

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于语义的情感挖掘系统的设计与实现*
引用本文
李纲, 王忠义. 基于语义的情感挖掘系统的设计与实现* . 现代图书情报技术, 2011, 27(7): 97-103
Li Gang, Wang Zhongyi. Design and Implementation of Semantic-based Sentiment Mining System. 现代图书情报技术, 2011, 27(7): 97-103
Permissions
Li Gang, Wang Zhongyi. Design and Implementation of Semantic-based Sentiment Mining System. 现代图书情报技术, 2011, 27(7): 97-103
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
基于语义的情感挖掘系统的设计与实现*
摘要
由于自然语言的复杂性,使得情感挖掘仍存在一些问题需要解决,如情感词的领域依赖性、隐式特征识别、同指特征处理和特征极性计算等。为解决这些问题,提出一种基于语义的情感挖掘方法,该方法以主题图为指导进行特征及情感词的识别和情感极性强度计算,充分利用特征之间及其特征与情感词之间的语义关系,可以在一定程度上提高意见挖掘的准确性。
关键词:
情感挖掘; 主题图; 特征层次结构
中图分类号:TP391.1
Design and Implementation of Semantic-based Sentiment Mining System
Abstract
Due to the complexity of natural language, there are still some problems existing in sentiment mining such as: domain dependence of sentiment words, implicit features recognition, synonym recognition, the calculation of the features’ sentiment strengths and so on. To solve these problems, this paper proposes a sentiment mining method based on topic map. This method, which makes full use of the semantic relationships between feature words and sentiment words, can improve the accuracy of the sentiment mining to certain extent.
Keyword:
Sentiment mining; Topic map; Structure of features
1 引言
随着Web2.0技术的发展和应用,互联网上包含的主观性信息与日俱增。这些反映人们对于事物或事件看法和态度的主观信息往往包含着大量的有价值的情报。这些情报无论是对于企业开展网络口碑营销以及竞争情报工作,还是对于消费者做出购买决策,或是对于政府了解舆情等都具有重要的意义和价值。然而主观信息数量巨大,人工查找成本较高,为此,情感挖掘[ 1, 2]这一自动获取有用情感信息的技术应运而生。它通过信息抽取、自然语言处理、情感分析等手段,能够从大量的文本信息中识别和抽取主观性信息并分析其情感极性。这能够大大降低用户的搜索成本,也能够发现很多潜在的知识,在一定程度上满足了人们对于主观性信息的需求。当前,情感挖掘已经广泛应用于网络口碑分析、舆情监控、企业竞争情报分析等领域,并取得了丰富的研究成果[ 3, 4, 5, 6, 7, 8, 9]。然而,由于自然语言的复杂性以及人们发表言论时的随意性,使得基于特征的情感挖掘[ 10]仍存在着一些问题有待进一步处理和优化。 (1)情感词的领域依赖性。情感词本身所表达的情感倾向与其所属的领域密切相关,同一个情感词与不同的特征相关联时,具有不同的情感倾向。
(2)隐式特征识别。在字面上不能直接识别,需要通过修饰语进行分析才能获得的特征称为隐式特征。比如“重”和“轻”是用来修饰“重量”的,当仅出现“重”和“轻”时,可推知隐式特征为“重量”。
(3)同指特征处理。同样的特征往往有不同的表达方式,如“笔记本”、“本本”、“手提”等都是指笔记本电脑,在特征抽取时,需能有效处理这些同指特征。
(4)特征极性计算。当前有关特征极性的计算仅考虑了单独特征的情感极性,未考虑特征之间的相互关系对特征极性的影响。
为解决以上问题,本文将主题图的基本思想集成到情感挖掘中,设计并实现了一个基于语义的情感挖掘系统。该方法以主题图为指导进行特征及情感词的识别和情感极性计算,充分利用了特征及其情感词之间的语义关系,能够在一定程度上提高情感挖掘的准确性。
2 方法
基于语义的情感分析方法的基本思路是:
(1)构建一个有关某主题领域的主题图,该主题图中描述了相关主题领域的各种特征、特征之间的关系以及与特征相对应的情感词;
(2)在主题图的指导下实现特征和情感词的抽取,由于主题图揭示了特征之间以及特征与情感词之间的关系,因此能够有效解决情感词的领域依赖性、隐式特征识别、同指特征处理等问题;
(3)对句子中的否定关系、程度副词进行处理,以对情感极性进行修正;
(4)依据主题图所揭示的特征层次结构,通过子特征极性计算属特征极性,以满足人们对某主题的宏观层次的情感信息的需求;
(5)对各特征情感分析结果进行合成,生成意见摘要。
在情感分析中引入主题图,能够在一定程度上实现基于语义的情感分析,进而提高情感分析的准确性。
2.1 基于语义的情感挖掘系统模型
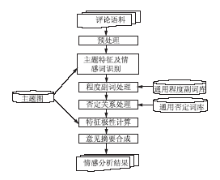
基于语义的情感挖掘系统模型如图1所示:
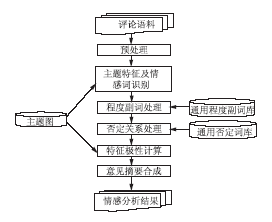 | 图1 基于主题图的意见挖掘模型 |
该方法模型主要包括6个功能模块,各模块的主要功能如下:
(1)预处理:原始数据是半结构化或者非结构化数据,利用预处理工具对其进行结构化处理生成结构化数据,作为情感分析的输入数据。包括句子切分、中文分词、词性标注、句法分析等步骤。
(2)主题特征及情感词识别:属于情感分析的核心步骤,主要是在主题图的指导下对句子中的特征以及与特征有着修饰关系的情感词进行发现和识别,并初步确定此句含有的情感极性。
(3)程度副词处理:识别出结构化数据中包含的程度副词,判断程度副词修饰的对象,并根据程度副词的特征,对被修饰对象的情感极性强度进行强化或者弱化处理。
(4)否定关系处理:结合否定词词典对否定关系进行处理。对结构化数据中包含的否定关系进行自动识别,然后判断否定关系中被否定词否定的对象。
(5)特征极性计算:依据主题图所揭示的各特征之间的层次关系,在得知子特征的情感极性值的情况下,加权计算得到属节点的情感极性。
(6)意见摘要合成:对于多文档数据进行情感分析后,将产生大量的关于特征的情感倾向,这其中不仅包含正面的观点,也会包含负面的观点。意见摘要合成将大量的观点合成一个摘要,便于用户分析和查看。
2.2 主题图构建
主题图的构建采用的是半自动的方式。由领域专家根据其对该领域的了解,借助一定的主题特征和情感词的抽取工具(CASE Tool)和工具辞典(HowNet、《中国网络语言辞典》)以及主题图编辑工具(Ontopoly),完成对主题图的编辑工作。具体步骤如下:
(1)确定主题图应用的目的和范围:根据所研究的领域或任务,建立相应的主题图;
(2)主题分析:由领域专家根据对该领域的了解定义主题及主题之间的关系;
(3)主题图评价:对主题图进行清晰性、一致性和完整性等评价,以根据情况,优化主题图;
(4)主题图的建立:根据以上要求对评价优化达到要求后的主题图进行存储。
2.3 特征及情感词识别
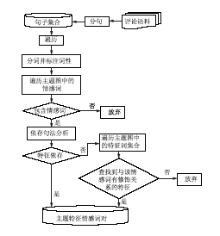
通过半自动方式构建的主题图实际上构成了一个针对某一主题领域的特征和情感词的层次结构。在特征和情感词的识别过程中,以该主题图为指导能够有效解决情感词的领域依赖性、识别隐式主题和同指主题等问题,提高情感挖掘的准确性。基于主题图的特征及情感词识别过程如图2所示:
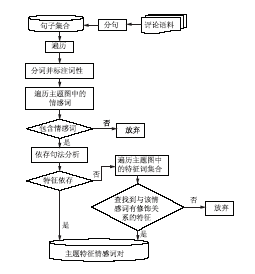 | 图2 特征和情感词识别 |
(1)分句:将评价语料处理成单句的形式,将句子集合存储在数据库中;
(2)分词并标注词性:遍历每一个单句,对每一单句采用中国科学院计算技术研究所开发的汉语词法分析系统ICTCLAS进行分词和词性标注;
(3)遍历主题图中的情感词:将分词结果与主题图中的情感词进行逐一匹配,如果不包含情感词,则说明该句不是情感句,所以丢弃,不进行情感分析,如包含情感词则进入步骤(4);
(4)依存句法分析:使用Stanford Parser对该句进行依存句法分析,若与主题图中某特征存在依存关系,则存储该主题特征情感词对,并记录其情感极性值,如果不存在特征依存,则说明此句不包含显式主题特征,则进入步骤(5);
(5)遍历主题图中的特征集合:当通过依存句法分析,找不到与该情感词相对应的显式特征时,则在主题图中查找与该情感词有修饰关系的特征,进行隐式特征识别,若查找到该特征词,则隐式特征识别成功,将该主题特征和情感词对存储在数据库中,并记录其情感极性。
2.4 程度副词处理
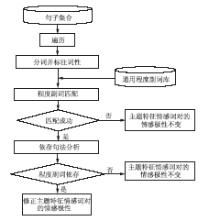
程度副词对用户的情感表达起着极其重要的作用,其能够改变句子的情感极性强度,因此,在情感挖掘中对程度副词进行处理是必不可少的环节。本文主要采用依存句法分析的方法对程度副词进行处理,识别它们与情感词的修饰关系,根据句法分析结果对情感极性进行修正。程度副词处理的过程如图3所示:
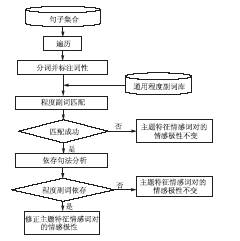 | 图3 程度副词处理 |
主要步骤包括:
(1)分词并标注词性:该步骤与特征及情感词识别中的分词并标注词性为同一步骤,此处不再赘述;
(2)程度副词匹配:将分词结果与通用程度副词匹配,如果匹配失败,则主题特征情感词对的情感极性保持不变,如果匹配成功,则进入步骤(3);
(3)依存句法分析:通过程度副词匹配,如果匹配成功,则使用Stanford Parser进行依存句法分析,如果程度副词和情感词存在依存关系则修正主题特征情感词对的情感极性,如果不存在则主题特征情感词对的情感极性保持不变。
2.5 否定词处理
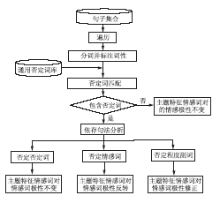
否定词能够改变句子的情感极性方向,在情感挖掘中,对否定词进行处理是至关重要的一步。在对否定词进行处理时,本文根据依存句法关系,找出被否定的词语,如果为单独一个词语,则其为否定范围,如果为情感词,则对情感极性反转;如果为多个词,那么这些词语组合成焦点词组为否定范围,如果词组是由程度副词和情感词组成,那么在计算情感倾向时,对极性强度进行修正。具体处理流程如图4所示:
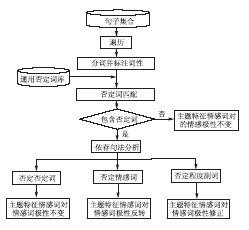 | 图4 否定词处理 |
(1)分词并标注词性:该步骤与特征及情感词识别中的分词并标注词性为同一步骤,此处不再赘述;
(2)否定词匹配:将分词结果与通用否定词匹配,如果匹配失败,则主题特征情感词对的情感极性保持不变,如果匹配成功,则进入步骤(3);
(3)依存句法分析:使用Stanford Parser对该句进行依存句法分析,通过分析确定否定词的否定范围,如果否定词是对另外一个否定词进行否定,则表示是双重否定即为肯定,因此,情感极性保持不变;如果否定词是对情感词进行否定,则将其情感极性进行反转;如果是对包含程度副词的词组进行否定,则将其表示的程度进行修正。
2.6 特征极性计算
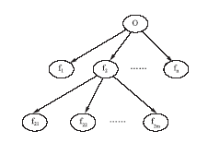
特征实际上是一个比较宽泛的概念,它泛指一切被描述的对象、对象的组件以及属性等。例如对于手机这一商品对象来说,“摄像头、屏幕”等是其组件,“款型、屏幕尺寸”等是手机及其组件的属性,对于意见持有者来说,发表意见时不会刻意去区分组件与属性,而是将它们都作为特征看待。因此特征包含的内容非常丰富,并且这些特征之间存在某种层次关系,共同构成了一个特征体系,如图5所示:
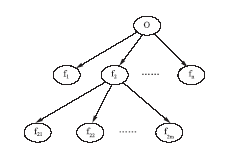 | 图5 特征层次示意图 |
在该特征体系中,意见持有者对某一子特征的评价,也隐含着对其属特征的评价,反之亦然。也就说这些特征极性之间是相互影响的,然而在当前已有的基于特征的情感挖掘算法中都没有考虑特征极性之间的这些相互影响关系,势必影响情感挖掘的准确性。为解决这一问题,本文以主题图揭示的特征层次结构为基础,提出了一种特征极性强度计算方法,计算某一特征的极性对与其相关的特征极性的影响值,并将其综合到与其相关的特征的情感极性强度中,以提高情感挖掘的准确性,计算方法如下:
Pt(节点)=P(节点)+ 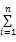
其中,P(节点)表示通过情感挖掘后节点的初始情感极性强度值,Pt(节点)表示综合了其子节点对其情感极性影响后的总情感极性强度值。W(子节点i)表示子节点i的权重,计算方法如下:
W(子节点i)=
 | (2) |
其中,n表示父节点包含的子节点的个数。从式(2)可以看出,在默认情况下,子节点对于父节点来说具有相同的权重,但用户可以根据需要调整各特征的相对重要性的权重(必须保证各子特征的权重之和为1)。这样做的目的主要是出于以下考虑:用户在选择商品时,商品的各个特征在不同用户的心目中的重要性也不相同,比如可能有的用户对洗衣机的“性能”的要求比其他特征更高,而有的用户可能对洗衣机的“经济性”的要求更高,也就是说用户有根据自己的偏好来调整特征的权重的需求。这样做可以很好地满足用户的个性化需求。因此,通过式(1)和式(2)可以获得特征f2的总情感极性强度如下。
Pt(f2)=P(f2)+P(f21)×W(f21)+P(f22)×W(f22)
+…+P(f2m)×W(f2m)(3)
3 实验
3.1 数据来源
实验系统将以洗衣机为主题,数据来源为京东商城(http://www.360buy.com)中顾客关于多款型号的洗衣机发表的评论。洗衣机是生活必需品,需求量大,由于洗衣机品牌样式多样,顾客在选购洗衣机时,往往遇到很大的困难,而互联网社区或者问答平台中,存在大量的网友们分享的产品评论,从这些评论中挖掘出有价值的信息对于购买者来说具有重要的价值,因此本文选择洗衣机作为实验系统的主题。京东商城是中国B2C市场很大的3C网购专业平台,是中国电子商务领域最受消费者欢迎和最具影响力的电子商务网站之一。京东商城为顾客提供商品评论功能,允许在线购买过此商品的顾客对商品的质量、价格、服务等各个方面发表评论,从而积累了大量的主观信息,为此,本文将京东商城作为实验数据的来源。为了让数据更具有代表性和统计意义,仅选择了评论数量超过100的热门机型,共计20款。针对这20款热门机型,对京东商城网站上的主观性评价信息进行了抽取,截至2010年11月20日,共收集4 025条评论。
3.2 洗衣机领域主题图构建
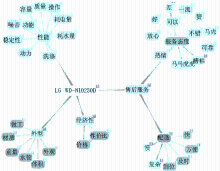
依据主题图构建方法,首先借助主题特征和情感词的抽取工具CASE Tool从抓取的情感语料中自动抽取特征和情感词;利用工具辞典HowNet和《中国网络语言辞典》进行特征词和情感词扩展;由领域专家根据自己对洗衣机领域的了解借助Ontopoly建立了一个针对洗衣领域的主题图,如图6所示:
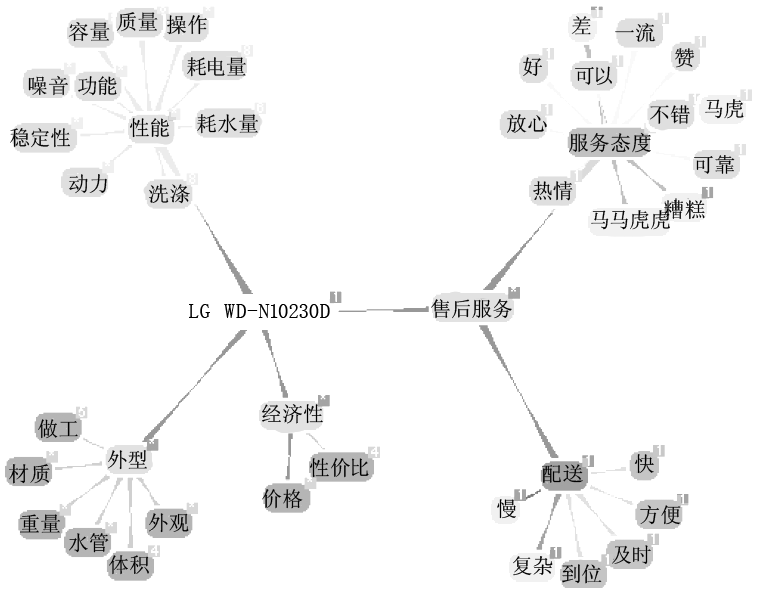 | 图6 洗衣机主题图 |
由于页面限制,图6仅展示了LG WD-N10230D这款洗衣机的主体特征层次结构及用于修饰各特征的情感词。借助主题图引擎可以对该主题图进行各种特征层次上的遍历查询,同时也可以随时对该主题图进行更新。
3.3 系统实现及摘要展示
(1)系统实现
本研究依据基于语义的情感挖掘方法,以构建的洗衣机领域的主题图为指导,借助于Java、JSP开发语言,利用MyEclipse6.6开发工具,在Windows XP(CPU为2.80GHz、内存为1GB)开发平台上实现了一个面向洗衣机领域的情感挖掘系统。整个系统主要由两部分组成:辅助知识库和工具集合。辅助知识库是进行情感挖掘的基础,包括:主题图、通用情感词库和通用程度副词库,它们提供了情感挖掘中所需要的数据支持。工具集合为情感分析提供处理工具和方法,包括:语料库标注工具、特征和情感词抽取工具、否定词处理、程度副词处理等,这些工具集合中的每个方法都是独立的,方法与方法之间以接口相联系,这样做的目的在于提高系统的可扩展性,便于今后的改进和升级。本系统提供了多种方式为终端用户服务。如以互联网、手机等方式提供服务,提供了RSS和短信等定制功能,终端用户可以根据自己的需要定制所需的服务,系统能够及时将相关信息推送给用户。
(2)摘要展示
为满足用户的个性化需求,本系统为用户提供了可自定义的情感挖掘摘要展示界面如图7所示:
 | 图7 条件设定界面 |
用户可以根据自己的喜好,选择自己关心的洗衣机品牌和不同品牌洗衣机的不同特征,系统会根据用户所设定的条件将情感挖掘摘要信息予以展示。展示的方式主要有:机型对比、排行榜等。
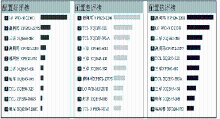
①机型对比
系统可以根据用户选择的机型及其特征,对比展示情感挖掘的结果。图8展示了三洋XQB50-S805Z、TCL XQB50-32S和海尔XQB45-10B三款洗衣机在外型、性能、经济性和售后服务4个特征上的情感极性分析结果以及总体情感极性得分。根据对比结果用户可以依据自己的偏好选择适合自己的洗衣机款型。
 | 图8 机型对比界面 |
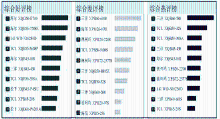
②排行榜
排行榜在多个方面进行排名,包括总体情感极性得分和特征细节得分的排名,每个排行榜分为3部分:好评榜、差评榜和热评榜。顾名思义,好评榜和差评榜关于正面口碑和负面口碑上进行排名,热评榜是在关注度上进行排名。图9是20款洗衣机“噪音”特征的口碑排行榜,图10是所有特征的综合排行榜。
 | 图9 洗衣机特征排行榜 |
 | 图10 洗衣机综合排行榜 |
3.4 结果分析
为检验基于语义的情感挖掘方法的有效性和科学性,本文对依照该方法实现的系统进行了性能测试。系统性能测试的指标有情感分析的准确率(P)、全面性(R)和F-度量(F)。
P= 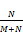
R= 
其中,N表示被识别且情感分析正确的特征个数;M表示被识别但情感分析错误的特征个数;L表示标注语料库中所有的情感特征。
F-度量是准确率和全面性两个指标通过加权平均取得的均衡的结果。F-度量的计算公式有多种,本文采用的经典计算方法:
F= 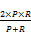
系统测试的数据集是从上述收集到的4 025条评论中随机抽取的100条正面评论和100条负面评论,并对这些评论进行人工标注,以作为系统评价的标准,为检验在情感挖掘系统中集成主题图后的比较优势,本文将基于语义的情感挖掘方法与Hu等提出的情感分析方法[ 11]进行了对比,实验结果如表1所示:
| 表1 系统性能测试结果 |
之所以选择Hu等提出的情感分析方法作为对比,主要是由于该方法是比较经典的一种情感分析方法,并且该方法没有使用任何语义信息。因此以该方法作为比较对象可以检验本文提出的情感挖掘方法集成语义信息之后的比较优势。
从表1可以看出,基于语义的情感挖掘系统的性能表现良好。本文提出的方法准确率优于Hu等提出的方法,这是由于Hu等的方法抽取了许多不相关的特征;本文提出的方法全面性也比Hu等提出的方法效果更好,主要因为本文提出的方法实现了对隐性特征的识别。可见本系统能满足实际需求,可以很好地对绝大多数主观信息进行准确有效的情感分析。
4 结语
随着网络中主观信息量的增长,主观信息中包含越来越多的有价值的情报,这些情报无论是对于政府、企业还是对于个人,都具有重要的意义和价值。为从这些主观信息中挖掘出有价值的情报,情感挖掘出现并迅速发展起来,取得了丰富的研究成果。然而,由于自然语言的复杂性,当前情感挖掘技术仍存在一些问题需要进一步解决,为在一定程度上克服这些问题,本文在前人研究的基础上,提出了一种基于语义的情感挖掘方法,该方法的创新之处在于:
(1)使用主题图描述了某一领域的特征体系和与特征相关联的情感词,在情感挖掘中以该主题图为指导可以有效实现隐式特征和同指特征的识别,克服情感词的领域依赖问题;
(2)依据主题图揭示的特征层次结构,本文提出了一个特征极性合成的计算方式,揭示了不同层次特征的情感极性强度之间的相互影响关系。
根据性能测试的结果以及理论分析可知,系统无论在实践层面还是在原理层面均能达到理想的效果和性能,能很好地满足实际的主观信息挖掘的需要,这也说明本文提出的基于语义的情感挖掘方法具有一定的可行性和有效性,能在一定程度上提高情感挖掘的准确性,从而为从主观信息中挖掘出有意义的情感信息提供了一定的帮助和指导。当然,本研究还存在一定的不足之处,即仅验证了该方法在洗衣机领域的情感挖掘的有效性,今后将在此基础上,探索其在其他领域的适用性,并在实践中发现该方法存在的潜在问题,以进一步优化。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|