
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
可视化的共词聚类系统分析及实现
引用本文
邢美凤, 许德山. 可视化的共词聚类系统分析及实现. 现代图书情报技术, 2011, 27(7): 62-68
Xing Meifeng, Xu Deshan. Design and Implementation of Visual Co-word and Cluster Analyzer. 现代图书情报技术, 2011, 27(7): 62-68
Permissions
Xing Meifeng, Xu Deshan. Design and Implementation of Visual Co-word and Cluster Analyzer. 现代图书情报技术, 2011, 27(7): 62-68
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
可视化的共词聚类系统分析及实现
摘要
在分析现有文献计量软件的优缺点及利用文献计量方法进行科学研究的目的与工作流程的基础上,建立多种文献数据库题录字典,有效进行关键词的合并和修正,集成文献计量中统计、共词和聚类过程,设计和实现一种可视化的共词聚类分析系统。
关键词:
共词; 聚类; 可视化
中图分类号:TP311 G350
Design and Implementation of Visual Co-word and Cluster Analyzer
Abstract
By analyzing the advantages and disadvantages of the existing bibliometric software, the purpose of scientific research and workflow based on the bibliometric method, this paper establishes a variety of bibliographic entry dictionary, combines and corrects keywords effectively, integrates the process of statistics, co-word and the clustering. Then it designs and completes a sort of visual co-word and cluster analyzer system.
Keyword:
Co-word; Cluster; Visual
1 引言
文献计量软件的开发和利用对于文献计量分析学者进行学术分析、解决复杂的大数据量的分析问题具有重要的辅助作用。目前国外用于文献计量分析的软件种类繁多[ 1],但这些软件在解决部分问题的同时仍存在一些不足:如Bibexcel[ 2]可以对ISI的SCI、SSCI和A&HCI数据进行分析,但对中文数据不能进行相关的分析;SPSS[ 3]是大型的统计学软件包,但应用于文献计量分析时,只能借助其他软件将文献数据库中的数据转换为矩阵格式后才能进一步分析,不能直接对文献数据库中的数据进行分析;UCINET[ 4]是目前流行的社会网络分析软件,但用于文献计量也需要借助其他软件,如Bibexcel将文献数据库的数据格式转换并进行相应的运算之后,才能进行文献计量分析。国内在文献计量软件的开发上也进行了诸多的尝试,如王曰芬等[ 5]开发了文献计量与内容分析综合应用软件,周春雷等[ 6]开发了CnkiRef软件工具,张云[ 7]利用开源的Lucene开发了中文学术文献计量软件。以上三种软件只实现了对题录信息的基本统计功能;肖伟等[ 8]开发的学术论文共词分析系统实现了基本统计和共词的功能,但文献数据库格式到系统格式由人工录入,分析时工作量很大;崔雷[ 9]开发的文献共现矩阵生成软件BICOMS,完成了文献外部特征的统计功能和共现矩阵的生成,但在生成共现矩阵时,只能按照原有关键词的词频顺序,以一定的阈值过滤关键词,没有对关键词进行修正或合并。基于此,本文更有效地集成文献数据库格式到共词聚类的操作流程,设计和实现一种可视化的共词聚类分析系统,以期能帮助相关分析人员更方便、更迅捷、更准确地进行科学研究。
2 文献计量软件开发需求分析[ 10, 11]
2.1 文献计量分析的目的和内容
利用文献计量的方法进行分析研究,主要是研究与某一领域相关文献的一些特性,对这些特征进行总结统计,揭示这些统计数据体现出来的某一领域的进展状况与发展趋势,揭示所研究领域的学科结构、发展历程、各个时间段关注的热点问题、当前研究态势及发展趋势。
文献计量分析的研究对象是表征相关文献特征的一些元素,主要有:题名、作者、刊名、机构、出版年份、关键词、文摘、被引次数、引文等。对这些元素进行数量统计。统计方式有:TopN统计、数量分布统计、数量增长统计、元素之间关联统计。关联统计主要是基于共词方法的统计、基于共引方法的统计等。利用以上的统计资料,得出与这一主题相关的论文年代、核心作者、高产作者、高被引作者、核心研究机构的分布。统计领域相关文献中出现的关键词、作者、机构等元素,并通过对共词矩阵和共引矩阵的聚类分析、因子分析、多维尺度分析等,分析出这一领域的研究热点和发展趋势。
2.2 利用共词聚类的方法进行分析的工作流程
利用文献计量共词聚类的方法分析某一领域总体现状与趋势,主要步骤为:下载相关文献;转换数据格式;对下载的数据进行预处理;借助相关软件进行计算,得出第一手资料;对这些数据进行分析和判断,结合相关的领域知识得出进一步深入的结论。
(1)下载相关文献
对某一领域的研究不仅要分析国内的现状和趋势,更要了解国外的发展情况。经过几十年的发展,全世界己有几千个中文和英文文献商用数据库,超大规模数据库年增长50万条以上记录。每种数据库都有独特的数据记录格式。
(2)转换为计量软件可以识别的数据格式
不同的数据库有不同的数据记录格式,每一种计量软件都需要将这些格式转换为对应软件系统特有的分析格式,用以统一处理。
(3)数据预处理
从数据库中下载的文献数据不一定都是想要的分析内容,因此需要将很明显的不属于研究范围的文献先去掉。同时数据的格式也不一定规范,如关键词中“本体”和“Ontology”代表同一个含义,应视为同一个关键词,因此像这类关键词应先统一为一个词。
(4)利用软件进行分析
借助相应的文献计量软件,生成所需要的共词矩阵和聚类图,分析这些数据所能揭示的深层含义,发现潜在的有用信息,进而得出所要研究领域的研究路线和发展趋势。
基于以上分析,本文设计了一个共词聚类系统,它能将不同数据库的数据格式统一转换为本系统可以识别和处理的格式,可以对文献数据如作者给定关键词进行同义词合并等预处理操作,生成更有效的共词矩阵,并利用所生成的共词矩阵进行聚类分析,生成聚类分析图。该系统为用户提供了一种更方便有效的文献计量分析工具。
3 文献计量共词聚类系统设计及实现
3.1 系统功能模块设计
文献计量共词聚类分析系统的整体功能是利用与文献相关的特征元素的统计信息,得出所研究领域的研究现状和发展趋势。其完成的具体功能主要有:读入题录信息,将原有的文献数据库的格式转换为本系统特有的格式;数据预处理,初步将读入的数据中意义相同但拼写有差别的词统一为一个词,或将没有实际统计意义的词去掉;词频统计,实现TopN统计、数量分布统计、数量增长统计;共词矩阵生成,实现元素之间的关联统计;聚类的图形化展示。在系统功能分析的基础上,生成如下的功能模块:格式转换模块、数据预处理模块、统计管理模块、共词生成模块和聚类模块等。这些模块在本系统设计时,分别以标签形式加以区别显示。
3.2 数据库结构设计
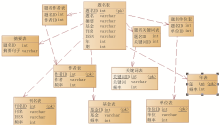
数据库用来持久化统计数据,以备将来直接使用。对于每一个题录项都要建立相应的表,共有11张用来负责处理业务逻辑的表单,本系统的数据存储于这11张表中,它们分别是:题名表、作者表、题名作者表、关键词表、题名关键词表、单位表、题名单位表、摘要表、基金表、刊名表和年表。
其中题名表用来存放所有题录数据的信息;作者表、关键词表、单位表、摘要表、基金表、刊名表和年表中存放相对应的题录信息,主要字段为题录的ID号、题录的值、题录出现的频率以及用来进行运算时的Flag标志;题名作者表、题名关键词表、题名单位表用来生成相应的题录向量,主要字段是题名的ID和各个题录项的ID号,通过这两个字段可为每一篇文献建立相应的题录向量,通过运算可以生成相应的共词矩阵。
以上各表利用题名的ID号或其他题录字段的ID号建立关联。数据库表的逻辑关系如图1所示:
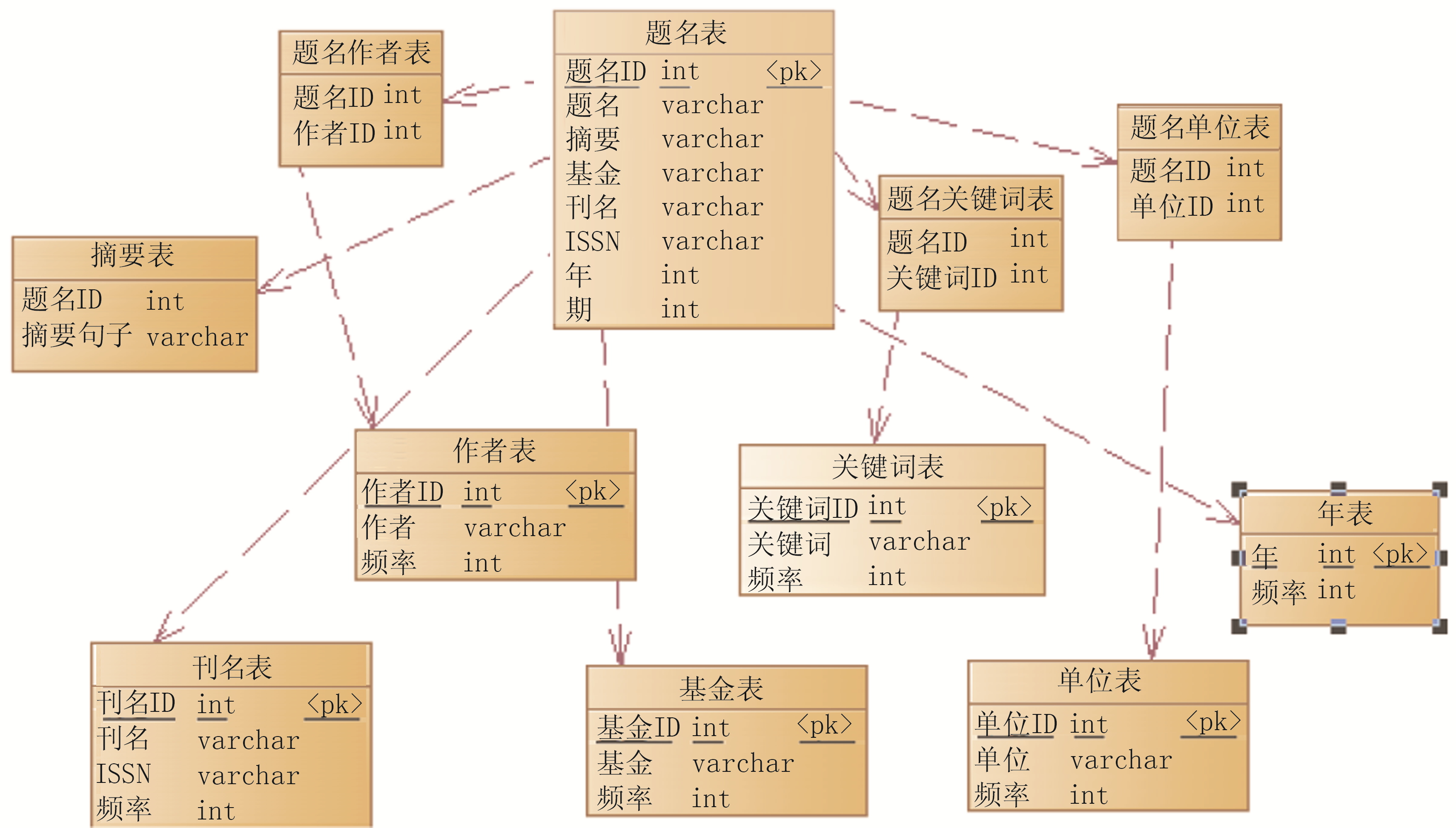 | 图1 数据库表的逻辑关系图 |
本系统利用MySQL建立数据库,在MySQL中建立的相应表存放到bibliodatabase库中,MySQL中建立的数据库表如图2所示,其中工作列表中显示timingbiao中各字段信息。
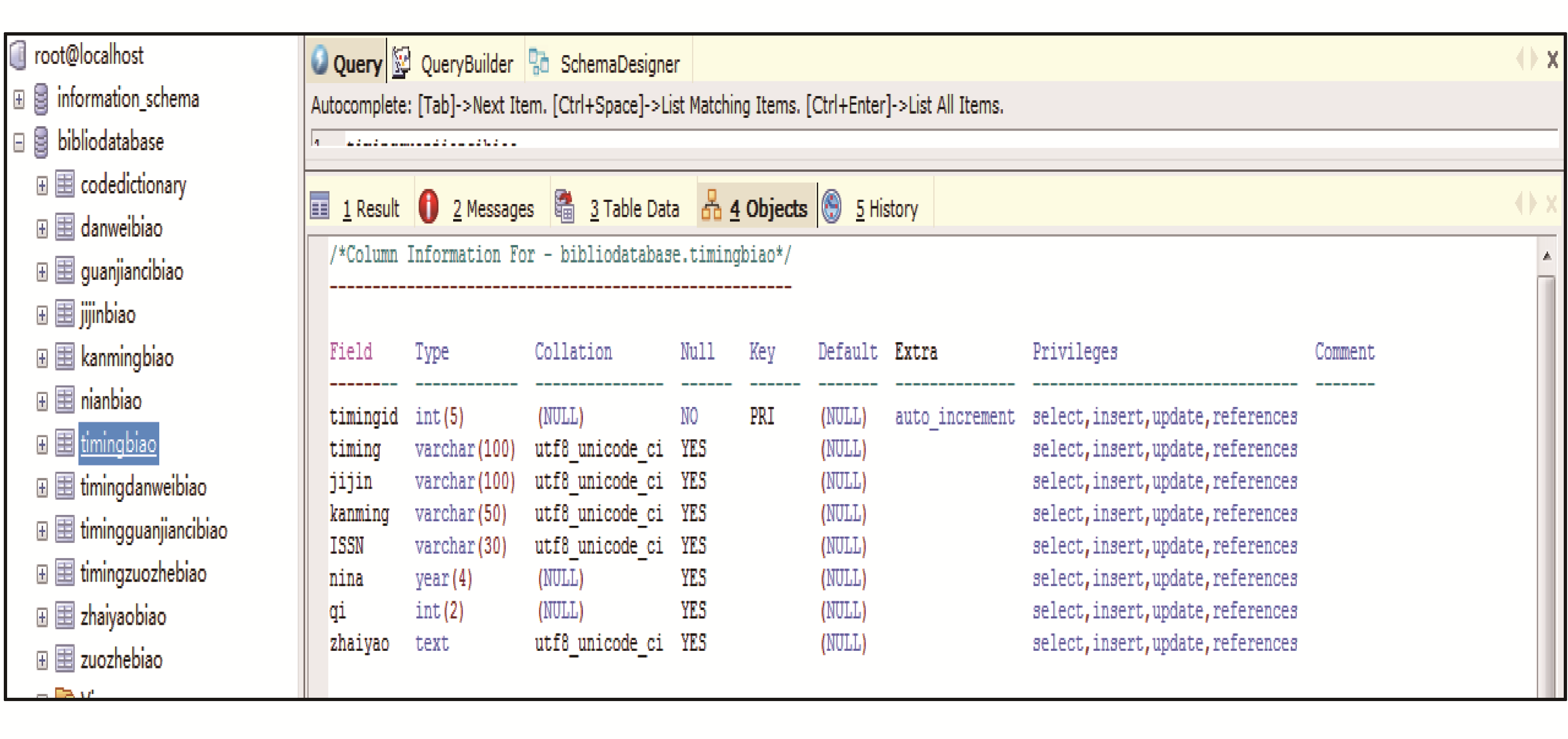 | 图2 MySQL中建立的数据库表图 |
3.3 系统主要技术思路设计
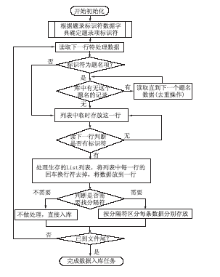
(1)文献数据库格式转换为本地数据格式
根据文献数据库的格式建立题录标识符数据字典,每读入一个文件与题录标识符数据字典对照,确定每一行的题录项标识符,将每一行的题录项信息转换为本系统的数据格式,转换流程如图3所示:
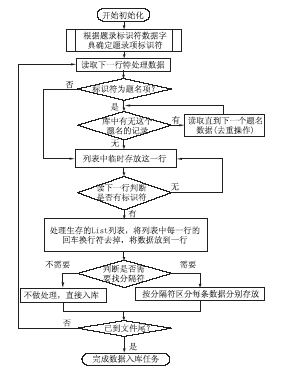 | 图3 数据入库流程图 |
(2)共词矩阵生成算法
本系统利用向量运算生成共词矩阵,以作者给定关键词共词矩阵生成为例,共词矩阵生成算法如下:
①利用题名关键词表可以直接生成每篇文献的关键词向量α;
②向量α的维数为所有要分析的关键词的个数,设向量的维数为n;
③向量α的个数为分析的不重复的文献,设所要分析的文献为m篇;
④引入n维辅助向量:βij=(0,0,0,0,…,1…0,0…1…)(其中第i个元素和第j个元素为1,其余为0,这样,引入的辅助向量总共 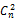
⑤用来计算共词矩阵的生成公式如下:
{Aij}={ 
k=]]>k表示k篇文献的关键词向量)]]>
(3)聚类算法设计
利用共词矩阵生成的聚类采用层次聚类算法,此算法由Johnson于1967[ 12]年首次系统阐述。根据类与类之间距离计算方法的不同,可分为single-linkage聚类法、complete-linkage 聚类法和average-linkage 聚类法。single-linkage 聚类法和complete-linkage 聚类法由Sokal等于1963[ 13]年首次使用,single-linkage 聚类法实质上就是Sneath[ 14]在1957年提到的Minimum方法,此方法中类间距离等于两类对象之间的最小距离; complete-linkage 聚类法等同于1948年由Sϕrensen[ 15]提出的Maximum方法,此方法中类间距离等于两类对象之间的最大距离;average-linkage聚类法由Gower于1966[ 16]年提出,此方法中类间距离等于两类对象之间的平均距离。目前这些仍然是有效的层次聚类方法。本系统采用single-linkage聚类算法,并利用Agglomerative机制,即每次将两个旧类合并成一个新类,直到最终合并成一个类为止。每合并一次,则在距离矩阵中删除相对应的行与列。算法如下:
①设待聚类的N个对象分别为0,1,……, n-1,[Dij]表示对应的共词矩阵,由对象m构成的类记为(m),类(r)与类(s)的距离记为d [(r),(s)];
②将每个对象归为一类, 共得到N类, 每类仅包含一个对象,类与类之间的距离就是它们所包含的对象之间的距离,令顺序号m = 0;
③在D中寻找最小距离d[(r),(s)] =max{[Dij]}(共词矩阵计算对象之间共现的次数,认为共现次数越大,两者的距离越小);
④将两个类(r)和(s)合并成一个新类(r,s),令m = m +1;
⑤更新距离矩阵D:将表示类(r)和类(s)的行列删除,加入表示新类(r,s)的行列;同时定义新类(r,s)与各旧类(k)的距离为 d[(k), (r,s)] = min d[(k),(r)], d[(k),(s)];
⑥重复步骤③-⑤,直到所有对象合并成一个类为止。
3.4 文献计量共词聚类系统实现
本文设计的可视化共词聚类分析系统定位为桌面应用程序,前台使用Java[ 17, 18, 19]语言,后台采用MySQL数据库,利用MVC设计模式进行分层[ 20]:Model层对文献计量分析流程中的对象进行抽象,本文分析不同文献数据源所提供的文献数据格式和内容的差异,抽象其中具有共性的部分,封装了文献计量对象的属性和对象隐含的处理逻辑;View层为文献计量研究人员提供了输入手段,并触发Controller层运行,然后通过Model层访问从不同的文献数据库中得来的数据,并利用某种方式来显示这些数据;Controller层管理文献计量研究人员与View的交互,能从View中取得数据并传给Model去执行相应的逻辑操作,根据Model的执行结果,选择一个合适的View把结果展现给文献计量分析人员。
4 文献计量共词聚类系统应用实例
为验证本系统的合理性:从CNKI数据库下载检索主题词为“文本分类”的研究论文,得到来自中国学术期刊网络出版总库1 798篇,来自中国优秀硕士学位论文全文数据库953篇,来自中国博士学位论文全文数据库114篇,总共2 865篇文献的题录信息。
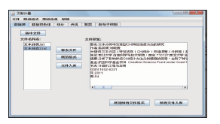
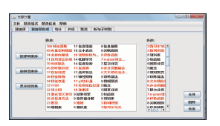
首先规范题录文件格式,然后选择图4中所有文件(对应“所有文件入库”按钮)或单个文件(对应“文件入库”按钮),将所需要的文件保存为本系统的数据库格式。
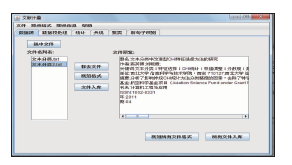 | 图4 选择数据源图 |
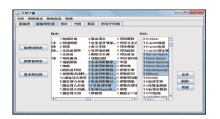
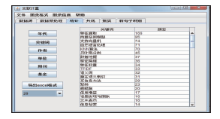
第二个标签页为数据预处理,从文献数据库中下载的文献中的关键词共有1 208个,但有一些关键词需要进行调整,如图5所示,所选中的有关“朴素贝叶斯”的选项应视为同一研究对象,需要将这些词进一步合并;同时将一些没有必要进一步分析的词去掉。
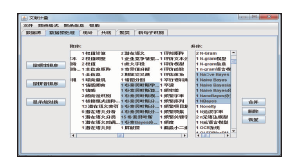 | 图5 数据预处理 |
经过合并和删除后,所得到的关键词如图6所示:
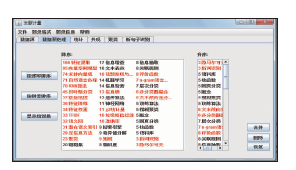 | 图6 数据预处理后的结果 |
图6中所给出的关键词是利用关键词进行计量分析的主要依据,选“统计”标签,可以对各个题录项进行统计,例如:频率排序的前20个关键词统计如图7所示:
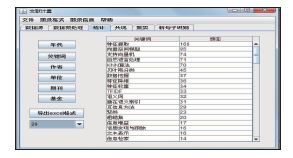 | 图7 TopN统计图 |
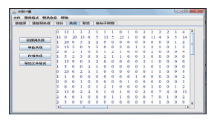
选“共现”标签,可以计算各个题录项的共现矩阵。如选择“关键词共现”按钮,可以在右边工作区中得出关键词的共词矩阵,如图8所示:
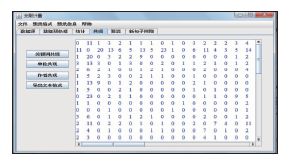 | 图8 关键词共词分析矩阵图 |
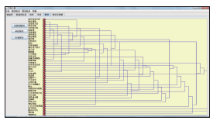
在生成共词矩阵以后才能进行聚类,利用图8所生成的共词矩阵计算的聚类结果,如图9所示:
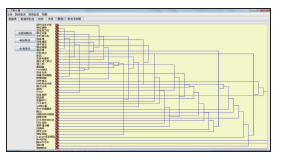 | 图9 关键词聚类图 |
通过对以上结果进行分析不难看出,文本分类是自然语言处理和数据挖掘领域的研究热点和核心技术。近几年的研究热点仍然是文本分类的基础工作特征提取。对于特征提取的研究以基于向量空间的表示模型为主。基于机器学习的特征提取是该领域研究的主流方向,主要通过分析特征权重,进行特征降维。文本分类还比较注重文本表示模式的研究、算法评价的研究、传统算法的改进、新算法的引入、多分类器的融合和文本分类的应用研究。
5 结语
本系统分析了有代表性的中文数据库格式和英文数据库格式,有效进行关键词的合并和修正,集成统计、共词和聚类的操作流程,为情报分析人员提供更便捷的分析过程。不足之处在于共词矩阵生成过程中,当维数过大时会出现堆内存溢出的情况,聚类的过程仍需进一步深入分析和改进。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|