{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种基于P2P的云存储模型研究
引用本文
王亚民, 刘晓伟, 韩学铃. 一种基于P2P的云存储模型研究. 现代图书情报技术, 2011, 27(7): 56-61
Wang Yamin, Liu Xiaowei, Han Xueling. A Cloud Storage Model Based on P2P. 现代图书情报技术, 2011, 27(7): 56-61
Permissions
Wang Yamin, Liu Xiaowei, Han Xueling. A Cloud Storage Model Based on P2P. 现代图书情报技术, 2011, 27(7): 56-61
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
一种基于P2P的云存储模型研究
摘要
在分析当前云存储系统所面临的问题的基础上,提出一种基于P2P技术的云存储模型。此模型应用Chord算法来组织节点并分发用户的请求,解决集中式云存储系统的中心节点瓶颈问题,实现系统的负载均衡;使用存储簇来完成数据的存储和管理,简化系统管理的难度;并提出模型的副本管理策略,使云存储系统具有良好的可扩展性、容错性和高性能。
关键词:
云存储; P2P; 服务管理节点; 副本
中图分类号:G350
A Cloud Storage Model Based on P2P
Abstract
After analyzing the problems of current cloud storage, this paper presents a new cloud storage model based on P2P. This model applies Chord arithmetic in managing nodes and handing out clients’ requests, which solves the problems from the centralized structured architecture such as SPOF, performance bottleneck and so on, and realizes load balancing. The model takes advantage of storage clusters to manage users’ data, which simplifies the difficulty of system management. Also a replica management strategy is applied in this model, which achieves better scalability, fault tolerance and enhanced performance.
Keyword:
Cloud storage; P2P; Service management node; Replica
1 引言
云存储[ 1]是随着云计算的发展而产生的一个概念,它是指通过集群应用、网格技术或分布式文件系统等功能,将网络中大量各种不同类型的存储设备通过应用软件集合起来协同工作,共同对外提供数据存储和业务访问功能的一个系统。云存储专注于向用户提供以互联网为基础的、高可靠性的在线存储服务,能够满足Web 2.0应用对数据存储的要求。
设计一个高性能的云存储系统面临着许多挑战,如异构性、分布性、扩展性、透明性、并发性、可靠性和效率等问题。现在的一些主流的云存储系统,比如Google的GFS[ 2]、亚马逊的弹性云[ 3]、开源的HDFS[ 4],都采用了相似的集中式的架构,系统中均存在一个中心服务器来负责管理系统中的数据存储节点,用户的所有数据存储和检索请求都需要经过中心服务器的处理。在这样的架构中,存在着单点失败(Single Point Of Failure,SPOF)的巨大风险,中心服务器很容易成为系统的瓶颈,一旦崩溃,就可能导致整个云存储服务的不可用。尽管这些系统中都对中心服务器采取了备份策略,但并未从根本上解决这一问题。而且,随着系统负载的增加,系统的扩展性不好,对系统的压力会越来越大。 P2P的许多特点,如非中心化、可扩展性、健壮性、高性能和负载均衡等,都契合了云存储的设计要求。本文结合P2P的相关思想和技术,提出了一种基于P2P技术的云存储模型,应用Chord算法来组织服务管理节点并分发用户的请求,使用存储簇来完成数据的存储和管理。将P2P技术应用在云存储系统的设计中,可以在云存储系统中发挥P2P技术的优点,能够有效地解决集中式云存储系统的中心节点瓶颈问题,将系统负载均分到多个服务节点上,实现了系统的负载均衡,从而有效地利用了系统资源,极大地提高了云存储系统的性能和云存储服务的质量,增强了服务的可靠性。
2 P2P技术与云存储
P2P技术[ 5]是一种网络新技术,依赖网络中参与者的计算能力和带宽,而不是把依赖都聚集在较少的几台服务器上,它的核心是“去中心化”。分布式哈希表(Distributed Hash Table,DHT)[ 6]是一种应用于结构化P2P网络的分布式存储方法,采用一致性哈希算法,在不需要服务器的情况下,每个客户端负责一个小范围的路由,并负责存储小部分数据,从而实现整个DHT网络的寻址和存储。一些实现了DHT的代表性算法有Chord[ 7]、CAN[ 8]、Pastry[ 9]、Tapestry[ 10]等。
Chord通过把节点和Key映射到相同的空间而保证一致性哈希,为了保证哈希的非重复性,Chord选择SHA-1作为哈希函数,SHA-1会产生一个2160的空间,每项为一个16字节的大整数。可以认为这些整数首尾相连形成一个环(Chord环)。整数在Chord环上按大小顺时针排列,节点(机器的IP地址和Port)与Key(资源标识)都被哈希到Chord环上,这样整个P2P网络的状态可以被看作一个虚拟的环,形成一个结构化的P2P网络。每个在Chord中的节点只需要知道其他少数节点的路由消息,因为Chord中的路由表是分散的,每个节点通过和少数节点交流来获取路径信息。一个N个节点的系统在稳定状态的时候,每个节点仅仅保持O(log N)个其他节点的信息,查询操作也需要发送O(log N)条消息到其他节点。当有节点加入和离开操作系统时,所产生的消息量在绝大多数情况下不超过O(log2N)。应用Chord算法的P2P系统具有良好的可扩展性,能够提供一定程度的负载均衡。
云存储是与云计算同时兴起的一个概念,是分布式存储技术的最新发展,是云计算的基础,云计算中的操作系统、相关服务程序及用户的海量数据等都必须保存在云存储系统中。Google提出的GFS是一个可扩展的分布式文件系统,它可以运行在普通的PC上,但可以提供强大的容错功能,给大量的用户提供总体性能较高的服务,能够满足对大量数据进行访问的应用。系统中存在单个中心索引服务器主Master对集群进行协调访问,保存元数据,并对元数据做备份。GFS的这种架构简化了系统的维护和管理,但中心索引服务器可能会成为系统性能的瓶颈。
3 基于P2P技术的云存储模型
3.1 基于P2P技术的云存储模型结构
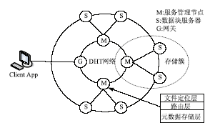
本文提出的基于P2P的云存储模型是个双环的结构,如图1所示:
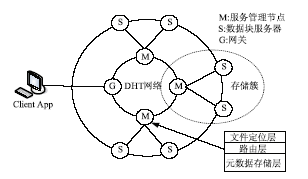 | 图1 基于P2P的云存储模型 |
将提供云存储服务的数据中心的服务器分成两部分,性能高、处理能力强的服务器组成内环的服务管理网络提供元数据等信息的存储和管理,采用DHT网络对内环的服务管理节点进行组织;普通的性能一般的服务器组成外环的数据存储网络来完成对用户数据的实际存储。外环的每一个数据块服务器(Chunk Server)将被指定一个内环的服务管理节点对其进行管理,一个服务管理节点将管理本区域内的所有数据块服务器,形成存储簇(Storage Cluster),完成对用户数据的实际存储。模型涉及4种角色:客户端、网关、服务节点和数据块服务器,主要功能如下:
(1)客户端(Client App):这里的Client App是指使用云存储服务的主体,根据自己的需求向云存储系统发出数据存储或是检索的请求。
(2)网关(G):所有来自Client App的请求首先到达网关,网关和服务管理节点一起由DHT网络进行管理,网关使用DHT算法计算出应该处理文件元数据所在的服务管理节点,然后根据其路由表转发请求。由于网关本身是无状态的,只是用来管理会话和转发请求,因此不会成为系统的瓶颈,即使出现宕机的情况,也不会丢失任何数据,可以迅速得到恢复。
(3)服务管理节点(M):服务管理节点需要管理本区域内的所有数据块服务器,监测它们的运行情况,处理Client App发出的请求信息,并需要对相邻服务节点的元数据进行备份。
(4)数据块服务器(S):数据块服务器完成实际的数据存储,接受本区域服务管理节点的管理。
3.2 服务管理节点网络
在本模型的设计中,服务管理节点之间采用Chord算法组成一个逻辑的环状覆盖网络(Overlay Network),通过这种分布式的存储方式,每个节点只需要负责小范围的路由,并管理一部分的数据块服务器,从而完成对网络的寻址和存储。服务管理节点采用分层结构(见图1),包括文件定位层、路由层和元数据存储层;各层需要实现的主要接口如表1所示:
| 表1 服务管理节点各层需要实现的主要接口 |
文件定位层和路由层实际上构成一个DHT网络,应用Chord算法对用户的请求进行分发和路由,通过DHT网络,请求能够被均匀地分发到各个节点,使系统具有良好的负载均衡。节点间采用DHT网络连接,当有新的节点加入时,节点需要执行Chord算法的加入协议,将一些其他节点加入到它的路由表中,并且需要将它的加入通知其他节点。某个节点的离开也类似此过程。总之,服务管理节点网络的构建类似于一个P2P网络的构建。元数据存储层存储与本节点有关的文件元数据信息,比如文件大小、文件ID、文件块对应的数据块服务器信息、版本号等。通过对元数据存储模块进行查询,存储系统能够快速、准确、完整地定位需求的文件。这样就实现了索引同存储相分离,同时避免了中心节点的瓶颈现象,提高了系统的性能。
3.3 存储簇
将云存储系统分成多个存储簇,每个存储簇由一个服务管理节点和多个数据块服务器组成,完成对数据的实际存储和管理。服务管理节点对集群内部的数据块服务器进行管理,监控块服务器的运行,为要存储的数据提供存储的位置、文件块和数据块服务器的映射信息等元数据信息。存储簇对文件的存储采用分块的方式,数据块服务器与Client App交互,完成对数据块的存储和数据的更新。
数据块服务器需要向服务管理节点发送心跳包来报告自己的状态信息,如果数据块服务器出现故障,服务管理节点需要及时获悉这一情况,并采取相应的措施来恢复失效节点的数据,从而维持整个系统的稳定,避免数据的丢失。此外,服务管理节点需要对所管理的数据块服务器的使用和运行情况信息进行统计,包括CPU性能、内存、带宽和硬盘剩余等。服务管理节点通过这些信息可以获得各数据块服务器的运行情况,当向Client App返回用于数据存储和检索的数据块服务器列表时,能够根据各数据块服务器的运行情况对其进行评定,使得Client App能够选择运行情况相对良好的数据块服务器来处理相关的请求,从而提高系统的整体性能。
4 关键功能实现
4.1 文件的分块存储策略
GFS和HDFS都通过数据分块和复制来提供更高的可靠性和更好的性能,能够满足对大文件的存储需求。为了提高数据在系统中的安全性,本文提出的云存储模型采用信息扩散法(Information Dispersal Algorithms, IDA)来对数据进行分块。
信息扩散法[ 11]是指将一个长为L=|F|的文件F分成n片,每片的长度为|Fi|=L/m,1≤i≤n,使得从n个分块中任意取出m块就可以重构文件F,且分块文件的长度总和为(m/n)×L。算法的具体步骤[ 12]如下:
(1)设文件F由字符串组成,F=b1,b2,…,bN,其中字符bi∈[0,…,B]且b∈Z(B=2l-1,l为一个字节拥有的位数);取最小的大于B的素数p作为该文件中字符运算的模,该字符串中所有元素上限为Zp。
(2)选择一个合适的整数m,令n=m+k,其中m/n<1+ε,ε>0。
(3)选择n个向量ai=(ai1,ai2,…,ain)∈ 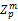
(4)利用选择的向量组对F进行拆分,把文件F分成长度为m的序列,则:
F=(b1,b2,…,bm),(bm+1,bm+2,…,b2m),…
令s1=(b1,b2,…,bm),s2=(bm+1,bm+2,…,b2m),…,
则Fi=ci1,ci2,…,ciN/m,其中i=1,2,…,n且cik=ai·sk= ai1·b(k-1)m+1+…+aim·bkm
|Fi|=|F|/m
(5)利用选择的向量组对矩阵F进行重组。
如果文件F的m个分块F1,F2,…,Fm已经给出,那么可以依照以下步骤重建文件F。
让A=(aij),1≤i,j≤m是一个m×m矩阵,其中第i行为ai,可以看出:
A·[b1,…,bm]T=[c11,…,cm1]T,则[b1,…,bm]T= A-1·[c11,…,cm1]T,其中,bj=ai1cik+…+aimcmk,1≤j≤N
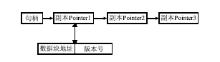
通过此算法对数据文件进行分块,数据不会被非法识别,极大地增强了云存储中数据的安全性和保密性,数据的分块存储也提高了系统的可用性和云存储系统的容错、容灾的能力。服务管理节点按照此算法对数据文件进行分块,对每个分块数据用一个128位的句柄进行表示,并且为每个数据块设置一个版本号,用于数据块副本间的一致性管理,文件元数据副本之间形成一个链表。服务管理节点上的数据块存储结构,如图2所示:
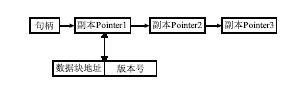 | 图2 文件元数据存储结构 |
4.2 副本管理
在本文提出的云存储模型中,由于提供数据存储的服务器可以是普通的PC,节点失效应该被视为一种常态,为了保证数据的可靠性和可用性,需要对数据进行多点备份,多点备份能够提高云存储系统的性能和可靠性,因此副本管理是云存储的一个非常重要的问题。在本模型的设计中,涉及到两类数据的副本存储:用户存储的数据本身,以分块的形式存储在Chunk Server中;在服务管理节点上存储的文件元数据信息。当Chunk Server 或是服务管理节点失效时,要确保不会影响系统的正常运行,并且需要有一种策略来恢复失效节点上的数据,从而保证相关数据的副本总是保持在一定的水平。
对于用户存储的数据,数据副本的存储位置由服务管理节点来分配与管理,当存储数据副本的某个数据块服务器失效时,服务节点管理能够及时地知道这一情况并重新选择一个数据块服务器来恢复失效节点的数据,确保系统中的数据副本总能保持在一定的水平。
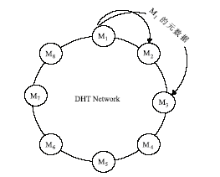
每个服务管理节点维护一个副本列表和一个后继节点列表,对于服务管理节点存储的文件元数据信息,通过查询后继节点列表(Successor-list),在紧邻的两个后继节点上分别存放一份元数据副本。例如,如果副本数量是3,当文件元数据发生改变后,就要将相关的元数据保存到此节点的前两个后继节点,如图3所示:
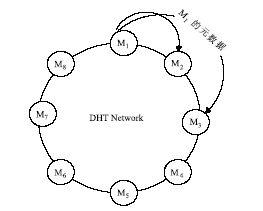 | 图3 服务管理节点元数据副本管理 |
图3中,节点M1的数据副本保存在它的后继节点M2和M3。当M1发现副本列表中某个节点失效时,便从后继列表中选择下一个后继节点加入列表,并将相关的元数据副本复制到这个后继节点上,以维护系统中副本数量不变,同时原来由失效节点管理的数据块服务器由失效节点的后继节点管理,避免了数据块服务器的丢失,不会对系统的性能产生较大的影响。通过应用这样的策略,保证即使某个服务管理节点失效,它所存储的元数据信息也能在相应的后继节点上找到,不会影响系统的运行。例如当M3失效时,M1会及时地发现这一状况,选择后继节点M4作为新的副本节点,将自己的数据副本保存在M4。同时,M4需要选择M6作为失效节点M3的副本节点。这样,M1和M3的副本数量都不会降低。原来由失效节点M3处理的请求由M4来处理,M4也将管理M3管理的数据块服务器。而这一切对Client App来说是透明的,不会对用户产生任何不利的影响,从而维护了系统的稳定。
由于云存储系统为多个用户提供服务,多个用户可能会同时访问同一数据的多个副本,当用户对数据进行更新的时候,就面临着如何保证数据副本一致性的问题,因此云存储系统需要提供一种策略来保证系统中数据副本的一致性。在本文提出的云存储模型中,采用如下的策略来确保副本的一致性。
(1)Client App 向系统发出要对某一数据文件进行更新的请求。
(2)请求到达相应的服务管理节点后,服务节点检查相关的文件元数据副本链表的状态,元数据副本链表的状态有锁定和未锁定两种状态。如果未锁定,说明没有其他的更新请求正在被处理。就将相关的文件元数据锁定,阻塞其他更新请求。
①服务管理节点向存储其副本的相关后继节点发出锁定的命令,将副本锁定。
②服务管理节点向Client App返回相应的文件元数据信息,Client App利用这些元数据来完成数据的更新。
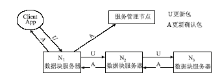
③系统对副本采取异步更新的模式,即Client App先对文件的某一副本进行更新,其余副本的更新由已完成更新的副本来完成,如图4所示:
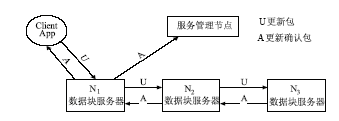 | 图4 数据副本更新过程 |
一个文件块及其副本分别存储在N1、N2、N3 三个节点上,当Client App对N1进行更新完成后,由N1对N2进行更新,同样的方式,由N2对N3进行更新。当某个数据块服务器完成更新后,需要向服务管理节点发出更新完成的消息,并增加相应副本的版本号。
④当文件的所有数据副本完成更新后,它们的版本号是同样的并且是最新的,此时将文件解锁,其他更新请求就可以得到处理,文件也可以被Client App读取,从而保证了副本的一致性。如果某一个数据块服务器出现故障,未能完成数据的更新,则副本链表的版本号会出现不一致的情况,服务管理节点会周期性地检查这一情况,并将相关的副本更新到最新状态。
(3)如果在步骤(2)中,相关的文件元数据已被锁定,服务管理节点就将这个更新请求放入一个请求队列中,等待当前更新请求的完成。
4.3 数据存储过程
此模型的数据存储过程如下:
(1)客户端向网关发出存储数据的请求,网关根据用户要存储文件的文件名等信息用Hash算法计算相应的Key值,并根据路由表转发此请求到相应的服务处理节点。
(2)相应的服务管理节点接收到请求后,为此请求分配适当的数据块服务器,并将数据块服务器的地址列表返回到客户端。
(3)客户端接收到从服务处理节点返回的数据块服务器地址列表后,分别与各数据块服务器建立连接,传输数据。
(4)当数据块服务器与客户端完成数据传输后,需要向相应的服务管理节点报告,并在其他节点完成数据备份,对于数据的备份情况,也要存储在服务管理节点。在服务节点知道数据完成存储(包括备份数据)时,服务管理节点从其后继节点列表中选择紧邻的两个服务节点,将此次存储的相关元数据信息存储到这两个节点,从而完成元数据信息的备份。
5 测试与性能分析
为了测试模型的可行性,笔者开发了一个基于此模型的原型系统,开发语言采用Java;测试环境是局域网环境,普通PC 16台,分为5个存储簇,一个网关,每个存储簇由一个服务管理节点和2个数据块服务器组成;操作系统为Linux Fedora 14。
经过测试,原型系统能够平稳运行,当少数几个服务管理节点出现宕机的情况(人工断网),仍然能够较好地处理客户端的请求;当某些块服务器失效的时候,数据副本的存在使得数据没有丢失,不影响数据的存储和检索,但数据副本使得对硬盘的空间要求较高,因此数据副本的数量不宜过多。P2P技术的应用,使得节点失效对于用户来说是透明的。多个服务管理节点的存在,实现了对高负载的均衡,但相对于集中式云存储系统,转发请求到相应的服务管理节点会存在一定的延迟;存储簇的存在简化了数据块服务器的管理。
6 结语
本文针对当前集中式云存储系统所存在的性能瓶颈和单点失败的问题,将P2P技术引入到云存储系统的设计中,提出了一种基于P2P的云存储模型,充分发挥了P2P的去中心化、良好的可扩展性、高性能和负载均衡的优点,可以有效地解决单点失败的问题,从而大大增强了系统的服务能力和稳定性,并且能够实现自我管理和自我组织,具有良好的可扩展性和容错能力。在下一步的研究中,还需要解决P2P的引入可能给云存储带来的一些新问题,如P2P系统存在的访问热点现象,会影响云存储系统的服务质量。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|