







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
汉语文本的最小递归语义表示研究*——以名词性量化短语为例
引用本文
曾少勤, 王惠临, 张寅生. 汉语文本的最小递归语义表示研究*——以名词性量化短语为例 . 现代图书情报技术, 2012, 28(10): 35-41
Zeng Shaoqin, Wang Huilin, Zhang Yinsheng. Mandarin Text Representation Based on Minimal Recursion Semantics——Illustrate by Quantitative Noun Phrases. 现代图书情报技术, 2012, 28(10): 35-41
Permissions
Zeng Shaoqin, Wang Huilin, Zhang Yinsheng. Mandarin Text Representation Based on Minimal Recursion Semantics——Illustrate by Quantitative Noun Phrases. 现代图书情报技术, 2012, 28(10): 35-41
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
汉语文本的最小递归语义表示研究*——以名词性量化短语为例
摘要
采用最小递归语义学(MRS)框架进行句子的语义表示。依照MRS的特色,以汉语名词性量化短语为例,设计一种合理的汉语MRS语义表示,并展示一种合乎HPSG理论的名词性量化短语句法分析方式。据此进行分析语法构建实验,结果显示,MRS形式框架基本适用于汉语名词性量化短语的语义表示。
关键词:
最小递归语义学; 文本意义表示; 自然语言理解与处理
中图分类号:TP391
Mandarin Text Representation Based on Minimal Recursion Semantics——Illustrate by Quantitative Noun Phrases
Abstract
This paper adopts a new framework named Minimal Recursion Semantics (MRS) to represent sentence meaning. Taking Chinese Quantitative Noun Phrases(QNP) as main analysis object according to MRS’s characteristics,the paper designs a suitable MRS representation for Chinese QNP and shows a reasonable HPSG analysis of QNP.It also implements a grammar analysis experiment, and the result shows the grammer is basically applicable to Chinese QNP representation.
Keyword:
MRS; Text meaning representation; NLP
1 引言
目前,针对文本的语义处理多集中于词汇层面(如本体、知网的研究),文本表示则多采用从平行语料或语义资源中获取翻译知识,进行空间映射,最终实现多语言文本关联的方式,其性能依赖于语料、语义资源的质量和规模[ 1]。基于这种现状,本文提出一种基于句子语义的、不依赖于平行语料的文本意义表示方法,提高多语言文本表示的准确性和一致性。
致力于多语言文本处理的DELPH-IN(Deep Linguistic Processing with HPSG)国际合作组织运用中心语驱动的短语结构文法(Head-driven Phrase Structure Grammar, HPSG)和最小递归语义学(Minimal Recursion Semantics,MRS)来进行文本的句法分析和语义表示[ 2]。近年来,针对英语、日语等数十种语言中的MRS研究和语法开发都显示出了其适用性。而汉语在这方面研究较少,因此本文尝试通过构建一种小型汉语语法来探索MRS框架对于汉语语义表示的适用性。 由于汉语的语言现象十分丰富, 对整个汉语现象的分析是一项系统性工作, 根据MRS
量词处理上的灵活性,本文以汉语名词性量化短语这一语言现象为例进行分析。
汉语的名词性量化短语指的是含有广义量词的名词短语,如“五篇论文”、“许多案例”、“大部分哺乳动物”等。
2 汉语名词性量化短语分析
2.1 名词性量化短语的MRS语义表示
MRS在1995年由Copestake等[ 3]首度提出,用以解决机器翻译中源语言和目标语言词汇表达习惯不同带来的翻译困难。MRS兼顾适度表达性和可计算性,采用扁平化表达简化了不必要的嵌套处理过程,允许在辖域信息没用的时候忽略它,而在辖域信息影响句子语义的时候恢复它。这种不充分确定性(Underspecifiability)使之可适应于不同分析深度的分析系统。关于MRS原理和构成规则的详细介绍可参见文献[4]。
以汉语高频句型之一(主谓宾)“每一个人携带约100万亿个微生物”为例,其MRS结构如图1所示:
 | 图1 “每一个人携带约100万亿个微生物” |
的MRS表达式结构简图
MRS将词的语义以元素谓项(Elementary Predications, EPs)的形式表达,一个EP包括标签、谓词和参数(如l1: 携带(e1, x1, x2))。词间的关系构成了句子的语义,在MRS中,词的关系是由参数的共值(Coindex)以及量词辖域关系(qeq关系)来表现的。图1中虚线是qeq关系,表示下位的EP处于上位EP的辖域范围内,并且它们之间可以浮动任意个量词。根据这种规则,例子中的MRS表达可组合成两种语义结构,如图2所示:
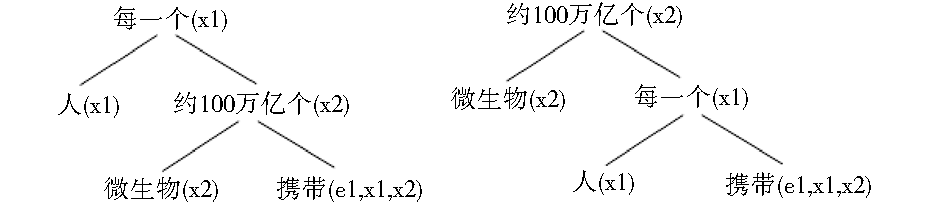 | 图2 “每一个人携带约100万亿个微生物” |
的语义组合结构简图
这两个语义结构均包含在MRS简化表达式中:
{l0, {l1: 每一个(x1, h1, h2), l2: 人(x1), l3: 携带(e1, x1, x2), l4: 约100万亿个(x2, h3, h4), l5: 微生物(x2) },{l0 qeq l3, h1 qeq l2, h3 qeq l5}}
对于本例中的句子来说,通常取第一种量词“每一个”占宽域的语义解释,量词的辖域歧义并不明显。而遇上量词辖域有歧义的情况,MRS表达便可以将所有的歧义语义用一个表达式表达出来而无需分别列出,在大规模处理中节约了处理空间和时间。
目前在计算机处理中通常采用类型化特征结构(Typed Feature Structures, TFS)来表示MRS,例子MRS的TFS表达如图3所示:
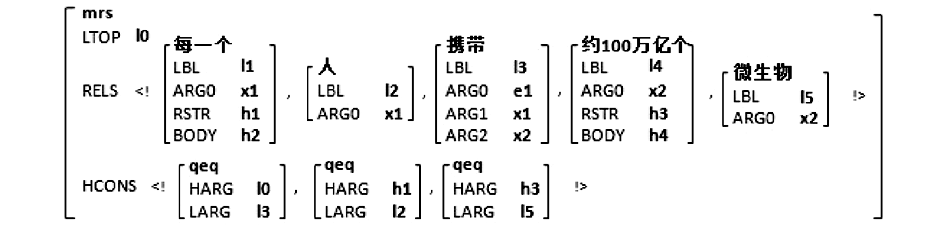 | 图3 “每一个人携带约100万亿个微生物” |
的MRS语义
在TFS中小写加粗字体代表类型,大写字体代表特征。MRS语义的谓词和标签分别由特征PRED和LBL标识,ARG0是索引,其他特征为变量。
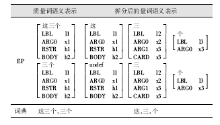
汉语需要分词处理,因此在设定词类和构建词典时,需要考虑到词的粒度。按照量词是否具有基数性质,可将所有的<1, 1>型量词分为基数量词和不对称量词两大类。大略来说,涉及数量的量词,如“奇数个”、“这五种”等均为基数量词,而涉及比例的量词如“所有”、“大部分”多属于不对称量词。不对称量词通常对应的就是一个词,而基数量词则通常由指示代词、数量词、单位词等几种词类自由组合而成,其语义可进行进一步拆解。
本文基于ERG(English Resource Grammar)的设计,将基数量词语义拆成三个关系:量词关系,为主体,在有指示代词时以指示代词为谓词,没有的情况则以“undef”为谓词表示这个量词是非定指的;基数关系,具有一个以单位词谓项的索引为值的变量和一个基数特征CARD;无变量的以单位词为谓词的关系。
这种处理有三个好处:进一步分解了量词的语义有利于后续的推理;由于基数量词通常是由几种句法角色组成的,拆分的处理使语义的合成更加贴合句法分析;减少了词典的冗余,增加了构词的灵活度。一个拆分实例如表1所示:
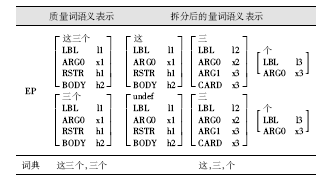 | 表1 基数量词的MRS语义拆分 |
拆分后的MRS语义的基本关系类型及其对应的词类如表2所示:
| 表2 MRS关系与对应的词类 |
2.2 名词性量化短语的句法分析
语义的合成随着句法分析的过程同步进行,句法的设计在很大程度上影响着语义的合成。
本文从约3万字的自然语言文本中选出300多个名词性量化短语,在对量词语义分析基础上进行了分类分析。分析表明量化NP结构的组成十分灵活,比如:指示代词+数量词+单位词一起构成定指基数量词;限定词本身构成一个不对称量词;一些数词不加单位词就作为基数量词,和名词一起构成NP。
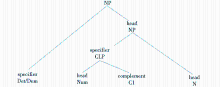
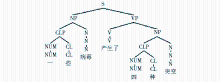
以往有针对中文名词短语的HPSG句法分析,可参见文献[5-8]。本文根据语料分析的结果采用这些分析中合理的部分并做了一些调整,设计名词性量化短语(不考虑形容词等其他句法结构)的HPSG结构分析如图4所示:
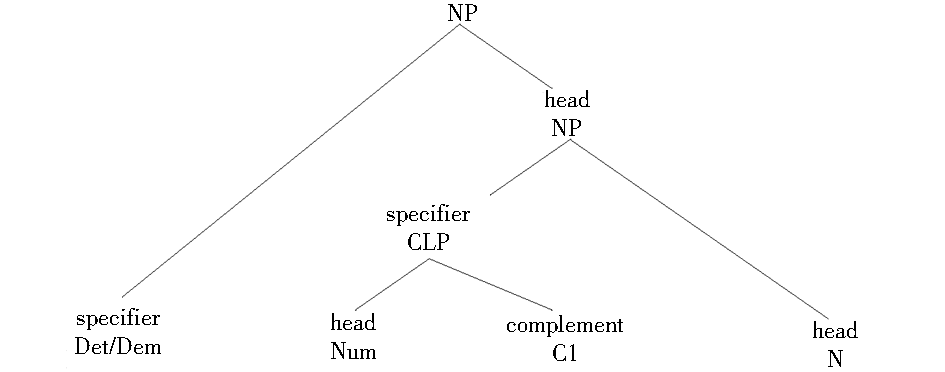 | 图4 名词性量化短语的HPSG结构分析 |
这个结构将基数量词对应的句法单元CLP和定指/存在标志对应的句法单元Det/Dem分列为中心语名词的两个标识语(Specifier, SPR)成分,便于它们进行组合形成定指量词和存在量词。需要注意以下几点:
(1)整个结构的中心语为N。与文献[6]认为中心语是指示代词Dem不同,本文认为选择名词N作为中心语较为适合。原因是:在逻辑上与其他成分(如VP等)发生作用的是名词N,而非Dem;在很多情况下,NP中是不出现Dem的,如果将Dem作为中心语,会给句法分析带来困难。
(2)指示代词Dem和“数量词-单位词”短语CLP为中心语的双SPR结构。Dem和CLP应当处理为不同的句法单元,双SPR的结构在语料分析和实际操作中都显示出较大的适用性。
(3)CLP是一个“中心语-补足语”结构,其中数词Num为中心语,单位词Cl为补足语。这与之前研究者对于CLP结构的几种分析都不一样,原因在于从逻辑结构来看,Cl所代表的单位词在逻辑上并不直接与名词发生关系,而是要借助数量词一起限定名词。
3 语法设计与实现
3.1 系统设计
本文语法以HPSG理论为形式模型,运用TFS来描述语言信息及规则。
语法使用类型化描述语言(Typed Description Language, TDL)进行编写,选用LKB作为语法的开发和实验平台[ 9]。LKB的最初开发者是Ann Copestake,后续的重要贡献者包括John Carroll、Rob Malouf 和 Stephan Oepen等[ 10]。
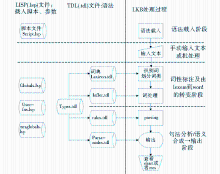
语法的功能模块和处理流程如图5所示:
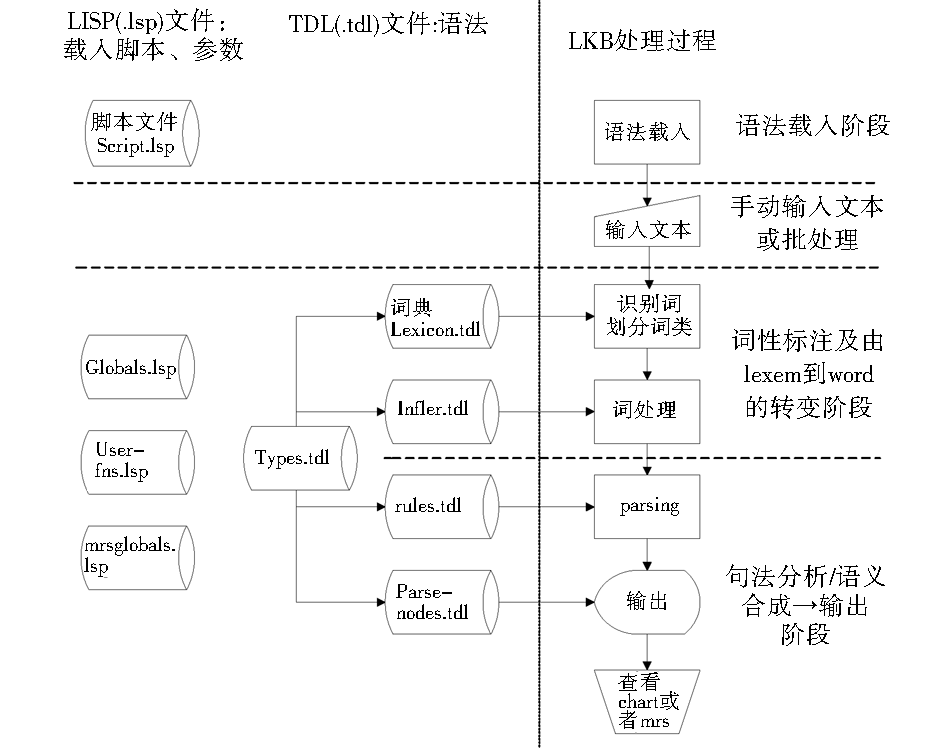 | 图5 系统功能模块图 |
(1)首先载入脚本文件(Script),LKB根据脚本文件指示依次读取其余所有的语法文件,并依据TFS的构成规则检验类型和等级关系的规定是否符合规定(包括Greatest Lower Bound、有无循环等)。
(2)在检验无误的语法载入完成后,手动输入句子或者通过批处理的方式输入多个句子。输入的句子将首先与词典进行比照,进行词性标注并形成包含音形和基本句法、语义信息的lexeme。随后根据infler.tdl文件将lexeme转化为word,至此每个词都已形成了一个类型特征结构。
(3)根据步骤(2)的处理结果,按照类型规定和处理规则(rules.tdl),不断进行类型特征结构间的合一运算,直至得出一个最终的类型特征结构。
(4)LKB会根据parse-nodes.tdl的命名生成一个句法树,标志着分析的完成。而后进行MRS语义结构以及分析的过程路径的查看。
3.2 类型定义及词典构建
基于TFS的语法通过类型描述和类型间的等级关系来描述语言现象,因此语法的核心内容就是关于类型的定义。
(1)类型定义
有一些类型已经内置在LKB的TFS的体系中,属于TFS的基本类型,比如*top*、*list*等,关于类型定义的方法和基本类型的规定等内容参见文献[11]。
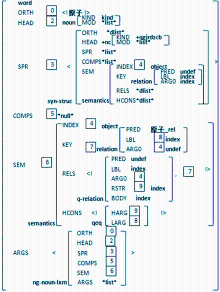
除去这些通用类型外,一个重要类型是syn-struc,这个类型是所有词、句子以及句法分析中间结构的母类型。根据其特征的不同取值形成词或者其他结构对应的类型。下面以名词“原子”为例进行说明,其TFS如图6所示:
 | 图6 “原子”的类型特征结构 |
这个TFS中包含了句法语义两方面信息。句法方面,ORTH表示语音信息,所有词的语音都是只有一个元素的列表;HEAD是该结构的中心语词性信息,其值在本例中就是名词词性noun。
SPR表示该结构的标识语,其值显示名词的标识语是一个词性为限定词或者数量词的结构,并且其KIND属性为“+qgjrdzcb”,表明这个名词可以搭配个体、集合、容器、度量、种类、成形和不定这几类单位词。
COMPS表示补足语,属性的值为“*null*”说明该词不应当有补语成分,ARGS是该结构中所有元素的列表,这个结构具有一个元素,就是这个词本身。除去词类型外,句法分析的过程中会产生一些中间结构,就是平常所说的短语结构,这时候这个属性的值是一个含有多个元素的列表。
词的语义信息由SEM特征描述,其值类型为semantics,这个类型有如下几个特征:INDEX标识了这个语义单元的类型,是一个事件(Event),或是一个对象(Object);KEY标识了TFS结构的中心语义关系,即带领整个语义结构与新元素关系发生关联的最高一级语义;RELS和HCONS分别是构成MRS的基本谓项(即语义关系)的列表以及涉及到量词的谓项间的辖域关系(qeq关系)的列表。由于一个句子的EP和辖域关系会有多个,并且随着句法分析不断增多,因此特征RELS和HCONS的值类型是*dlist*。
从图6中SEM描述的属性来看,这个词索引的值表示该词是一个“对象(Object)”类型,其标识语和它同索引,表明他们指向的是同一个对象;其中心语义关系是以“原子_rel”为谓项的一个名词关系;这个词的语义由两个关系组成:undef标记和名词本身的语义关系。
矩形内加数字的结构是一个标引,被相同数字矩形标记的两个特征共值。共值的有效范围是单个TFS。
“原子”是一个word类型的TFS实例,其本身特征的值是由其他类型的实例组成的。在本文构建的语法中,一共设计了约90个类型,其具体的名称和等级关系如图7所示:
 | 图7 语法的所有类型及其等级关系图 |
(2)词典的构建
由于大部分词汇信息都在类型中进行了定义,因此词典需要负担的信息量不多,主要是词的类型、形态以及语义关系的相应谓词,其编写完全依照语法对于词类的定义。有一点需要注意:虽然词典的书写方式与类型的定义方式一样,但词条的解释却与类型的定义不一样,不应当理解为子类型,而应理解为实例。
3.3 句法规则及语义表示合成示例
语法选择“NP+不及物动词”和“NP+及物动词+NP”这两种自然语言中常见的高频句式为基本句式来进行句法分析。根据对名词性量化短语的HPSG分析,句法分析的规则主要有:
S → NP(specifier) + VP(head)
NP → Det (specifier)+ CLP(specifier) + N(head)
NP → Det (specifier)+ N(head)
NP → CLP(specifier)+ N(head)
NP → N(head)
CLP → Num(head) + Cl(complement)
CLP → Num(head)
VP → V(head) + NP(complement)
VP → V(head)
所有这些规则基本可以归为两种规则:标识语和中心语的合一以及中心语和补足语的合一。标识语和补足语的数量不同,或者短语结构的内部条件的不同会演化出多条规则,但本质上都是这两种规则的变体。这些规则在语法中的名称以及相应的说明如表3所示:
| 表3 句法规则说明 |
以上介绍了文本分析所需的关键文件:类型定义、句法规则和词典。由于在编译语法时已嵌入了MRS框架,随着句法分析的过程,语义表示会同步合成。图8简要给出一个名词性量化短语语义合成的示例。
 | 图8 “那五种病毒”语义表示合成示例 |
4 实验结果
单个句子的句法分析结果、规则调用过程以及生成的语义表(以句子“一些病毒产生了四种突变”为例)分别如图9至图11所示:
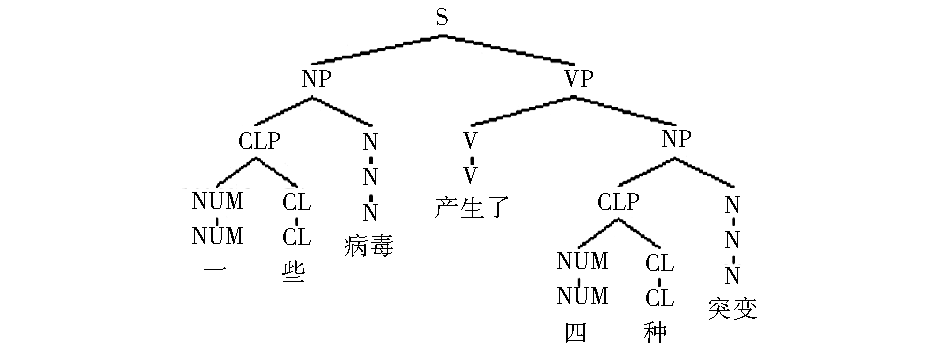 | 图9 “一些病毒产生了四种突变”句法树 |
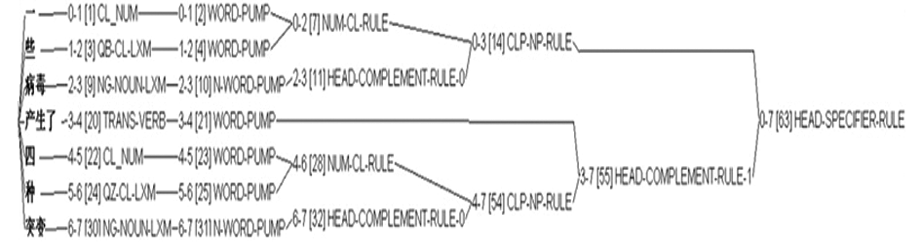 | 图10 “一些病毒产生了四种突变”规则调用 |
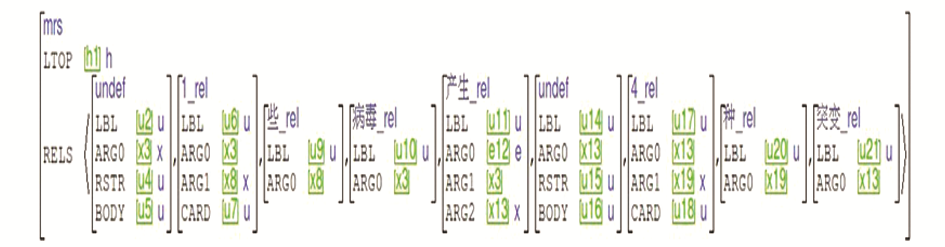 | 图11 “一些病毒产生了四种突变”的MRS语义 |
与基于统计或者语料库的方法不同,这种文本分析方式属于基于规则的理性主义方式,因此对它的测试在一定程度上是对句型处理能力的测试。基于规则的文本分析方式的缺点之一就是生成能力过强,会将本不合法的句子也视作正常句子进行处理。这是本语法希望避免的。根据语法针对的处理对象,本文构建了一个小规模实验句集,这些句子囊括了“NP-不及物动词”和“NP-及物动词-NP”这两种最基本的高频句式,包含定指、非定指、基数、非对称等不同类型的量词。此外,为考察该语法是否可以辨别不合法的句子,实验句集中故意插入了几个错误句子。句集的分析结果如图12所示:
每个句子后面的第一个数字表示句法分析得到的结果数量,数字为0则表示分析失败。
从结果可看出,该语法能正确分析两种主要句型以及“限定词-数量短语-名词”、“限定词-名词”、“数量短语-名词”、“数量-名词”这几种基本类型的量化名词短语;同时,可分辨单位词的缺失、标识语的错位、合法结构的重复以及限制词间搭配。
这个实验表明该框架适用于处理汉语的基本名词性量化短语以及两种基本句式、处理词间搭配(本文中主要是名词-单位词的搭配),并能阻止不合法句子(避免生成能力过强)。
5 结语
本文基于最小递归语义学、中心语驱动短语结构语法和广义量词理论,以汉语的名词性量化短语为例,设计实现了一种小型汉语语法,并通过实验验证了语法在处理汉语的名词性量化短语中的有效性。但对于汉语的部分特殊用法和大规模的汉语分析语法的构建还需进一步研究。
汉语HPSG/MRS语法的研究上有两个难点:
(1)作为一种基于规则的处理方法,其构建的复杂度很高;
(2)作为一种基于词典的语法,HPSG/MRS语法的分析能力受词典规模的制约。
在未来研究中,会考虑将针对汉语的HPSG/MRS分析整合到LinGO的Matrix研究项目中[ 12],运用已有
的对“共同语法”的研究来辅助汉语语法的构建。词典的构建则可以考虑借助已有的汉语知识库(如知网等)来自动构建。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|