{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Solr的中文农业期刊文摘检索系统的构建研究*
引用本文
鲜国建, 赵瑞雪. 基于Solr的中文农业期刊文摘检索系统的构建研究* . 现代图书情报技术, 2011, 27(6): 51-58
Xian Guojian, Zhao Ruixue. Research and Implementation of Chinese Agricultural Journals’ Abstracts Retrieval System Based on Solr. 现代图书情报技术, 2011, 27(6): 51-58
Permissions
Xian Guojian, Zhao Ruixue. Research and Implementation of Chinese Agricultural Journals’ Abstracts Retrieval System Based on Solr. 现代图书情报技术, 2011, 27(6): 51-58
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
基于Solr的中文农业期刊文摘检索系统的构建研究*
摘要
简要介绍企业级开源全文检索系统Solr的发展历史、系统架构和特色功能,设计基于Solr的中文农业期刊文摘检索系统的体系架构,通过对Solr的本地化部署、索引文件创建、用户交互界面的设计与实现构建原型系统。该系统初步具备多入口高效检索、分面导航检索、相似文献查找等功能。
关键词:
开源软件; Solr; Lucene; 数字图书馆; 检索系统
中图分类号:TP393
Research and Implementation of Chinese Agricultural Journals’ Abstracts Retrieval System Based on Solr
Abstract
This paper gives a brief introduction about the history, architecture and features of the open source software Solr, and designs the architecture of the Chinese agricultural journals' abstracts retrieval system based on Solr. With the steps of installing and configuring the Solr locally, creating index data and designing and realizing the user interface, the retrieval prototype system is built up, which has functions such as multi-points searching, faceted navigation and retrieval, similar documents search and so on.
Keyword:
Open source software; Solr; Lucene; Digital library; Retrieval system
1 引 言
近年来,开源软件(Open Source Software)作为一种新兴的软件模式在世界范围内迅速发展,它所倡导的自由、共享的理念深入人心[ 1]。伴随着数字图书馆日益开放分布的建设环境,越来越多的数字图书馆系统采用开源软件的模式来开发[ 2]。基于开源软件,有助于图书馆在有限的技术力量和资金投入下,根据自身业务需要进行功能定制和增值开发,更好地进行资源整合,为读者提供多层次、多类型、多方面的信息服务,从而打破商业软件对图书馆技术发展的束缚,促使数字图书馆建设朝着低成本、高性能、短开发周期的目标发展[ 3],并能有效提高图书馆的创新能力和服务能力。
数字图书馆系统开源软件在一定程度上反映了当前数字图书馆理论与实践的最新发展水平[ 4]。在全球数字图书馆的研究和建设实践过程中,出现了很多面向数字图书馆业务流程和应用服务的开源软件,如联机公共目录查询系统SOPAC[ 5]、机构仓储系统DSpace[ 6]、个性化图书馆软件MyLibrary[ 7]、学科信息门户软件SPT[ 8]、领域知识环境VIVO[ 9]、数字图书馆软件工具包Greenstone[ 10]、内容管理工具Drupal[ 11]、知识交流系统JSPWiki[ 12]、全文检索系统Solr、网络信息资源采集与保存工具Heritrix[ 13]等。这些开源软件为数字图书馆提供强大的技术支持和功能支撑。我国数字图书馆系统的构建,应充分开发和利用这些优秀的开源软件,提高数字图书馆建设的起点和整体水平[ 14]。
本文在简要介绍开源的全文检索引擎Solr的基础上,初步设计并实现了基于Solr的检索原型系统,实现了对国家农业图书馆中文农业期刊文摘数据的高效查询和浏览。
2 Solr概述
2.1 发展历史
Solr在全文索引工具Lucene的基础上进行了封装和功能扩展,是一个高性能的、可独立运行的企业级全文搜索引擎服务器,能为多种数据格式提供索引、检索及分面浏览的功能。Solr最初由CNET于2004年设计开发,旨在提供相关度较高的分面检索平台,后来CNET将代码捐赠给Apache进行开源,Solr于2006年1月成为Apache的孵化器项目,并于2007年1月正式成为Apache的子项目,先后共发布了Solr 1.1.0、1.2、1.3、1.4、1.4.1等版本,目前的最新版为2011年3月发布的Solr 3.1,该版本包含了最新的索引工具Lucene 3.1[ 15]。
2.2 体系架构
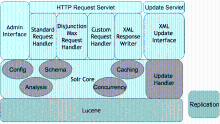
Solr在Lucene的基础上,重点加强了对于数据之间内在关联关系的挖掘。作为一个完整的全文检索服务系统,Solr具有良好的体系架构[ 16],如图1所示:
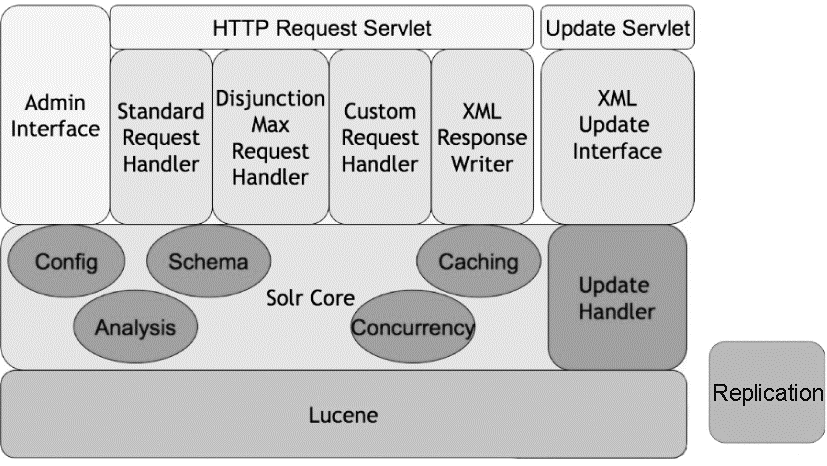 | 图1 Solr的体系架构[ 16] |
(1)上层由管理员界面(Admin Interface)、HTTP请求处理器(HTTP Request Servlet)和索引更新处理器(Update Servlet)三大模块组成。管理员、用户和其他系统基于对外提供服务的HTTP接口,向Solr发送 HTTP 请求,HTTP请求处理器根据接受到的不同请求,确定要使用的SolrRequestHandler,然后通过Solr核心层处理请求,并以XML、JSON等格式返回请求结果。索引更新处理器主要提供XML数据的导入界面。
(2)中间层为Solr的核心层,由多个独立模块组成,负责整个系统配置(Config)和索引参数(Schema)的加载与解析、索引文档及查询请求的分析(Analysis),提供建立索引和读取索引的并发控制(Concurrency)和分面、文档缓存机制(Caching)。更新处理器(Update Handler)负责对XML、CSV和数据库等来源的索引请求进行处理。
(3)底层为全文索引工具Lucene,负责具体的文本分析、创建索引,并对索引文件进行高效查询。此外索引复制功能(Replication)是一个独立的模块,可以通过脚本程序、异步处理程序等完成,用于支持分布式索引和检索。
2.3 特色功能
Solr具备众多企业级功能特性,如高性能的全文搜索、基于XML的灵活配置和管理、支持多客户端语言、索引复制、查询缓存、对富文本的解析与索引、日志记录以及可扩展的插件体系等。Solr以Lucene的良好索引性能为基础,提供了分面检索、高亮显示、相似文献检索、拼写检查与纠错等特色功能。
Solr在分面检索方面进行了专门的优化处理,通过自建的集合类来提供高效的分面结果计算,实现了分面检索组件FacetComponent。在用户发出分面检索请求后,Solr生成两个检索结果集:有序的结果集和无序的全部结果集合。其中,有序结果集默认按相关度进行排序输出,即通常情况下返回的检索结果。而在无序的全部结果集合中,通过计算不同集合之间的交集来统计不同面下的记录数,以此来提供快速直接的分面检索与导航功能。
Solr使用MoreLikeThisComponent(MLT)和 MoreLikeThisHandler实现了查找相似文献的功能。在发出获取相似文献请求时,一般需要附加一些参数(如mlt.count、mlt.fl等)。MLT 要求进行相似查找的字段(如题名和关键词)被储存或使用检索词向量。检索词向量以文档为中心的方式储存信息,可以提高检索性能,只需在Schema.xml 文件的对应字段
3 基于Solr的中文农业期刊文摘检索系统设计
3.1 系统总体功能
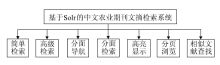
为适应和满足农业科研人员对网络化、数字化信息资源的强烈需求,国家农业图书馆经过多年的数字化建设,已累积加工中、外文农业科技期刊文摘数据400余万条,形成了专业领域集中、元数据完整规范、学术价值较高的中外文农业科技期刊文摘数据库。基于高性能的Solr构建中文农业期刊文摘检索系统,可以对文摘进行深度开发和综合利用,为我国农业科研人员提供稳定、高效的检索服务平台,该原型系统的功能结构如图2所示:
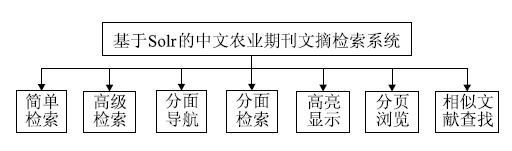 | 图2 系统功能结构图 |
该系统的总体功能主要包括7个部分。其中,简单检索是直接提供对所有字段的检索;高级检索则是提供对文摘、题名、作者、关键词、期刊名称、ISSN、年、卷、期、页码等进行多入口的组合检索;分面导航是从关键词、作者、期刊名称、年份这4个维度对检索结果进行聚类统计并提供导航,当用户点击某项链接时,将对当前结果进行分面过滤,实现分面检索;为提高用户界面的友好性和易用性,提供检索结果的高亮显示和分页浏览功能;为帮助获得更多有价值的文献,在每条检索结果中提供查找相似文献的功能。
3.2 系统体系架构
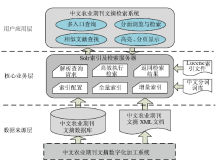
基于Solr的中文农业期刊文摘检索系统的体系架构,如图3所示:
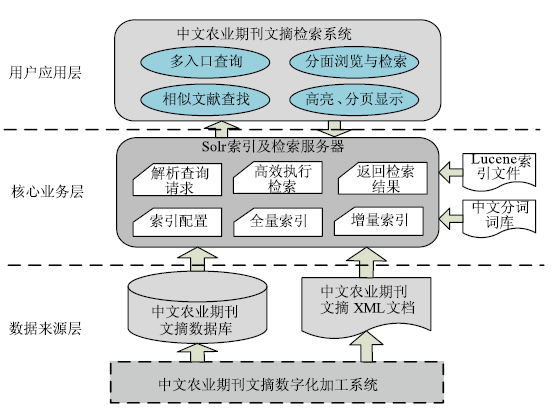 | 图3 中文农业期刊文摘检索系统体系架构 |
(1)最底层为数据来源层,为最大程度减少对数字化加工业务系统的影响,本系统在加工系统外建立索引。在获取来源数据时支持两种方式:直接从加工系统的底层数据库获取数据;或将加工系统中的数据导出为规范化的XML文档。
(2)核心业务层主要是基于Solr提供的强大功能,进行系统参数及索引参数的动态配置与管理,接受来自文摘加工系统的文摘数据,基于中文分词器和词库进行全量和增量索引,并生成Lucene索引文件。同时,该层还负责对来自应用层的用户查询请求进行解析,高性能地执行检索,并将检索结果以标准的XML或JSON格式返回。
(3)用户应用层是本系统需要基于Solr进行二次开发的重点,主要是提供用户界面,实现用户与系统的交互功能,支持用户灵活地输入查询条件,对检索结果进行动态的分面导航、过滤,以及相似文献查找、检索结果的高亮、分页显示等。
4 中文农业期刊文摘检索系统的构建
4.1 Solr的本地化安装部署
Solr必须运行在Java1.5 或更高版本的Java虚拟机和Servlet服务器环境中,本文以在安装JDK和Apache Tomcat的基础上,进行Solr的本地化安装、配置与测试。选择稳定的版本Solr1.4.1进行安装部署。
首先从Solr的官方网站下载开源软件包[ 18],解压后可看到build、client、dist、example、lib、site、src等目录。本研究要用到的主要是dist和example两个目录。dist目录包含build过程中产生的apache-solr-1.4.1.war,example包含了一些样例数据和一些Solr的配置,其子目录example/solr是一个包含了默认配置信息的Solr的Home目录(即主目录),实际上是一个运行的Solr实例所对应的配置和数据(Lucene索引)。
在安装发布Solr前,先停止Tomcat的运行,将dist文件夹中的apache-solr-1.4.1.war 复制到 Tomcat的webapps并且改名为solr.war。该文件是一个完整的Web 应用程序,包括了Solr的Jar文件和所有运行Solr 所依赖的Jar文件、JSP和很多的配置文件及资源文件。重新启动Tomcat,solr.war将自动发布为Web 应用并在webapps文件夹下生成solr目录。
由于solr.war文件中并不包括Solr主目录,因此在启动Tomcat之前还要先指定Solr的主目录。为简单起见,在E盘website目录下新建一个solr的文件夹,并将前面提到的example/solr文件夹中所有内容复制到该目录下,然后修改webapps/solr/WEB-INF目录下的web.xml文件,去掉对下边内容的注释,并将“
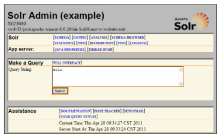
为验证Solr是否正确安装,可打开http://localhost:18080/solr/admin/,如果出现Solr系统管理主界面则表示配置成功,如图4所示。
 | 图4 Solr系统管理主界面 |
4.2 索引文件的创建与更新
(1) 索引参数设置
在建立索引之前,首先要对索引性能参数和索引结构进行设置,主要通过solrconfig.xml和schema.xml实现。solrconfig.xml主要负责Luence建立索引过程中的性能参数(如mergeFactor、maxMergeDocs和ramBufferSizeMB等)以及索引文件和数据库索引配置文件的存储路径设置。
schema.xml文件的定义非常关键,负责对索引的主体结构进行配置,主要包括字段类型(fieldType)、字段(fields)、复制字段(copyField)和文档唯一标识符(uniqueKey)等。首先,需要在types结点内定义需要的fieldType,包括name、class等参数,name就是这个fieldType的名称,class指向org.apache.solr.analysis包里面对应的class名称,用来定义这个类型的操作方式。在定义fieldType时通常需要指定该类型的数据在建立索引和查询时要用的分析器Analyzer,本系统采用开源的mmseg4j 中文分词器来进行中文分词[ 19],代码如下:
mode="max-word" dicPath="/data/my_dic"/> 本系统只定义了三种字段类型,即String、Text和Date,分别与Solr中定义的StrField、TextField和DateField对应,其中String类型不允许对字符串再进行拆分,Text类型在索引和检索时都需要通过mmseg4j分词器来进行中文分词处理。 在fields结点内定义具体的字段,包括name、type(前面定义的fieldType)、indexed(是否被索引)、stored(是否被储存)、multiValued(是否有多个值)、termVectors(是否存储检索词向量)等。对可能存在多值的字段(如作者和关键词)设置multiValued为true;为了使用查找相似文献功能,需将termVectors设置true;对于只需检索而不需要存储的字段,将stored属性设为false。为满足对所有字段进行统一检索,需建立一个复制字段,将所有的字段内容复制到该字段中。本系统对字段的定义代码片断如下: <schema name="example" version="1.1"> <types> <fieldType name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true"/> <fieldType name="date" class="solr.DateField" sortMissingLast="true" omitNorms="true"/> <fieldType name="text" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" dicPath="/data/my_dic"/> </analyzer> </fieldType> </types> <fields> <field name="id" type="string" indexed="true" stored="true" required="true"/> <field name="title" type="text" indexed="true" stored="true" termVectors="true"/> <field name="author" type="string" indexed="true" stored="true" multiValued="true"/> <field name="keyword" type="string" indexed="true" stored="true" multiValued="true" termVectors="true"/> <field name="abstract" type="text" indexed="true" stored="true"/> <field name="journalname" type="string" indexed="true" stored="true"/> <field name="issn" type="string" indexed="true" stored="true"/> <field name="year" type="string" indexed="true" stored="true"/> <field name="volume" type="string" indexed="true" stored="true"/> <field name="period" type="string" indexed="true" stored="true"/> <field name="page" type="string" indexed="true" stored="true"/> <field name="copiedfiled" type="text" indexed="true" stored="false" multiValued="true"/> </fields> <uniqueKey>id</uniqueKey> <defaultSearchField>copiedfiled</defaultSearchField> <solrQueryParser defaultOperator="AND"/> <copyField source="*" dest="copiedfiled"/> </schema> 在定义好字段类型和各索引字段后,可通过提交XML、CSV等规范文档或连接数据库进行数据的索引创建。 (2) 基于XML文件的索引创建 向Solr基于XML文件传递索引请求时,通常包括4种类型,如表1所示: 可以在同一个XML文档中使用这4种请求命令,样例数据实例片断如下: <add> <doc> <field name="id">123456</field> <field name="title">对新农村建设中培养造就新型农民的思考</field> <field name="author">戴红梅</field> <field name="keyword">新农村建设</field> <field name="keyword">新农民</field> <field name="keyword">培养造就</field> <field name="keyword">农民素质</field> <field name="abstract">农民是社会主义新农村建设的主体,建设"富强、民主、文明"的新农村,必须培养造就千千万万高素质的新型农民。提出必须加快发展农村基础教育,开展技能培训和农村文化事业,提高农民素质,培养造就有文化、懂技术、会经营的新型农民。...</field> <field name="journalname">安徽农业科学</field> <field name="issn">0517-6611</field> <field name="year">2007</field> <field name="volume">35</field> <field name="period">6</field> <field name="page">1836~1837,1858</field> </doc> </add> <delete><id>12345</id></delete> <delete><query>id:1234</query></delete> <commit></commit> <optimize></optimize> 为了对所有文摘数据建立索引,要先将数据库中的文摘转换为XML文档,再通过HTTP POST将命令发往: http://localhost:8080/solr/update,可以使用Solr提供的样例数据exampledocs文件中的post.jar包来完成提交,在命令行环境下,运行类似:“ java-Durl=http://localhost:8080/solr/update-Dcommit=yes-jar post.jar *.xml”的命令,如果一切顺利,等待一段时间会输出“Committing Solr index changes”提示,这就表明索引建立成功。 (3)基于数据库的索引创建 Solr提供的DataImportHandler(DIH)支持直接从数据库获取数据来建立索引,并提供全量索引(Full-Import)和增量索引(Delta-Import)两种方式。全量索引是将获取满足条件的所有数据进行索引,增量索引是对最近一次索引以来增加或者被修改的记录进行索引。每次在建立索引时会在solr.home\conf\dataimport.properties文件中记录最近一次索引的时间,通过比较这个时间和数据库表中的最后修改时间列,即可得到需要建立索引的记录。 为实现基于数据库建立索引,首先将对应数据库的JDBC驱动(本研究使用MS SQL Server 2005的JDBC驱动sqljdbc4.jar)复制到tomcat\\lib或webapps\solr\WEB-INF\lib目录下。然后在Solr主目录下新建数据库配置文件db-data-config.xml,同时修改solrconfig.xml,将该配置文件与DataImportHandler进行映射。其中column是数据库的字段名,name是索引文件对应的字段名。由于作者和关键词都可能有多个值,因此在索引时要进行拆分,依据是各值以英文分号隔开,各参数的详情可参考文献[20],该文件的内容如下: url="jdbc:sqlserver://localhost:1433; DatabaseName=AgriAbstracts;responseBuffering=adaptive;selectMethod=cursor;user=sa;password=sa" /> query="Select * From agri_abstract" deltaImportQuery="Select * From agri_abstract Where GID =′{dataimporter.delta.GID}′" delta Query="Select GID From agri_abstract Where lastupdatetime &gt; ′{dataimporter.last_index_time}′"> 设置好参数后,可通过http://localhost:8080/solr/dataimport?command=full-import和http://localhost:8080/solr/dataimport?command=delta-import分别启动全量索引和增量索引,本研究针对近180万条包含10个字段的文摘数据,建立全量索引所用时间为35分钟左右。![]()
表1 Solr索引请求类型
4.3 用户界面的设计与实现
基于Solr的优势在于,一旦建立起对大规模信息资源进行索引创建和更新的机制后,就可专注于系统功能和用户交互界面设计、查询条件的构造、检索结果的解析与展示,以及系统整体功能的实现。
(1) 用户界面的设计
在设计系统界面时,保持简洁美观的风格,在页面顶部提供所有字段、题名、作者、期刊名称、ISSN、年、卷、期、页码等检索入口。在左侧为用户提供包括对Top关键词、Top作者、Top期刊名称和出版年份进行分面导航、浏览和过滤的交互界面,在右侧显示查询结果信息,包括满足条件的记录数、响应时间和分页导航功能,以及每条文摘的详细信息。
(2) 查询条件的构造
表2列出了Solr常用的查询参数,进一步了解各参数的详细情况可参考文献[21]。
| 表2 Solr常用查询参数 |
可以通过上述参数的组合来灵活构建查询请求并提交给Solr,一个简单的查询请求类似“http://localhost:8080/solr/select/?q=新农村&version=2.2&start=0&rows=10&indent=on& facet=true&facet.field=keyword”。
(3) 查询结果的解析与展示
Solr将以XML、JSON等格式返回响应结果,结果包含了响应时间、查询条件等检索元数据信息,以及返回的记录、分面检索、高亮显示和相似文献等信息。由于Solr返回的结果是XML等格式,需要借助XLST、JDOM等对其进行解析和页面重构,以适当的页面呈现给用户。一个典型的查询结果XML片断如下:
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">828</int>
<lst name="params">
<str name="indent">on</str>
<str name="start">0</str>
<str name="q">对新农村建设中培养造就新型农民的思考</str>
<str name="rows">10</str>
<str name="version">2.2</str>
</lst>
</lst>
<result name="response" numFound="1" start="0">
<doc>
<str name="abstract">农民是社会主义新农村建设的主体,建设"富强、民主、文明"的新农村,必须培养造就千千万万高素质的新型农民。提出必须加快发展农村基础教育,开展技能培训和农村文化事业,提高农民素质,培养造就有文化、懂技术、会经营的新型农民。</str>
<arr name="author">
<str>戴红梅</str>
</arr>
<str name="id">28545738-4B04-4CF4-9819-0CA11C1EEDF8</str>
<str name="issn">0517-6611</str>
<str name="journalname">安徽农业科学</str>
<arr name="keyword">
<str>新农村建设</str>
<str>新农民</str>
<str>培养造就</str>
<str>农民素质</str>
</arr>
<str name="page">1836~1837,1858</str>
<str name="period">6</str>
<str name="title">对新农村建设中培养造就新型农民的思考</str>
<str name="volume">35</str>
<str name="year">2007</str>
</doc>
</result>
</response>
(4) 系统功能实现与运行分析
在系统实现过程中,为提高开发效率,本研究使用了由EvolvingWeb设计开发的开源JavaScript脚本库Ajax-solr[ 23],该脚本库基于Solr和Ajax技术,实现了查询参数的动态管理、查询结果的解析展示、分页查看浏览、自动提示和分面标签等功能。本研究基于该框架进行了系统的二次开发,初步实现了检索系统的用户界面和系统总体功能,如图5所示:
 | 图5 检索系统主界面 |
从原型系统的实验运行情况看,系统能够较好地解析用户的查询请求,并能较为准确地完成核心作者、关键词、期刊、出版年份等分面的聚类统计、导航和过滤功能,检索结果中也包括了与每条文摘的题名和关键词相似的文摘数据,但由于关键词的随意性,相似文献有时并不一定相似。此外,检索结果可以按相关性和出版年份进行组合排序。尽管文摘数量近180万,但其响应时间一般都能控制在几十毫秒范围内。
5 结 语
当前,开源软件在数字图书馆的应用研究备受关注。将优秀的开源软件引入数字图书馆系统,并进行本地适应性改造和深层次开发,将有利于图书馆有效缓解资金短缺和技术力量不足的困境,也可显著提升业务管理水平和服务创新能力。本文根据国家农业图书馆的实际情况,将开源的全文检索引擎Solr应用于中文农业期刊文摘检索系统,取得了理想的实验效果,为图书馆自建数字资源研制全文检索系统提供了初步的范例。由于该系统只是一个原型系统,下一步要将英文文摘加入到系统中,同时在分布式检索、可视化检索、检索结果重排序、基于农业科学叙词表的中英文双语智能检索、建立全文链接等方面开展研究与实践,以提高系统的整体性能和实用性,充分发挥Solr在建设数字图书馆服务系统中的优越性能。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|