网络日志中查询串语义关系挖掘及其应用研究
[段建勇 , 徐骥超, 张梅]
, 徐骥超, 张梅]
, 徐骥超, 张梅]
|
|


通过挖掘网络日志中的查询词语义关系,将《知网》的语义知识加入到聚类算法中实现搜索引擎优化。该方法通过机器学习算法深入挖掘查询日志,对其中的查询串进行概念相似度、语义聚类等计算,使返回网页更加合理,将更准确的网页结果呈现在用户面前,能够更好地满足用户需求。
By mining semantic relation between Web log query terms, this paper puts the HowNet semantic knowledge into clustering algorithm to achieve search engine optimization.In order to understand user needs better, the method uses machine learning algorithms to analyze query log deeply,and puts query items into the depth of analysis.The paper makes the back page more reasonable and presents more accurate Web results to the users.
随着现代信息检索系统的快速发展,关于搜索引擎的性能优化方法不断出现,搜索引擎是在网上查找信息的工具,并服务于万维网用户,其服务的内容是协助用户在万维网上查找信息,因此其数据对象是全体万维网数据。从具体运行方式上说,系统根据站点/网页的URL信息和网页之间的链接关系,利用网络蜘蛛在网上收集数据;收集的数据分别通过链接信息分析器和文本信息分析器处理,保存在链接结果信息库和文本索引信息库中,因此数据量大是搜索引擎必须关注的一个关键问题。用户查询返回的结果是数以万计的,不进行合理的查询结果的优化与排序很难满足用户的个人需求,无法提高引擎的商业价值。
随着搜索引擎技术的不断发展,关于它的优化技术也是领域中的研究热点,其中包括关键词优化、URL优化、META优化和链接流行度优化。本文的主要工作是利用查询词对URL进行优化分析,通过引入《知网》的语义知识计算查询词之间的语义相似度,从而对网页进行权重的优化,使得相似度大的查询词对应的网页权重提升。
典型的网络日志格式由如下几部分组成:用户ID;用户查询串;用户选择的URL;用户点击URL的Rank值;用户提交查询的时间。表1展示了网络日志的格式。
| 表1 网络日志格式 |
目前,挖掘网络日志是搜索引擎优化的主流方法。挖掘的具体内容包括网络日志中的查询语句、点击信息与推荐排名。挖掘方法包括挖掘网络日志的序列模式、查询词间语义分析以及网络链接结构分析等。挖掘网络日志的序列模式,一般采用聚类的方式[ 1],例如首先将查询串进行聚类,并使用GSP(Generalized Sequential Patterns)算法获得每个聚类的序列模式,然后对每个网页进行评分。查询词之间语义关系挖掘方法主要采用查询语句与点击信息相结合的方法,通过抽取在查询日志中提交的查询之间的关系来进行推荐查询,研发了一个有效的双层查询推荐模型,建立了关系矩阵,计算各个查询的潜在语义[ 2, 3]。该方法缺少语言方面的深入理解。网络链接结构分析方法中比较流行的有基于PageRank的排序方法来优化搜索引擎[ 4, 5, 6, 7, 8]。主要考虑域名、内容、关键词、链接结构等因素对于网站在搜索结果中的排序影响,改善网站在搜索引擎中的结果排名。
大部分国内外研究人员都是从用户点击的历史、查询词与查询词关系、以及网站自身的结构入手对搜索引擎结果进行优化,主要从网络日志本身进行挖掘,很少引入外部语义知识。本文从查询词与查询词之间的语义关系入手,引入《知网》的语义知识,对用户输入的查询词进行语义计算,从而改善搜索引擎结果中网页的排序。
一般分为基于查询内容关键词、基于用户反馈来计算查询词相似度。
(1)基于内容关键词相似度公式如下:
Sim1(p,q)=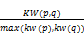
其中,kw(p), kw(q)分别是各自查询串中关键词的数量,KW(p,q)是两个查询串公共的关键词数量。
(2)基于用户反馈的相似度公式如下:
Sim2(p,q)=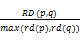
其中,rd(p),rd(q)分别是查询相关文档的数量,RD(p,q)是二者公共点击的文档数量。
将任意两个查询串分词,并依次进行基于查询内容关键词、基于用户反馈的相似度计算,如文献[1]中将公式(1)、(2)两部分按照一定权重进行加权,形成公式(3):
Sim(p,q)=αSim1(p,q)+βSim2(p,q) (3)
其中,α,β分别是基于内容与基于用户反馈对关键词影响的重要程度,一般分别取0.5。
在文献[1]中的查询词相似度计算仅对查询词的内容以及用户反馈两个方面进行相似度计算,没有进行深层次的语义层面上的理解,没有考虑到查询串之间的语义关系,这样会造成两个字面上完全不相同的词相似度很低,甚至为0,但实际上两者存在某种语义上的关联关系,例如:电脑和计算机、手机和移动电话。为此,本文引入《知网》的外部知识来描述语义关系。
《知网》是一个以词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库,其中每个概念都由许多义原组成。义原在层次树中越靠近根节点越抽象,描述的语义信息量越粗略;越靠近层次树的底部的叶子节点,描述的信息越详细、具体。根据《知网》语义树形结构中各个节点的距离来计算语义相似度,在文献[9]和[10]中定义了语义相似度计算公式,如公式(4)所示,其中不仅考虑了两个节点距离对相似度的影响,也将节点之间的公共路径、深度差因素考虑其中。
知网大部分由实词组成,而实词概念的语义表达式,将其分成三个部分:
(1)独立义原描述式:将两个概念的这一部分的相似度记为Sim1(p1,p2);
(2)关系义原描述式:语义表达式中所有的用符号义原描述式,将两个概念这一部分的相似度记为Sim2(p1,p2);
(3)符号义原描述式:语义表达式中所有的符号义原描述式,将两个概念的这一部分的相似度记为Sim3(p1,p2);
于是,两个概念语义表达式的整体相似度为:
Sim(C1,C2)=β1Sim1(p1,p2)+ β2Sim2(p1,p2)+β3Sim3(p1,p2) (4)
本文引入《知网》中的概念相似度计算,对网络查询日志的查询串两两进行相似度计算,使得相似度大的查询串聚集在一起,形成聚类簇指导用户查询优化,当用户输入新的查询串,选择与聚类簇中相似度高的网页权重进行改善。最后将网页权重大的网页推荐给用户。
本文提出融合《知网》的词汇语义相似度来计算查询串之间的相似度,挖掘词汇中深层次的语义关系,通过公式(4)概念相似度的方法来计算两个查询串相似度。首先对查询串进行分词处理,得到若干个查询词语,找到两个查询串之间的词语对应关系,再计算查询串之间的语义相似度。按照如下算法:
(1)计算两个集合中的所有元素之间的语义相似度。
(2)从所有的相似度值中选择最大的一个,将该相似度值对应的两个元素对应起来。
(3)从所有的相似度值中删除那些已经建立对应关系的元素的相似度值。
(4)重复上述步骤(2)-步骤(3),直到所有的相似度值都被删除。
(5)没有建立起对应关系的元素与空元素对应(与空值的相似度可以用一个很小的数来表示δ)。
得到两个查询串各个部分之间的相似度后,将各个部分加起来获得两个查询串的相似度,如公式(5)所示:
Sim(p,q)= 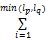
其中,lp,lq分别是p,q查询串分词后的词汇数量,Sim(pi,qi)是第i个对应的词之间的相似度,δ为一个词与空值的相似度,作为平滑系数,其取值很小。
对用户已经提交的查询串进行聚类,在某种程度上同一聚类簇中的各个查询串存在某种关系,借此可以判断出用户更倾向哪些网页,并提高权重,更大限度地满足用户查询需求。对文献[1]中的提到的查询词聚类算法进行了改进,加入了公式(6)引进的语义成分,算法思想如下:
Query_Clustering(Q, α,β1, β2, β3,δ,λ)
//输入: Q是已经分词后的查询串,α是一个可调节的参数,表示重合度对相似度影响的大小,β1,β2,β3是各个义原对相似度的权重,δ为一个词与空值的相似度,λ为相似阈值。
//输出:查询词的聚类集合
k=0;
For(each query p in Q)
Set isCluster(p)=false;//设置每个查询串都未被聚类
For(each p∈Q and isCluster(p)=false)
{
isCluster(p)=true;
Classk={p};
For(each q∈Q and isCluster(q)=false)
{
sim=CalculateSimilarity(p,q)//按照公式(5)的查询词相似度方法计算
If(sim>=λ)then
Classk=Classk∪{q};
Else
Continue;
}end of inner for;
k++;
}end of outer for;
Return set of query Cluster
为了避免聚类盲目性,提高准确度,需要从聚类好的查询日志的查询串中抽取出能代表整个簇类的查询特征作为聚类中心,以便后续对用户查询串进行聚类分析。抽取特征词的原则是提取其中最能代表簇的词汇,去掉频度比较低的词汇,因为其不能体现整个簇的一般性。
本文引入Apriori算法来挖掘聚类中心的特征词。网络日志的查询串有些时候虽然不存在字面上的匹配关系,但有时候在语义层面上具有一定关联性,而Apriori算法只是字面上的扫描数据库中的字符串,可能会忽略词汇间的语义关系。因此这里对文献[11]中Apriori算法进行了改进,加入基于《知网》的词汇相似度的语义成份,便于聚类语义上关联的词汇,适应本文的挖掘特征词需求。改进后的算法伪代码如下:
Modify_Apriori (Q,α,λ)
//输入: Q是某一个聚类集合中已经分词后的词汇,α是基于《知网》的词汇相似度的阈值,λ为支持度
//输出: n频繁项集
k=1;
Canditems={{}};
Freqitems={{}};
GetOneCanditems(Canditems)//获得1候选集
CalculateSimilartyForItem(Freqitems, Canditems, k)//根据基于《知网》的相似度计算统计K候选集计数并返回大于阈值的K频繁项集
Loop:
k++;
Cross_Join(Freqitems, Canditems,k)//由k频繁项集交叉连接生成k+1候选集
CalculateSimilartyForItem(Freqitems, Canditems, k)
If(Freqitems[k]==null)exit
end//end of Loop
return Freqitems
在文献[12]中对Sogou网络日志进行了深入的分析,得出高达70%多的查询串只有2-3个点击的网页,因而不需要大量更新返回页面的权重便能提升查询的准确度。本文将查询串的语义相似度加入到少量的网页中,以提升权重。当用户输入查询串时,首先进行分词然后对其进行索引检索。对用户输入的查询串与网络日志的各个聚类中心进行比较,对相似度较高的查询串,应该是潜在用户要查找的网页,需要给出一个额外的相似度值Simq来提升网页X的Rank(X)值。对网页进行Rank修改,提高排名,如公式(6)所示:
New_Rank=Rank(X)+Simq (6)
为了展示语义相关的查询词相似度对搜索引擎返回结果排序的实际影响效果,对Sogou查询日志中的数据进行实验,实验样本数据如表2所示。
(1)对以上数据按照查询串聚类算法进行聚类,α,β1, β2, β3,δ,λ分别设置1.60,0.50,0.20,0.17,0.01,0.4。得到的聚类结果为C1(网络电视免费,无线电视,电影下载,网上影院票价),C2(山寨手机,经典手机短信,手机主题下载,移动设备),C3(汶川地震原因,地震起因,救援地点,地震现场),C4(智慧辅助软件,计算机发展,华军软件,电脑性能)。
| 表2 网络日志样本数据 |
(2)对C1,C2,C3,C4,C5中的簇进行特征词的提取,C1(网络,电视,电影),C2(手机,经典,主题),C3(地震,起因,现场),C4(软件,计算机,电脑)。
(3)对用户输入的查询串进行分词,并将其与提取好的C1,C2,C3,C4进行相似度计算,将其归类到相似度最高的簇中,并赋予簇中每个网页权值。
例如:当用户输入查询串“网上电影观看”时,首先借助搜索引擎下载所有的返回结果页面。计算查询串与C1,C2,C3,C4相似度大小,计算结果后将其归入到C1类中。接下来计算C1中查询串与用户输入串之间的词汇相似度。
Sim(上网,网络)= 0.149333,Sim(上网,电视)= 0.126316,Sim(上网,免费)= 0.042904
Sim(电影,网络)= 0.166667,Sim(电影,电视)= 0.266667,Sim(电影,免费)= 0.044444
Sim(观看,网络)= 0.074074,Sim(观看,电视)= 0.044444,Sim(观看,免费)= 0.044444
从中选取相似度最大的类簇进行对应,结果生成以下词汇对:电影-电视、网上-网络、观看-免费。
Sim= Sim(电影,电视)+ Sim(上网,网络)+ Sim(观看,免费)= 0.460444
对包含C1中查询词的返回结果页面进行编号分别为:A,B,C,D;其中Rank_a,Rank_b,Rank_c,Rank_d分别为基于PAGE_RANK算法的结果,融合相似度值后更新的A,B,C,D网页RANK值如表3所示:
| 表3 更新网页Rank值 |
从表3中的数据可以看出,A、B、C、D的权值得到了修改,而其他簇中网页的权值并没有修改,保持原来Rank算法所得到的Rank值。而Rank算法都是基于网页链接结构而计算出来的,本实验通过网络日志的聚类分析对基于链接结构而计算出来的Rank进行修改,提升返回结果页面的排名,可以更好地理解用户查询意图,用户输入“上网电影观看”时,显然希望得到C1中所对应的页面,C1中所对应的网页更可能是用户所需要的,提升了其Rank值,在查询结果中提升了其顺序。
本文主要工作是提高搜索引擎返回结果的排序效果,使用户尽可能从排名靠前的返回结果中获得自己需求页面。该聚类算法结合了《知网》的语义相似度计算方法,可以挖掘深层次的词汇语义关系,使得字面上不相干的查询串在语义层面上得到更多得联系,更大限度地满足用户查询的潜在需求。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|