

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向网络科技监测的分布式定向资源精确采集研究和应用*
引用本文
谢靖, 曲云鹏, 刘建华. 面向网络科技监测的分布式定向资源精确采集研究和应用* . 现代图书情报技术, 2011, 27(7): 26-31
Xie Jing, Qu Yunpeng, Liu Jianhua. Targeted Websites Distributed and Precise Harvest System for Network Monitoring Technology. 现代图书情报技术, 2011, 27(7): 26-31
Permissions
Xie Jing, Qu Yunpeng, Liu Jianhua. Targeted Websites Distributed and Precise Harvest System for Network Monitoring Technology. 现代图书情报技术, 2011, 27(7): 26-31
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
面向网络科技监测的分布式定向资源精确采集研究和应用*
摘要
在分析研究现有开源信息采集系统的基础上,综合应用开源框架,以开源爬虫Crawler4j为基础,设计开发基于开源框架的分布式定向资源采集系统,实现对网络信息实时精确的采集,以满足网络监测系统的及时性和准确性的要求。主要介绍系统的结构设计和功能实现,并详细阐述精确采集的方法和技术路线。
关键词:
监测; 分布式; 精确采集
中图分类号:G250
Targeted Websites Distributed and Precise Harvest System for Network Monitoring Technology
Abstract
By analyzing the existing open-source framework collection system, an accurate acquistition system is designed and developed based on Crawler4j. So the system can meet the real-time monitoring of collection of resources and accuracy requirements. And the paper introduces the design and implementation of the system.
Keyword:
Monitoring; Distributed; Precise harvest
1 引言
网络科技监测要求在最短时间内获取并分析各科研机构在某个学科领域发展动态的相关信息,因此,与一般的网络信息采集技术相比,面向网络科技监测的信息采集系统对信息的实时性和准确性有较高要求,这一认识对制定战略规划、调整战略布局,有着重要的意义。由于监测领域内的网站群具有种子站点多、目录结构复杂、层次多样的特点,因此,为了满足监测课题的需要,定向采集功能的设计需要满足以下两个要求:
(1)制定合理的采集周期,完成对多站点、多目录的采集任务,及时发现网络中发布的新消息、新内容。
(2)实现对站点内容的批量和增量采集,并能够过滤掉无关信息,精确定位到监测课题关注的信息内容,保障采集内容不被淹没在信息噪声中。
从以上需求出发,本文以开源爬虫Crawler4j为基础,利用正则表达式和网页特征库对噪声页面进行过滤,实现对主题相关网页的精确采集。同时,设计开发了针对多节点爬虫的中控调度模块,提高了采集系统的效率,满足了网络监测系统的及时性和准确性的要求。
2 开源采集系统分析
目前,基于Java平台的开源爬行软件较多,本文调研了较有影响力的采集项目,包括用于广域网范围内采集的Apache Nutch和Heritrix。同时,也包括简单小巧的轻量级采集工具Crawler4j,可以根据项目需要,在开源框架基础上,量身定制采集功能。
2.1 Nutch
Nutch[ 1] 是 Apache 基金会的一个开源项目,起初是开源文件索引框架 Lucene的子项目,后来渐渐发展为一个独立体系。它采用Java语言开发,基于 Lucene 框架实现网络信息采集功能。
Nutch分为网页爬虫(Crawler)和搜索引擎(Searcher)两部分。网页爬虫用于从网络上抓取网页并为网页建立索引。搜索引擎则利用索引并依据用户输入的关键词生成检索结果。Nutch的突出特点表现在,它提供了一种插件框架,能够对网页内容的解析以及数据的采集、查询、集群、过滤等功能进行扩展,简化插件开发,极大地增强了Nutch的功能。
2.2 Heritrix
Heritrix[ 2]是互联网档案馆(http://www.archive.org)上的开源产品,利用Heritrix的组件,可以自定义抓取逻辑,表现出强大的可扩展性,但配置过程比较复杂。另外,Heritrix可以准确地获取和存储网站上的文本和非文本信息,不对页面进行任何修改,但是抓取速度较慢并且需要足够的存储空间和网络带宽。Heritrix可以通过网络控制管理界面进行启动和监控,在重新爬行时对相同的URL不进行替换。
2.3 Crawler4j
Crawler4j[ 3]是用Java编写的开源项目,它支持多线程方式采集网站信息,并利用正则表达式限制采集对象。Crawler4j具有完整的爬虫功能框架,小巧灵活并可以独立运行。因此,易于集成到项目中,或者将第三方业务逻辑嵌入工作流中自定义爬行。
2.4 开源系统分析
通过对以上三种爬虫的分析调研,针对网络科技监测的任务需要,从采集准确度、采集效率、可控性、集成性、资源消耗5个方面对三种爬虫做了对比,结果如表1所示:
(1)Nutch在爬行过程中分层对网页内容抓取,爬
| 表1 爬虫性能对比 |
行过程不可分割,不便于在每层加入自定义的抓取策略,因此抓取内容、抓取路径和抓取准确度难以控制,会产生较多主题信息无关的页面,这些信息噪声影响科技监测系统对信息精确度的要求。另外Nutch与Hadoop集成,系统复杂度高,对Nutch系统Crawler模块的分离、集成难度大。
(2)Heritrix可以详细定制所需要抓取的资源类型和抓取策略,但是对比其他采集系统,其配置复杂度高,抓取过程对服务器的存储和带宽消耗较大,采集速度较慢、效率较低,不能满足科技监测对采集信息的实时性要求。
(3)Crawler4j虽然整体功能上没有Nutch和Heritrix强大,但是具有小巧灵活的特点,它开放了抓取过程中的各种事件功能接口,可以方便地嵌入自定义抓取策略,实现抓取内容、抓取路径和抓取精确度的控制。而且Crawler4j属于轻量级的采集系统,对服务器的带宽和存储资源消耗较小,方便集成到监测系统的采集平台上。因此将Crawler4j作为科技监测采集系统的首选方案。
3 基于开源框架分布式采集系统设计
3.1 系统目标
网络科技监测对信息实时性和准确性的特定要求,需要采集爬虫的支持。但是对于采集目标相对固定和明确的网站,可以使用轻量级爬虫提高任务运行效率并减轻采集服务器和被检测站点服务器的运行负担。本课题需要监测大量网站,每个网站下又需要监测爬行十几个到几十个详细目录。因此,要在指定时间内完成采集任务,就需要将其分散到分布式采集系统的不同采集节点上。同时,采集节点还应该能够根据任务需要进行扩充、收缩和动态调配。
考虑到采集环境的复杂性及操作系统的异构性,需要设计基于纯Java开发环境并且与系统无关的分布式采集系统,用于保障分布式采集系统中每台计算机的计算能力、存储能力和网络吞吐能力得到充分利用。
基于以上因素,选择Crawler4j作为原型系统,并在Crawler4j基础之上进行开发,将其改造为一个符合项目需求的分布式资源采集系统,以支持多节点协同工作,并充分利用硬件与网络完成采集任务。
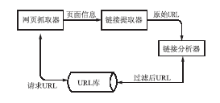
采集系统工作流程如图1所示:
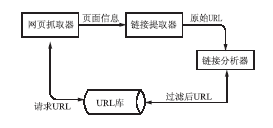 | 图1 基于Crawler4j的采集系统工作流程 |
以Crawler4j为基本框架,采用最新的Apache HttpClient作为网页抓取器,Cobra Parser作为链接提取器,并对采集工作流程做了适当的修改和调整。网页抓取器将指定的URL页面内容抓取下来,交由链接提取器提取出页面中包含的URL链接,链接分析器将提取出来的URL和URL库中的URL做比较,过滤重复的URL地址,将要采集的新URL写入URL库。之后网页抓取器再次从URL库提取新URL进行更深层次的抓取。
3.2 系统框架设计
基于对系统设计目标和Crawler4j开源框架的分析,对信息采集系统进行了详细设计,具体采集流程分为框架、通信机制和采集信令三部分。
(1)系统框架
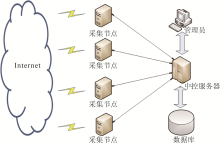
信息采集子系统框架结构如图2所示:
 | 图2 分布式采集系统框架 |
系统采用基于星型布局结构的分布式体系,由中控服务器和采集节点组成的多台服务器并发对种子网站列表进行采集。其中:中控服务器负责完成编辑工作,生成多个采集任务并将任务分发到采集节点计算机;采集节点是拥有不同的IP地址和一定网络吞吐能力的计算机,负责接收中控服务器发送的采集任务,并依据任务要求对Internet上指定站点的指定目录进行采集。其工作流程如下:
管理员编辑采集的站点和站点下采集的目录,并指定每个站点目次的采集深度、采集策略和采集频率,然后将设定好的采集任务按照指定的格式保存到数据库。中控服务器负责读取采集任务,按照指定的时间和频率生成采集任务,并插入到采集队列。采集节点与中控服务器计算机建立安全稳定的通信连接,从中控服务器的采集队列中申请采集任务,采集任务按照指定的信令格式发送到采集节点,按照任务内容对指定URL地址进行爬取。
(2)分布式采集通信机制
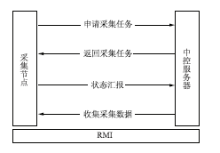
系统通信方式如图3所示:
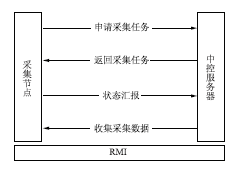 | 图3 系统通信方式示意图 |
在中控服务器和采集节点通信方式部分,项目组采用了RMI[ 4]远程调用方式,在中控服务器与采集节点计算机之间建立安全稳定的通信管道。在通信机制部分,以采集节点作为主动发起者,向中控服务器申请采集任务。中控服务器从任务队列中取出任务,返回给采集节点计算机。在一个采集任务完成之后,采集节点向中控服务器汇报当前采集状态,中控服务器根据每个采集节点的状态汇报,监控分布式采集的总体情况。在采集结束后,收集本次采集的数据,并交由导入程序,保存到采集系统数据库。
采集节点主动模式不需要中控节点轮询采集机器状态,可以有效地减少采集机器故障对整体采集系统造成的影响。当一台采集节点计算机出现故障时,该节点将停止向服务器申请新的采集任务,而该节点的采集任务会均匀分派到其他采集节点上。虽然会降低采集效率,但不会造成对目录采集失败的情况,可以保障数据采集的时效性和准确性。
(3)采集信令
采集信令是中控服务器和采集节点通信的标准指令。采集信令中包含完整的采集任务描述,在一次通信中,采集节点即可获得完整的采集任务详情,根据信令内容完成采集任务。采集信令包括:
①目录的ID号:目录的唯一标识符,由中控服务器统一分配。
②站点的ID号:识别该目录从属于哪个站点,由中控服务器统一分配。
③目录的URL地址:采集的起始地址(Seed URL),可以是多值。
④目录的限定域:限定采集在指定目录的URL,过滤指定目录之外的URL链接。
⑤目录采集线程数:该目录并行采集的线程数目。
⑥目录的采集深度:该目录的采集深度。
⑦目录采集TopN:每层目录采集的最大页面数量。
⑧采集附加参数:针对不同站点目录的个性化参数配置,例如:站点的链接等待时间、最大文件下载限制、登录认证、会话保持、Cookie管理等。
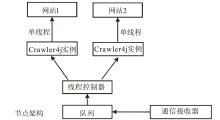
3.3 采集节点设计
节点是中控服务器的管理单元,每个节点可以配置若干个任务队列以备采集。节点中的通信接收器负责接收中控服务器的控制指令,并把所分配的任务列表保存入队列。在节点设计中,配置了一个线程控制器,负责对线程的分配调度。根据单个节点的带宽、负载能力等因素,在线程控制器中对并发采集数量进行配置,使系统的性能和稳定性达到平衡。
为了减轻对象服务器的压力,采取了如下的策略,即针对每一个需检测站点只启用一个线程对其进行采集,线程控制器根据节点上的配置决定同时运行的线程数。当一个采集线程完成时,线程控制器会启动队列中下一个处于等待状态的线程并开始采集。节点设计如图4所示。
3.4 采集工作流程
为了更好地对采集流程进行控制,采集工作并没有采用采集-解析并行的策略,而是使用了串行策略,即完成了采集任务之后再开始对所采集的HTML内容进行解析。系统利用采集任务中的控制单元控制采集
 | 图4 节点架构图 |
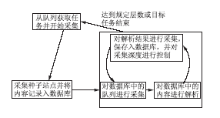
进度,利用数据库作为标志位的记录地点。当任务中的采集部分完成后,控制单元开始接收信号,将采集进程设为休眠状态,并启动解析进程。解析进程将所采集页面内容解析完毕并加入队列后,控制单元将使解析进程进入睡眠状态,并启动采集进程。这种方式间接地减轻了对象服务器的负载,使系统稳定性得到了一定的提高。采集工作流程如图5所示:
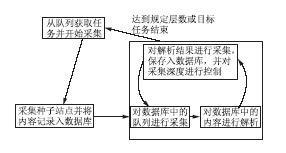 | 图5 采集流程图 |
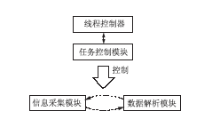
其中涉及到主要模块及模块间的关系如图6所示:
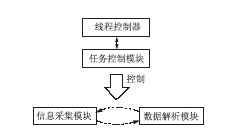 | 图6 采集模块设计 |
(1)任务控制模块负责从队列中获取新的任务,并将旧的任务设置为“完成”。控制采集深度,在达到规定采集深度时停止采集,并通知解析模块开始工作。在整体任务完成时通知线程控制器进行下一个网站的采集检测。
(2)信息采集模块以Crawler4j为基础,并进行了一定改造。尽管策略上对单一站点采用了单一线程进行采集,但是可以根据情况修改针对单一网站的线程数,提高采集性能。
(3)数据解析模块使用了Cobra引擎[ 5]。Cobra是一个HTML工具包,它包含一个纯Java HTML DOM 分析器和一个页面表现引擎。Cobra支持HTML4、JavaScript 和CSS2。
4 系统功能实现
为了方便对分布式采集系统的管理,设计实现了站点编辑、采集目录精确控制、采集、节点监控、数据审核等功能集中为一体的管理系统,使得管理员根据UI显示情况全面掌控采集系统当前状态。
4.1 采集站点目录管理
站点编辑列表如图7所示:
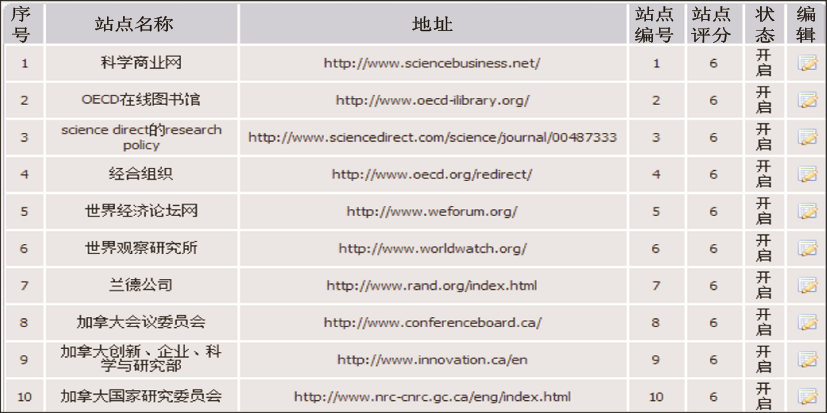 | 图7 站点编辑列表 |
站点编辑列表提供采集站点的添加、修改、删除等站点编辑功能,使管理员可以对所有采集站点进行监控和管理,管理员可以自由调整采集策略,对站点采集进行开启和关闭。站点信息包括站点名称、英文名称、站点地址、站点描述、站点所属国家、站点类型等。同时还可以对站点进行评分,该评分将影响采集结果的显示排序。
4.2 采集精准度控制
(1)目录精准度控制为保证采集的准确性,采集策略中对每个站点采集操作精确到目录,将每个站点详细划分为若干个目录,确定每个目录采集起始URL地址,从而对该目录下的网页内容进行2-4层采集。这样的采集策略既可以减少采集机器负担,又能减少对方网站的访问压力,把采集到的页面更准确地定位到监测课题相关的最重要、最关注的信息上,降低无关页面的干扰。
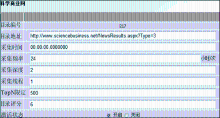
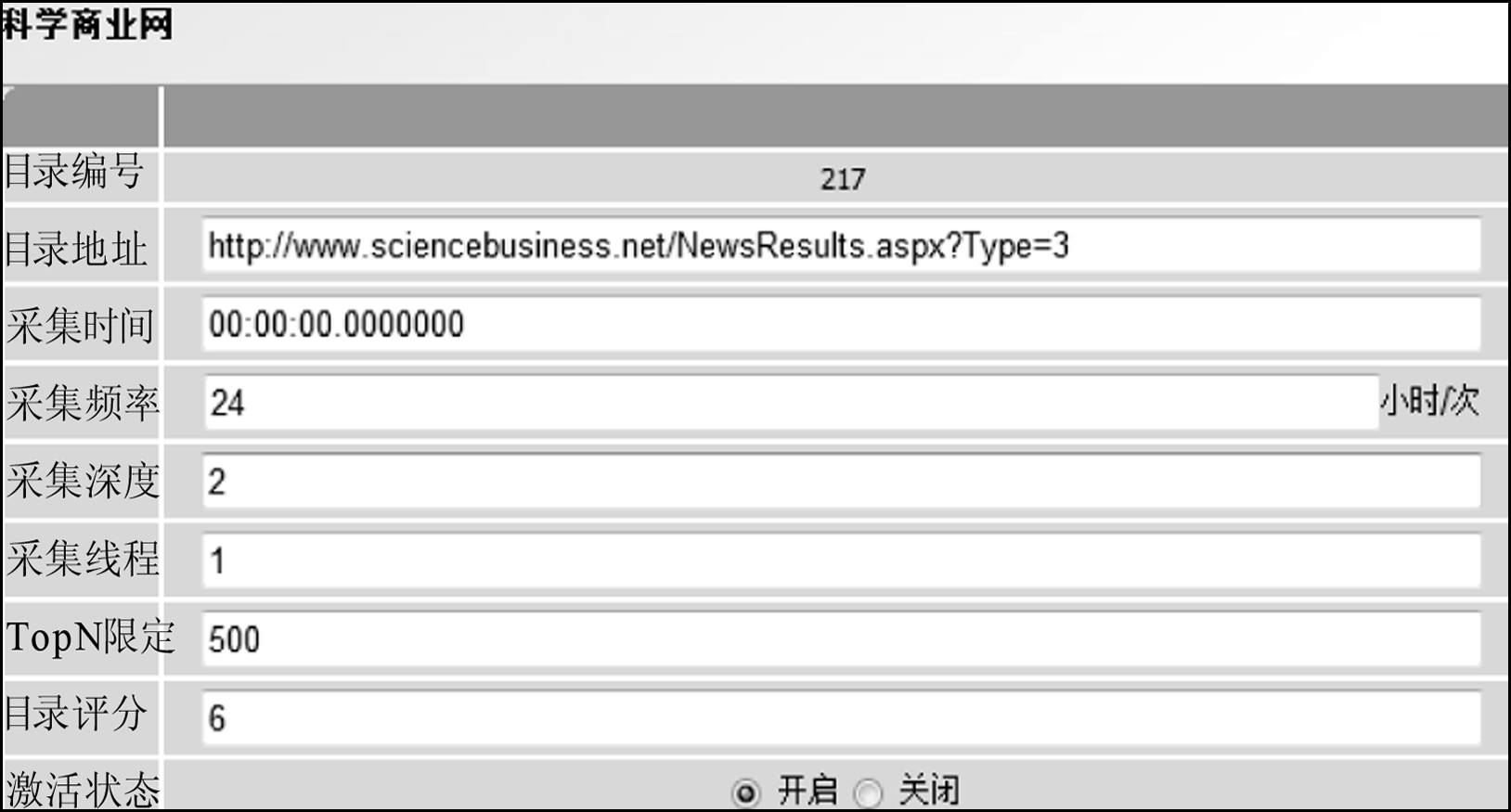
目录编辑实例如图8所示:
 | 图8 目录编辑实例 |
由图8可见,系统可以精确地设定每个目录的采集时间、采集频率、采集深度、采集线程等。其中,采集时间为开始采集该目录的准确时间;采集频率为根据监测的需要对该目录设定多长时间爬行一次;采集深度为需要爬行该目录下几层的深度;采集线程为同时开启几个线程对该目录进行爬行,可以根据网站容量和目录下页面的数量进行定制;TopN限定为每张页面下包含过多链接时候,限定最多采集链接数;目录评分类似于站点评分,支持对每个目录的具体评分。
根据目录所包含页面的数量,调整采集线程数,让包含较多页面的目录采集线程多一些,以便在指定时间内完成采集任务;还可以根据某个目录的更新频率,调整采集的频率,减少更新较少的目录采集次数,缓解采集压力,形成一套可以灵活定制的采集策略方案。
(2)页面信息精准度控制
在每一层的页面采集中,都包含不需要的页面链接,如广告、菜单、联系方式等与主题信息无关的链接。在传统的信息采集系统中,追求广而全的采集方式,将主题信息无关的信息都纳入采集过程之中,与监测系统相关的页面信息就会淹没在大量无关信息噪声中,对科技监测的需求造成较大影响。
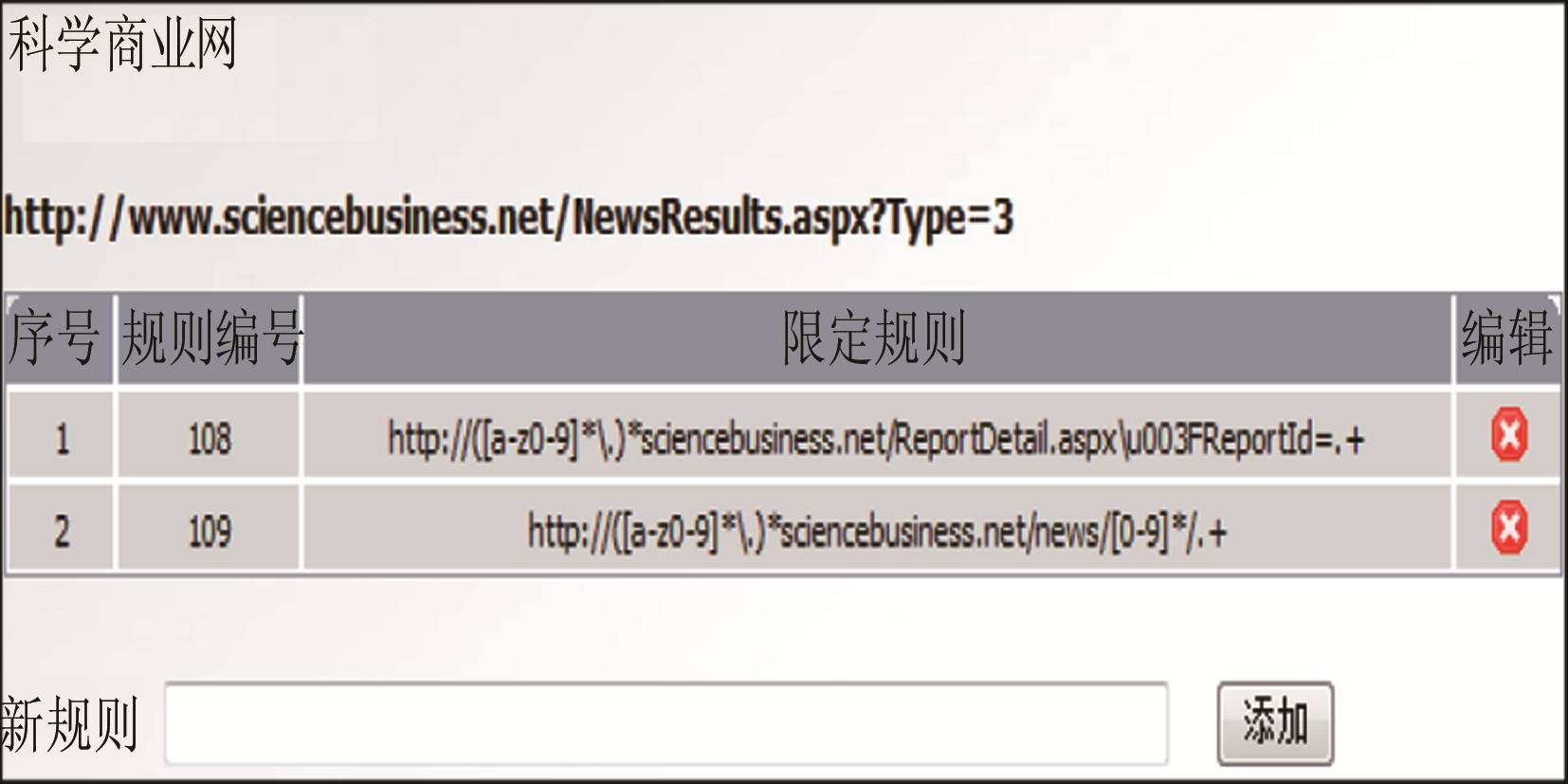
为更一步精确需要采集的信息,过滤页面上的干扰链接,针对每层目录设定采集限定规则。该限定规则由一组正则表达式[ 6]组成,根据页面包含URL的特征进行匹配对比,精确过滤出页面上需要爬取的主题相关链接,去除不需要的干扰链接,实现对每张页面上链接的筛选。正则表达式本身既可以放宽对URL的限定,又可以收缩限定,从而可以根据需要灵活定制,如图9为科学商业网其中一个目录的限定规则编辑实例。
 | 图9 限定规则编辑 |
4.3 采集应用效果评估
采集系统在科技政策领域的应用中,部署一台采集中控服务器,三台PC作为采集节点,以每天一次的频率,对领域内收录的84个站点,涉及202个目录进行连续6个月的不间断采集。
(1)采集实时性:经过统计,采集任务利用每天夜间网络空闲时刻4-5小时内完成,完全可以满足信息实时性的要求。
(2)采集准确度:系统共采集新页面数量61 571个,被监测系统采纳主题相关页面数量43 176个。采集统计准确度为70.12%。准确度达到网络科技监测系统初步数据筛选的要求,在今后还有待于提高。
5 结语
该采集系统在网络科技监测领域采取每日增量采集的运行方式,发现监测领域站点群各个目录中出现的新页面和新内容,从而给网络科技监测系统提供每日最新的数据。采集工作的效率能够满足网络科技监测的任务需要,根据每层页面特征采取正则表达式的方式限定采集URL,一定程度上使得采集信息精确度得到很大提升,但是在实际测试数据中仍会出现少量干扰页面还不能过滤。此外,系统设计没有考虑集成RSS和Ajax页面的解析和提取,有待于后续的研究来改进。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|