{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Web系统多级分布式缓存机制设计与实现*
引用本文
王科, 周强, 李春旺. Web系统多级分布式缓存机制设计与实现* . 现代图书情报技术, 2011, 27(7): 21-25
Wang Ke, Zhou Qiang, Li Chunwang. Design and Implementation of Web System Multi-stage Distributed Caching Mechanism. 现代图书情报技术, 2011, 27(7): 21-25
Permissions
Wang Ke, Zhou Qiang, Li Chunwang. Design and Implementation of Web System Multi-stage Distributed Caching Mechanism. 现代图书情报技术, 2011, 27(7): 21-25
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
Web系统多级分布式缓存机制设计与实现*
摘要
提出一种Web系统多级分布式缓存机制的设计方案,以及基于主流开源软件的实现方法。本方案包含多粒度组织、多物理层级存储的缓存数据管理方法,以及键名生成机制等关键技术。随后介绍缓存效率评价模型,包括单机与分布式缓存的提速原理,并基于真实的应用场景进行效率测试实验,证明本方案的有效性。
关键词:
多级; 分布式系统; 缓存; 开源软件
中图分类号:G250.7
Design and Implementation of Web System Multi-stage Distributed Caching Mechanism
Abstract
This article introduces a common Web system multi-stage distributed caching mechanism design scheme and the realization method based on the open source software. The program includes multi-granularity organizations, multi-level physical device stored cache management methods, and the cache key formation mechanism and other technologies. Then the cache efficiency evaluation model including single machine and distributed cache acceleration principles and the efficiency test experiment which proves the validity of the scheme are presented.
Keyword:
Multi-stage; Distributed system; Cache; Open source software
1 引言
网络拥塞与服务器超载是Web应用系统的普遍问题,此类问题加剧了服务提供方的资源消耗并严重影响着用户的使用体验。为Web系统增加缓存机制是解决这一问题的重要方法之一[ 1]。系统缓存是位于应用程序与物理数据源之间,用于暂存数据的内存空间,其目的是为了减少直接对数据源进行访问的次数,从而节约系统资源,提高系统效率。
当前,缓存开源软件实现已经比较丰富,如EhCache[ 2]、Memecache[ 3]。这些开源软件已经广泛地应用于各种应用软件与Web系统中。例如Hibernate系统使用EhCache作为数据库缓存,使得Hibernate系统数据读取效率优于直接对数据库进行操作。而Facebook、Flickr等超大型Web系统使用Memecache作为缓存是其能够承载超大规模用户操作与数据处理的重要原因之一。
本文提出了一种通用的多级分布式缓存实现方法,将缓存通过存储粒度与位置进行分层组织管理,并遵从面向对象的设计原则,将接口与实现进行了分离,可以使用不同开源软件进行缓存实现。
2 设计与实现
首先介绍缓存对象定义,并设计了Web系统缓存机制与实现方案,主要包括多层缓存、多级缓存、分布式缓存,以及键名生成机制。
2.1 缓存对象
本方案中,缓存对象以键值对的形式存在,键名为缓存项唯一标识,键值为缓存项内容。将缓存对象分为两类:
(1)实体类:实体类缓存对象是指本身存储于物理介质的资源,包括物理文件、数据库、配置文件等。实体类缓存的意义主要在于减少IO次数,以提高系统效率。
(2)非实体类:非实体类缓存对象是指本身并未存储于物理介质的资源,往往为系统进行服务过程中生成的中间计算结果,例如用户的检索记录、登录状态、权限判断结果等。非实体类缓存的意义主要在于减少长时间重复计算次数,以提高系统效率。
2.2 多层缓存
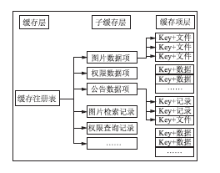
本方案将缓存按照粒度划分为多层,如图1所示:
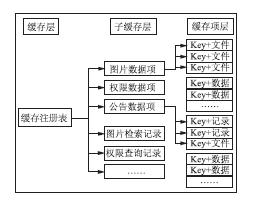 | 图1 缓存分层示意图 |
进行分层组织使得缓存的存储组织更加清晰,查询与维护效率更高,并使得系统可以以不同粒度进行缓存操作。缓存数据划分为三个层次,分别为缓存、子缓存、缓存数据项。“缓存”存储(一般使用Map容器)“子缓存”引用,“子缓存”为“缓存项”的容器。将缓存数据再次划分为子缓存,主要有利于提高缓存查找与更新效率,某类资源仅需要在对应子缓存中进行查找即可,而在某条缓存项更新时,仅需要更新对应子缓存,而不需要重新加载整个系统缓存。另外,将所有子缓存全部注册于缓存容器,允许系统对全部系统缓存进行操作,例如清理或重新加载缓存。
多层缓存机制为抽象的缓存方案,可以使用不同的开源软件,甚至不依赖于开源软件进行实现。
2.3 多级缓存
参照操作系统[ 4]中缓存实现的分级策略,缓存按照存储位置分为线程缓存、虚拟机缓存、集群缓存三个层次,每层缓存在实际应用中都可以设置为开启或者关闭。每级缓存可以视为一个不同的物理存储介质,随着层级的提高,缓存存取效率降低,维护成本增加,而缓存容量增大,提供缓存服务的能力更强。实验证明,缓存分层能够进一步提高缓存响应速度,并节约系统资源。
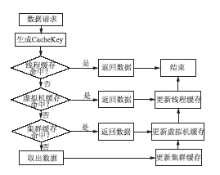
(1)缓存查找与更新逻辑
缓存查找与更新算法逻辑如图2所示:
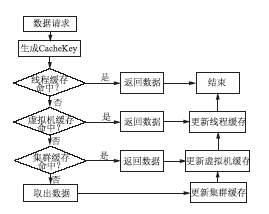 | 图2 缓存查找与更新算法逻辑示意图 |
Web系统在进行数据请求时,首先到低层缓存进行查找,如果无法找到数据,再到更高一级缓存中进行查找。如果在高层缓存中查找到存在的数据,则依次更新低层缓存。低层缓存比高层缓存容量更小,查找速度更快。如果底层缓存能够具备较高命中率,就能够大幅度提高缓存速度。
(2)线程缓存
用户对Web系统的每一次访问操作,在Web服务器端对应一个线程进行处理。在用户对Web系统进行访问的过程中,所使用的数据往往具备高度的重复性。线程缓存存储某个用户再次与Web系统交互过程中对应线程所使用的数据,将直接提高用户的响应速度。
线程缓存暂未调研到有开源软件能够支持。本方案中,线程缓存通过Java虚拟机技术中的ThreadLocal[ 5]技术实现。ThreadLocal可以视为一个线程内的全局变量。使用静态的ThreadLocal
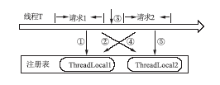
每个服务器端线程在不同时间段内将为不同的用户请求进行服务,这些请求未必属于同一用户,这在某些情况下将导致数据不一致问题。假如使用ThreadLocal来缓存用户的认证信息,用户A通过线程T登录系统,认证信息将缓存在线程T的ThreadLocal中。T完成对用户A的服务后未进行ThreadLocal重置,即未清空缓存。而同时用户B在没有登录的情况下访问系统,本请求也接受了来自T的服务,T将使用用户A的认证信息,这将为系统带来灾难。本方案为每个线程维护一个ThreadLocal注册表[ 6],每个请求完成时对表内所有ThreadLocal进行重置,以保证数据的独立性。线程缓存注册与重置示意图,如图3所示:
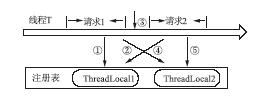 | 图3 线程缓存注册与重置示意图 |
请求1的①、②两步操作分别使用了两个ThreadLocal数据,如果不进行步骤③的数据清空操作,请求2的④、⑤两步操作,将使用请求1的数据。
(3)虚拟机缓存
虚拟机缓存是指存储于服务器虚拟机的缓存,虚拟机缓存可以独立实现,也可以依赖于开源软件实现。不依赖开源软件实现,可以将每一个子缓存(每个子缓存对应系统中的某个类),通过一个多线程安全的全局Map容器ConcurrentHashMap
(4)集群缓存
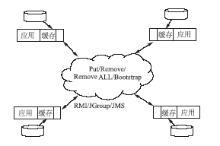
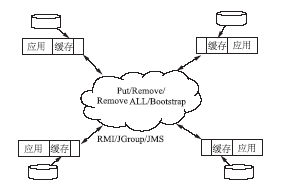
一旦将应用部署在集群环境中,每一个节点将维护各自的缓存数据,当某个节点的缓存数据进行更新,如果更新的数据无法在其他节点中共享,将降低节点运行的效率,并导致数据不同步。采用集群模式时,集群中的每个节点都是对等关系,并不存在主节点或者从节点的概念,因此节点间必须有一个机制能够互相识别对方,必须知道其他节点的信息,包括主机地址、端口号等。缓存之间相互连接后,当某个单机的缓存发生变化时,立即将数据变化通知到其他节点,其他节点通过通知更新数据以保持数据一致性,如图4所示:
 | 图4 集群缓存示意图 |
当前主流的开源软件均提供了集群环境支持。例如EhCache[ 8]提供了手工配置和自动发现两种节点发现方式。手工配置方式要求在每个节点中配置其他所有节点的连接信息,一旦集群中的节点发生变化时,需要对缓存进行重新配置。提供了基于RMI、JMS、JGroups等技术的数种实现方案,每种方案的配置方法不同,对应使用的节点通信方式不同[ 9]。
2.4 键名生成机制
实体类缓存项本身含有能够在系统中进行唯一标识的信息,例如物理文件地址、数据库中数据项的主键等。非实体类缓存同样也对应着标识信息,如检索记录类缓存项的检索词与检索对象,用户认证类缓存的用户ID号。可以直接使用此类原始的缓存标识信息直接或者做简单处理作为键名,但为了更好地组织缓存并避免出现键值重复,也可以使用缓存的原始信息进行计算得到新的键名。由于缓存类别的不同,各层次缓存进行键名生成的元素也不同,本文的方案并非唯一可行方案,仅作为参照。缓存键名生成信息如表1所示:
| 表1 缓存键名生成信息 |
键名生成主要需要效率与避免重复,可通过原始键名进行MD5计算,也可使用哈希值方法。进行键名生成所使用的信息可以视为一个数组SK=[sk1,sk2…skn]。Key(k)定义为通过前k个信息元素生成的键值,Hash(m)为第m个元素的哈希值,S为一个大素数,可以取17、31、53等值,则:
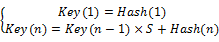 | (1) |
3 实验验证
3.1 缓存评价模型
缓存系统一般使用埃坶德尔定律[ 9]进行缓存提速的评估,计算方法如下:
N=
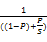 | (2) |
其中,N为整个系统的提速倍数,P为被提速部分所占用整个系统原始耗时的比例,而S为被提速倍数。
埃坶德尔定律将原始耗时视为1(100%),而提速后的耗时为原始耗时减去被提速部分耗时,再加上提速后的被提速部分耗时。本定律可以看出缓存系统的有效性,即缓存缩短了可加速部分所耗损的时间。同样也可以看出缓存系统的局限性,即局部的加速对整体产生的影响往往是有限的。
服务器缓存集群可以分为两类:独立缓存集群和协同缓存。对于独立缓存集群,服务器之间可以使用不同的负载均衡算法,例如Round Robin(缓存命中后即转入下一个服务器)。服务器集群的提速效果,即提速请求占所有请求的比例CE定义如下[ 9]:
CE=
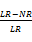 | (3) |
其中,LR为请求数,NR为独立缓存个数。
对于服务器集群缓存,缓存对其的提速倍数比为:
N=
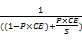 | (4) |
协同缓存可以将所有缓存视为一个独立缓存,当前主流的开源软件均支持这一机制[ 9]。协同缓存实现方案中,NR始终为1,在请求数目很大的情况下,服务器集群的提速效果可以视为100%。另外,通过式(4)可以看出,缓存集群实质上不能提高单个请求的处理速度,其目的为提高系统处理请求的能力,从而提高请求处理的平均速度。
在现实中,缓存所不能够提速的一般指缓存加载部分,直接取得原始数据部分。缓存加载部分在系统启动时进行,所以往往可以忽略不计,但是缓存的维护往往需要一定时间,将此时间定义为W。真实的缓存提速倍数应该为:
N=
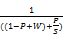 | (5) |
3.2 实验验证
为了验证本方案的有效性,笔者使用EhCache进行了权限验证缓存的实验。系统统计了10个不同用户登录后总共进行500次、1 000次、2 000次、4 000次、10 000次权限判断的情况,需要进行权限判断的地方包括页面、页面内容、物理文件、数据库表操作与数据项操作等。在后台记录权限判断耗时,实验机为Intel Core2处理器、2.00GHz主频、2.00GB内存、Ubuntu Desktop操作系统、MySQL数据库。
(1)缓存命中率
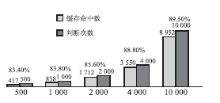
缓存命中率的对比数据统计,如图5所示(其中时间单位为微秒):
 | 图5 权限缓存命中数与判断次数对比统计图 |
通过图5可以看到,用户权限判断达到一定数目后,缓存命中率维持在一个比较高的范围,并且逐渐升高,这说明用户的权限判断操作与行为确实具备一定的规律性与重复性,所使用的权限判断真值数据也比较聚焦,权限判断系统的缓存机制符合用户的实际应用情况。
(2)权限判断耗时
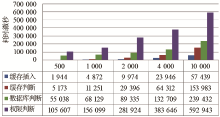
用户在系统中进行权限判断的耗时,如图6所示:
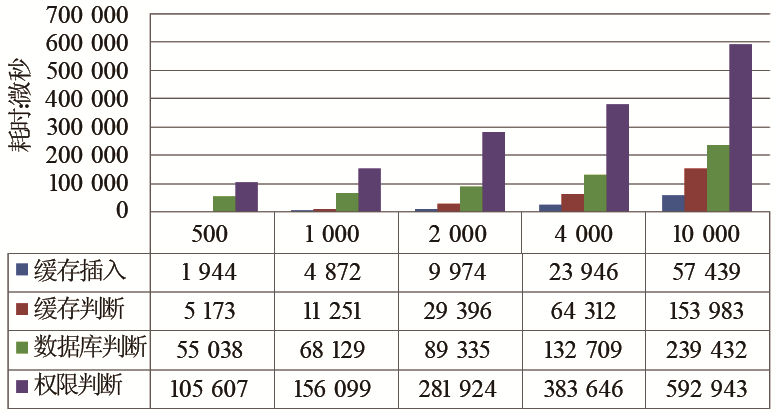 | 图6 缓存权限判断效率统计图 |
其中,权限判断总耗时为上层调用程序得到反馈的时间总和,还包括异常捕捉等程序逻辑耗时。而真实的权限判断耗时应该为缓存插入耗时、数据库判断耗时、缓存判断耗时之和。结合图5与图6可以得到如下结论:缓存插入操作需要耗费一定时间,但是相对其他耗时较短。即使缓存命中率很高,数据库判断的耗时还是占用了大部分的权限判断时间。
(3)缓存提速
根据埃坶德尔定律,缓存所提速的部分P为缓存命中部分,即缓存命中率,以I表示缓存命中率,而SC为缓存读取速度、SD为数据库读取速度。则理想环境下,缓存的提速倍数为:
N=
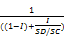 | (6) |
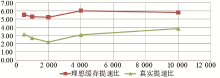
在现实中,缓存维护与异常捕捉等程序逻辑均需要耗费一定时间,所以缓存往往难以达到理想效果。实际情况的加速比可以认为是使用数据库读取所耗费时间与使用缓存所耗费时间的比值。理想中的缓存加速比与实际中的加速比,如图7所示:
 | 图7 理想与实际缓存加速比统计图 |
图7说明本缓存显著地提高了权限判断效率。当然,缓存需要消耗相当的内存空间,并且权限判断的耗时与系统配置与环境、数据库数据量、数据库是否建立索引、用户数量、用户行为所涉及的资源、缓存大小与策略等都有关系,大范围数据量的真实应用统计可能距离本实验结果有一定出入。
4 结语
本文介绍了一种通用的Web系统缓存实现方案及其实现的原理与设计方法,并简单介绍了基于主流开源软件的实现方案,随后介绍了缓存效率评估模型,并通过真实的应用统计分析证明了本方法的有效性,旨在为Web系统的缓存机制提供参照。本方法可以通用于各种类型Web系统,具体应用可以做适当修改。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|