科技文献全文主题识别方法实证研究
[叶春蕾1, 2, 3  , 冷伏海
, 冷伏海1 ]
, 冷伏海|
|


利用基于多词短语词频分析和短语邻近分析的DT方法,结合学科领域术语识别内容,对美国国家航空航天局2011-2020年战略规划做全文主题识别。实验证明,改进的DT方法可以有效地识别全文文献主题,一定程度上能够简化情报研究人员的工作。
This paper proposes an improved DT method to identify the theme of the NASA 2011-2020 strategic plan based on multi-word phrases frequency analysis and phrases proximity analysis, adding the term identification of subject. Experiment proves that the improved DT method can identify the theme of documentation in full-text effectively and simply the work of intelligences to some extent.
科学技术文献是科学技术发展过程中知识的主要载体,是科学技术发展过程的累积形态,其中蕴含着大量揭示学科发展演化的主题信息,对科学技术文献中蕴含的学科主题进行识别是情报人员的主要研究内容之一。主题及主题之间的关系都隐含在大量的文本数据库中,为了从中高效地发现并汲取有用的信息,情报研究人员围绕科技文献的内、外部特征,研究并实践了多种文献计量分析方法,包括利用科技文献的引文数据开展的同被引分析、引文耦合分析等进行文献主题识别[ 1]和共词分析方法[ 2]。基于共词分析方法的主题识别大多是采用科技文献数据库标引的主题词进行共现聚类识别[ 3]。由于诸如科技规划、科技项目申请和描述、科研项目评估材料等科学技术文献缺少引文数据、主题词等信息,因此,以上两种方法很难获得蕴含在科技文献文本中的主题内容。
DT(Database Tomography)是Kostoff等[ 4]于20世纪90年代初提出的一种面向全文数据库的共词分析方法,并申请了美国专利。该方法基于这样的假设:科技文献中出现频次高的短语表征一个主题,而与该高频短语在一定的时间窗口内同时出现的共词短语将会和高频短语产生主题关系。此后,Kostoff等[ 5, 6, 7, 8]将DT方法成功地应用于多个领域,并提出将文献的其他特征信息,如作者、期刊、机构或引文分析也引入DT研究方法中[ 9]。由于受美国专利的保护,DT方法主要被以Kostoff为首的美国海军研究总署(Office of Naval Research, ONR)团队研究和使用。2005 年,Kostoff等[ 10]获得了“基于文献的知识发现方法”专利授权。该专利整合了DT方法和其他文献计量分析方法,提出基于文献的知识发现方法(Literature-Based Discovery,LBD),自此,DT方法只是作为基于文献的知识发现方法一部分,较少被单独提及。
国内对DT方法的研究还不够充分,冯璐等[ 11]将DT视为“新一代”的共词分析方法,但并没有对其进行深层次的讨论。赵凡等[ 12]对DT方法做了综述性的介绍,但更多应用细节没有明确地阐明。冷伏海等[ 2]介绍了DT方法,但仅是将其作为一种共词分析方法做了简单的介绍。王立学等[ 13]提出基于文本结构解析的DT方法,尝试对DT方法进行改进,但是由于诸如规划这类自由文本结构存在很大的差异,因此在使用中缺乏一定的灵活性。
本文在DT分析方法基础上,基于多词短语分析结合学科领域术语识别算法,能够让更多低频主题词参与到短语邻近分析的主题识别过程中,以获得全文本数据库中更隐含的主题内容。实验选择科学研究成果最常用的表现形式——PDF文件作为实验数据源,使用改进的DT方法识别其中的主题内容,验证了使用改进的DT方法进行全文本文献主题识别的意义。
DT方法是定性和定量相结合的极具特色的共词分析方法,它不依赖于任何科学文献的外在形态,如叙词、关键词、作者关键词、引文等,完全面向文献内容。该方法利用一定的算法从大量文本材料中进行数据抽取、数据聚类。其中包括两个重要的算法:多词短语频次分析(Multi-word Phrases Frequency Analysis)和短语邻近分析(Phrases Proximity Analysis)。
多词短语是由一个或多个单词组成的具有一定主题特征的短语,可以是两词短语、三词短语或更多单词组成的短语。虽然Kostoff等提出DT方法并将其成功应用于各领域,但是对于如何在自由文本中进行多词短语的抽取,很少直接说明具体抽取的方式,只能通过研究报告中给出的一些数据结合说明文字进行推断[ 9]。因此,本文采用如下的多词短语抽取方式:
假设文本流中单词序列表示为:W={w1,w2,…, wN},其中wi是第i个单词,N是文本中所有单词个数,那么抽取的两词短语集合2-terms= 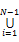
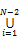
本文采用以上抽取方法完成全文本数据中的多词短语抽取工作,并在此基础上进行频次统计,以此识别具有一定主题特征的核心短语和共现短语。
短语邻近分析是在确定 DT 方法的共现范围(时间窗口)后,对每一个核心短语获得与其在指定时间窗口中共现的短语,并对其进行分析。Kostoff等通过实验证明,将DT方法的共现窗口设为50更有利于主题分析。本文沿用该经验值,定位到核心短语在文本中第一次出现的位置,以核心短语为起点分别向前、向后取25 个单词,从中抽取不同的短语形式,加以记录和累加。以此获得与核心短语共现的共现短语,通过短语邻近分析算法获取每一个核心短语的共现短语列表之后,对每个共现短语i计算其与核心短语j的等价指数(Eij)和两个包容指数:共现短语的包容指数(Ii)和核心短语的包容指数(Ij),分别定义为[ 14, 15]:
Eij=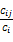
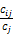
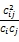 (1)
(1)
Ii=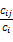
Ij=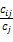
其中,Cij是核心短语和共现短语在50个短语的时间窗口内共现的次数,Ci是共现短语在整个文献中出现的次数,即共现短语词频,Cj是核心短语在整个文献中出现的次数,也即核心短语词频,Ii是共现短语的包容指数,Ij是核心短语的包容指数。
数值指标是度量共现短语与核心短语的关联强度,如果一个共现短语的数值指标高,则意味着它极有可能与核心短语一起共同表征一个主题。DT方法中采用计算每个共现短语与核心短语的包容指数(Ii、Ij)和等价指数(Eij)共同确定该共现短语的数值指标。Eij 的值越大,表明两个短语共同出现的次数占其各自出现总次数的比例越大,其联系可能就越密切;Ij和Ii的值越大,表明共现短语与核心短语共现的次数占其总出现次数的比例越大,有助于保留那些绝对出现频次低但与核心短语共现次数多的词语。
根据上文所定义的多词短语抽取方法,将一篇40多页图文等信息并存的PDF文件经过停用词过滤分析将获得3 000多个不同的单词短语、11 000多个不同的两词短语、13 000多个不同的三词短语以及15 000多个不同的四词短语(这里的四词短语只是为了计算它所包容短语的C-value值,因此不具有主题统计意义)。从Kostoff等的多项研究中可以看出,在传统的DT方法中,仅以短语频次进行核心主题词的筛选。如果只从频次角度进行筛选,最终入选为核心短语的必将多数为单词短语和两词短语。
本文将用到的实验材料通过NacTem开发的TerMine术语抽取工具进行验证[ 16],发现更多候选术语是两词以上的多词短语,没有单词作为术语而被识别。TerMine是一种常用的术语抽取工具,它将与领域无关的C-value算法和NacTeM开发的AcroMine术语缩写识别系统融合在一起,从英文文本中抽取候选术语,且更主要是抽取多词术语[ 17]。因此本文借用TerMine方法,将C-value算法引入多词短语词频分析过程中,计算两词以上短语的C-value值,为后续的研究提供可靠的指标值。
C-value 是一种领域独立的多词术语识别方法,其综合了语言学和统计的信息,并着重强调统计部分[ 18]。它是针对术语词频计算的一种改进,可增进嵌套多词术语的识别,排除了一些非术语的词汇。在C-value算法中,如果一个字符串经常在长的多词术语中出现而很少单独存在,那么这个字符串有可能频率很高但却不是术语;如果一个字符串经常在多个长的多词术语中出现,那么此字符串有可能是术语;如果一个长字符串和短字符串拥有相同的词频,那么长字符串更有可能是术语。基于以上的考虑,C-value的计算需要获取以下参数:
(1)侯选字符串在整个数据集中的频次;
(2)候选字符串被其他长的侯选术语包含的频次;
(3)包含该侯选字符串的侯选术语的数目;
(4)候选字符串的长度(即候选字符串的单词个数)。
C-value的计算公式如下[ 18]:
C-value=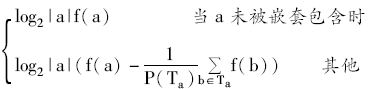
其中,a表示候选字符串,|a|表示字符串长度(按单词数计算),f(a)表示候选字符串a的词频;Ta表示包含候选字符串a的候选术语,P(Ta)表示包含候选字符串a的术语总数;b表示包含a的字符串。
本实验采用美国国家航空航天局2011-2020年战略规划“516579main_NASA2011StrategicPlan.pdf”全文文件[ 19]作为数据源。将该PDF文件转换为纯文本TXT文件,保留了大部分PDF中大多数的文本内容。
首先对文本文件中的英文内容进行切词,由于实验不仅需要词性标注,而且需要记录每个词在文献中的位置,以便进行后续的实验,因此笔者使用C语言自编软件进行处理。对切出的单词做简单的处理,如单复数处理,并用停用词表对其过滤,统计所有保留的单词短语词频,用词频进行排序。
根据上文所定义的多词短语抽取方法获得两词短语、三词短语和四词短语序列,并为其建立双向链表,链表包括短语词频以及该短语在文献中的位置等信息,可以按词频对它们进行排序。
除此之外,本实验利用式(4)分别计算每个多词短语C-value值,并保存在链表的对应位置中。由于本文所定义的C-value值不能作为唯一的主题识别指标,后续的短语邻近分析中所提供的等价指数和包容指数也是主题识别的重要指标,因此将每个短语的C-value值保存到短语链表中,部分数据如表1所示:
| 表1 带C-value值的多词短语链表(部分数据) |
可以看出,虽然C-value值也是基于短语词频的,但它考虑的参数较多,特别是包含该短语字符串的更长的字符串出现的频率和嵌套数量,所以使用C-value值进行术语识别可以将更多的低频多词短语突显出来,而这些短语具有很强的主题特征,因此可以使用C-value值作为主题词筛选的第一项指标。
由于两词短语和三词短语都是由单词短语扩展产生,通过实验可知,由高频词的单词短语所扩展的两词短语、三词短语的频次也较高,因此本实验的核心短语从单词短语列表中产生,核心短语的确定主要采用词频统计定量分析和专家定性分析相结合的方法。其中词频作为核心短语筛选的量化标准,如果一个单词短语在全文本文献中出现的频率高很可能就是该文献的核心短语。将频率相对高的短语序列呈送给学科领域专家进行定性筛选,对一些频次较高、但是不具备主题特征的短语进行排除,专家意见作为核心短语筛选的定性标准。如“NASA”的频次达到259,但该词对于文献中的学科主题识别帮助不大,属于噪声数据;又如“ISS”,虽然频次只有41,但是主题特征比较明显,入选为核心短语。最后确定该规划中的20个单词短语作为核心短语,并分别以其作为主题名。
本实验短语邻近窗口设为50,也就是将与核心短语前后距离为25个短语范围内出现的单词短语、两词短语、三词短语作为核心短语的共现短语,同时计算每个共现短语与核心短语的等价指数和包容指数。例如,在对核心短语“space”做短语邻近分析中共获得10 450个共现短语,如此庞大的共现短语中存在大量的噪声数据,影响主题特征和内容的有效识别,因此采用如下的识别算法:
(1)单词短语:按词频进行排序,满足阈值的单词短语作为核心短语的共现短语;
(2)两词短语和三词短语:
①按C-value值进行排序,满足阈值的多词短语作为核心短语的候选共现短语;
②按等价指数Eij进行排序,由式(1)和式(2)可知,等价指数高的共现短语和该核心短语的关联性较强,满足阈值的多词短语作为核心短语的候选共现短语;
③由式(3)可知,Ii和Ij表明共现短语和核心短语之间的关联强度,因此对Ii和Ij联合排序,满足阈值的多词短语作为核心短语的候选共现短语。
表2中列出对核心短语“space”使用改进DT方法前后所分别获得的属于同一主题的共现短语。
| 表2 改进DT方法与传统DT方法的结果对比 |
从表2可以得到:
(1)从所列出的Top20短语看出,更多的多词短语(包括两词短语和三词短语)属于学科领域术语,而由于其在文献中频次较低,因此该短语的等价指数也会较小,在传统的DT方法中会因为等价指数的阈值限制而被筛除。表面上看,使用改进DT方法识别的共现短语等价指数相对较小,但其主题特征更明显,满足主题识别的需求。
(2)与空间相关的内容是空间考察、空间飞行、空间站、空间技术等,其中近地轨道(Low earth orbit)是空间技术中的重要技术,在规划原文中提到近地轨道的安全飞行是战略目标之一。在传统的DT方法中没有作为主题的一项重要内容突显出来,而在改进DT方法中,虽然它的等价指数并不高,却跃居第6的位置。
(3)在规划原文中提到国际空间站(ISS)的维护与运行是其战略目标之一,因此ISS也是空间主题中的重要内容。在改进DT方法中,该主题内容在Top20的位置更靠前一些,显示其重要的主题特征。
通过阅读原文可知,本实验所识别的空间主题内容基本上涵盖了文献中的相关主题内容。
实验表明,在进行科技文献自由文本全文主题识别时,改进的DT方法在短语频次分析阶段加入术语识别算法,能够让更多低频的主题词参与到短语邻近分析的主题识别过程中,在简化情报研究人员通过阅读文献以获得科技文献全文主题内容的同时,让研究人员获得精确的主题信息。但是本文只是做了初步的尝试,方法的有效性还需要在更多领域进行实验,通过逐步地改进和修正得以不断完善,因此还需要在后续工作中开展进一步的研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|