{kind=link}
{kind=link}
{kind=link}
{kind=link}
关联爆发主题模式挖掘方法研究综述*
引用本文
黄永文. 关联爆发主题模式挖掘方法研究综述* . 现代图书情报技术, 2012, 28(10): 28-34
Huang Yongwen. Review on Mining Methods of Correlated Bursty Topic Patterns. 现代图书情报技术, 2012, 28(10): 28-34
Permissions
Huang Yongwen. Review on Mining Methods of Correlated Bursty Topic Patterns. 现代图书情报技术, 2012, 28(10): 28-34
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
关联爆发主题模式挖掘方法研究综述*
摘要
简要介绍关联爆发主题模式的含义,从探测与发现爆发主题、定位爆发主题的爆发时间段以及分析和挖掘出关联的爆发主题三个方面出发,研究关联爆发主题模式挖掘的关键问题。最后,对基于文档集、基于同步文本流、以及基于异步文本流的关联爆发主题挖掘的相关研究进展进行分析。
关键词:
关联爆发主题; 爆发探测; 主题模式挖掘
中图分类号:TP393
Review on Mining Methods of Correlated Bursty Topic Patterns
Abstract
This paper introduces the definition of correlated bursty topic patterns and studies the key issues of mining correlated bursty topic patterns such as detect bursty topics, locate bursty period of a bursty topic and discover correlated bursty topics.Finally, it analyzes the methods of mining correlated bursty topics from text collections, synchronous text streams and asynchronous text streams.
Keyword:
Correlated bursty topic; Bursty detection; Mining topic patterns
引言
随着互联网的飞速发展,信息提供与获取越来越方便,网络信息以惊人的速度不断增加,在同一时间段经常可以获得关于同一主题的多文本流。例如,Web上每天发布新事件的报道,搜索引擎返回给用户的信息,用户发布的博客文章,研究人员出版的科研论文,这些对关联爆发主题模式的探测和挖掘而言是新的机遇也是新的挑战。当一个重大事件发生或者新的研究热点出现时,由不同机构以不同语言报道该事件或研究热点的所有新闻将持续一段时间,在所有的文本流中就呈现出一种相关的爆发主题模式,通过探测和挖掘出文本流中的关联爆发主题,可以帮助用户及时理解和把握突发的新闻事件或新兴的科学研究主题热点。本文重点研究从单个或多个文本流中进行关联爆发主题模式探测的技术,分析国内外关联爆发主题挖掘方法的研究进展。
1 关联爆发主题模式的含义
爆发主要是指在很短的时间内频繁出现的数据特征,在一个数据流突发的区域,主要表现为在一定的时间间隔内,数据值超过预设的阈值[ 1]。Kleinberg[ 2]认为爆发是一种现象,表现为有关某个相同主题的文本流在短时期内大量出现。关联爆发主题模式是指文本流中同时爆发的一些相关的主题,具体表现在两个方面[ 3]:
(1)当发生重大事件时,在同一时间段里会出现不同机构以不同语言密集报道关于该事件的新闻。
(2)当在研究领域里出现一个新的研究方向时,在同一时间段里不同的研究团体在这个新的方向上会发表许多研究成果。
在关联爆发主题模式的探测中,文本流是指带有时间戳的在线和离线的数据,同步文本流指同一时间段出现的多个相关的文本流,异步文本流指不同时间段出现的多个相关的文本流。
2 关联爆发主题模式探测的关键问题
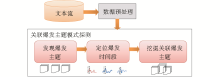
关联爆发主题模式探测的基本流程是:先分别从文本流里发现爆发主题,然后定位主题的爆发时间段,最后从发现的爆发主题中有效地分析出真正的关联主题。其流程图如图1所示:
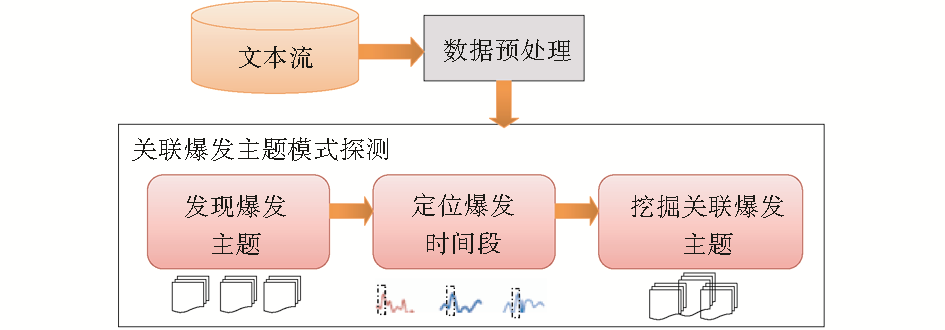 | 图1 关联爆发主题模式探测的基本流程 |
2.1 探测与发现爆发主题
爆发主题探测主要是通过识别爆发词或者爆发特征来发现爆发的主题热点或者突发事件,从文本流中抽取频繁出现的爆发词是探测新出现的主题或者主题发生变化的有效指标。在某个相对时段中具有高爆发度的术语为爆发词,可以根据爆发的相对时段、强度等来测度爆发词[ 4]。爆发词可以是关键词、术语或者命名实体,不同文本流中的爆发词可以是不同的形式,关于相同主题的爆发词之间在一定时间段中的词频分布会有很强的联系。目前,爆发主题探测方法主要有:基于状态机的爆发词探测方法、基于阈值的爆发词探测方法、基于实体识别的爆发主题探测方法、基于窗口的爆发特征探测方法等。
(1)Kleinberg提出的有限状态自动机模型(Infinite-State Automaton Model)[ 1]是最早的爆发词探测方法,其中爆发作为一种状态的自然转换现象被识别,通过在文本流中限定一个较小的时间间隔来观测包含某个词的文档的到达频率,识别超出平均到达频率的时间段及词的爆发强度,该方法适用于对文本流中的爆发词和其爆发时段的识别。关于爆发词识别方法的研究,大多是在Kleinberg提出的模型基础上开展的或者对其进行改善[ 5]。
(2)基于阈值的爆发词探测方法[ 1, 6]主要是应用阈值去发现爆发点。确定文档主题词最常用的方法是基于统计的方法,根据词频信息选出在文档中出现次数超过一定阈值的词作为主题词。基于阈值的爆发探测方法一般有一个共同的缺点,即需要依赖于数据阈值参数的调整。由于此方法很容易被实际数据中的一些噪声所影响,有时抽取的主题词汇并不能真正地反映文本主题。因此,一些学者提出利用位置加权、概念长度、概念类型、词间关系等,来衡量词汇对主题表达的贡献。
(3)近几年,出现了利用爆发实体来探测爆发主题的研究。在文本流中所提到的特定命名实体的突然增加,是与特定事件或者主题热点的发生相关的,因此通过命名实体的识别也可以探测出爆发主题。此外,时间相关的爆发实体还可以揭示不同的语言(或国家)中特定事件的表示形式。Kotov 等[ 7]提出从多文本流中挖掘爆发实体的两阶段方法,钱哲怡等[ 8]利用关键词和命名实体集合作为线索来结构化新闻事件。
(4)基于窗口的爆发特征探测方法[ 9, 10]主要是采用滑动的窗口和小波变换来探测和捕获爆发特征,数据流可以分解成离散的数据块,通过多个层级小波树变化,在从低层级到高层级变换中,爆发数据会最终落入到一个窗口中,从而捕获到爆发特征。虽然基于窗口的爆发检测方法可用于大规模数据流的情况,但是这种方法对跨多个数据流爆发识别不太适用,这是因为数据流被平滑后爆发的形状、时间段和爆发强度也被潜在扭曲了。
2.2 定位主题的爆发时间段
多文本流中的相关爆发主题在时间上经常存在着时间延迟和滞后的现象,因为不同国家的媒体开始关注同一事件的时间存在延迟,定位主题的爆发时间段主要是确定主题或相关爆发词集中出现的时间段。对于主题爆发的时间段,目前已经有一些学者开始研究。Krause等[ 11]提出阶乘HMM模型和指数秩序统计相结合的方法,以确定在不同的静态文本集合中主题爆发的时期。He等[ 12]提出在每一个时间点计算每个词的文档频次-逆文档频次(DFIDF),采用光谱分析来识别词的爆发和所有特征词的分布关系,进而从时间和文档频次两个方面分析词的演化轨迹。Wang 等[ 13]提出非马尔可夫连续时间模型,认为时间标签也是很重要的信息,通过主题分布将词汇和时间标签进行关联。
目前,在爆发主题探测中主要有两种常见的为时间数据建模的方法:
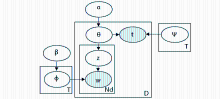
(1)为每个主题确定在时间轴上的概率分布,一个主题在某个时间点出现的概率高就表示该主题在这个时间点上出现爆发趋势[ 14]。时间变化主题模型(Topic Over Time, TOT)就采用该种建模方法。TOT的贝叶斯网络如图2所示:
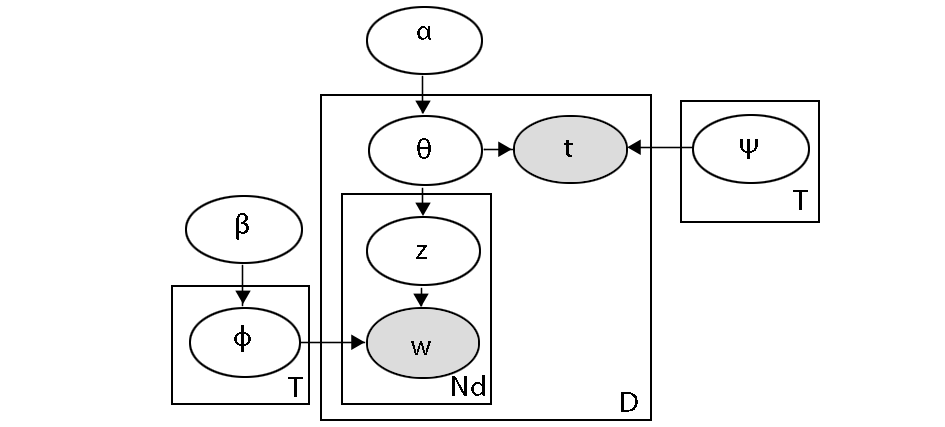 | 图2 TOT模型的贝叶斯网络[ 14] |
图2中随机变量w和t分别表示文本内容和文本发表时间。变量ф是在词汇库上的一个多项分布,表示主题(共T个),变量Ψ是一个在时间轴上的Beta分布(共T个),分别表示对应主题的冷热程度随时间的变化。通过参数估计,可以得到每个主题对应的Beta分布的参数。
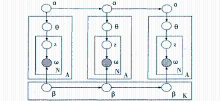
(2)将多个文本流按时间划分成段,对各时间段内文本分别进行主题模型训练,得出每个时间段内的主题。使用前后时间段的主题进行平滑以及对不同文本流之间的主题互加强进行爆发主题的探测。时间数据的作用主要体现在当前时间段内文本主题模型的参数受前一个时间段内文本主题模型训练结果的影响[ 3, 15]。动态主题模型(Dynamic Topic Model, DTM)就采用该种建模方法。DTM的贝叶斯网络如图3所示:
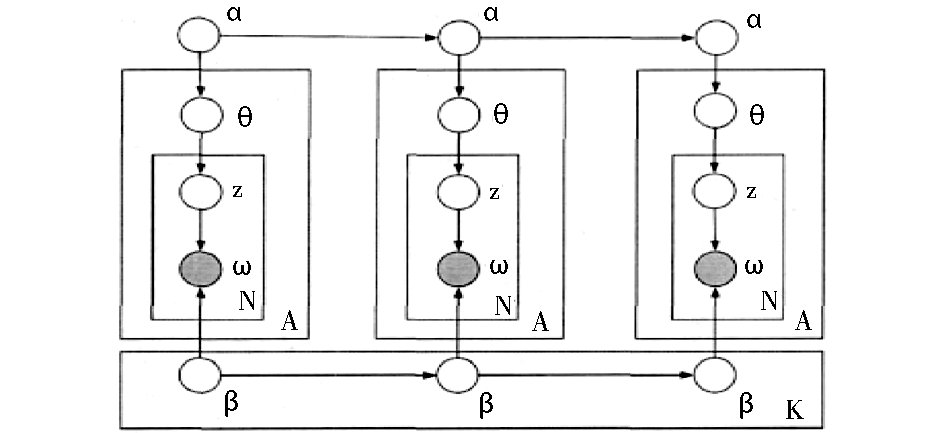 | 图3 DTM模型的贝叶斯网络[ 15] |
图3中是三个时间段的文本建模,和LDA模型的贝叶斯网络相比,可以看到DTM的贝叶斯网络近似于按照时间先后顺序训练了三个独立的LDA模型,不同之处是当前时间段内文本训练的主题模型的参数(α,β)受前一个时间段内文本的主题模型训练结果的影响。
2.3 分析和挖掘出关联的爆发主题
从发现的爆发主题中有效地分析出真正的关联主题是关联爆发主题模式探测的关键问题之一,通常采用识别关联的爆发词或利用主题模型来发现相互关联的爆发主题。对于多文本流,需要先从每个文本流中发现主题,然后跨文本流进行同一时段爆发主题的匹配。跨文本流进行主题匹配比较困难,因为不同文本流中的词汇不一定重叠。每个文本流中发现的主题可以描述相应的文本流,但不一定能在多个文本流之间匹配出共同相关的主题。当前应用较多的主题模型是LDA模型 (Latent Dirichlet Allocation)[ 16],不过LDA不适于为关联主题建模。为了解决这个问题,许多研究开始在LDA基础上进行扩展和改进,主要包括:
(1)采用关联主题模型(Correlated Topic Model,CTM)[ 17]以及在CTM上进行改进。CTM模型主要是把LDA模型中的先验概率由Dirichlet分布改为多维高斯分布,不过CTM模型只能挖掘主题间的两两相关性,为了挖掘多个主题之间的关系,Li等[ 18]提出在PAM模型(Pachinko Allocation Model)中引入超级主题的概念来挖掘多个主题之间的相关性,并提出可以自动调整超级主题和主题个数的改善模型[ 19]。Kim等[ 20]提出一个双向关联的非参数主题模型(DCNT),用来捕捉主题之间的相互关系,以及由元数据引起的文档潜在主题之间的相关性。
(2)采用动态主题模型(DTM)或时间变化动态主题模型(cDTM)[ 21],对主题强度在给定时间范围内的变化进行建模,将文本、词语和时间三者联合起来观测数据。Blei等[ 22]基于LDA 模型提出DTM模型,认为主题会随着时间变化,且满足一阶马尔可夫假设,主题概率分布参数以及主题中词项的概率分布随时间变化,且依赖于前一个时间片的状态。
(3)将主题模型和跨语言相互结合,如多语言LDA模型(MLLDA)。Ni等[ 23]针对Wikipedia提出一个MLLDA模型来从跨语言的语料中抽取主题,每一个主题都对应多种语言,不同语言的新文档都能够用统一的主题来表示。
3 关联爆发主题模式的挖掘方法
目前,已经有一些研究者针对不同类型的文本流,如静态的文档集、同步文本流、异步文本流,提出了不同的关联爆发主题模式的挖掘和探测方法,它们之间的比较如表1所示:
| 表1 不同类型数据的关联爆发主题模式探测的比较 |
3.1 基于文档集的关联爆发主题挖掘
关联爆发主题挖掘是以发现相关爆发主题为目的,挖掘出那些最能表达主题信息的爆发词或者爆发特征。早期的研究主要是在文档集上进行关联主题挖掘,很多研究在探测爆发特征时仅仅基于词频开展,而未考虑词语的上下文语义信息。目前,除了基于爆发词词频统计的挖掘方法之外,主要还有:基于文档空间主题结构的挖掘方法、基于语义信息的挖掘方法、词共现或命名实体分析方法等。
(1)基于文档空间主题结构的挖掘方法。基于爆发词词频统计方法的主题挖掘,对文档语料的篇幅有较大的依赖性,利用文档空间中的主题信息是提高主题挖掘的有效途径。挖掘文档空间主题结构通常采用文档聚类或词聚类的方式(如VSM),这些基于文档内容的聚类方法主要根据词汇的出现模式来判断文档之间、文档与词汇之间以及词汇之间的相关程度。有研究者提出爆发向量空间模型(Bursty Vector Space Models, BVSM)[ 12]来构建爆发主题的识别模型,并为文档中的每个词赋予爆发权重,是一种比较新颖的方法。
(2)基于语义信息的挖掘方法。一些爆发特征挖掘的研究中已经考虑文档集中不同主题之间的语义信息[ 24, 25],通过语言建模方法来构建爆发特征,利用上下文语义背景信息(如元数据频次、主题覆盖范围、用户吸引度等)来为爆发特征自动分配有意义的标签。
(3)词共现或命名实体共现的分析方法[ 7, 26]。词之间或命名实体之间的共现频率在某种程度上反映了它们之间的语义关联,可以通过共现的词或实体获取相同主题的爆发事件或研究热点。如果从不同语种的文本流中发现共现的爆发词或爆发实体,就可能将不同语种中语义上相关的爆发词或爆发实体聚集在一起,从而识别出潜在关联的事件或研究热点。
3.2 基于同步文本流的关联爆发主题的挖掘
目前,大多数研究主要关注于单文本流的主题挖掘,不同文本流之间的语义或时间上的潜在关系没有被挖掘出来。然而,Web上存在着大量多文本流,如新闻、博客、评论等,同一时间段出现的多个相关的文本流称之为“同步文本流”。从同步文本流中挖掘出相关的爆发主题模式,有助于进一步发现隐藏于这些文本流背后的潜在关系。多语种文本流中的相关实体,在不同国家中其爆发强度和幅度不同,例如在美国发生的事件,美国媒体报道的频率比俄罗斯、中国等国家要高。因此,采用词语被文本流提及的次数来监测爆发词可能会产生不准确的结果。针对多文本流,通常采用时间相关方法探索语义关联的主题,如基于相同时间戳假设的爆发监测方法、基于FHMM模型(Factorial Hidden Markov Model)的爆发监测方法等。
(1)基于相同时间戳假设的爆发监测方法
Wang等[ 3]假定数据流是同步的或协调的,从多文本流中发现相关的爆发模型和它们的爆发周期。基于这样的前提,将不同的数据流中具有相同时间戳的文本结合在一起,发现不同数据流中的主题词分布情况。针对多文本流提出了协调的概率混合模型,来识别爆发词以及它们的同步爆发时间段。并在新闻数据集和文献数据集上对该方法进行评测,实验显示所提出的方法可以从这两类数据中有效地发现有意义的话题模式。
(2)基于FHMM模型的爆发监测方法
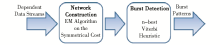
Sun等[ 27]提出基于FHMM模型的爆发探测方法,从多个相关的数据流中探测关联的爆发模式,提出根据时间的推移从多个数据流分析和识别相关爆发模式的新方法。采用动态概率网络来建模,模型主要依赖于数据流的结构,并进行了相关的数据实验,爆发模式挖掘主要包括两个步骤,如图4所示:
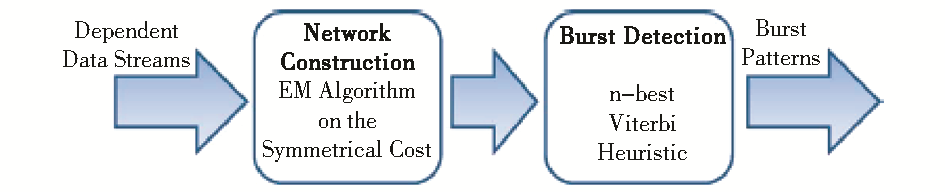 | 图4 基于FHMM进行爆发主题探测的主要步骤[ 27] |
①在网络构建中,预先设定相应的状态转换成本函数τ,通过期望-最大化(Expectation-Maximization,EM)算法,获得一阶马尔可夫依赖关系(Markov Dependencies)。
②在爆发探测过程中,使用观察到的因素和在网络构建中得到的依赖因素,应用Viterbi算法来估计隐藏状态序列。
与一般的基于状态的爆发模型方法相比,该方法允许更多的平衡和精确爆发量化。
3.3 基于异步文本流的关联爆发主题挖掘
同步文本流的关联爆发主题挖掘依据于不同文本流在时间上是同步的或者是协调的基本假设,这意味着不同文本流中共同主题的时间分布是一致的。不过,在现实中还存在着很多异步的文本流。例如,关于同一主题的研究论文或者新闻文章,发表在不同时期;对特定事件的报道可以有延迟。对于异步文本流,目前的挖掘方法主要有:基于MMPP模型的关联爆发主题挖掘、基于统一目标函数的关联爆发主题挖掘等。
(1)基于MMPP模型的关联爆发主题挖掘
针对异步文本流中挖掘关联爆发所面临的相关爆发幅度不同、相关爆发存在时间延迟等问题,Kotov 等[ 7]提出基于MMPP模型(Markov Modulated Poisson Process)挖掘相关爆发的方法来解决爆发时间滞后的问题。在挖掘的第一阶段,采用MMPP模型对文本流中个别实体的时间行为规范化建模,利用MMPP对原始数据流进行必要的抽象,确保个别实体的爆发幅度差异方法的鲁棒性,从而解决实体爆发幅度不同的问题。在第二个阶段,采用动态算法发现相关爆发实体,潜在爆发的时间可以由不规则的差距分隔组成。并对通过RSS Feed抓取的4个月数据进行了实验,挖掘出英语和俄语文本流中的关联爆发实体。这种MMPP方法要比主题模型的方法简单,但缺少与其他类似方法的比较。
(2)基于统一目标函数的关联爆发主题挖掘
异步文本流给传统的主题挖掘方法带来了新的挑战,如果采用传统的词频统计方法,会使主题词出现的频率相对太低,而无法发现爆发的主题。最直接的解决方案是采用文本流的时间戳粗粒度,理顺文本流之间的异步。不过,这样可能会带来一些问题,相同主题与不同主题的时间信息将不可避免地混合起来。针对这些问题,Wang等[ 28]提出概率框架的原则,在此基础上得出统一目标函数。然后,利用一个优化目标函数的算法来探索主题发现和时间同步之间的相互影响。核心思想是利用文本流之间的语义和时间相关性建立一个相互加强的过程,实现的基本思路是:
①使用原来的时间戳,假设当前文本流的时间戳是同步的,从给定的文本流中提取相同主题;
②基于这些抽取的主题和词汇分布情况,分别将它们调整和匹配到最相关的主题,更改所有文本流中文档的时间戳。
步骤②降低了文本流之间的异步情况,同步后再根据新的时间戳完善相同主题。这两个步骤反复交替,最大限度地实现统一的目标。
4 结语
本文从探测与发现爆发主题、定位爆发主题的爆发时间段以及从发现的爆发主题中有效地分析出真正的关联主题三个方面出发,研究关联爆发主题模式挖掘的关键问题,分析了基于文档集、基于同步文本流、以及基于异步文本流的关联爆发主题挖掘的方法。传统的主题探测方法大都是把文档集合看作一个完全静态的集合来处理,随着互联网的不断发展,文档开始以动态文本流的方式出现。在文本流中,每个文本除了内容特征外,时间因素也是一个重要的要素。如何在爆发主题模型中刻画出时间因素、如何从爆发主题模型的角度考虑同步或异步文本流的挖掘工作、以及如何进行关联爆发主题的探测,这些都是非常关键的问题。以前的研究主要在单一文本流中挖掘出爆发词和爆发主题,不能很好地探索和识别出不同文本流主题之间的潜在语义和时间关联,传统的方法不太适应多文本流中相关爆发主题的挖掘,如基于主题的探测方法可以发现反响重大的、长期的和非常有影响力的事件的一些主题,而忽略了在一些短时间小事件中爆发的相关术语或实体,因而需要结合基于实体识别的爆发主题探测方法。网络环境下出现的多文本流给关联爆发主题的挖掘和发现工作带来了挑战,同时也带来了新的契机,希望有更多的研究关注于新环境下关联爆发主题挖掘的更为有效的方法。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|