
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于种子文档LDA话题的演化研究*
引用本文
单斌, 李芳. 基于种子文档LDA话题的演化研究* . 现代图书情报技术, 2011, 27(7): 104-110
Shan Bin, Li Fang. Topic Evolution Based on Seminal Document and Topic Model. 现代图书情报技术, 2011, 27(7): 104-110
Permissions
Shan Bin, Li Fang. Topic Evolution Based on Seminal Document and Topic Model. 现代图书情报技术, 2011, 27(7): 104-110
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
基于种子文档LDA话题的演化研究*
摘要
提出一种基于种子文档的LDA话题演化方法。首先选取种子文档,利用种子文档指导后一时间段文档的建模,然后根据种子文档的语义分布信息对连续时间上的LDA话题进行关联,保证话题的同一性。实验结果证明,在NIPS论文语料集和全国两会新闻报道集中,该方法可以推导特定话题的演化结果,避免关联话题之间存在的演化结果。
关键词:
LDA; 话题演化; 种子文档; 话题模型
中图分类号:TP393
Topic Evolution Based on Seminal Document and Topic Model
Abstract
This paper presents a new method to infer the LDA topic evolution automatically based on seminal documents. The semantic distribution of the seminal documents is used to guide the successive model and link topics between consecutive time slices. The experiments are based on NIPS dataset and Chinese newswire of NPC and CPPCC,and the results show that the method can not only get the correct evolutions in various forms, but also avoid those related topics without evolution relationship.
Keyword:
LDA; Topic evolution; Seminal document; Topic model
1 引言
互联网信息的爆炸和电子文档数目的激增,使得人们难以准确地获取有用的资源。如何有效地探测文档集合的话题,并且按照时间顺序演绎话题演化,具有实际的应用背景和研究意义。话题演化反映了实际应用中的各种情况,例如,新闻事件报道主题的变化、科学技术的发展、博客或微博热点话题的变化等。
随着话题模型的兴起[ 1, 2, 3, 4],可以利用话题模型对大量文本集合进行建模,无监督地抽取文集上的话题。近年来,出现了不同的基于LDA (Latent Dirichlet Allocation)话题模型的演化研究。其中比较有名的模型是TOT模型[ 2],DTM模型[ 5]以及DMM模型[ 6],分别代表了三种不同的演化方法[ 7],在这些方法中,有的假设话题之间形成一对一的演化,有的通过计算话题的相似度或者话题的分布距离,找到话题的关联,形成演化关系。一对一话题的演化不符合实际情况,通常,新话题的产生或者旧话题的消失,以及话题之间的合并与分裂,都有可能发生[ 8];而计算话题相似度的方法往往会在关联的话题之间形成演化关系,例如,西藏话题和达赖喇嘛有关联,但不一定形成演化关系。为了形成精确的话题演化关系,本文提出了一种新的话题演化方法,通过选取种子文档,利用种子文档关联不同时间段的话题,从而形成话题的演化关系。
2 问题的提出
在文献[9]中,通过在各个阶段自动抽取LDA话题,计算相邻时间段话题的相似度来决定是否存在演化关系,这种方法可以得到形式多样的演化,包括话题合并与分裂以及新旧话题。研究发现,有些相似的不同话题也被关联起来,例如,在全国两会语料的实验中,养老保险和保险公司的风险两个话题也关联起来,如图1所示:
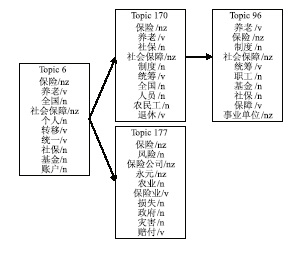 | 图1 文献[9]中提出的方法得到的错误的演化路径实例 |
话题6和话题177具有一定的语义关联,但不具有演化关系,养老保险是社会保障的一部分,而和保险公司相关的属于商业保险,因此,两个话题存在关联,但不具有演化关系。
从话题词中可以看出,话题6和话题177语义上比较相似,都是关于保险的话题,因此,通过JS距离公式计算话题之间的相似度实际上反映了话题的关联,并不是所有关联的话题都存在演化关系。为解决这一问题,本文提出了一种基于种子文档研究话题演化的方法。选取满足一定条件的种子文档,该种子文档加入到后续时间段的文档集合,通过该种子文档自动关联不同时间段上的话题,形成演化关系。利用种子文档可以得到话题一对一的演化,也可以得到话题的新生、消亡、合并等形式。该方法不依赖话题的距离或话题的相似度形成演化关系,而是利用种子文档的语义分布对齐话题,避免在关联而非演化的话题之间形成演化关系,增加LDA话题演化的精确性。
3 基于种子文档的话题演化模型
3.1 模型假设与方法介绍
科技文献的很多方法都借鉴了前人的方法形成,某一篇科技文献被引用的次数越多,说明它对未来的研究方向具有更大的影响力。基于种子文档话题的演化就是源于参考文献对于论文写作的作用。Rameshe等[ 10]将文献间的引用关系引入LDA模型来研究话题演化,但是,很多文本集合并没有显式地给出文本间的引用关系,引用模型不能应用在任何文本集合中。
基于种子文档的话题演化方法如下:
(1)在t-1时间窗口上对文本集合运用LDA模型,抽取话题。
(2)利用LDA模型的参数后验来判断并提取种子文档。
(3)将这些种子文档加入t时间窗口上的文本集合,利用LDA模型抽取t时间窗口上的话题。其中t-1时间窗口上的种子文档会影响t时间窗口内话题的生成,利用种子文档上话题的分布关联话题,最终形成t-1和t时间窗口上的话题演化。重复这个步骤,直到得到所有时刻的演化。
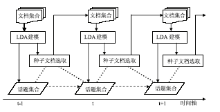
因此,本文提出的方法有两个重要步骤:通过规则选取种子文档和运用LDA模型生成话题,利用种子文档关联话题演化。其流程图如图2所示:
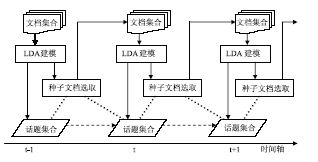 | 图2 基于种子文档的话题演化模型流程图 |
3.2 种子文档选取
= 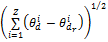
= 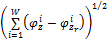
种子文档的选取需要满足一定的条件,来体现有意义的话题。首先定义一个平凡文档dr和垃圾话题zr,然后分别计算每一篇文档和平凡文档的距离以及每一个话题与垃圾话题的距离,距离越远,说明文档或话题越有意义,这样就可以得到种子文档和有意义的话题。
通过考察LDA模型参数θd和φz,分别定义平凡文档dr和垃圾话题zr为:
dr={d|p(zi∈Z|d)= 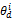
zr={z|p(wi∈W|z)= 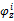
其中,K表示文本集合中的话题个数,W表示文本集合的词语个数。式(1)表示每个话题在平凡文档上的分布概率都是1/K,即无法判断平凡文档到底表达什么主题。同样,从式(2)可以看到每个词语在垃圾话题上的分布概率都是1/W,也就是说没有任何一个词语可以有效地突现话题的内容,因此这个话题是无意义的。定义任意一篇文档与平凡文档之间的距离 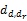
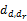 | (3) |
定义任意一个话题与垃圾话题之间的距离 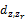
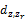 | (4) |
根据话题模型,任意一篇文档可以表示为话题空间上的一个向量,假设有K个话题,文档d可以表示为θd={ 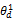
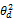
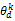
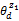
z1=zi且 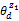
其中,λ1是阈值。式(5)表示文档d对于话题zi的表示程度, 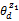
综上所述,一篇种子文档d需要满足:
(1)清晰表达一个话题,并且与平凡文档有较大的距离;
(2)清晰代表某一个话题,而且该话题与垃圾话题的距离足够大。
所以,除了要满足式(5),还要满足式(6)和式(7):
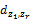
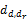
根据上述条件,种子文档d与演化话题zi由此产生。
3.3 话题演化形成
种子文档确定后,每个时间窗口的文档集合由属于该时间窗口的文档和上一时段抽取出的种子文档组成。在每个时间窗口上运用LDA模型抽取出话题后,利用种子文档关联话题,使之形成有意义的演化。
4 实验结果与分析
4.1 实验设置
= 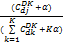
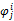
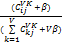
以NIPS会议2003年到2008年录用的论文作为英文实验语料,如表 1所示:
| 表1 2003年-2008年的NIPS语料 |
以全国2007年到2009年两会新闻报道作为中文实验语料,如表2所示:
| 表2 2007年-2009年全国“两会”报道语料 |
在实验中,对于英文语料首先过滤掉英文停用词,以及低频词;对于中文语料首先利用分词进行词性标注,再过滤掉停用词。利用模型选择的方法选取话题个数。利用Gibbs Sampling方法[ 12]推导LDA模型的参数θ和φ的后验估计。
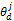 | (8) |
其中,D表示文档个数,K表示话题个数,V表示词语集合的大小。
4.2 种子文档选取实验
选取阈值λ1=0.40,λ2=0.05,λ3=0.55在NIPS语料上抽取种子文档。为了检验种子文档的抽取方法,作者对比了这些文档在谷歌学术搜索上被引用的次数。35篇不同的论文作为种子文档,一共被引用了1 465次,平均每篇文档被引用41.83次。表3列出了引用次数超过30次的种子文档。实验证明所选取的种子文档确实是具有影响力的文章。
实验发现,有一些种子文档出现在很多时间窗口上,跨越了多个时间段,比其他文档具有更长久的影响力,在科技文献领域,符合实际的应用。实验证明,种子文档选取方法在会议论文集合上得到了有效的验证。
| 表3 种子文档和引用次数 |
4.3 话题演化实验
(1)基于种子文档的演化结果
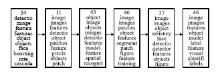
图3是根据种子文档“Using the Forest to See the Trees: A Graphical Model Relating Features, Objects, and Scenes”在2003年-2008年NIPS会议论文上所发现的话题演化。
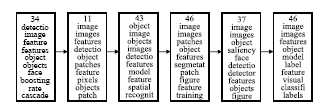 | 图3 文档“Using the Forest to See the Trees: A Graphical Model Relating Features, Objects, and Scenes”的演化结果 |
图3显示基于这篇种子文档得到的话题演化主要是关于“物体识别(Object Detection)”方面的。可以看到该领域研究技术有以下的变化:
从图像特征识别(Image Feature)、对象图像识别(Object Feature)、人脸识别(Face Detection)、特征标识向可视化发展。
两会报道的语料选取了2007年第111篇文档作为种子文档,其标题为《人大代表王填:食品制假可处投毒罪》,形成的话题演化,如表4所示:
| 表4 2007年-2009年全国两会语料基于文档《人大代表王填:食品制假可处投毒罪》的话题演化结果 |
从表4中可以看出,食品安全话题的演化发展,2007年主要针对食品检测环节和体系指标,2008年关注食品的标准和质量问题,2009年针对药品、奶粉等特殊的食品事件,并提出了安全法。确保了同一话题的演化结果是正确的。
(2)演化对比实验
选取文献[9]中的通过计算话题间距离来形成演化的方法作为基线(Baseline)进行对比实验。选取距离阈值0.4,即相邻时间上的话题如果它们的距离小于0.4,则认为存在演化关系。
在NIPS语料上的实验表明,两种方法都能得到2003年-2008年关于以下领域的一些演化:决策规则学习(Decision Rule Learning),话题模型(Topic Model),信号处理(Signal Processing),贝叶斯方法(Bayes Theory),神经网络(Neural Network),聚类分类(Clustering and Classification),马尔可夫决策过程(Markov Decision Process),支持向量机(SVM)和博弈理论(Game Theory)等,两种方法得出的结果差别并不大。以“马尔可夫决策过程”的话题演化为例,对比结果如表5所示。
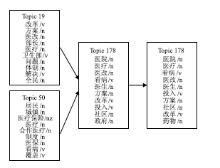
表5显示两种方法都能得到类似的话题演化结果,对应话题的话题词也没有很大区别,只是在次序上的变化,原因是在下一时刻加入了种子文档,对话题的产生有一定的指导作用,但是并没有影响话题的内容。另外本文提出的方法也得到了基线方法没有得到的话题演化,如表6所示。
表6中的演化是基于种子文档2003年的论文《Hierarchical Topic Models and the Nested Chinese Restaurant Process》得到的。该论文被引用次数超过190次。
| 表5 NIPS语料中有关“马尔可夫决策过程”的话题演化对比 |
| 表6 NIPS上基于种子文档方法得到的关于“话题模型”的话题演化 |
基线方法没有得到结果,是由于话题词变化大,话题之间的相似度不高,小于事先设定的阈值。阈值的调整也会带来其他更多噪音数据。
全国两会新闻报道集合上的话题演化实验与基线方法对比,都能得到一些基本的话题演化,如“农民工”、“教育”、“医保”、“食品安全”等。表7展示了两种方法在“市场投资”话题上的演化。
本文提出的方法,也发现了话题的合并和分解,如图4所示:
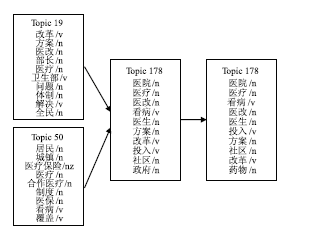 | 图4 两会语料中存在话题合并的话题演化实例 |
图4显示,2007年“医疗改革”主要关注医疗体制改革和居民医疗制度,而从2008年开始,话题关注点转向社区医疗上。
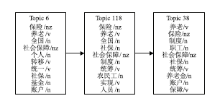
本文提出的方法也得到了图1中关于“社会保障”话题的演化,但没有引入错误,如图5所示。
| 表7 全国两会语料上关于“市场投资”话题演化的对比 |
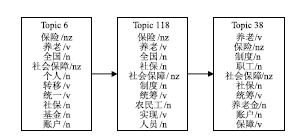 | 图5 利用本文的方法得到的2007年-2009年全国两会报道关于“社会保障”的话题演化路径 |
实验结果证明,本文提出的基于种子文档的方法能得到形式多样的有意义的演化,符合话题的生命周期。与基线方法的对比实验表明,两者都能有效地得到类似的演化,但是本方法克服了基线方法中根据距离公式计算引入的关联话题演化,提高了话题演化的精度。
5 结语
本文提出了一种新的话题演化方法,该方法不需要计算话题的相似度或者分布距离,通过引入种子文档,指导话题的建模,并利用种子文档关联话题,生成演化关系。对比实验证明,该方法可以得到和基线方法相同的演化关系,同时,避免了一些错误的话题演化结果,例如:2007年有关物业税和消费税话题被关联到2008年的印花税话题等。基于种子文档的方法在一定程度上提高了话题演化的精度。
通过定义平凡文档和垃圾话题的概念,提出了选择种子文档的方法。在科技文献上的实验证明了该方法的合理性, 但在其他文集上的实验还缺乏客观的评测标准。基于种子文档的话题演化,可以实现特定话题的演化关系。对于基于查询的话题演化,帮助用户追踪感兴趣的话题研究具有一定的启示。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|