

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
语义Web模式下综合科技资源的关联策略研究*
引用本文
王思丽, 马建霞, 祝忠明, 张秀秀, 马建玲. 语义Web模式下综合科技资源的关联策略研究* . 现代图书情报技术, 2011, 27(6): 32-38
Wang Sili, Ma Jianxia, Zhu Zhongming, Zhang Xiuxiu, Ma Jianling. Study on the Linked Method of the Integrated Resources in Semantic Web Patterns. 现代图书情报技术, 2011, 27(6): 32-38
Permissions
Wang Sili, Ma Jianxia, Zhu Zhongming, Zhang Xiuxiu, Ma Jianling. Study on the Linked Method of the Integrated Resources in Semantic Web Patterns. 现代图书情报技术, 2011, 27(6): 32-38
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
语义Web模式下综合科技资源的关联策略研究*
摘要
在开发综合科技资源集成登记系统的实践基础上,研究综合科技资源的关联策略,针对其在语义化方面的局限性,提出一种利用D2RQ组件将综合科技资源的关系数据源公开为RDF接口,进而利用SPARQL端点查询技术将RDF接口公开为Web服务的优化方案。试验证明,该方案合理可行,可为综合数字资源体系建设的未来发展提供思路。
关键词:
语义Web; 综合科技资源; 关联策略; RDF; D2RQ; SPARQL
中图分类号:G250
Study on the Linked Method of the Integrated Resources in Semantic Web Patterns
Abstract
Based on the practices for developing integrated resources and services metadata registry,the paper studies on the linked method the integrated resources,and proposes an optimized method using D2RQ to expose relational database of integrated resources as RDF interface, then uses SPARQL points to query the RDF interface and exposes it as Web service.In fact,the method can provide a good way for the future development of constructing integrated digital resources system with its rationality and feasibility.
Keyword:
Semantic Web; Integrated resources; Linked method; RDF; D2RQ; SPARQL
1 引 言
以数据为中心,将语义置于数据中,是语义Web模式的核心视角所在[ 1]。它得到了国内外数字图书馆界的广泛关注和认可,并陆续建设了一些示范性试验系统。当前,具有代表性的资源登记服务系统主要有澳大利亚的ANDS(Australian National Data Service)[ 2]、英国的IESR(Information Environment Service Registry)[ 3]、法国的Michael(Multilingual Inventory of Cultural Heritage in Europe)项目[ 4]、美国的OCKHAM-DLSR(Ockham Digital Library Services Registry)[ 5]以及我国的OCSR(Open Collection and Service Registry)[ 6]等。这些系统的共同点是都支持各类元数据的登记、发布、检索和浏览,并提供了相关轻量级协议的访问接口,在一定程度上方便了资源与服务的发布和管理。但从实际的应用和推广程度来看,这些系统大多还停留在对资源进行二维描述其基本属性关系的阶段,并没有进一步深度挖掘各类资源间的关联关系,无有效持久的工作流管理机制[ 7]。因而,在语义Web对资源知识化和集成化组织的更高要求之下,存在着许多亟待解决的难题。综合科技资源集成登记服务系统(Integrated Resources and Services Registry,IRSR),是中国科学院国家科学图书馆“十二五”战略规划布局中综合数字资源体系建设的先导性项目,其预期目标是构建集中式资源集合元数据登记系统,为综合科技资源的语义化标注和管理提供可靠平台和技术支撑,为实现各类资源基于语义化的自动发现和关联扩展奠定基础。目前,该系统已能够支持对多种类型元数据的登记注册和管理,同时与第三方系统进行互操作的重要接口,如 Web Service、OAI-PMH、SRU等,也正在持续开发和完善中。
本文在开发IRSR的实践基础上,从语义Web架构模式视角出发,结合当前数字资源知识化组织建设和服务的应用需求,通过分析IRSR的数据模型和相关的实体关系,重点研究综合科技资源的关联策略,并针对其局限性给出了实际的优化方案,从而为综合数字资源体系建设的未来发展提供思路。
2 IRSR的关联策略分析
2.1 IRSR的核心数据模型
IRSR的数据模型继承了DLSR(Digital Library Service Registry)[ 8]的标准化服务描述和共享使用方案,重用并扩展定制了DC、IESR、OCSR等元数据标准,形成了多维度元数据应用规范和编码体系,如表1所示:
| 表1 IRSR基本编码体系 |
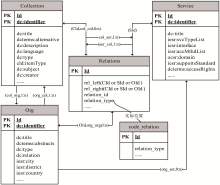
该模型可抽象为由资源(Collection)、机构(Org)、服务(Service)、关系(Relations)4个核心实体元素集共同构成的元数据描述框架,如图1所示:
 | 图1 IRSR核心数据模型 |
(1)资源是指综合科技集合类资源,除了包含一些资源的基本描述信息如资源题名、交替题名、语种等之外,还包含一些版权声明、访问权限等使用信息。具体来说,共有8种主体资源集合类型:软件、资源集、文本集合、数据集、事件、图像/多媒体、交互资源、服务,与其相关联的资源内容类型有65种,每一种资源实体都被归入一种或多种相应的学科主题类型,采用中国图书馆分类法,目前共分为16个一级学科和147个二级学科,同资源内容类型一样可根据实际需求进行二次扩展。
(2)资源、机构、服务三类实体既可单独存在,又可作为彼此的检索点,可视为一个可重用的功能组件。其中资源实体是三类实体的核心,每一种资源都给出了其对应的基本服务参数,如服务类型、服务接口地址、访问控制方式及支持协议等。IRSR中涉及的服务类型主要有9种:检索服务、咨询服务、文献传递/馆际互借服务、接口服务、个性化服务、委托服务、元数据提供/收割服务、订阅服务、保存服务。同一类服务可以支持多种访问方式和协议。可根据资源实体浏览相关服务,也可根据服务的基本参数查询和使用相关服务。
(3)机构实体同样不仅有自己的基本属性,如名称、机构URL、所在地区、国家,可以被单独进行检索和浏览外,最重要的一个特性是作为资源、服务的管理者角色而存在。IRSR中划分的机构类型有10种:研究院/所/中心/、大学/学院/系、实验室/野外台站、学/协会、政府机构、国际组织/非盈利组织、图书馆/信息中心、博物馆/档案馆、个人、企业/公司。某种程度上来讲,机构和服务的存在是从管理的角度为资源提供多样性的捕获和发现途径。
(4)关系实体,是一种规则,是关联资源、机构和服务实体的纽带。概括来说,一个资源可以拥有0个或多个子集、超集及相关集合,具有一个或多个创建机构、所属机构和资助机构,具有至少一个服务。同理,机构可以拥有、创建和资助一个或多个资源,管理一个或多个服务。一个服务至少服务于一个资源。IRSR预定义了13种关系结构和6组关系类型标识。这13种关系包含一组自反的关系类型(相关集合)和6对互逆的反向关系组(由pair_id标出)。具体描述如表2所示:
| 表2 IRSR基本关联关系 |
2.2 IRSR关联策略的优点
通过分析相关数据模型和实体关系,可以发现与先前的登记系统相比,IRSR有了很大的改进,主要可以总结为以下两个方面:
(1)以实际的用户群需求为导向,在对综合科技资源进行描述的时候,除了遵循和定制文献资源描述领域的基本行业标准,揭示了资源自身的一些基本属性信息之外,还对资源相关的实体信息进行了多维度的关联和扩展,如提供了相关资源集合、所属的机构、资助的机构、服务的对象信息等。而相关联的实体信息在物理上或逻辑上与资源实体信息都是相对独立的,资源实体仅提供了一个或一组关联指针(Handle标识)作为定位信息,指向已知的关联实体的详细信息点。这样不仅能够方便元数据管理者或发布者更加全面地描述、重用和更新资源,还能提高用户发现资源和选择最合适的服务的效率。
(2)面向资源可重用性,独立封装了关系实体。关系实体是IRSR预定义的实体关联规则,封装了资源、机构、服务实体之间的关系信息,却并不显式依赖于这三类实体。关系实体只存储了这三类实体间相互指向的指针标识符以及对应的关系类型。这一做法从数据模型算法设计的角度看,避免了数据冗余,提高了数据更新的速度。对元数据管理者而言,同一资源如果服务于多种服务类型,或同一资源被多个机构所拥有,可以直接通过添加关系指针标识符进行引用,而不用重复描述,降低了资源重用的复杂性,提高了系统的整体性能。
2.3 IRSR关联策略的局限性
尽管上述的资源关联策略已在IRSR系统中得到了很好地体现和应用,相关的评估和测试也表明了其策略的合理性,但依然存在着一定的局限性。语义Web模式的另一个技术核心是机器可读、机器可理解[ 9]。如何将IRSR的数据转换为带语义的关联数据(即RDF数据),使之能够通过语义Web数据之间的逻辑和规则进行推理,支持一定程度的替换和定制,从而在机器可读层面提高综合科技资源被访问和调用的自动化处理能力,同时增强IRSR与其他系统平台的互操作性,是一个问题。
3 综合科技资源关联策略的优化
针对上述问题,结合IRSR进行Web测试,本文给出了综合科技资源关联策略的优化方案。
3.1 引入D2RQ 组件
IRSR使用的是MySQL关系型数据库,可以在多用户和高强度数据负荷的条件下提供可伸缩的性能,但并不满足语义Web关联开放的基本原则。然而语义Web的实质并不是颠覆这些已有的数据方法,相反,它主要是提供RDF这样一种灵活的、可扩展的数据模型表示工具[ 10],使资源的知识组织和语义关联更为容易。
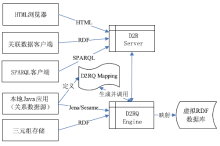
D2RQ就是其中最常用的组件之一,其主体框架[ 11]如图2所示:
 | 图2 D2RQ组件的主体框架[ 11] |
D2RQ主要包括D2RQ Server、D2RQ Engine以及D2RQ Mapping[ 11]。
(1)D2RQ Server是一个HTTP Server,它的主要功能是提供对RDF数据的查询访问接口,以供上层的RDF浏览器、SPARQL查询客户端或传统的HTML浏览器调用。
(2)D2RQ Engine的主要功能是使用一个可定制的D2RQ Mapping文件将关系型数据库中的数据转换成RDF格式。它并不是将关系型数据库发布成真实的RDF数据,而是使用D2RQ Mapping文件定义的规则将其映射成虚拟的RDF格式。
(3)D2RQ Mapping文件的作用是在访问关系型数据时将RDF数据的查询语言SPARQL转换为RDB数据的查询语言SQL,并将SQL查询结果转换为RDF三元组或SPARQL查询结果。
目前D2RQ支持Oracle、DB2、MySQL、PostgreSQL等几乎所有的主流关系型数据库。
3.2 利用D2RQ将IRSR关系数据源公开为RDF接口
使用D2RQ将关系数据库公开为RDF接口主要有两个步骤:
(1)定义并生成映射文件。
该映射文件用来定义数据库中的表和列与本体中的类和属性进行映射的规则,它并不生成真正的本体,主要是隐式定义并使用了一个类和属性集合的vocab前缀,等效于本体的命名空间。主要通过调用D2RQ组件Java类的generate_mapping方法实现,具体如下:
generate-mapping
-u root
-p ****
-d com.mysql.jdbc.driver
-o irsr.n3
jdbc:mysql://localhost:3306/irsr
其中,-u表示数据库用户名;-p是数据库登录密码;-d是数据库驱动类名称,不同的数据库驱动格式不同,本项目是以MySQL为例;-o是D2RQ输出的映射文件名称,后缀指定为n3;最后一个参数设置了所映射的MySQL数据库的路径和名称。
生成的映射文件如下:
@prefix map:
@prefix db: <> .
@prefix vocab:
@prefix rdf:
@prefix rdfs:
@prefix xsd:
@prefix d2rq:
@prefix jdbc:
map:database a d2rq:Database;
d2rq:jdbcDriver "com.mysql.jdbc.Driver";
d2rq:jdbcDSN "jdbc:mysql://localhost:3306/irsr ";
d2rq:username "root";
d2rq:password "***";
jdbc:autoReconnect "true";
jdbc:zeroDateTimeBehavior "convertToNull";
.
#Table collection
map:collection a d2rq:ClassMap;
d2rq:dataStorage map:database;
d2rq:uriPattern "collection/@@collection.Id@@";
d2rq:class vocab:collection;
d2rq:classDefinitionLabel "collection";
.
map:collection__label a d2rq:PropertyBridge;
d2rq:belongsToClassMap map:collection;
d2rq:property rdfs:label;
d2rq:pattern "collection @@collection.Id@@";
.
map:collection_Id a d2rq:PropertyBridge;
d2rq:belongsToClassMap map:collection;
d2rq:property vocab:collection_Id;
d2rq:propertyDefinitionLabel "collection Id";
d2rq:column "collection.Id";
d2rq:datatype xsd:int;
.
map:collection_dc_identifier a d2rq:PropertyBridge;
d2rq:belongsToClassMap map:collection;
d2rq:property vocab:collection_dc_identifier;
d2rq:propertyDefinitionLabel "collection dc_identifier";
d2rq:column "collection.dc_identifier";
.
……
其中,d2rq:uriPattern提供一个URI标识,用来指导生成所实例化实体的真实URI,一般由关系数据库的实体表名和对应的主键组成;d2rq:class表示该映射类所对应的实体类,其取值一般来自所应用的OWL 本体或RDFS Schema,也可以根据数据模型自定义新的class,本例中的class是取自IRSR系统中的collection实体;d2rq:PropertyBridge代表OWL本体或ORDFS Schema中类的属性,它具体映射到关系数据库中数据表的某一列。
(2)调用映射文件对关系数据库进行转换与访问。
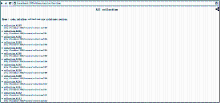
调用D2RQ组件Java类的d2r_server方法:d2r-server irsr.n3,启动D2R Server,最终可将IRSR关系数据库中的相关实体collection、org、service转换为虚拟RDF视图的格式进行访问,服务端口为2020,如图3所示:
 | 图3 IRSR关系数据库实体的RDF Schema |
点击collection,可以看到已经将其资源数据实例化为一组关联的URI标识,如图4所示:
 | 图4 collection实体的URI标识 |
任意浏览其中的一个collection URI,例如collection 1001,详细信息如图5所示:
 | 图5 collection #1001的RDF关联视图 |
最终构建的RDF接口可满足如下基本条件:
(1)接口能够接收一个查询或者一个对返回数据的说明;
(2)能够生成使用一个或多个一致的隐性本体描述的合法RDF;
(3)能够生成可以准确反映底层数据源结构的实体关系。
3.3 利用SPARQL端点技术查询RDF接口并公开为Web服务 在这里要用到Jena语义Web框架,因为它提供了调用D2RQ的强大的API以及基于RDF和SPARQL语言的Java编程环境[ 12]。具体实现时,需要在D2R Server端建立一个基于Query方法的查询类,读取irsr.n3映射文件和D2RQ的虚拟RDF模型,构造符合SPARQL语法的查询语句,最后以三元组方式提供可视化的查询结果,并可定制为XML、XML+XSLT、JSON多种Web服务格式。以collection实体为例,查询其部分实例信息,基本SPARQL语法如下:
PREFIX rdfs:
PREFIX db:
PREFIX owl:
PREFIX xsd:
PREFIX map:
PREFIX rdf:
PREFIX vocab: http://localhost:2020/vocab/resource/
SELECT ?dc_identifier ?dc_title ?dc_creator WHERE {
?collection vocab:collection_dc_identifier?dc_identifier.
?collection vocab:collection_dc_title?dc_title.
?collection vocab:collection_dc_creator?dc_creator.
} LIMIT 20
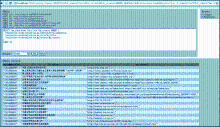
查询结果如图6所示:
 | 图6 SPARQL查询RDF接口的结果 |
将Results定制为XML格式,示例如下:
……
4 结 语
实际的测试和应用表明,使用上述策略的优点是:
(1)将新的数据源关联到IRSR系统后,只需要进行极少的配置改动,而且映射文件可根据关系数据库的实体模型自动生成。
(2)提供了SPARQL端点服务,方便第三方用户尤其是机器用户的自动调用。
(3)能够支持一定程度的语义查询和推理。
该策略也存在着一定的缺陷:
(1)生成的RDF接口几乎是关系数据库结构的一个精确映像,可能包含一些管理元数据方面的信息,而这些数据一般并不为用户所需要。
(2)SPARQL端点技术要求用户对底层的关系数据库模式有较为细致的了解,才能构造可用的查询。因而使用对象可能会局限于科研人员、教师、学生等。
(3)关系数据库数据模式的变化会导致映射文件的重新生成和查询的改变。
在下一步的工作中,将考虑引入领域知识模型,定制更为标准的本体转换规则,以适应语义Web更为复杂的语义查询和推理要求,从而推动综合科技资源语义化知识服务机制的快速实现。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|