{kind=link}
基于负关联规则与频繁项集挖掘的信息检索系统*
引用本文
黄名选, 余如. 基于负关联规则与频繁项集挖掘的信息检索系统* . 现代图书情报技术, 2011, 27(7): 91-96
Huang Mingxuan, Yu Ru. Information Retrieval System Based on Negative Association Rules and Frequent Itemsets Mining. 现代图书情报技术, 2011, 27(7): 91-96
Permissions
Huang Mingxuan, Yu Ru. Information Retrieval System Based on Negative Association Rules and Frequent Itemsets Mining. 现代图书情报技术, 2011, 27(7): 91-96
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
基于负关联规则与频繁项集挖掘的信息检索系统*
摘要
提出一种新的基于负关联规则与频繁项集挖掘的信息检索系统模型,详细阐述系统模型的设计思想、各模块的功能,以及检索系统实现的三种关键技术(即频繁项集挖掘技术、负关联规则挖掘技术和查询优化扩充技术)及其检索算法。实验结果表明,该检索系统能有效提高和改善信息检索性能。
关键词:
信息检索; 频繁项集; 负关联规则; 模型
中图分类号:TP391
Information Retrieval System Based on Negative Association Rules and Frequent Itemsets Mining
Abstract
A novel model of information retrieval system based on negative association rules and frequent itemsets mining is proposed, and its designing conception and the function of each module are expounded. And some key techniques to implement the model and searching algorithm are also expatiated. The results of experiment show that the proposed model can improve and enhance the performance of information retrieval effectively .
Keyword:
Information retrieval; Frequent itemset; Negative association rule; Model
1 引言
随着Web信息急剧膨胀,如何便捷、准确地检索到所需信息已成为信息检索研究的热点。然而,依赖于布尔查询技术和基于关键词机械式符号匹配技术的Web信息检索系统,即搜索引擎,其检索结果难以全面地反映用户的查询意图,使得现有的Web信息检索系统难以满足用户查询信息的需要。针对上述问题,不同的学者从不同的角度提出了各种信息检索系统模型,这些模型大致归结为如下5类:
(1)基于经典检索模型(布尔模型、向量空间模型、概率模型等)的信息检索系统,如搜索引擎。其主要优点是实现起来比较容易,查询语言表达简单,缺点是都强调关键词的统计信息,忽略了关键词之间的语义信息。
(2)基于本体的信息检索系统[ 1, 2, 3]。其原理是首先构造本体(如语义网和语义概念网),根据本体建立“词-词”相似度矩阵,然后对用户查询和文档根据专家建立的本体进行特征词提取,最后通过“词-词”相似度矩阵可以得到用户查询和文档之间的相似度。这种检索系统在一定程度上把信息检索从目前基于关键词的层面提高到基于知识的层面,实现了语义查询。
(3)基于自然语言处理的信息检索系统[ 4, 5, 6, 7]。其使用的技术包括自动分类、自动摘要、相似性检索和基于语言模型等信息检索技术。迄今为止,自然语言处理在信息检索中的应用还仅仅集中在分词、词典的使用、词义消歧、命名实体识别等方面,信息检索与自然语言处理技术的结合还只是通过较松散的预处理、后处理等方式进行。
(4)基于粗糙集和模糊集的信息检索系统[ 8, 9]。其原理是以粗糙集技术为支撑,结合模糊集合理论,对查询进行泛化以提高查询性能。
(5)基于数据挖掘技术的信息检索系统[ 10, 11, 12, 13]。其主要思想是对过去用户访问的各种链接和网页内容[ 10]、用户的访问日志[ 11]或局部文档或全局文档[ 12, 13]进行关联规则挖掘,从而揭示文档中语词/概念之间的相关性,构造词间关联库,通过关联库对用户查询进行优化、扩展和修正,再进行二次检索,以提高信息检索性能。
在数据挖掘技术应用于信息检索领域的研究中,当前的研究焦点只是考虑从关联规则找出语词/概念之间的相关性,并不重视从频繁项集模式中直接发现各种相关性。实际上,频繁项集中的项集间本质上是客观地反映各种相关性,这种相关性有可能是正相关、负相关或假相关,而负关联规则本质上反映项集间的各种否定关联,因此,将负关联规则挖掘和频繁项集挖掘技术融合,应用于信息检索领域,具有重要的学术研究价值和现实意义。为此,本文提出一种基于负关联规则与频繁项集挖掘的信息检索系统模型及其检索算法。该模型由7个功能模块组成,并融合了频繁项集挖掘、负关联规则挖掘和查询优化扩充等三种关键技术。实验结果表明,该模型及其检索算法能有效地改善和提高信息检索性能,具有广阔的应用前景。
2 基于负关联规则与频繁项集挖掘的信息检索系统
2.1 检索系统的设计思想
首先将原始查询通过用户界面提交给搜索引擎,在返回的初检结果中提取前列n篇文档作为局部相关文档集,然后对局部文档集采用三种关键技术(即频繁项集挖掘、负关联规则挖掘和查询优化)进行处理,得出优化后的新查询,再次提交到搜索引擎进行二次检索,最后返回二次检索的查询结果给用户。
上述三种关键技术对局部文档集的具体处理是:
(1)关联词库的创建:采用频繁项集挖掘算法对局部相关文档集挖掘频繁项集和非频繁项集,分别构造频繁项集库和非频繁项集库,从频繁项集中发现与原查询相关的各种关联,由此获得与原查询相关的关联词,建立关联词库;
(2)负关联词的发现:采用负关联规则挖掘算法对频繁项集和非频繁项集挖掘负关联规则,建立负关联规则库,从负关联规则发现与原查询负相关或假相关的关联,由此获得与原查询负相关或假相关的负关联词,计算每一个负关联词与整个原查询的相关性,将相关性不大于1的负关联词入库,建立负关联词库,而对于那些相关性大于1的负关联词与原查询不是真正的负关联或假相关,因此不能入库;
(3)查询的优化和扩充:将存在于关联词库中的、与负关联词库中相同的词删除,对余下的关联词计算其权值,并添加到原查询组合成新查询,实现查询优化和扩充。
2.2 检索系统模型框架及其模块功能
根据设计思想,该信息检索系统模型结构,如图1所示:
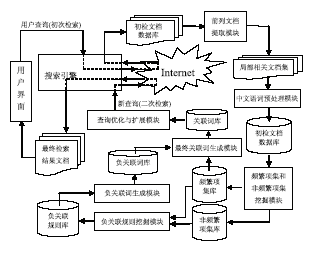 | 图1 基于负关联规则与频繁项集挖掘的信息检索系统模型结构 |
该系统模型包括7个功能模块:前列文档提取模块、中文语词预处理模块、频繁项集和非频繁项集挖掘模块、负关联规则挖掘模块、负关联词生成模块、最终关联词生成模块和查询优化与扩展模块;以及6个数据库:初检文档数据库、频繁项集库、非频繁项集库、负关联规则库、负关联词库和关联词库。
各模块功能如下:
(1)提取前列文档模块:根据搜索引擎对原查询的检索结果,提取前列n篇文档组成初检局部相关文档集。
(2)中文语词预处理模块:该模块主要针对从提取前列文档模块中获得的局部相关文档集进行预处理,完成中文语词切分,去掉停用词等预处理,提取特征词,构建基于向量空间模型的初检文档数据库。
(3)频繁项集和非频繁项集挖掘模块:该模块负责发现与原查询相关联的词或者概念,对初检文档数据库挖掘同时含有原查询词项和非查询词项的非频繁项集和频繁项集,分别构建频繁项集库和非频繁项集库,从频繁项集库中提取与原查询词关联的词,建立关联词库。
(4)负关联规则挖掘模块:该模块负责寻找与原查询负相关或假相关的词或者概念,对频繁项集库和非频繁项集库挖掘负关联规则,提取前件是原查询词项的负关联规则构建负关联规则库。
(5)负关联词生成模块:该模块负责从负关联规则库中提取负关联词,计算每一个负关联词与整个原查询词的相关性,将相关性不大于1的负关联词入库,建立负关联词库。
(6)最终关联词生成模块:该模块负责从频繁项集库中的每一个频繁项集提取其中的非原查询词项作为关联词,建立关联词库,并在关联词库中删除与负关联词库相同的词,最后对余下的关联词计算其权值。
(7)查询优化与扩展模块:从关联词库中提取关联词及其权值,和原查询词重新组合成新查询,实现对原查询的优化和扩展,最后,提交新查询给搜索引擎二次检索,将返回的最终检索结果文档按照用户所需的格式推送到用户界面。
2.3 检索系统模型中的关键技术
(1)频繁项集和非频繁项集挖掘
在本文的检索系统模型中,对初检文档数据库挖掘非频繁项集和频繁项集的过程如下:首先从初检文档数据库提取特征词,按其在初检文档集中的出现频次降序排列,提取同时含有查询词项和非查询词项的前列m个特征词作为候选1_项集。根据最小支持度阈值,由候选1_项集产生频繁1_项集,频繁1_项集与自己进行Apriori连接[ 14],进行剪枝操作,产生候选2_项集,根据最小支持度阈值,由候选2_项集产生频繁2_项集和非频繁2_项集,提取同时含有查询词项和非查询词项的频繁2_项集和非频繁2_项集分别存入频繁项集库和非频繁项集库中,再将上述的频繁2_项集与自己进行Apriori连接,产生候选3_项集,再产生频繁3_项集和非频繁3_项集,提取同时含有查询词项和非查询词项的频繁3_项集和非频繁3_项集分别存入频繁项集库和非频繁项集库中,……,循环进行下去,可得频繁4_项集和非频繁4_项集、频繁5_项集和非频繁5_项集、……,并存入频繁项集库和非频繁项集库中,直到不能产生频繁项集为止。
在挖掘过程中,那些只含查询词项并没有非查询词项的候选项集,或者不含查询词项的候选项集,对发现与原查询关联的关联词和负关联词没有任何贡献,是属于剪枝的对象。
(2)负关联规则挖掘
根据查询优化和扩展的需要,本文只考虑挖掘q⇒¬t形式的负关联规则,其中q代表原查询词项,t代表非原查询词项,其挖掘的主要思想是从频繁项集库和非频繁项集库中挖掘与原查询成负关联或假关联的词。其挖掘过程是:
①求出频繁项集和非频繁项集的各类子项集;
②求负规则的前件q:将只含有查询词项的子项集作为规则的前件;
③求负规则的后件t:将不含查询词项的子项集作为后件;
④求q⇒¬t形式的负关联规则:计算前件和后件的相关性,当相关性小于1时, 根据给定的最小支持度和最小置信度阈值,生成形如“q⇒¬t”的强负关联规则,建立负关联规则库。其中,相关性的计算方法见文献[15]。
(3)查询优化与扩充
频繁项集中项集间会存在着某种关联[ 14]。根据这个事实会发现,如果一个频繁项集中同时存在原查询词项和非原查询词项的特征词,则这两类特征词会存在着某种关联,由此可以发现与原查询词存在某种关联的关联词。由于这种关联有可能是正关联、负关联或假关联,所以,还需要通过负关联规则挖掘技术发现与原查询负相关或假相关的负关联词,通过删除负关联词后就可以得到与原查询正相关的最终所需的关联词,将这些关联词与原查询重新组合得到新查询,可以达到查询优化扩充的目的。
根据上述查询优化的思想,可以得到如下的查询优化和扩充过程:
①从频繁项集库中提取关联词;
②从负关联规则库中提取负关联词;
③删除关联词中所有的负关联词,计算余下关联词的权值,并与原查询组合成新查询。
关联词t的权值主要以包含该关联词项的频繁项集的支持度为依据,由此得到其权值Wt计算方法如下:
Wt=
 | (1) |
通过式(1)得到的关联词权值还要经过规范化处理,使其值在[0,1]区间内。在查询优化和扩充过程中,原查询项永远是最重要的,最能反映用户查询意图,故原查询词项权值可设为大于1的数,本文设为2。
2.4 检索算法描述
算法:基于负关联规则与频繁项集挖掘的信息检索算法(Information Retrieval System Based on Negative Association Rules and Frequent Itemsets Mining,NAR&FI_Retrieval算法)
输入:原查询(q),最小频繁项集支持度(minsup),最小负关联规则支持度(Nminsup)和置信度(Nconf),前列文档篇数(n)
输出:经过查询优化和扩充后的最终检索结果
算法描述:
Begin
(1)搜索引擎对用户查询q进行检索,在初检结果中提取前列n篇文档组成初检前列局部文档集。
(2)对初检前列局部文档集进行预处理,如语词切分、去掉停用词等,提取特征词,构建基于向量空间模型的初检文档数据库。
(3)对初检文档数据库挖掘同时含有查询词项和非查询词项的特征词频繁项集和非频繁项集,具体算法如下:
①扫描初检文档数据库, 提取特征词,统计其在初检文档集中出现的总频次,并降序排列,建立总的特征词库;
②提取m个同时含有查询词项和非查询词项的前列特征词作为候选1_项集;
③根据minsup阈值,由候选1_项集产生频繁1_项集;
④for (k=2;频繁k-1项集不为空; k++)
1)频繁k-1_项集与自己进行Apriori连接,产生候选k_项集;
2)对候选项集进行剪枝操作(Apriori剪枝,以及删除只含查询词项并没有非查询词项的候选项集,或者不含查询词项的候选项集);
3)统计候选项集在初检文档数据库中的支持数,计算其支持度;
4)根据minsup阈值,由候选k_项集产生同时含有查询词项和非查询词项的频繁k_项集和非频繁k_项集;
5)频繁k_项集和非频繁k_项集入库,分别建立频繁项集库和非频繁项集库;
(4)从频繁项集中提取非原查询词作为关联词,建立关联词数据库。
(5)对频繁项集和非频繁项集挖掘前件是原查询词后件是非查询词的负关联规则,具体算法如下:
①for 每一个频繁项集lido
if (q属于 li)and (q和(li - q)的相关性<1)and (q和(li - q)的支持度不小于minsup)and (q,¬((li - q))的支持度不小于Nminsup)and (q⇒¬(li - q))的置信度不小于Nconf then 输出负关联规则q⇒¬(li - q),并入负关联规则库
②for 每一个非频繁项集Nlido
if (q属于 Nli)and (q和(Nli - q)的相关性小于1)and (q和(Nli - q)的支持度不小于minsup)and (q,¬(Nli - q))的支持度不小于Nminsup)and (q⇒¬(Nli - q))的置信度不小于Nconf then 输出负关联规则q⇒¬(Nli - q),并入负关联规则库
(6)从负关联规则库中提取负关联词,计算每一个负关联词与整个原查询(q)的相关性,将相关性不大于1的负关联词入库,建立负关联词库。
(7)删除关联词库中与负关联词相同的词,计算余下关联词的权值,并作规范化处理。
(8)将原查询中各个查询项的权重置为2,将原查询和关联词库中的关联词组合成新查询,实现查询优化扩充。
(9)将新查询提交给搜索引擎,进行二次检索,输出最终的检索结果。
End
3 实验设计及其结果分析
3.1 数据集和评测方法
由于搜索引擎的研究范围较广,本文难以一一涉及到,所以本该在搜索引擎上实验的,现改由传统的向量空间模型检索系统完成。因此,本实验是个模拟实验。实验用的测试集由720篇计算机领域方面的论文组成。对测试集经过分词、去掉停用词等预处理,构建基于向量空间模型的文本数据库。设计了6个原始查询(q1,q2,…,q6)作为查询集,并人工检索获得原查询在原始测试文档集中的相关文档篇数。对每一个查询的初检局部文档集也采用同样的预处理,建立基于向量空间模型的局部文本数据库及其特征词库,根据特征词的频度降序排列并取其前列m个特征词作为频繁项集挖掘的对象。为了评估检索模型及其算法的检索性能,将查全率和查准率作为实验中的主要评测指标。
3.2 实验设计及其结果分析
编写模拟实验源程序,将NAR&FI_Retrieval算法与传统的基于向量空间模型检索系统(即TF-IDF算法)比较。实验中的参数设定如下:前列特征词个数m取50,在初检中,查询与文档的余弦相似值取0.2时提取各个查询的初检文档构成初检局部文档集,挖掘频繁项集时所用的最小支持度阈值minsup的取值是:q1、q2、q3的取0.3, q4、q5、q6的取0.4。将上述两种算法分别对所设计的6个查询在相同的测试文档集中进行检索,统计这6个查询在10点查全率水平级下总的平均查准率,实验结果如表1所示:
| 表1 检索性能比较 |
从表1可以看出,在测试文档集上, NAR&FI_Retrieval算法确实获得了相当好的效果。相对于传统的基于向量空间模型检索系统,在10点查全率水平级下总的平均查准率有了明显的提高,即提高的幅度达到17.50%。主要原因分析如下:本信息检索模型中,采用了频繁项集挖掘、负关联规则挖掘和查询优化扩充等三种关键技术,通过频繁项集挖掘技术和负关联规则挖掘技术的融合,发现与原查询正关联的关联词,添加到原查询实现查询优化扩充,扩充后的新查询能够检索到原始查询所不能检索到的文档,所以本文算法的查询性能比没有进行查询优化扩充的TF-IDF算法有明显的提高。
4 结语
本文针对现有Web信息检索系统存在的缺陷,将负关联规则挖掘与频繁项集挖掘技术融合应用于信息检索,提出基于负关联规则与频繁项集挖掘的信息检索系统模型及其检索算法。其检索算法对用户查询的初检文档采用了频繁项集挖掘和负关联规则挖掘技术,获取与原查询相关的关联词,对原查询进行优化扩充后,进行二次检索,以提高检索性能。实验结果表明,该检索系统能有效地提高和改善信息检索查询性能。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| 9 |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|