
{kind=link}
搜索引擎的灵敏度和特异度研究
引用本文
张李义, 陈明英. 搜索引擎的灵敏度和特异度研究. 现代图书情报技术, 2011, 27(7): 41-46
Zhang Liyi, Chen Mingying. Research on the Sensitivity and Specificity of Search Engines. 现代图书情报技术, 2011, 27(7): 41-46
Permissions
Zhang Liyi, Chen Mingying. Research on the Sensitivity and Specificity of Search Engines. 现代图书情报技术, 2011, 27(7): 41-46
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
搜索引擎的灵敏度和特异度研究
关键词:
搜索引擎; 筛检; 灵敏度; 特异度; 用户体验
中图分类号:TP393
Research on the Sensitivity and Specificity of Search Engines
Abstract
This paper analyzes the evaluation indexes of Web search engines using the epidemiological screening theory without gold standard. User experience score and user judgment are used as the prior information of Bayes estimation. Then it maks use of the MCMC(Markov Chain Monte Carlo)technology to estimate the sensitivity,specificity and detection rate of Baidu and Google(Simplified Chinese).
Keyword:
Search engine; Screening; Sensitivity; Specificity; User experience
1 引言
截止到2010年12月底,我国网民总数达到4.57亿,互联网普及率为34.3%[ 1],搜索引擎用户数达到3.75亿,位居各种网络应用使用第一位,成为网民上网的主要入口[ 2]。同时搜索引擎评价指标体系也在不断完善中,但以用户体验为主导的评价指标还有待发掘。
本文首先介绍搜索引擎评价的研究现状,包括研究的意义和方法、搜索引擎的综合评价指标,以及在查全率和查准率基础上扩展和定义的评价指标;然后构建基于筛检理论的评价指标,并以Google简体中文(简称Google)和百度为例进行实证分析;最后讨论实验结果。
2 搜索引擎评价研究背景
搜索引擎评价研究既能指导用户选择最适合自己的搜索策略,也能促进搜索引擎研发人员通过改进技术进而不断完善检索功能,同时对于丰富传统情报检索理论也有重要意义。搜索引擎评价研究的方法主要包括调查法、实验法、观察法、数据分析等[ 3]。在20世纪50年代,信息检索系统的评价指标体系研究已经开始。1994年网络搜索引擎出现之后,评价指标体系得到了全方位和多角度的完善,出现了针对搜索引擎的综合评价指标及细分[ 4, 5, 6, 7],但查全率和查准率一直是搜索引擎评价指标的研究重点[ 8]。 由于网络信息难以测量,Leighton等提出了“相关性范畴”,并在此基础上提出“前命中记录查准率”的概念,用来反映检索工具在前k个检索结果中向用户提供相关信息的能力[ 9]。部分学者也对查全率和查准率进行了相关改进研究[ 10, 11],并扩展和定义一些新的评价指标[ 12],包括:正确率-召回率曲线(Precision-Recall Curve)[ 13]、MAP(Mean Average Precision)[ 14]、P@k(Precision at k)[ 15]、ROC曲线(Receiver Operating Characteristics Curve)[ 16]、归一化折损累计增益 (Normalized Discounted Cumulative Gain,NDCG)[ 17]等。
(1)正确率-召回率曲线是对前k个(k=1,2,…)有序检索结果集,分别以正确率和召回率作为纵坐标和横坐标在平面上描点得到的曲线。为了消除曲线的锯齿状,定义了在某个召回率水平r上的插值正确率(r'为任意不小于r的召回率):
pinterp(r)=maxr'≥rp(r')
(2)MAP是TREC(Text REtrieval Conference)最常规的评价指标之一,它可以在每个召回率水平上提供单指标结果,具有很好的区别性(Discrimination)和稳定性(Stability)。设信息需求qj∈Q对应的所有相关记录集合为{d1,d2,…,dmj},Rjk是返回结果中直到遇见dk后其所在位置前(含dk)的所有记录集合,则:
MAP( Q) = 
(3) P@k称为前 k个结果的正确率,如: P@10。使用该指标不需要计算相关记录集合的数目,但相关记录的总数会对 P@k有很大影响,导致它不稳定。若事先知道相关结果集 Rel,然后计算出前 |Rel|个结果的正确率就能很好地弥补 P@k的不足。
(4) ROC曲线是基于敏感度和1 -特异度的曲线,通常以曲线下方的面积为指标计算检索效果。
(5) NDCG是针对非二值情况下的指标,是基于前 k个检索结果进行计算的。设 R( j, d)是评价人员给出的记录 d对查询 j的相关性得分,那么有:
NDCG(Q,k)= 
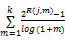
其中, Z j, k是归一化因子,用于保证对于查询 j最完美系统的 NDCG at k得分是1, m是返回记录的位置。
目前,对搜索引擎评价的研究很多都停留在描述阶段,并且没有把用户的主观判断作为影响因素体现在评价指标中。无论搜索引擎提供多少相关链接,用户只浏览前4至5个结果页面,因而搜索结果的质量远比搜索结果的数量重要。在前 k个检索结果中,基于用户相关性范畴判断的查准率和查全率反映了搜索引擎提供相关信息的能力,在很大程度上体现出检索结果的质量。因此,对基于相关性范畴的指标的量化是一个很重要的研究方向。
3 利用无金标准的筛检理论构建搜索引擎评价指标
筛检(Screening)是在大量表面上无病的人群中通过快速简便的方法,去发现那些未被识别的、可疑的病人或有缺陷的人,常用的筛检方法是把金标准作用于实验对象进行诊断,灵敏度和特异度是衡量诊断效果的重要指标。所谓“金标准”是指当前临床医学界公认的诊断疾病的最可靠方法。灵敏度和特异度越大,表示该方法正确判断“病人”和“非病人”的能力越强,相应的Youden Index(约登指数,值为灵敏度+特异度-1)综合反映了该方法的诊断能力[ 18]。用户利用搜索引擎检索的过程与通过试剂确诊病例的筛检过程是一致的,因而可以借鉴无金标准筛检实验的灵敏度和特异度指标评价搜索引擎。运用贝叶斯原理进一步计算出搜索引擎的灵敏度和特异度。
3.1 模型假设
(1)相关性范畴
相关性范畴是对检索结果与用户期望结果之间相关性的描述。针对网络搜索引擎本文把相关性分为三个等级[ 4],如表1所示:
| 表1 相关性范畴的等级和权重 |
(2)页面权重
由于时间、精力或者从已经阅读过的记录中得到相关信息等原因,用户不会看完所有检索结果。因而在搜索引擎的结果序列中,排序越靠后其价值越小,相应的权重也越小。根据iProspect的统计结果:56.6%的用户只看搜索结果前2页的内容,大约16%的用户只看搜索结果的前几条内容,只有23%的用户会查看第2页的内容,查看前3页的用户数量下降到10.3%,愿意查看3页以上内容的用户只有8.7%[ 19]。本文对检索结果的各页赋以权值,如表2所示:
| 表2 页面权重 |
(3)用户体验得分
根据相关性范畴对结果页中的每条记录判断得分,再把10条记录的得分相加后乘以该页的权重,得到用户体验得分。用户体验是一种纯主观的在搜索用户使用产品过程中建立起来的感受,但用户体验的共性能够通过调查和数据统计认识到。
(4)用户判断
一条信息是否满足用户的需求,并不是它包含查询中的关键词,而是内容上有很大的相关性,用户能够基于自己的信息需求判断返回结果的准确性。查询是否达到了目的,或者是否找到了想要的答案,用户自己有“是”或“否”的准确判断,这个二值判断称为用户判断。
(5)二值判断
筛检实验结果为“+”和“-”,为了把用户体验得分转化为二值判断,本文以用户体验得分的均值为阈值,大于阈值的为“+”,用1表示,反之用0表示;用户判断为“是”的用1表示,反之用0表示。
(6)根据流行病学中灵敏度、特异度、检出率以及Youden Index的定义[ 18],给出搜索引擎的灵敏度、特异度、检出率以及Youden Index的定义,如表3所示:
| 表3 搜索引擎的灵敏度、特异度和检出率的定义 |
灵敏度= 
特异度= 
检出率= 
Youden Index=灵敏度+特异度-1,衡量搜索引擎辨认相关信息和不相关信息的总能力。
3.2 模型建立
= 
=θ 
=(1-θ) 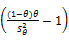
(πS1(1-S2))v((1-π)(1-C1)C2 
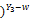

贝叶斯参数估计方法的基本思想为:参数后验密度与先验密度和似然函数之积成比例[ 20],如果收集到用户体验得分和用户判断的数据,就可以通过贝叶斯方法对搜索引擎指标的后验分布做出评价。
(1)求先验分布参数
利用贝叶斯原理确定先验信息时主要涉及两方面问题:确定先验信息的类型和先验分布的超参数[ 21]。就搜索引擎的用户体验而言,涉及到的重要指标是灵敏度、特异度和检出率,由于它们都属于率的指标,因而服从二项分布。二项分布的共轭分布为贝塔分布[ 22],故可以用贝塔分布作为灵敏度、特异度和检出率的先验分布,保证了其后验分布和二项分布有相同的核,使计算得以简化,并且能使后验分布的超参数得到很好的解释。
贝塔分布有两个超参数α、β,设θ是总体分布的超参数(如灵敏度、特异度),可得密度函数[ 23]:
F(θ)= 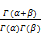
把贝塔分布作为检索评价指标(灵敏度、特异度)的先验分布后,最重要的是确定先验超参数α、β。在共轭先验分布的条件下,先验矩、分位数、众数与分位数三种方法确定的先验分布超参数结果是一致的[ 24]。在这里用先验矩法。
根据实验可收集到灵敏度、特异度的实验数据,将此作为先验信息可得先验均值θ和先验方差 
θ=
 | (2) |
 | (3) |
联立式(2)和(3)可得超参数α与β的估计值:
 | (4) |
 | (5) |
(2)求似然函数
N表示样本总体,π表示检出率,S1、S2和C1、C2分别代表Google和百度的灵敏度及特异度,Y1、Y2、Y3、Y4表示两种检测结果共同的观察值,则Y1+Y2+Y3+Y4=N;u、v、w、x和Y1-u、Y2-v、Y3-w、Y4-x分别表示达到搜索目的和未达到搜索目的潜在真值。可以导出两种检索结果所有可能性的似然分布(Likelihood Contribution),如表4所示:
| 表4 两个搜索引擎的似然贡献 |
L(X|π,C1,C2,S1,S2)∝(πS1S2)u((1-π)(1-C1)(1-C2)
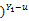 | (6) |
(3)计算方法
根据贝叶斯原理,整合先验分布与似然函数[ 23],导出全条件分布中各参数的后验密度。利用MCMC技术,选取适合于全条件分布的Gibbs抽样算法构建Markov链[ 26],使其平稳分布与未知参数的后验分布是一致的,这样就可以从这个Markov链中通过反复抽样来构造参数的样本,进而可以估计出所要求的参数。贝叶斯估计过程在软件WinBUGS1.4中完成。
4 实例分析
4.1 实例
本次实验选择市场占有率和渗透率都非常高的Google和百度两个搜索引擎进行。假设用户使用Google和百度搜索是互不影响的、独立的。考虑到用户体验得分和用户判断均由用户主观判断所得,所以用问卷调查的方式获取数据。收集到的300份有效问卷由两部分组成: 23名电子商务硕士研究生填写23份,通过网络推广填写277份。调查的内容主要涉及学历、搜索条件、第1至5页各页相关记录条数、用户判断。根据相关性范畴和页面权重可计算出用户体验得分,然后把用户体验得分和用户判断转换成二值备用。
把收集到的300份问卷进行统计,最终得到的结果如表5所示:
| 表5 实验数据统计结果 |
其中,潜在真值“1”表示用户判断为“是”,即该用户达到了搜索目的,反之“0”表示未达到搜索目的。Google和百度对应的“1”和“0”表示通过用户体验得分进行的相应的二值判断。观测数表示对应前面三个实验结果的实验次数。
统计显示Google和百度的用户体验得分均值分别为2.4666和2.4159。把300次实验分为6组,分别统计出每组实验的灵敏度、特异度和检出率,运用矩估计法求出先验参数如表6所示:
| 表6 先验分布参数 |
进而可以得到待估参数灵敏度、特异度和检出率的先验分布为:
C1~beta(3.52,4.01),C2~beta(3.66,3.45)
S1~beta(12.20,5.06),S2~beta(29.14,6.32)(7)
π~beta(7.89,6.28)
本研究的资料利用MCMC技术将Gibbs抽样迭代36 000次,经5 000次迭代退火(Burn-in)后,已满足收敛要求,为此用后31 000次迭代结果作为Markov链进行参数估计,得到参数估计结果如表7所示,后验参数密度如图1所示,其中,c1、c2和s1、s2分别表示百度和Google的灵敏度和特异度,pa表示检出率。
| 表7 搜索实验的参数估计 |
 | 图1 搜索实验的后验密度分布 |
4.2 分析
从图1可以看出Google的灵敏度和特异度的均值分别为0.5227和0.8215,说明用户在Google上的体验是很好的,结果序列中有较多的准确信息排在前面。相对Google而言,百度的灵敏度和特异度都较小,分别为0.4685和0.7063,这也是由于调查群体的学历偏高致使外文搜索频率偏高的原因,因为百度主要以中文搜索为主,而在英文搜索上性能不及Google。检出率均值为0.5562,说明用户在使用这两个搜索引擎时对55%以上的检索是满意的。根据灵敏度和特异度可以算出百度和Google的Youden Index分别为0.1748和0.3442,表明这两个搜索引擎的检索能力还有待提升。
朱庆华等采用网上德尔菲法确定指标,并用层次分析方法确定指标权重构建评价指标体系,对6大搜索引擎(Google、百度、雅虎、搜狗、新浪、网易)进行评价,指出Google是性能最优的搜索引擎[ 27]。刘子慧等通过把11项搜索引擎评价指标聚合为内容准确性和内容直接性两项因素,最终指出Google的内容准确性比百度好,特别是在外文信息上有明显的优势[ 28]。毛晓燕建立搜索引擎用户满意度测评理论模型,构建搜索引擎用户满意度评价指标体系,得出总体满意度指数Google大于百度[ 29]。这些研究结论都与本文的结果一致。
5 结语
搜索引擎同质化倾向越来越强,当用户浏览检索结果的时候关心的是前k个结果中有多少条记录能找到自己想要的答案,并且希望越准确的记录排序越靠前。因而,建立衡量检索结果中有效结果数和其排列次序的指标(用户体验得分)是非常有意义的。用户使用搜索引擎是否达到了搜索目的,是用户体验后的主观判断。本文以用户判断为潜在真值,用户体验得分为实验检测值,估算出搜索引擎的灵敏度、特异度以及检出率。
查全率是衡量搜索引擎检出相关信息的能力,查准率是衡量搜索引擎检出信息的准确度的尺度。相比较而言,基于相关性范畴的前k个检索结果的灵敏度反映了搜索引擎能正确地把相关信息判断为“相关”并且排在前面的能力,特异度反映了搜索引擎正确地把不相关信息判断为“不相关”并排列靠后的能力。与传统信息检索相比,使用网络搜索引擎时,用户并不是希望得到很多而且很准确的信息,而是希望得到准确而且排序靠前的结果,因而需要搜索引擎能正确区分相关和不相关信息,这也是灵敏度和特异度所衡量的。
把流行病学的筛检理论应用到信息检索中只是提供了一种搜索引擎评价的思想,利用流行病学中一些相对成熟的理论完善搜索引擎的评价体系,还有需要改进的方面。为了更全面地了解目前的检索水平,样本群体覆盖可更加广泛,样本数量也可以更大。用户体验得分的确定很主观的过程,所涉及到的不确定因素还有很多,评价指标可以加以完善。实验检测数据的二值判断中阈值的确定是一个有待改进的地方,或者可以不转化为二值而直接对用户体验得分进行统计分析得出新的评价指标。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|