
{kind=link}
{kind=link}
{kind=link}
{kind=link}
科技文献关键词冗余解决方案研究
[邢美凤 ]
]
]
|
|


提出一种改进的基于相似度计算的科技文献关键词选取算法。先利用N-gram算法提取领域词库,再综合利用领域词库和常识词库,对最初选择的关键词重新切分,进行给定关键词之间的语义对比。语义相似度大于一定阈值的关键词被认为是表达同一意义的同义词,将同义词在文献库中合并,从而解决关键词冗余问题。实验结果可以证明该方法的有效性。
Irregular keywords often cause high redundancy in the same research topic. To address the issue, this paper proposes an improved keywords selection algorithm based on similarity calculation. It re-segments keywords using field dictionary and common-sense knowledge database thesaurus. When the total semantic similarity is greater than a given threshold, the two compared keywords are considered to express the same meaning, then merging and keeping only one of them in library,which achieves the purpose of the dimension reduction. Finally, experimental results show the effectiveness of the method.
在利用作者给定的关键词进行科学研究的过程中,由于关键词数量庞大,经常要截取词频较大的一部分进行分析。这种方法有一定的科学依据,但由于作者给定的关键词不规范,同一意义在关键词中会以多种形式出现,以词频的方式选取关键词会丢失大量有用的信息。如果在利用词频处理之前,先进行关键词之间的合并或修正,将关键词进行无损压缩,可以最大程度地保留所要分析的信息内容。
本文的方法归结为语义特征降维。将作者给定的同一主题关键词组成最初的高维特征向量,选用一种合适的方式识别并合并同义词,实现关键词向量空间的有效降维。
目前,基于语义的特征降维主要利用一些常识知识库如WordNet、知网、同义词词林等进行。Chua等[ 1] 和Li等[ 2]利用WordNet中提供的同义关系、上下位关系、部分整体关系等计算词与词之间的语义相似度进行特征降维。也有一些研究人员[ 3, 4]将知网[ 5]应用于中文文本表示降维研究。还有一些研究人员利用同义词词林进行同义词合并[ 6],实现特征降维。以上的研究对象主要是新闻稿和社会科学领域的文档,利用常识知识库可以有效完成文本特征降维任务。但是,自然科学领域的科技文献会涉及到大量的领域词汇,这些词汇大都没有被常识知识库收录,仅利用这些常识知识库对科技文献进行相关的特征降维研究,效果并不是很好。
本文提出一种利用N-gram算法获取领域词库,结合《知网》进行相似度计算,达到对科技文献关键词进行特征降维的目的。
(1)相同意义的词汇写法多样,如算法和方法,原理和定理,选择、选取和筛选,量和值等,这些词都可以利用常识性词典如《知网》或WordNet通过语义计算后达到无损特征降维。
(2)对于科技文献,很多专业词汇是几个一般词汇的组合,组合在一起表达一个完整的意义。这些专业词汇是某个领域的专用词,没有必要再进行切分,但这些词在常识性知识库中并没有收录,所以直接利用常识性词典进行语义计算不能完全解决实际问题。
(3)有些领域词汇没有规范写法,一个意义的表示方法可能有几种,这几种都有可能用在关键词中,如“因特网”、“互联网”和“Internet”等。也有一些是简写和正式写法混用,如“自然语言处理”和“NLP”、“词频”和“TF”、“倒排文档频”和“IDF”等。这些关键词出现的频率几乎不相上下,在利用词频的方法进行特征选择时,两者都有可能被选入,错认为是两个独立的特征项,造成关键词向量的冗余。这些词合并后都可以无损地进行特征降维。但这些词在常识性词典中没有收录,直接利用常识性词典不能完全解决相似问题。
为解决关键词标引中出现的问题,国家标准GB/T 7713.1-2006[ 7](学位论文编写规则)中要求每篇论文应“选取3-8个词作为关键词”,“尽量用词表提供的规范词”。许多期刊要求按照标准进行关键词的标引。但随着信息技术的飞速发展,词表不能及时跟上飞跃发展的科学技术,难以满足各专业的要求。为此,一些研究人员提出了提高关键词标引质量的方法:马开俊[ 8]提出“有控制的关键词标引”,谭慧华[ 9]提出“论文作者标引与专业标引人员标引相结合的方法”;郭淑敏[ 10]提出利用辅助词表来提高关键词标引的质量。赵宗蔚[ 11]提出采用自然语言与人工语言结合的后控制词表来提高期刊论文关键词标引质量等。
针对由于关键词标引不当造成的冗余问题,本文提出一种新的关键词冗余解决办法。主要思想为:根据关键词冗余问题的特点,对己有的语义特征降维方法进行改进。在分析词与词之间的语义相似度时加入了提取领域词的过程;先进行简写和正式写法的合并,然后利用N-gram过滤算法构建领域词库。在计算词与词之间的语义相似度时,领域词作为整体来考虑,最后将计算所得的同义词加到同义词词典中,并且将这些同义词在向量空间中合并,实现关键词向量的特征降维。
利用Java语言实现所提出的方法。实验部分下载自CNKI某一领域文献关键词。利用本文所提出的方法进行领域词库的构建。对原有关键词进行分词,区分为领域词和非领域词,并对这两种词分别进行计算。关键词之间的语义相似度是几个部分相似度的加权结果,计算结果大于一定阈值,则认为是表达同一意义的同义词。将这些同义词分别放到同义词词典中,并且在原有的向量空间中合并,以达到利用特征降维方法消除冗余关键词的目标。
通过在同义词词典中加入领域术语简写和正式写法的同义词项,实现对这些意义相同的领域术语简写和正式写法的合并。针对领域术语的特点,选择具体的N-gram候选词条的长度范围,按照过滤效果为不同长度的候选词设置不同的阈值,大于阈值的词被选入领域词库。根据本文建立的领域词库将关键词分为不同的组,同一个组的关键词之间进行对比,组与组之间不再进行对比。在组内进行对比过程中,首先利用领域词库将关键词切分为三个部分:领域前缀、领域词和领域后缀,然后分别计算两两关键词之间领域前缀部分和领域后缀部分的相似度,综合得出关键词之间的相似度。给定一个阈值,将大于阈值的这些词视为同义词,选取其中一个作为标准词,其余放入同义词典,达到特征降维的目的。
同义词词典最初存放的是领域术语的简写和正式写法的同义词对照表。计算后所得的同义词也存入该词典中,为后续研究使用。同义词词典格式为每个同义词集合各占一行,最后一个为标准写法。同义词之间用固定分隔号分隔。本文使用的同义词合并算法流程如图1所示:
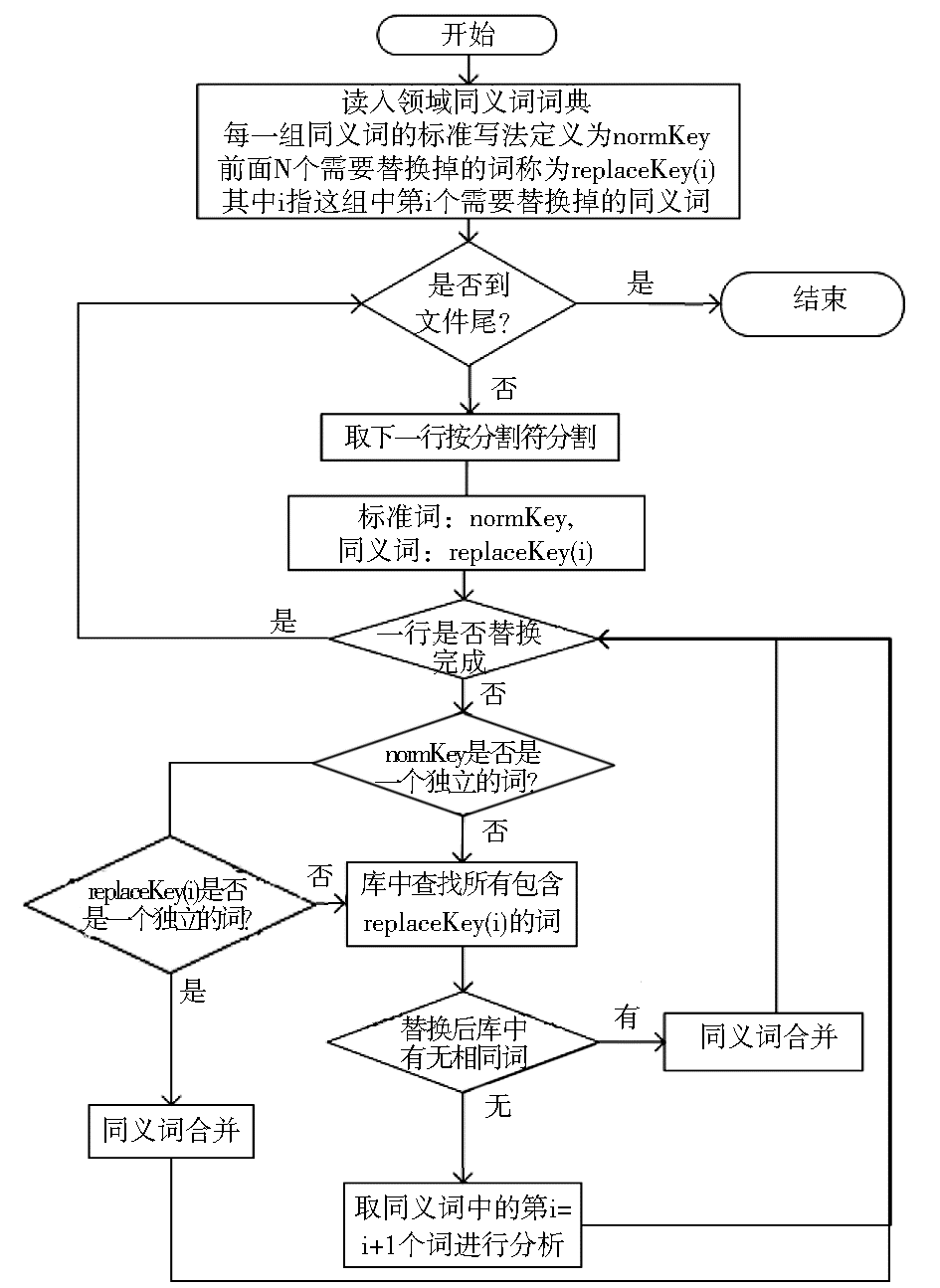 | 图1 同义词合并算法流程 |
N-gram是应用很广的统计语言模型,在语音识别[ 12]、机器翻译[ 13]、手写识别[ 14]、拼音输入[ 15]、信息检索[ 16]、分词和词性标注[ 17]等许多领域都有应用。本文利用N-gram算法确定领域词库。将关键词切分为2-gram, 3-gram,…,n-gram,具体最大值n的确定视领域术语的特点而定。利用过滤算法考察这些N-gram成为领域词汇的可能性,最终确定领域词库。领域词库生成算法如下:
输入:作者所给的关键词列表AK
输出:领域词库
中间参数:N-gram片断中最大的词长为n,对于每个N-gram列表,粗过滤词频值为αn ,利用N-gram列表进一步过滤子串的参数为βn
①对作者所给的关键词列表AK进行N-gram切分;
②将长度相同的N-gram 切分词组成一个列表,把这个列表中频率值小于αn的词过滤掉,形成n-1个N-gram列表(分别为2-gram,3-gram,…,n-gram列表);
③对于每一个列表,取每个候选词的词频θ;
④分别取候选词子串中的每个词及词频θ';
⑤如果θ'-θ<βn 时,在子串中过滤掉该词。如图2所示,当每一个候选词和候选子串中对应的词的比较阈值βn都定义为3时,“支持向量机”,“支持向量”和“向量”被作为领域词,其他子串被过滤掉;
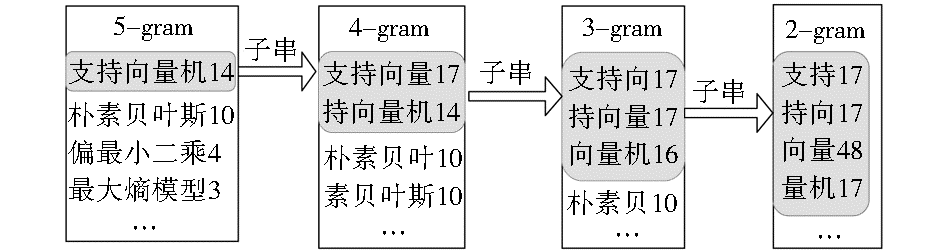 | 图2 N-gram词串以及每个词对应子串 |
⑥将N-gram列表中没有执行过滤操作的词选作领域词汇。
利用领域词库对关键词进行切词;利用一般分词程序对非领域词部分进行重新切分;切词后,将词表示为三个部分,分别为领域前缀、领域词和领域后缀。领域前缀指其他词位于领域词的左边,领域后缀指其他词位于领域词的右边。
如:“树状贝叶斯方法”和“树形贝叶斯理论”二个关键词分别切分为:
树状贝叶斯方法= 树状 + 贝叶斯 + 方法
树形贝叶斯理论= 树形 + 贝叶斯 + 理论
作者所给关键词= 领域前缀 + 领域词 + 领域后缀
利用知网计算非领域词的语义相似度:设关键词W1经过切分后为三个部分W1l 、W1f 、W1r,关键词W2经过切分后为三个部分W2l、 W2f、W2r,其中W1f 和W2f 分别对应领域词。领域词和领域词相比较,领域前缀和领域前缀相比较,领域后缀和领域后缀相比较。前缀和后缀的比较利用常识库的相似度计算方法进行。只有当领域词相同时,才进行比较;领域词不相同时,认为是相似度很小的词,没有必要再进行前后缀的比较。本文提出用来计算两个关键词的语义相似度公式如下:
S(W1,W2)=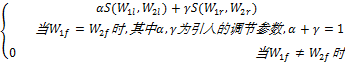
所给定的关键词没有必要一一对比,只有当分词后领域词一致时,这两个关键词才有可比性。计算每个领域词包含前后缀的相似矩阵,然后利用所给的相似性公式计算词与词之间的语义相似度,将语义相似度大于一定阈值的关键词视为同义词,将这些同义词存放到同义词词典中,以备计算时用。将这些同义词合并,完成特征降维过程。
特征降维的具体实现算法如下:
输入:作者所给的关键词列表AK
输出:降维以后的关键词列表
中间辅助变量: 每个领域词对应一个相似矩阵,这个矩阵中存放所有与本领域词相关的前后缀的语义相似度值。在关键词列表AK中为每个关键词设删除标志位。
①利用相似矩阵,分别计算两个关键词对应的前后缀的相似度,再利用本文所提出的语义相似度计算方法加权计算整个相似度,最终所有关键词之间的语义相似度存放到N×(N-1)维的二维数组中,其中每一行数据存放某个关键词与其他N-1个关键词的语义相似度;
②给定一个循环变量i,初始赋i=1;
③判断i值是否大于N,如果是,执行第⑧步操作,否则取第i个关键词的删除标志位以及在二维数组中的第i行数据;
④判断这个关键词删除标志位是否为1,如果是,说明这个词己被认定为其他词的同义词,没有必要进一步对比,取下一个关键词i=i+1,返回第③步,否则往下执行;
⑤在对应的N-1维数组中取语义相似度大于阈值δ的所有关键词Keyj,执行以下操作;
⑥关键词Keyj存放到同义词词典中,并定义为Keyi的同义词;
⑦在关键词列表AK中设置关键词Keyj的删除标志位为1,取下一个关键词i=i+1,返回第③步;
⑧将AK列表中没有设为删除标志的关键词放到降维以后的关键词列表中,实现关键词的降维操作。
本文实验在32位的Windows 7系统平台下进行,利用Java语言实现关键词向量的冗余处理。通过Lucene建立索引和进行N-gram统计[ 18, 19],利用imdict-chinese-analyzer[ 20]进行非领域词分词,参照文献[21]设计非领域词的相似性对比计算,领域词之间相互独立,不再进行对比。
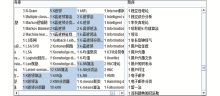
实验数据从CNKI选取1 113篇主题词为“文本分类”的研究论文,从题录信息中提取作者给定的关键词1 731个。选中部分是与“K近邻”有关的关键词,前面的数字表示共有多少篇文章用到了这个关键词,可以看出作者给定的关键词的冗余程度之大,如图3所示:
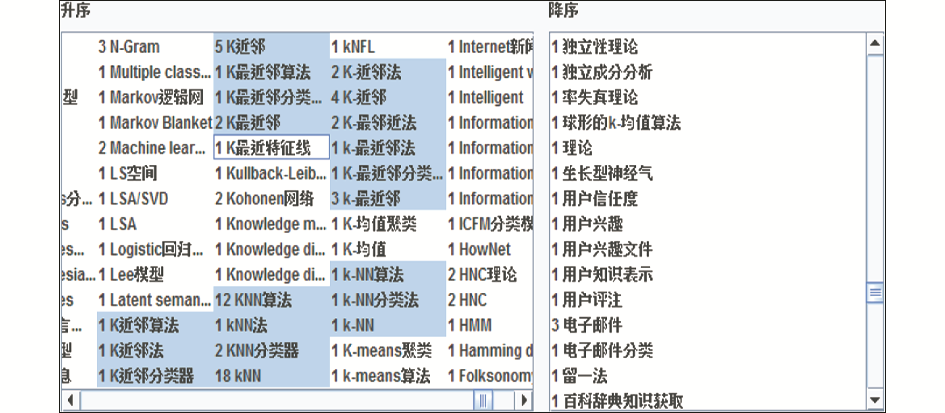 | 图3 作者给定的部分关键词 |
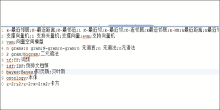
通过查看作者给定的关键词,将简写的领域同义词手工提取出来,生成同义词词典,图4所示是本文最初生成的领域同义词词典的一部分,同义词之间以分号分隔。
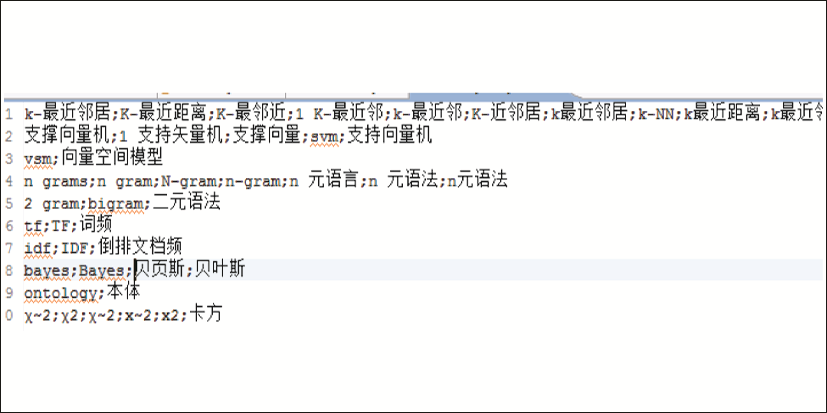 | 图4 领域同义词词典 |
利用本文提出的方法进行领域同义词合并,上面选中部分可以合并为:K近邻法、K近邻算法、K近邻分类器和K近邻4个关键词,进一步的合并需要后续的相似性计算。
利用N-gram算法提取领域词共129个,包括支持向量机、散度、本体、朴素贝叶斯、模糊、潜在语义、特征、K近邻、矢量、神经网络、贝叶斯、降维、隶属度和领域等。同时需要根据实际情况对这些计算得来的领域词汇进行细微调整。
利用生成的领域词库以及知网知识库,按照式(1)计算相似度,利用提取流程识别同义词集合,并进行特征提取。对给定的1 731个关键词进行降维后,最终关键词为1 491个,压缩比为13.9%。
本文的创新之处在于针对关键词冗余问题,在分析词与词之间的语义相似度时加入了利用N-gram算法提取领域词的过程;分词时领域词作为一个整体来对待,分词后每个关键词分为领域词部分和非领域词部分,如果领域词不相同,两个词不再对比;如果领域词相同,再进行非领域词部分语义相似度计算。利用这一改进的方法进行关键词的特征降维处理,有效地解决了关键词的冗余问题。并且和没有加入领域词库的相似性计算方法相比,减少了内存的使用量以及词与词之间对比计算的次数。不足之处在于:N-gram统计生成领域词汇时会出现一些垃圾词汇,需要手动去除;相似度计算公式还需要改进;程序还需要进一步优化,进一步改进词库存放格式和相似性对比的过程。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|