用L-K-中心点算法进行聚类。用事先选定的一级特征词作为初始中心点,算法迭代找出新的中心点,输出结果簇。结果簇很好地对产品属性进行了聚类,此时只需对每个簇选择一个代表词进行人工标注来作为二级特征词即可,同时作为下一层聚类的初始中心点。
3.3 商品评价中三级特征词的抽取及频繁项集的挖掘
本文采用Java语言,Eclipse软件编写网络爬虫在网页中提取商品评论信息,进行预处理形成评价语料库。特征词的抽取分两步进行:
(1)基于二级特征词用L-K-心中点算法对评价语料进行聚类。例如选择 “羊毛、呢子、手感、荷叶边、肩、腰、金属扣、袖子、格子、连衣裙”这10个二级特征词作为第三层聚类的初始中心点,k=10。同理,算法收敛时输出10个簇,得出三级特征词。
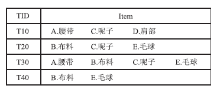
(2)运用Apriori算法,抽取语料中频繁项,挖掘出的频繁项经过频率过滤和名词剪枝,得到评价对象集,作为新的特征词。例如数据库中有4个事务,即|D|=4,如图2所示:
 | 图2 商品属性事务 |
找出需要的频繁项集步骤如下:
(1)每个项都是候选1项集的集合C1的成员,扫描所有事务,对每个项的出现次数进行计算。
(2)假定最小支持度是2,可以确定频繁1项集的集合L1。它由最小支持度的候选1项集组成。
(3)算法使用L1连接 L1产生候选2项集的集合C2。C2由 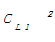
(4)计算C2中每个候选项集的支持计数。确定频繁2项集的集合L2。
(5)根据Apriori性质,频繁项集的所有子集必须是频繁的,这样仅剩{ B.布料;C.呢子;E.毛球}。
算法终止,找出了所有的频繁项集,如图3所示:
 | 图3 商品属性频繁项集 |
将得到的频繁项集和三级特征词整合,消除重复特征词,建立特征词数据库,以备结果评估。
3.4 挖掘结果的评估方法
产品属性的判断相当于对产品特征词进行二维分类,即真实属性还是非真实属性,本文采用二维列联表,如表1所示:
| 表1 产品属性评估方法性能的列联表 |
指标用查准率和查全率来表示:
查准率(precision)=A/(A+B)
查全率(recall)=A/(A+C)
4 实验过程
本文以淘宝商品评论为特征词的挖掘样本,选择某连衣裙商品进行L-K-中心点算法的聚类实验。实验分4步进行:
(1)从商品标题中获取一级特征词
淘宝中商品的标题都是30字以内,包含许多产品特征(如颜色、款式、材料)、性能(如:舒适、保暖、防寒)的短文本。这种短文本一般不具有严格的语法,大多为名词和形容词的堆砌。因此采用中国科学院计算技术研究所的切分器切分以后能够很容易地挑出一级特征词。该步实验结果为6个一级特征词,如表2所示:
| 表2 一级特征词结果 |
(2)从商品描述中获取二级特征词
实验中该商品的描述如下:“本商品采用羊毛呢子面料,让衣服穿着更加保暖,胸前点缀着两排金属扣,雅致而不单调……同时料子手感柔软,很上档次。”同样切分出的名词有:羊毛/n. 呢子/n. 面料/n. 衣服/n. 胸前/n. 金属扣/n. 款式/n. 职业/n. 女性/n. 两肩/n. 褶皱/n. 荷叶边/n. 作用/n. 连衣裙/n. 腰部/n. 蝴蝶/n. 腰带/n. 效果/n. 曲线/n……由于数据使用不同的尺度度量,在使用欧氏距离之前先进行归一化处理,属性值归一化定义为:
ai= 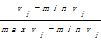
其中,ai是指某个对象的属性i,vi是属性i的真实值,最大属性值maxvi和最小属性值minvi是从训练集实例中获得的。选择表2中的6个一级特征词作为此步聚类的初始中心点。算法收敛时得到6个结果簇,不同的结果簇会有不同的属性词,同时属性词的个数也不同。在个数较少的簇用人工标注的方法选择一个词作为此簇的代表,在个数较多的簇中可以选择2个及2个以上的代表词,目的是保证选择出的代表词能够很好地反映出第二层即商品描述层的属性特征。将这些代表词作为二级特征词。结果如表3所示:
| 表3 二级特征词L-K-心中点算法结果 |
(3)从商品评论中获取三级特征词
本实验用网络爬虫得到部分评论,内容如下:
“1.路边摊一样的次品,拿到手衣衣就毛毛球球的。这是最晕的一件,打着羊头卖狗肉;2.买的XL,衣服腰有点肥了,其他很合适,跟图片一样,总体还不错,很有独特的感觉;3.裙子好看,不过有些地方起了一点点毛球,关系不大,腰带有一处烂了,可能是掉线吧!……”
在实验当中,笔者对商品的2 380条评价文本进行单词切分和聚类对象的归一化处理。然后用L-K-中心点算法进行聚类分析,初始中心点为表3的12个二级特征词,k=12,进行迭代计算,直至算法收敛,得到三级特征词如表4所示:
| 表4 三级特征词L-K-心中点算法结果 |
(4)从商品评论中获取频繁项集
将评价语料中切分出的单词存入数据库,用Apriori算法逐层搜索迭代,k-项集用于探索(k+1)-项集。每一次迭代都扫描一次数据库,最终找出所有频繁项集。
将抽取出的频繁项集和三级特征词进行比较,消除重复词,最终得出满意的结果。
5 实验结果分析
5.1 语料数据
本文针对一种典型电子商务网站——淘宝网中的服装类产品连衣裙的在线评论进行实验研究。淘宝类网站的结构规范,在每个商品页面都需要含有商品标题和商品描述信息,在电子商务领域应用比较广泛。从淘宝网站中用网络爬虫下载了2 380条评论连衣裙的数据,对于产品特征挖掘实验的参照属性采用自动聚类方法:从商品标题入手,逐层建立挖掘模型,运用L-K-中心点算法和Apriori算法聚类分析,对于评价语料随机选取200个句子作为训练集合,100个句子作为测试集合。
5.2 实验结果
(1)连衣裙评论的产品特征词挖掘结果
对该商品的2 380条评论挖掘出的产品特征词结果如表5所示:
| 表5 连衣裙评论所挖掘出的属性(按照关注程度排名) |
表5列出了按照关注程度排名前5位的产品特征。表6为产品特征挖掘性能列联表。可以计算出挖掘性能查全率为89.2%,查准率为70.2%。
| 表6 连衣裙评论挖掘性能的列联表 |
(2)本研究算法和K-中心点算法比较
为了综合评价结果,利用了F-score值:
F-score=(2×recall×precision)/(recall+precision)
对产品评论的特征词挖掘结果对比,如表7所示:
| 表7 针对产品评论特征挖掘结果比较 |
通过比较可以看到本文研究结果的查全率、查准率都优于K-中心点算法,在同类研究中具有一定的有效性,反映了L-K-中心点算法在抽取商品特征词方面有着较好的挖掘性能,特别是对于含有商品标题和描述的在线评论更是提高了挖掘的准确性。这是由于商品标题和商品描述是卖家发布的,商品评论是买家发布的,传统的挖掘过程是仅仅针对买家的评论进行特征词的抽取,这使得卖家的信息很少被考虑到,从而导致商品属性会有些遗漏和疏忽,导致查准率和查全率不高。本文的方法挖掘的特征词结果综合了买家和卖家的信息,因而比较全面和完善,查全率和查准率也因此得到提高。
(3)时间性对比实验
笔者将L-K-中心点算法与K-中心点算法进行消耗时间的对比实验。对该商品的2 380条评论分成11组进行计时统计。每扫描200条评论统计一次,时间记录单位为毫秒。耗费时间Matlab代码如图4所示:
 | 图4 评论耗费时间Matlab代码 |
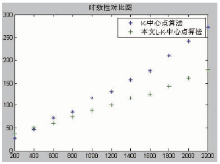
L-K-中心点算法与K-中心点算法的时间对比结果,如图5所示:
 | 图5 耗费时间二维线性对比图 |
对图5进行分析得到本文的L-K-中心点算法消耗的时间较少,在开始阶段由于需要扫描商品标题和描述,时间对比相差不大,600条及以后的评论挖掘时间上远远小于K-中心点算法。这是由于每层迭代的中心点指定,减少了迭代次数,缩短了挖掘时间。
6 结 语
实验结果表明,结合商品标题和描述的特征词抽取算法,能够快速且准确地找到评价语料中的产品特征词,较之以前的方法在准确率和效率上有很大提高,尤其对于以淘宝网为代表的电子商务网站上的含有商品标题和描述的商品评论更为适用。特征词选择的准确性直接影响着商品评论的语义倾向性。如何对评论的语义倾向性进行分析,得出特征词的极性从而分析评论的褒贬性将是下一步的研究工作。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|