
{kind=link}
{kind=link}
{kind=link}
一种集成客户终身价值与协同过滤的推荐方法
[张慧颖1 , 薛福亮1, 2  ]
]
]
|
|


提出一种加权RFM与协同过滤相结合的集成推荐方法,对由“Web数据挖掘”隐式收集的客户评价数据进行协同过滤处理,应用加权RFM对相似用户聚类结果加以改进,从而更有效地发现推荐规则,提高推荐质量。同时应用产品分类树(PT)对产品进行预处理,以减少计算空间的复杂度。实验评价结果表明该方法无论在推荐精度还是推荐相关性上都更为有效。
In this paper, an integrated recommender method which employs weighted RFM and CF method is presented. Firstly,CF is applied to customer ratings on products, which are collected implicitly by Web usage mining approach,then weighted RFM is applied to improve similar user clustering to find recommend rule effectively and generate better quality recommendations. Product Taxonomy (PT) is also used to preprocess products according to their categories and to reduce dimensions of computational space. Evaluation results show that the proposed method is more effective both in the accuracy and relevance of recommendations.
推荐系统通过对用户历史交易记录及用户评价信息的处理,发现用户购物偏好并向潜在客户推荐产品。国内外的推荐系统,依据其采用的核心技术可以分为基于内容的推荐和协同过滤推荐[ 1]。其中协同过滤(Collaborative Filtering,CF)是较为成功的一种推荐系统,这种系统首先依据用户的历史评分记录对相似用户进行聚类,然后依据相似用户的购买行为向目标用户进行推荐。
越多越多的研究关注如何将客户终身价值(Customer Lifetime Value,CLV)应用到推荐系统中[ 2, 3],研究表明CF中应用CLV能够发现许多更有效的规则,从而提高推荐质量。本文基于某在线零售商城提出一种集成CF与RMF的推荐方法以提高推荐精确度。用RFM矩阵以及用户偏好评分矩阵来计算用户相似性,前者具有相似的客户终身价值,后者具有相似的购买偏好,并依据权值形成最终相似用户聚类簇,然后在相似用户聚类簇内鉴定客户的最积极和最消极邻居实施推荐。实际的网购环境中为更好地关注客户因产品种类不同而引起的购买行为的变化,引入产品分类树(Product Taxonomy,PT)理论,依据市场环境、竞争对手情况及不同产品类的相对重要性对产品进行种子类预设。该方法能够对企业具有战略优势的产品进行客户定位,使推荐更具有针对性,同时能够缩减产品空间维度,降低了因产品种类繁多而引起的计算复杂度,保证了推荐的效率。
主流的推荐技术有三种:基于内容的推荐,协同过滤推荐,混合推荐[ 4]。基于内容的推荐通过匹配用户与商品的特征的一致性进行推荐,用户的特征通过分析用户所购买的商品的特征得到。协同过滤推荐通过分析用户对商品信息的评价信息以发现用户兴趣的相似性,从而对具有相似购买兴趣的用户进行交叉推荐。相比来说协同过滤是目前非常成熟的一种方法,如果用户对项目的评价非常完整,其推荐精度是非常准确的。而现实生活中因为数据的稀疏或者因为新产品没有足够的评价数据,会产生稀疏性以及冷启动问题,同时因为用户相似性的比较需要大量的计算,随着系统的规模扩大,计算复杂度呈几何级增长。针对以上问题,国内外学者提出了很多解决方法,较为典型的方法有采用奇异值分解技术来缩减稀疏评价矩阵的维度,以消除评价矩阵的稀疏性[ 5],但这种方法会丢失有价值的数据,降低推荐质量。聚类分析是降低算法复杂度的有效方法,自组织地图(Self-Organizing Map,SOM)和K-均值聚类方法是最为流行的两种[ 6]。K-均值算法应用一种迭代爬山算法在一系列聚类簇中寻找最优分割点,因其简单易用而被广泛采用,Kim[ 6]提出利用K-均值聚类以降低算法复杂度,提高推荐效率,但该方法未考虑数据稀疏的处理。有学者提出利用Web数据挖掘提取客户日志,以进行个性化推荐[ 7],这种方法挖掘了用户的隐性评价数据,但未考虑与显性评价数据的结合。利用混合算法(基于内容与协同过滤相结合)实现两种推荐算法的互补以提高推荐质量[ 8]是一种不错的方法,但两种算法的集成一直是困扰其推荐质量提高的瓶颈。Liu等[ 2, 3]及 Albadvi等[ 9]对利用客户终身价值与产品评分相结合的协同过滤推荐方法,并取得了较好的效果,但这种方法未考虑隐性评价数据的重要性及算法的复杂性问题。Devi等[ 10]提出应用神经网络进行产品评价值预测以消除稀疏性问题,该方法同样只处理显性评价数据,忽略了隐性评价数据。Cho等[ 11]提出协同过滤推荐技术同产品分类树结合,可以获取更精确的近邻聚类,同时也缩减了评分数据的维度。Hung[ 12]提出并实现了一种基于聚类技术和产品分类树的电子商务推荐技术,对产品分类树进行了修改,从而对那些品牌敏感的客户进行区分,聚类分析同产品分类树的结合有效降低了算法复杂度。
总结前人的研究成果,本文提出利用服务器日志进行Web数据挖掘来获取隐性的用户评价数据以消除稀疏性,服务器日志数据挖掘主要有两个阶段:数据预处理和用户行为模式发现[ 7]。针对传统方法采用奇异值分解法,利用主成分分析法进行维度的缩减以降低计算复杂度,但存在有价值数据丢失问题。本文提出采用产品分类树缩减产品的空间维度以降低计算复杂度。产品分类树依据营销经理或者领域专家提供的专业知识进行产品分类,有效地定位企业的优势产品,提高推荐的准确性,同时有效降低计算复杂度,提高推荐效率。在此基础上,进一步提出集成客户终身价值和Web数据挖掘得到的评分数据进行相似客户聚类,得到具有相同购买兴趣的相似客户聚类簇,客户终身价值(CLV) 是指一个顾客在与公司保持关系的整个期间内所产生的现金流经过折现后的累积和[ 2]。CLV可以发现更有价值的客户,是分析客户流失、客户利润和客户关系管理的重要指标,结合CLV推荐能够定位优势客户,增加了客户的黏性,同时使推荐更具有针对性。本文提出的核心思想如图1所示:
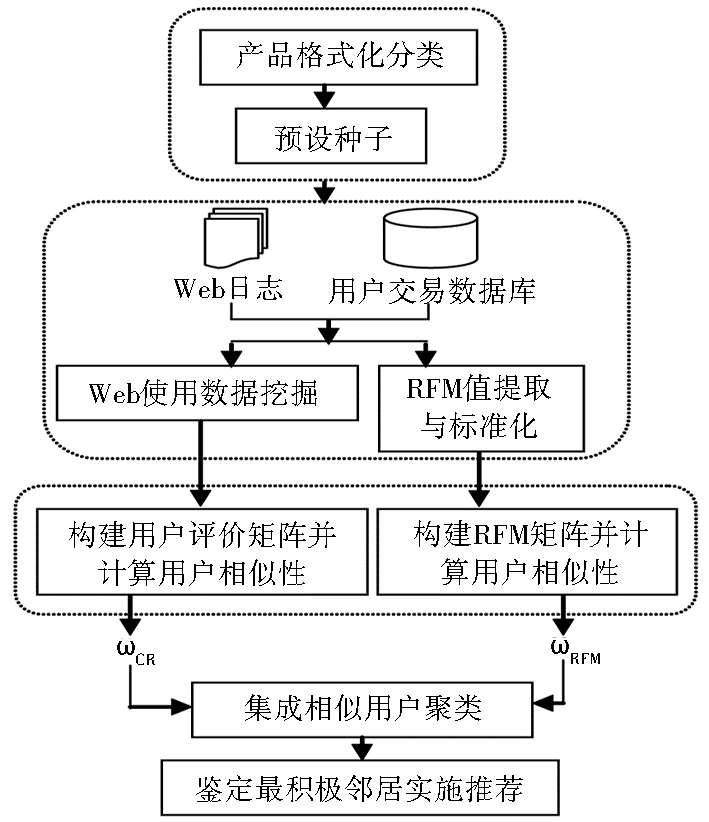 | 图1 推荐算法框架 |
CLV集成CF推荐算法共分为5个阶段,各阶段功能为:
(1)产品分类树生成及种子预设。
(2)基于Web操作日志及客户交易数据库进行Web数据挖掘,获取用户评价数据,同时进行用户RFM值提取并进行标准化处理。
(3)基于用户评价数据构建用户评价矩阵,并进行用户相似性(CorrCR)计算,基于标准化后的RFM值构建RFM矩阵,并进行用户相似性(CorrRFM)计算。
(4)基于两种矩阵得到的用户相似性CorrCR和CorrRFM,依据各自权重进行相似用户聚类,得到相似用户聚类簇。
(5)在同一用户聚类簇内,鉴定最积极和最消极邻居并实施推荐。
产品分类树可以将较低层次的产品归属到较高层次的产品类中去,其叶子节点通常表示一种具体的库存产品,若干个同一类型的叶子节点组成其上层的非叶子节点类[ 9]。图2为某网络零售商的产品分类树。科幻小说和言情小说被分类到故事类,而故事类和烹饪类丛书则归属于书籍类。此分类树中面霜类和皮肤护理类对其所属上层的护肤品类来说较为重要,所以细分为面霜类和皮肤护理类。虽可以继续将香水类分为面部香水、身体香水等分类,但相对来说进一步细分对其上层类已没那么重要,所以直接将香水类产品直接归属到更高层的化妆品类,而未继续细分。
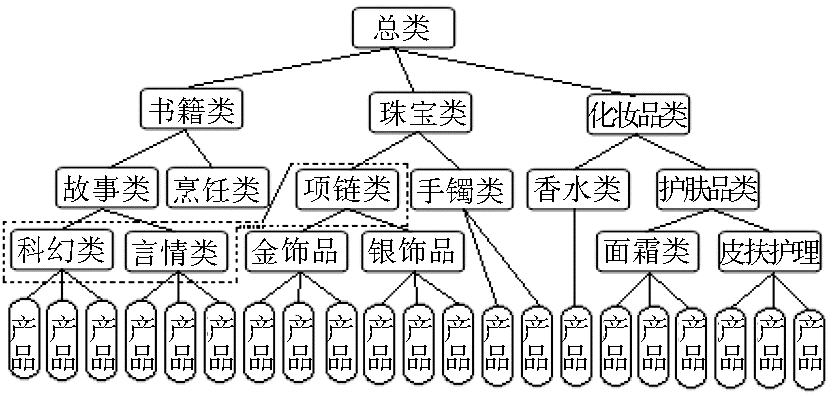 | 图2 某零售商产品分类树 |
通过对市场环境、竞争对手情况和不同产品类的相对重要性以及风险分析,市场经理和领域专家选取产品分类树中的一些节点(或产品类)作为“种子”[ 9, 11],如图2中虚线部分所示。“种子”的预设是下一步工作的基础。在“种子”内进行相似用户的聚类,可有效地缩减产品维度空间,降低计算复杂性,同时依据“种子”对客户进行细分,提高了推荐的针对性。本文中“种子”的定义如下:“种子”是产品分类树中的节点的集合[ 12],是产品分类树的子集,对任一个从叶子节点到根节点的路径中,只有一个属于该路径的节点属于该子集。若产品或产品的上层类属于“种子”,该产品称为种子产品,该产品类称为种子类。对于一个给定的种子G,任意产品其对应的种子类CategoryG(p)定义如下[ 12]:
CategoryG(p)= 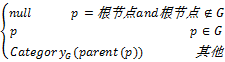
其中,parent(p)指产品p的父节点,图2所示的产品树中科幻类和言情类是种子类,其下产品为种子产品。在实际的购物环境中用户的需求是多变的而且难以预测,不同类别产品用户的购物偏好也会有所不同,因此用户的相似性计算、用户聚类,将会分别在每个种子类内完成。
用户对产品的评价值和用户RFM指标值两类数据会被从服务器Web日志、用户交易数据库中提取,经过进一步处理后,被用来进行种子类内的用户相似性计算。
Web数据挖掘是为了获取客户对产品的隐性评价值,依据Cho等的研究[ 11],客户对产品的评价可以通过对顾客行为模式的分析获得,如下:
(1)点击:客户点击网页产品的超链接。
(2)放入购物车:客户将产品置入购物车。
(3)交易完成:客户购买产品,完成购物交易。
基于以上行为,所有的产品可以被归为以下4类中的一类:购买的产品、置入购物车的产品、点击浏览的产品、其他产品。获取用户-产品隐性评价值步骤如下:
(1)将产品映射为标识符
分析网站产品结构,将产品用唯一的URL来标识。本文网站中产品数据库用如下形式表示:
[A,1253,2,23.3,李峰,… ]
其中,A是每一行开始的标识符,接下来的序号表示产品ID,后面依次是“价格”,“作者”…等不同产品特征的描述。以[1253,1254,…]这样的集合ID序列来表示,这为后面的数据分析提供了很大的方便。
(2)解析访问路径
数据处理的主要目标是把原始的日志数据转换为向量数据。本文实验的网站用户原始访问日志格式如下:
[C,#10001,*V,1038,#时间#,*V,1026,#时间#,*V,1034,#时间#,…]
每个用户由一个序号表示,如:#10001。“C”代表一个新客户的访问记录开始,“*V”表示这个用户访问的一个产品。其中“1038”表示产品标识,“#时间#”表示当时访问时间。数据处理的目标是抽象出每个用户的访问路径,存储在一个向量中。比如对于#10001用户,可以用[1038,1026,1034]这样的向量来表示其访问路径,以访问的时间先后顺序排列产品。
(3)删除访问路径中短时间内的重复节点
在解析出的路径中,经常出现短时间内连续多次访问同一个产品的情况,这可能是由于用户端的Cache机制等所造成的,所以需要删除短时间内重复的节点。
根据筛选规则,得到的一条处理后的某用户访问向量,其格式如下:
[10003,1064,1065,1028,1007,1064,1026,1052,1064,1028]
对向量处理得到ID为10003的用户对ID为1064的产品总访问点击次数为3,对ID为1028的产品总访问点击次数为2,其他依次类推,用c 
置入购物车日志与用户访问日志类似,在此不再赘述。用户i对产品j置入购物车次数用c 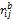
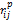
对用户原始操作日志进行数据挖掘,获取用户i对产品j的总点击次数、置入购物车次数和购买次数,分别用c 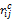
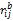

crij=ωc× 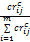


其中,crij为标准化后的c 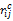
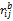

客户终身价值通过RFM(最近购买时间,购买频率,购买金额)三个指标来进行度量[ 3, 9]。
(1)最近购买时间(R):最后一次交易至今的时间,该值越低表明客户再次购买的可能性越高。
(2)购买频率(F):单位时间周期内发生交易的次数,该值越高表明客户忠诚度越好。
(3)购买金额(M):单位时间周期内发生的货币交易总额,该值越高表明该客户应给予更多的关注。
用户交易的RFM指标数据将会用来计算顾客终身价值,此处通过服务器Web日志以及用户交易数据库分别提取用户的最近购买时间、购买频率、购买金额三个指标数据的原始记录。购买频率(F)和购买商品价值(M)与客户忠诚度和客户生命周期价值正相关,应用如下公式进行两个指标的归一化处理:
Xg'=(Xg- 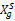

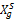
最近购买时间(R)与客户终身价值负相关,应用如下公式进行该指标的归一化处理:
Xg'=( 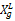
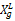
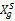
Xg' 和Xg分别表示g内所有客户的归一化后和初始R、F、M值,RFM指标值的获取与处理过程在此不再赘述。
依据三种用户行为模式产生用户的评分矩阵。假定有M个用户构成用户集{ui|i=1,2,…,M},N个不同产品构成产品集{pi|i=1,2,…,N},依据得到的评价值crij可得到一个[M*N]矩阵,包含第i个用户对第j个项目的评价。基于此用户-产品评分矩阵,用户对某个种子类g内产品的偏好相似性可以通过Pearson相关系数[ 4]计算得到,如下:
Cor 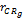

其中, 
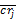
假定有M个用户,依据Xg'(g内所有客户归一化后的R、F、M值),可以得到一个[M*3]RFM矩阵。包含M个用户归一化后的R、F、M值。种子类g内的客户终身价值相似性可以由Pearson相关系数[ 4]基于归一化的客户RFM矩阵计算,如下所示:
Cor 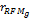
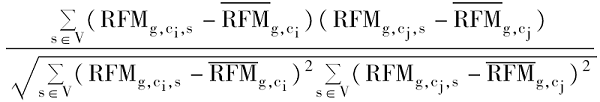

基于每个种子类用户偏好相似性(Cor 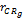
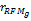
Cor 
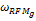
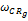
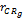
其中, 
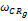
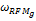

用户登录商城,基于其浏览、购物等操作产生商品评分。基于其评分,推荐系统开始工作。算法如下:
输入:活动用户对项目评分,T代表待评分的项目,rik表示评分值,N表示项目的数量,t表示用户i和用户j都已评过分的项目, 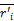
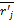
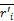
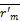
输出:该用户的推荐。
特殊功能:
①如果用户没有任何历史评分记录(冷启动问题),用户所在聚类簇的Top T项目将会向该用户推荐。
②如果用户已有历史评分记录,将利用Pearson相关系数[ 4]鉴定该用户正相关邻居和负相关邻居:
simi,j= 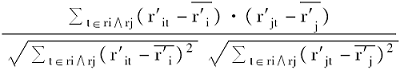
③利用预测函数预测用户未评分项目的预测评分值。基于用户相似性选取k个最相似用户,并计算预测值作为加权平均偏差,本文提出预测公式如下:
Pui= 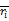
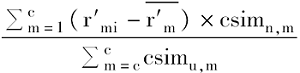
④对相关用户执行步骤③。
⑤正相关邻居的推荐项目预测集合赋值到集合X,负相关邻居的推荐项目预测集合赋值到集合Y。计算Z=X-Y,集合X包含基于相似性得到的项目,集合Y包含基于非相似性得到的项目。将集合Z作为推荐项目。
⑥推荐Top T项目给用户。
本文采用互联网上的某零售网站公开日志信息进行推荐质量的评价,数据库采用SQL Server 2008。依据专家建议,将产品构架为一个4层的产品分类树,种子类有三个分别为:珠宝类(包含4个节点),化妆品类(包含4个节点),书籍类(包含144个具体产品)。Web日志信息通过服务器IIS获得,删除因Cache机制造成的重复访问操作记录以及代理服务器(Proxy)造成的多个用户的重叠访问记录,共得到278 884条有效记录。选取2006.1-2009.4用户访问数据作为训练集,选取2009.5-2010.3用户访问数据作为测试集,训练集和测试集比重为[80%,20%]。目标用户选择在训练阶段和测试阶段都至少有一次交易记录的用户。在训练集数据空间内通过数据整理、用户识别、会话识别、路径分析方法等对日志信息进行处理,得到用户-产品评价矩阵与RFM指标。依据评价矩阵与RFM指标计算用户偏好相似性(Cor 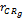
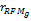

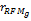
通常精确率(Precision)和召回率(Recall)两个指标被用来度量推荐质量:精确率是推荐的项目除以总推荐项目;召回率是推荐的相关项目除以总相关项目(应当检索到的)[ 6],计算公式如下:
Precision= 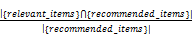
Recall= 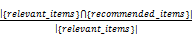
由于精确率和召回率一定程度上是一对相互矛盾的指标,精确率高就意味着召回率低,采用综合指标平衡两者,综合评价指标也称为 F1 指标(F-measure)[ 4]。F1 指标值越大,推荐质量越高,计算公式如下:
F-measure= 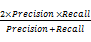
三个指标分别在每一个聚类簇内单独计算,取其均值作为推荐质量高低的依据。
为得到一个合适的权重 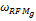
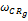
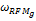
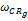
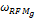
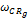
| 表1 种子类内权重组合取值对F1指标的影响比较 |
在珠宝类中N=10, 
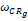
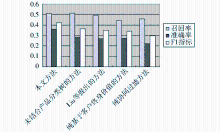
依据上述参数调整在训练集内获得最佳推荐质量后,通过实验在测试集内与其他推荐方法进行比较,如图3所示:
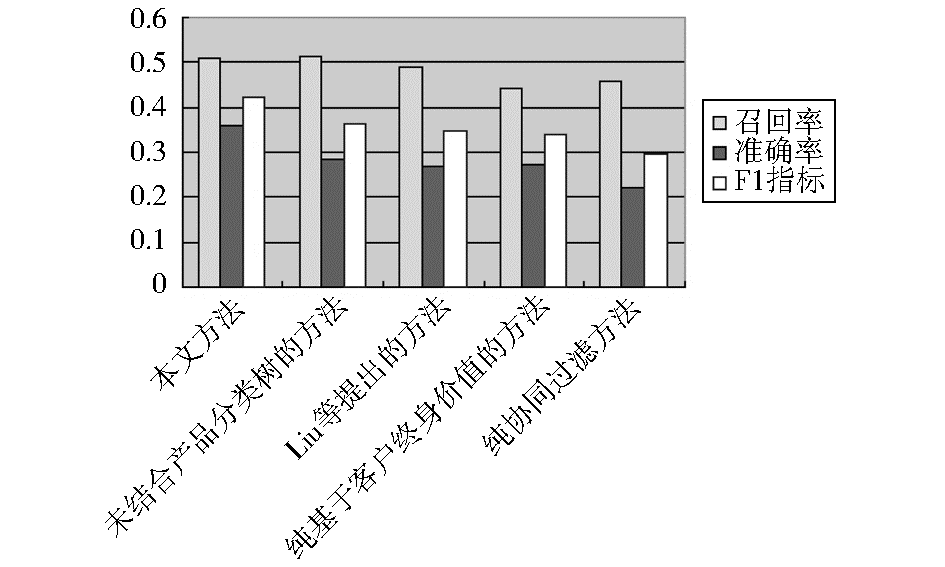 | 图3 不同推荐方法推荐质量比较 |
说明:
(1)在未结合产品分类树的方法中,通过将珠宝类、化装品类、书籍类整合为一个产品类,以测试产品分类树对推荐质量的影响。
(2)Liu等[ 3]提出的方法集成层次分析法、协同过滤以及关联规则挖掘实施推荐。
(3)纯基于客户终身价值的方法中,取ωRFM=1。
(4)纯协同过滤的方法中,取ωCR=1。
实验结果表明,本文提出的方法在推荐质量上要优于其他推荐方法,应用产品分类树进行种子类预设能有效提高推荐准确率。集成客户终身价值与客户偏好聚类推荐要优于纯协同过滤或者纯基于客户终身价值的方法。
本文将协同过滤、客户终身价值、RFM方法、产品分类树以及Web数据挖掘和三种用户行为模式进行整合,提出了一种新型的推荐方法。该方法基于产品分类树整合协同过滤与客户终身价值提出了更精确的推荐规则。实验结果表明该系统的推荐质量优于其他类似的推荐系统,如纯协同过滤或纯RFM方法。种子类、K(聚类的数量)、N(推荐产品的数量)以及ωRFM、ωCR的相对值是该方法对推荐质量影响最大的几个指标。以上几个指标中,种子类和K值由市场经理及领域专家界定。实验主要考虑的实验指标包括N、 ωRFM、ωCR。由于购物环境的多样性,系统的精度可通过长时间的运行调节改善,同时依据市场专家和系统分析师的建议可以定义更精确的参数值来改进推荐质量。下一步,将利用多个电子商务站点数据集来评价系统。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|