



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
文献跨库检索中去重方法研究与应用
引用本文
郝丹, 周津慧, 关贝, 王衍喜, 韩继欣. 文献跨库检索中去重方法研究与应用. 现代图书情报技术, 2011, 27(7): 116-121
Hao Dan, Zhou Jinhui, Guan Bei, Wang Yanxi, Han Jixin. Research on Duplicated Literature Deletion Method Based on. 现代图书情报技术, 2011, 27(7): 116-121
Permissions
Hao Dan, Zhou Jinhui, Guan Bei, Wang Yanxi, Han Jixin. Research on Duplicated Literature Deletion Method Based on. 现代图书情报技术, 2011, 27(7): 116-121
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
文献跨库检索中去重方法研究与应用
摘要
以作者和单位发文的统计需求为背景,分析作者和单位发文在跨库检索中产生数据冗余的特殊成因,在借鉴网页去重的基础上,设计中文跨库ID、英文跨库ID、DOI以及“标题+类型”4种文献跨库去重方法,解决中文库之间、英文库之间以及中英文库之间的冗余问题,并有效应用于专家发文和单位发文信息获取与统计工作中。
关键词:
跨库检索; 去重策略; 文献信息
中图分类号:G250
Research on Duplicated Literature Deletion Method Based on
Keyword:
Cross-database searching; Duplicate removal strategy; Literature information
1 引言
随着对个人及单位发文统计需求的不断增加,通过对单一数据库检索和简单的跨库检索已经无法满足用户需求。其原因在于:文献数据库产品内容交叉重复现象比较严重[ 1],当检索某一作者/单位发文时,跨库检索结果中不可避免地会出现大量的重复冗余文献,使得用户不得不对检索结果采取人工方式进行去重处理,而且这种人工排查的时间开销远大于检索过程所耗费的时间。因此,如何设计一种高效的跨库检索去重方法,可使得在具有查全率和查准率较高的检索结果中有效合并重复文献,快速完成文献检索与统计工作,成为一项十分必要且有意义的工作。
本文针对基于Web信息抽取的多源网络数据库的检索结果,参考网页去重机制,设计了一套适应于此类应用的跨库去重方法,并通过构建中间库,实现并验证了方法的有效性。
2 检索结果去重方法简析
文献检索结果去重处理的代表是网络环境下随处可见的跨库检索平台,这些用户平台虽大多具有去重功能,但均不能直接服务于对“专家/单位发文”检索结果的去重,其原因如下:
(1)跨库平台集成度有限,导致数据去重涉及范围较窄。多数文摘跨库平台,如ISI Web of Knowledge,虽然对跨库检索的结果进行冗余处理[ 2],但是,相对于专家发文所涉及的数据库范围,ISI Web of Knowledge的跨库去重仅相当于单个数据库的库内去重。
(2)中英文文献库之间的去重鲜有涉及。现有跨库平台大多只是对同一语种数据库的集成,所以去重的对象也仅限于单一语种的数据库之间。如:万方、CNKI对所收录的中文库的跨库检索结果进行去重,DBLP、微软学术搜索、Scientific Commons、CiteSeerX、ArnetMiner平台等对所收录的英文库的跨库检索结果进行去重[ 3]。然而专家/单位的某些发文,可能同时既被中文库收录,又被英文库收录,如万方中所收录的题为:“基于视平面上特征计算的视点选择”的文献和EI中所收录的“viewpoint selection by feature measurement on the viewing plane”实则为同一篇文献,所以需要解决中文库与英文库之间的跨库去重问题。
(3)尚无涉及操作层面的去重方法可供借鉴。现有的跨库检索平台数据整合方式通常有三种:元数据模式、中间件模式和网络搜索代理模式[ 1],但大多文献资料中对这三种数据整合方式所进行的表述都比较笼统,不能直接利用。
(4)常用跨库检索平台重复数据频率仍存在。以Google Scholar为代表的跨库平台,虽然对多个网络数据库的检索结果进行合并,提供不同的版本信息供用户选择,而且能提供统一的返回格式,但是在检索结果中,同一标题被罗列的现象还是相对比较常见,如图1所示:
 | 图1 Google Scholar检索图 |
此外,从检索结果上看,Google Scholar也未实现跨语言数据库的去重。
根据以上分析,本文拟从提供Web查询的多个中英文文献数据源出发,通过分析文献跨库检索结果产生的独特数据冗余原因,借鉴网页去重机制,研究并设计了中文跨库ID、DOI、英文跨库ID和“标题+类型”4种去重方法,借助于构建中英文文献集成的数据库,来实现中文库之间、英文库之间以及中英文库之间的跨库检索结果去重与整合处理,有效解决了检索专家发文和单位发文时所遇到的去重合并问题。
3 文献跨库检索去重
用户通常在采用跨库检索的同时还希望确保检索结果具有一定的查全率与查准率。然而这种“全”与“准”必然造成检索结果数据的冗余,其解决办法就是设计一种基于跨库检索过程中的去重方法,以保证检索结果的准确性和唯一性。
3.1 检索结果冗余分析
文献数据库检索可归结为多源网络数据库检索,其跨库检索冗余主要来自于两个方面:
(1)收录冗余
收录冗余是指由于数据库收录期刊重叠而导致跨库检索结果的冗余。区别于一般网页信息上传的自由性与转载的随意性,文献信息因其通常涉及版权问题而与特定的刊物所绑定,所以文献信息的出处是唯一的,且上传与转载的自由性不大。然而,特定的刊物却总是被一个或多个网络数据库所收录,不同的数据库收录的刊物经常存在交集,在获取个人/单位发文信息时,通常是借助于对多个数据库跨库检索来完成的,因此,数据库收录刊的重叠是导致文献跨库检索冗余的最根本的原因。
数据库的收录冗余通常可以分为三类:中文库之间的冗余(有数据统计,维普数据对万方期刊的重复率为93.6%,对中国期刊数据的重复率为94.1%[ 4])、英文库之间的冗余(例如:Springer与ACM、IEEE之间)以及中文库与英文库之间的冗余(最为常见的是CSCD与EI、CNKI与EI、万方与EI)。
(2)查全冗余
查全冗余是指由于人为引入额外检索条件而引发的检索结果冗余。为查全信息产生数据冗余实际上是一种牺牲的检索冗余,是为了保证“查全”而付出的代价,且多来源于英文数据库。在文献检索与统计工作中可以发现,姓名和单位的英文拼写方式、排列顺序存在多样性,例如:Wang Qiming的表述有Wang Qiming、Qiming,Wang、Wang-Qiming、Qiming-Wang、QM,Wang和Wang,QM,中国科学院的表述有CAS、Chinese Academy of Sciences和Acad,北京大学的表述有Peking University和Beijing University等[ 5]。虽然在各个数据库内部,作者姓名和单位名称的表述相对比较固定,但在多个数据库之间缺乏统一的收录规则,如果只用某一种或者少数几种表述进行检索,会使得某些确实存在的匹配项漏检,导致检索结果不全。所以,跨库检索须覆盖姓名和单位的各种表述方式,才能确保不会漏检。理论上讲,即使数据库之间缺乏统一标识也只是检索结果“全”或“不全”的问题,不存在冗余之说。这便涉及到了检索冗余的第二个成因——数据库的标引问题,对于同一篇文献,数据库可能从不同的角度对其进行标引[ 6],即接受多种姓名拼写格式的查询,例如,某篇署名单位为中国科学院的文章,使用CAS和Chinese Academy of Sciences都能检索到。在以上两方面因素的共同作用下,当使用CAS、Chinese Academy of Sciences和Acad对中国科学院的发文进行检索时,就会使检索结果中同一篇文献出现多次,导致了检索结果的查全冗余。
3.2 检索结果去重依据
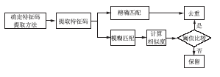
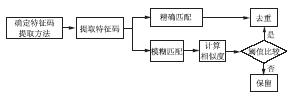
基于Web页面抽取的文献信息的跨库去重方法,遵循网页去重的基本思路:即确定特征码提取方法→提取特征码→精确匹配→去重,或者确定特征码提取方法→提取特征码→模糊匹配→计算相似度→去重(与阈值比较)[ 7, 8, 9],如图2所示:
 | 图2 一般网页去重流程 |
其去重方法可根据特征码提取的规则不同分为基于URL的和基于内容的两种[ 10, 11]。基于URL的去重方法,将特定的URL作为网页文献信息的特征码被提取出来,进行全部匹配(或部分匹配计算相似值),再根据预先指定的规则,决定淘汰还是保留。基于内容的去重方法,其操作对象是网页的实际装载内容,是将网页文献信息的某些标志性较强的内容提取出来组成特征码,然后按照既定的规则进行匹配,决定弃留。
3.3 检索结果分类去重
根据中英文数据库中文献信息的不同特点,本文分别采取构造中文跨库ID、DOI、英文跨库ID以及“英文标题+类型”的去重方法,主要解决中文数据库文献去重、英文数据库文献去重以及中文库与英文库间文献去重。
(1)中文数据库文献去重
经分析发现,中文数据库大多没有采用国际统一的DOI对文章进行标识,本文构造文章在所有中文库的跨库ID即“论文名拼音首字母+发表期刊拼音首字母+出版年份”(适用于期刊论文)或者“论文名拼音首字母+主办单位(赞助商)拼音首字母+出版年份”(适用于会议论文)来对所有中文库做统一的去重处理,比如对于一篇名为“多源文献合并浅析”、发表在《计算机学报》上、2003年的文献,构造的跨库ID为:DYWXHBQXJSJXB2003[ 12]。对于两篇相互比较的文献,或许它们拥有相同的出版年份、发表于同一刊物上,但是标题转换的拼音首字母都相同的却是小概率事件,将这些内容拼在一起不仅使得不同中文库中的文献具有可比性,而且能够唯一标识。
(2)英文数据库文献去重
由于大多数英文数据库采用国际通用的、全球唯一的DOI来标识文献,因此本文首选DOI去重,并将英文跨库ID作为辅助去重策略,用于处理未采用DOI的英文数据库。为了避免英文标题特殊符号较多、处理复杂等问题,本文所采取的英文跨库ID构造方法为:“第一作者姓的拼音+其他作者姓的首字母+出版年+起始页码”,如对于一篇作者为张某、王某和李某,且出版年为2002,起始页码为23的文献,构造的跨库ID就是:ZhangWL200223。这种方法虽然会带来一定的伪文献,但使用“作者+单位”一起检索时,出现伪文献的几率可以忽略。
(3)中文库与英文库间文献去重
目前,笔者仅发现中文数据库与EI数据库存在交集,即EI中有不少中文文献的英文标引。在中文数据库中,包含了中英文标题、中英文作者以及中英文摘要等全面信息,而在EI数据库中,仅仅给出了重复文献的英文标题、英文作者以及英文摘要等信息。由于中文库中缺少国际通用的DOI,而中英文库中的跨库ID构造方式又各不相同,鉴于此,直接使用“英文标题+类型”来去重,但不能单独使用“英文标题”,因为在现实中,存在标题相同的文献同时被期刊和会议收录的情况,而这种情况在学术上被认定为不同的文献,所以,为了防止去重的同时遗漏文献,本文采用“英文标题+类型”来弥补其不足之处。
3.4 跨库检索去重算法
跨库检索去重算法的伪代码如下:
Read检索结果集
提取检索结果集中每条文献信息的跨库ID、DOI、标题、类型、来源库等信息,并保存到数组A中
Load数据库中已有的文献信息(包括每条文献的跨库ID、DOI、标题、类型、收录库等)到数组B中
Do 从A中取出一条记录X
将X从A中删除
i<-0 //用于记录数组B的当前索引,初始化为0
Do 从B中取出第i条文献信息y
If(x,y同是来源于中文库)
If(二者的中文跨库ID相同)Break //Break 表示跳出内层循环,这步操作代表去重,以下相同
Else If(i==B中的条目数-1)//即该条记录y是B中最后一条记录
将X加入B中
Else Continue //Continue代表结束本次循环,开始下次操作,以下相同
Else If(x,y同是来源于英文库)
If(二者的DOI相同//英文跨库ID相同)Break
Else If(i==B中的条目数-1)
将X加入B中
Else Continue
Else If(x,y分别来自于中/英文//英中文数据库)
If(二者的“英文标题+类型”相同)Break
Else If(i==B中的条目数-1)
将X加入B中
Else Continue
i++
While(i==B中的文献条目数)//Do…While 是直到型循环,意为“直到……条件时,循环结束”
While A为空
将最终数组B增量插入数据库//即有则更新,无则插入
4 应用案例及效果评价
4.1 应用案例
本文所设计的去重方法已用于“作者/单位发文检索平台”,该平台以多个目标数据库为底层数据源,通过集成的统一入口对作者/专家的发文进行检索,旨在方便快捷、准确而无重复地收集作者/专家所有发文。通过该平台的专家文献检索界面(见图3),输入专家姓名、署名单位及检索时间,系统可在SpringerLink等西文全文数据库和万方、CNKI等中文全文数据库及EI、CSCD等文摘数据库中找到专家公开发表的论文和专利的题录信息,经本文的去重算法处理后,得出如图4、图5所示的检索结果。
 | 图3 专家文献检索界面①①领域专家知识导航平台[DB/OL] |
 | 图4 去重合并后的检索结果① |
 | 图5 文献统计结果① |
图5中各数据库栏下给出的序号取自于图4所示文献题录数据的序号。从图5可以看出,相同序号会出现在不同列中,即表明该序号在图4中所示的文献取自多个数据库,由此也明显反映出数据库存在的三种重叠:中文库之间(如:8、9、10同时出现在万方、CNKI、CSCD中),英文库之间(如:13同时出现在ACM、Springer、ISTP中)以及中英文库之间(如:2、6同时出现在EI和万方中),经去重方法处理后,不同冗余问题已被归类合并。
4.2 去重效果评价
为了更客观地评估去重方法,笔者在较大规模的数据集上做了测试,进一步验证了该方法的时效性和准确性,主要表现在:
(1)去重速度的高效性。笔者通过“作者/单位发文检索平台”对新疆某大学2009年的3 360篇发文题录信息从数据采集到去重处理完毕所花费的总时间大约10分钟,除去数据采集以及人工操作时间6分钟,实际所用的去重时间仅有4分钟,篇均去重时间小于0.08秒,由此可见,去重速度较快。
(2)去重结果的准确性。通过对某科研单位1998年-2010年发文的跨库检索结果,采用本文所述去重方法进行冗余处理,在英文库文献去重阶段被合并的有702篇;中英库之间合并的有454篇,中文库之间合并的有667篇,最终得到3 728篇文献,基本符合该单位的统计结果,处理效果较为理想。
5 结语
本文针对“作者/专家发文”应用所设计的跨库文献去重方法,提供了适用于Web文献信息的跨库检索结果去重一般思路和常用方法,它是网页去重方法的纵向深入,从这个角度讲,它可以借鉴网页去重的各种技巧来进一步完善,具有极大的发展潜力。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|