基于改进编辑距离的相似重复记录清理算法*
引用本文
叶焕倬, 吴迪. 基于改进编辑距离的相似重复记录清理算法* . 现代图书情报技术, 2011, 27(7): 82-90
Ye Huanzhuo, Wu Di. Approximately Duplicate Data Cleaning Algorithm Based on Improved Edit Distance. 现代图书情报技术, 2011, 27(7): 82-90
Permissions
Ye Huanzhuo, Wu Di. Approximately Duplicate Data Cleaning Algorithm Based on Improved Edit Distance. 现代图书情报技术, 2011, 27(7): 82-90
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
基于改进编辑距离的相似重复记录清理算法*
摘要
相似度计算是相似重复记录清理过程中的一个关键问题,编辑距离算法在其中具有广泛应用。在传统编辑距离算法的基础上,通过分析影响相似度计算结果的序列长度、同义词等因素,得到一种同时引入同义词词库和归一化处理思想的改进的基于语义编辑距离的相似重复记录清理算法,适用于相似记录的识别过程。实验分析表明,改进算法计算结果更符合句子的语义信息,绝大部分结果符合人们的认知经验,从而可以有效地提高相似重复记录识别的准确率和精确度。
关键词:
相似重复记录; 编辑距离; 语义; 同义词词库
中图分类号:G202 TP391.1
Approximately Duplicate Data Cleaning Algorithm Based on Improved Edit Distance
Abstract
Similarity calculation is a key issue in the process of approximately duplicate data cleaning,and edit distance algorithm is widely used in this application. Based on the traditional edit distance algorithm, by analyzing the sequence length, synonyms and other factors which affect the similarity of the results, an improved approximately duplicate data cleaning algorithm based on semantic edit distance is proposed. This algorithm used synonyms thesaurus and normalized distance metric, and it can be applied to similar records identification process. Experimental results show that the calculating results by this improved algorithm become more in line with the sentence semantic information and people’s cognitive experience. Thereby, the method effectively improves the accuracy and precision of detect approximately duplicate data.
Keyword:
Approximately duplicate data; Edit distance; Semantic; Synonyms thesaurus
1 引言
数据是企业进行有效审计、数据挖掘和管理决策等的关键,但是由于各种原因,如缺乏有效的数据分析技术、数据录入错误、不同来源数据引起的不同表示方法等,导致企业现有系统数据库中存在大量的脏数据(Dirty Data),人们常常抱怨“数据丰富,信息贫乏”。企业数据质量的管理正在获得越来越多的关注,因此,数据清理技术显得尤为重要[ 1]。 数据清理(Data Cleaning)[ 2]是数据仓库中数据加载和数据维护的一个至关重要的环节,其目的是提高数据的质量,并且对于数据库中相似重复记录的检测和清除更是数据清理活动研究的热点[ 3, 4]。本文的研究目的是采用改进的编辑距离算法有效解决数据清理过程中对源数据的检测和识别,具有重要的理论意义和实际的应用价值。
2 相似重复记录清理
相似重复记录(Approximately Duplicate Data)是指同一个现实实体在数据集合中用多条不完全相同的记录来表示,由于它们在格式、拼写上的差异,从而导致数据库管理系统不能正确识别的记录。狭义地说,即如果两条记录在某些字段的值相等或足够相似,则认为这两条记录互为相似重复[ 5, 6]。
相似重复记录的检测是建立在相似度计算的基础上的,目前主要有两种判断字符串之间相似度的方法:相似度函数,用来判定两个字符串之间的相似度,函数值越大则两个字符串的相似度越高,如字段匹配算法[ 7, 8, 9]、递归的字段匹配算法[ 7, 8, 9]、Smith-Waterman算法[ 8, 9, 10]等;距离函数,将字符串看作距离空间中的点,则对字符串相似度的判别用距离函数来衡量,距离函数越小则越相似。多数情况下,相似度函数和距离函数是可互换的,即大相似度和小距离是等价的。距离函数法中,编辑距离法计算方法相对成熟,得到了广泛的应用。
3 编辑距离算法
3.1 国内外研究现状
编辑距离(Edit Distance)首先由Levenshtein在1965年提出的,故又叫Leven-shtein距离[ 11],是一种常用的距离函数度量方法,在相似性匹配领域得到了广泛的应用。两序列之间的编辑距离是指只用插入、删除和替换三种基本操作把一个字符串(S)转换成另一个字符串(T)所需要的最少基本操作次数。编辑距离值越大,则相似度越小。求两个字符串之间的编辑距离实际上转化为一个求最优解的问题,可以利用动态规划的思想来计算[ 12],其中传统的编辑距离算法将每一种基本操作的代价值都简单设定为1。
Monge等使用一种可调节的编辑距离计算方法来识别重复记录[ 13],文献[14]提出一种应用子串进行相似度计量的编辑距离方法。文献[15]提出一种基于NFA(Nondeterministic Finitestate Automation)的编辑距离方法。将匹配字符串看作是一个查找树,通过建立一个查找树索引,从而有效地提高了识别准确率。以发现100万条记录中的1 000条相似重复记录为例,识别所需时间仅是普通编辑距离算法的0.2%。文献[16]提出了一种自适应的编辑距离算法,通过建立匹配索引能够更好地处理字符串倒转和缩写的情况。交换操作与编辑距离值结果的准确性具有重要的关系,文献[17]在文献[12]的基础上提出了非相邻位置字符的交换操作动态规划方法,使对交换操作的识别准确性大大提高。
目前,已有很多学者加强了对词汇处理准确性的研究,如文献[18]和文献[19]等对知网结构的相似度计算方法进行了研究,文献[20]将《同义词词林》与依存文法相结合,文献[21]将加权的思想引入到《同义词词林》的应用中,文献[22]同时使用了HowNet和同义词词林两种语义资源来计算中文句子的相似度,使得对中文识别的准确性更高。同义词比较的结果受同义词词库的直接影响,目前各种同义词词库正处在不断完善和发展的过程中。
3.2 存在的不足
尽管编辑距离算法在数据清理中具有一定的优势,对拼写错误、短单词的插入和删除错误等的检测具有很高的正确率,但是仍然存在一些问题。
(1)传统的编辑距离算法,因为忽略了序列长度对编辑距离产生的影响,所以对于长字符串插入和删除错误等的计算存在一定的偏差;
(2)单纯以字为单位计算各个字符之间的编辑距离,计算出的距离只是文字表面的距离,并没有充分考虑语义的概念,与实际语句意义出入较大,特别是对中英文间比较时不能得到满意的结果;
(3)对于插入、删除、替换三种基本操作的代价值的确定没有统一的、合理的方法,这使得计算结果受到严重的影响。
由此可见,编辑距离算法在数据清理中的应用还存在一定的不足。本文在现有研究的基础上,提出了一种基于同义词词库的归一化编辑距离相似重复记录清理算法,解决了计算结果受序列长度的影响和计算结果偏离语义信息的问题,使算法具有较高的查全率和查准率。
4 改进的编辑距离算法
对于字符串匹配,单纯使用以字为单位的编辑距离方法,计算出的语义距离和实际情况出入很大,而且序列长度对代价函数的计算结果也有很大影响。针对这些情况,本文提出了一种基于同义词词库的归一化编辑距离相似重复记录检测算法,以归一化编辑距离算法为基础,首先对待匹配记录进行分词,判断单词的中英文属性,然后针对中中匹配、英英匹配、中英匹配三种不同的情况,分别调用相应的同义词词库,结合词汇的语义信息,进行编辑距离的计算,从而使结果更符合字符串语义相似度计算的要求。
4.1 算法步骤
改进的编辑距离算法以单词为单位代替以字符为单位进行计算,基本步骤如下:
(1)设定各基本操作的代价值。使用同义词词库辅助计算词汇之间的语义距离。假设a和b分别为记录Sx和Sy中包含的单词,用insert、delete、substitution分别表示插入、删除、替换的代价,同时引入代价值synonym代表用a的同义词a'代替a操作的代价。
本算法采取灵活设置操作代价的方式,通过对操作代价值的不断调整,比较实验结果,选取效果最优的代价值设置方案。
(2)利用分词算法对待匹配的记录进行分词,以便通过同义词词库进行各原子单词间的操作代价判断。
(3)将待匹配的记录以单词为单位分别存入字符串数组A[m]和B[n]中,其中Sx包含m个原子单词,Sy包含n个原子单词。
(4)构造二维矩阵D[(m+1)×(n+1)],用于存储记录递归求得的代价值。
(5)把矩阵D[(m+1)×(n+1)]第一行的值初始化为insert×(0…n),第一列的值初始化为delete×(0…m)。把字符串Sx的字符分别与矩阵第一列中的1到m值相对应,字符串Sy的字符分别与矩阵第一行中的1到n值相对应,并标记为A[i]和B[j]。当满足i≤m且j≤n的情况下,对比A[i]和B[j], cost值的计算如下。
cost(a,b)=
 | (1) |
其中,元素D[i,j] (0≤i≤m,0≤j≤n)的值表示将A[1…i]转变为B[1…j]所需的代价,即A和B之间的编辑距离。其递归计算过程可表示如下:
D[0,0] = 0
D[0,j] = D[0,j-1] + insert(B[j]) if(j > 0)
D[i,0] = D[i-1,0] + delete(A[i]) if(i > 0)
D[i,j] = 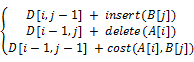
(6)对进行比较的两个单词A[i]和B[j]判断其中英文属性。若两者都为中文,则调用《同义词词林扩展版》进行中文同义词比较;若两者都是英文,则调用WordNet.Net API进行英文同义词比较;若一者为中文,一者为英文,则调用Google翻译API将中文转化成英文,再调用WordNet.Net API进行英文同义词比较,由此进行A[i]和B[j]是否为同义词的判断,进而得到cost值。
(7)迭代执行以上步骤,求得D[m,n]即为所求的Sx和Sy之间的原始编辑距离。根据编辑距离归一化公式[ 7],将D[m,n]进行归一化,得到记录间的语义距离Dist。编辑距离归一化公式如下:
Dist=
 | (3) |
(8)输出Dist的值,即为求得的两记录间的语义距离。
利用以上8个基本步骤的分析和描述,可以将关键算法NewEdit(string[]P, string[] T, int m, int n)用伪码表示如下:
①初始化insert, delete, substitution, synonym的值
②利用分词算法SubString()对记录X和Y进行分词
③将分词结果存于数组A[m]和B[n]中
float NewEdit(string[] P, string[] T, int m, int n)//本文提出的改进编辑距离算法
{
int i, j; float Dist; //Dist记录最终求得的归一化编辑距离
④int[,] D = new int[m + 1, n + 1]; //记录各步求得的代价值
⑤//初始化距离矩阵
for (i = 1; i <= m ; i++ )
D[i, 0] = i * delete ; //设置替换成空串的值
for (j = 0 ; j <= n ; j++ )
D[0, j] = j * insert ; //设置将空串替换成非空串的值
//循环得到距离矩阵中各元素的值
for (j = 1 ; j <= n ; j++ ){
for (i = 1 ; i <= m ; i++ ){
if (P[i - 1] == T[j - 1]){ //两字符串完全相等时,无需进行同义词比较
D[i, j] = min(D[i - 1, j - 1],
D[i - 1, j] + delete,
D[i, j - 1] + insert);
}
⑥else { //根据中英文属性选择相应的同义词词库
synonym = syn(P[i - 1],T[j - 1]); //同义词判断函数syn(P[i - 1],T[j - 1])返回语义距离值
D[i, j] = min(D[i - 1, j - 1] + substitution * synonym, D[i - 1, j] + delete, D[i, j - 1] + insert);
} //if
} //for
} //for
⑦Dist=2 * D[m, n] / (insert / delete * (m + n)+ D[m, n] );
⑧return Dist;
} //NewEdit
4.2 同义词词库的选取
= 
本文所提出的改进算法中选用《同义词词林扩展版》作为中文匹配时同义词比较的词库。同时,WordNet是针对英文的语义网络,对于计算英文词语的相似度准确性和效率更高,因此选用WordNet作为英文匹配时同义词的词库。而对于在中文和英文词语之间查找同义词匹配的情况,可以通过编程调用Google提供的Google翻译API来实现中文向英文的转换过程,再利用WordNet进行英文单词间的同义比较。
(1)《同义词词林扩展版》
《同义词词林》由梅家驹等[ 24]于1983年编纂而成,词典中不仅包括了一个词语的同义词,而且也包含了一定数量的同类词,即广义的相关词,其基本思想就是利用词林中对每个词提供的语义编码进行两个词之间的语义距离计算。
《同义词词林》原版将词的词义分为大、中、小三类进行编码[ 22],计算结果的精确性有待加强。本文选用哈尔滨工业大学信息检索实验室的《同义词词林扩展版》[ 25]作为系统的词义知识资源。扩展后的《同义词词林》新增了第4级和第5级编码,描述了一个由上到下、由宽泛到具体的语义分类体系,含有比较丰富的语义信息。每个词语按照其语义,赋予相应的语义代码,具体的编码体系描述[ 25]如下:
﹤词义编码﹥::=﹤1层﹥﹤2层﹥﹤3层﹥﹤4层﹥﹤5层﹥
﹤1层﹥::=﹤大写英文字母﹥
﹤2层﹥::=﹤小写英文字母﹥
﹤3层﹥::=﹤数字﹥﹤数字﹥
﹤4层﹥::=﹤大写英文字母﹥
﹤5层﹥::=﹤数字﹥﹤数字﹥
如“草莓”Bh07A16=,“杨梅”Bh07A16=,“苹果”Bh07A14=,“豆角”Bh06A42=,“茶水”Br12B08#,“菠菜”Bh06A06@。第8位的标记有“=”、“#”、“@”三种,分别表示“同义”、“同类”、“独立”。
利用P,Q分别表示A,B两词具有语义的集合,则A,B两词之间的语义距离计算方法如下:
Dist(A,B)= 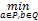
语义a,b之间的距离如下:
dist(a,b)=2×(7-n)(5)
其中,n表示它们之间的语义代码从第n位开始不同,全部相同则语义距离为0。可知Dist(草莓,杨梅)=0,Dist(草莓,苹果)=2,Dist(草莓,豆角)=6,Dist(草莓,茶水)=12, Dist(草莓,菠菜)=6。由此可见,利用这种代数操作计算语义距离方便、快捷。
因为本文将调用同义词词库求得的语义距离值直接与代价值进行操作,故应将Dist(A, B)的值进行归一化处理,定义归一化处理方法如下:
IDist(A,B)=
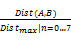 | (6) |
(2)WordNet
WordNet是美国普林斯顿大学认知科学实验室开发的一种基于英文的词汇语义网络词典。WordNet的基本单元是同义词集合(Sunsets),每一个集合表示一个基本的词汇概念,在这些词汇概念间建立了同义关系、反义关系、上位关系、下位关系、部分关系以及完全关系等多种词汇语义关系[ 26, 27]。这样就构成了一个比较完整的词汇语义网络系统,继承结构层次更深。
本文将通过调用WordNet提供的基于ASP.NET的WordNetDotNet接口直接访问WordNet字典,免除了提前构建词根表的灵活性较差的缺点,使访问速度更快。首先下载并安装WordNet 2.1,然后通过Open Source中提供的WordNet Library for .Net入口,下载调用WordNet.Net API所需的C#代码[ 28]。在代码中相应的位置应用这些代码调用WordNet字典(主要使用SentenceSimilarity类的GetScore()方法获得英文单词的相似度值),完成英文数据间的相似度计算(WordNet现在已经更新到3.0版本,但是由于3.0版本只能支持在Linux系统中的安装,因此,本文选用WordNet 2.1版本)。
利用GetScore()方法计算出的值为两个英文单词的语义相似度,取值范围为[0,1]。由语义距离和语义相似度“两个词汇的语义距离越大,其相似度越小”的关系,可定义Sim(A, B)和Dist(A, B)之间的简单转换方法,如下:
Dist(A,B)=1-Sim(A,B)(7)
这样计算出来的语义距离值的范围为[0,1],符合本算法归一化的要求。
(3)Google翻译API
当前Google免费提供了翻译的API,主要有两种调用方式:B/S方式调用Google Ajax语言API,可以翻译和检测网页中的文本块的语言;C/S方式调用Google Translate API,设定from、to和text后获得返回值中的翻译结果。通过编程方式调用Google翻译API,程序读取表中的中文字段后,将访问Google翻译服务并提供相应的英文翻译结果。本文选用B/S模式调用Google Ajax语言API的方式,辅助完成中文向英文的转换过程,再利用WordNet进行英文单词间的同义比较。过程中需要加载Newtonsoft.Json.Net35.dll文件,使用语句MultiLanguageTranslate(strTranslateString, "zh-CN", "en")调用翻译方法。
由以上分析可见,根据单词不同的中英文属性,选择适合的同义词词库进行同义词的比较是准确进行单词语义分析的关键。在本文中此过程通过函数syn(string P, string T)实现。
4.3 编辑距离归一化
由于某些应用中序列的长度相差较大时,序列长度对最终代价函数的计算结果影响较大,因此,有必要对距离值进行归一化操作。
目前,常用的归一化方法主要有基于编辑路径的长度和基于序列的长度两种方法。本文采用文献[23]提出的归一化编辑距离计算方法,其计算方法如式(3)所示,文献[29]对这种归一化方法进行了完整的证明,证实其完全满足三角不等式标准,进一步发展了编辑距离理论。
4.4 相似重复记录检测流程
为了检测并清除相似重复记录,对计算好语义编辑距离的记录,可以结合聚类算法进行编辑距离相似性聚类,以便于进行识别工作。基于改进编辑距离算法的数据清理基本流程主要包括阈值设定、分词过程、相似度计算和重复记录聚类4个阶段。设定聚类的阈值δ(0≤δ≤1),若比较的两记录Sx和Sy之间的归一化编辑距离Dist小于等于这一阈值,则说明Sx和Sy具有一定的相似度,可以将两记录认为是相似重复记录,从而聚为一类。对聚类的结果采用人工判别的方式进行相应的验证,从而得到算法的查全率和查准率。
5 实验结果及分析
5.1 实验方法
根据以上的算法定义,本文实现了一个基于同义词词库的归一化编辑距离计算程序,其中选用正向最大匹配算法对待比较的两条记录进行分词操作。对于记录相似度计算的结果评价,目前还没有一个较为通用的标准,本文采用了人工判别的方法。使用以下三种方法来计算相似度,并对它们的计算结果进行比较:
(1)传统的编辑距离算法,以字符为比较单位,代价值均为1,结果未归一化。
(2)归一化编辑距离算法,以字符为单位,设置可变的代价值,计算结果归一化。
(3)本文提出的基于同义词词库的归一化编辑距离算法,以单词为单位,设置可变的代价值,计算结果归一化处理。
在参数的选择上,通过反复的比较与验证,最终确定使实验结果最合理的操作代价值。实验中分别将insert设为0.5、0.6、0.7、0.8、0.9,delete设为0.7、0.8、0.9、1,substitution设为0.6、0.7、0.8、0.9,发现不同取值对相似度计算结果会产生重要的影响,原因在于操作代价值反映了各操作对文本意义更改的区分度,具有很强的现实意义。经多次测试,最终设置操作代价值为:insert=0.6,delete=1,substitution=0.8。
5.2 实验结果及分析
本文分别选择了部分具有代表性的词汇和语句进行了两次实验。第一次实验针对单词进行,目的是检查本文提出的方法在同义词比较方面是否能够正确的识别;第二次实验针对语句进行,验证本文提出的方法在句子识别过程中进行同义词比较和归一化处理的作用,进而验证整体算法的合理性。最后,对具有多个属性的数据表进行了第三次实验。其中实验数据一中含有69条记录,实验数据二中含有64条记录,通过对实验数据按照用户指定的关键属性进行相似性匹配,则共产生4 416条计算结果值。利用动态优先队列算法对记录进行聚类,将实验结果进行统计,从而可以验证算法在相似重复记录识别上的有效性。
| 表1 单词编辑距离计算结果一 |
表1显示了中文和中文、英文和英文进行匹配的情况,可以看出,方法2对距离值进行归一化操作,从主观理解上改进了方法1没有考虑原始序列长度这个缺点,使计算准确度得到提高。方法3由于在方法2的基础上引入了同义词比较的概念,可以比较细腻地区别不同词汇,因此其计算的结果更趋于合理。比如“工人”和“雇工”的距离比“工人”和“教师”的距离小;“教师”和“老师”、“教书匠”的距离都为0,并小于和“农民”的距离;“doctor”和“repair”、“mend”、“fix”等的距离都为0;“play”和“sport”、“game”的距离小于和“football”、“basketball”的距离。从认知的角度看,方法3计算的距离更具有可比性。
| 表2 单词编辑距离计算结果二 |
表2中显示的是中文和英文进行匹配的情况,从结果中可以看出,“CPU”与“中央处理器”的距离明显小于与“心脏”的距离,这与方法1和方法2计算的结果相反,从认知的角度看,“中央处理器”即为“CPU”,而“心脏”为动物的器官,很明显,方法3通过引入Google翻译API使得中英文同义词比较成为可能,并且计算的结果合理。再如Google翻译API将“医生”翻译为“doctor”、“修理”翻译为“maintenance”、“维修”翻译为“repair”,经比较发现表2的计算结果与表1完全一致。
第二次实验的结果如表3所示:
| 表3 语句间的编辑距离计算结果 |
表3中显示的是对语句进行匹配的结果,可以看出方法3对中文、英文的比较都能够得到较为满意的结果,可以较好地识别出语句之间的细微差别,计算结果更趋于合理。如“他是一个工人”和“he is a worker”的距离值为0,和“我和他都是经验丰富的工人”的距离值为0.680。但是算法对单词交换操作的识别效果较差,如“我和他都是工人”和“he and I are workers”的距离值明显高于与“I and he are workers”的距离值。
以“我们是工人”和“我们都是工人”为例,由于Google翻译API将“是”翻译为“is”,将“都是”翻译为“are”,所以“我们都是工人”与“we are workers”的距离值要小于“我们是工人”与“we are workers”的距离值。因此可以看出,对于中英文比较的情况,由于Google翻译API对不同单词翻译的差别,使得计算出的距离值存在一些偏差,可见初始的句子表述对距离值计算存在一定影响。
经过第三次实验发现,分别利用传统算法和改进算法对两个相同的数据表进行记录相似性匹配,其计算结果有很大的差别。对此次实验结果进行统计,可以得到算法的计算时间、查全率、查准率的对比情况如表4所示:
| 表4 算法性能对比 |
可以看出,改进算法在查全率方面提高10%;在查准率方面提高25%。通过F值可以看出两个算法综合性的差距,证明改进的编辑距离算法大幅度提高了相似重复记录的查全率和查准率,使得匹配结果得到了极大的改善。说明同义词词库的调用和编辑距离值的归一化处理在匹配过程中发挥了作用,计算结果更符合语义层的概念,准确性更高。但是同时也看到,由于需要进行同义词比较,在计算时间上,改进编辑距离算法还需进一步优化。
综合分析,本文提出的改进编辑距离算法适合应用于相似重复记录识别的过程中。
6 结语
语义相似度计算是相似重复记录清理的基础,是计算机语言学深入研究的内容。本文通过对编辑距离算法进行分析,提出了一种改进的基于语义编辑距离的相似重复记录清理算法,通过调用同义词词库及对距离值进行归一化处理,使得算法更符合现实意义。通过调用Google翻译API使得中英文之间的同义词比较成为可能,因为改进的编辑距离算法以单词为基本单位进行比较,而对于这种单词翻译,Google翻译API具有良好的准确性,因此其适合在本算法中应用。利用实验对比分析验证了改进算法的合理性,绝大部分结果符合人们的主观经验,查全率可达83%,查准率可达93.75%。
但是,在交换操作的识别和中英文互译的准确性方面还存在一定的问题,这是本方法尚待解决的不足之处。在以后的研究工作中,可进一步探讨优化同义词词库的语言结构及相似度计算方法,如可考虑将《同义词词林》和《知网》结合起来计算中文相似度。并针对某一特定领域建立特殊的构建体系,以此为基础设计更加合理的相似重复记录识别算法。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|