{kind=link}
{kind=link}
{kind=link}
知识组织系统自动映射规则研究与实现*——以《杜威十进分类法》和《中国图书馆分类法》为例
引用本文
曲建峰, 李芳, 张轶华, 李鲍. 知识组织系统自动映射规则研究与实现*——以《杜威十进分类法》和《中国图书馆分类法》为例 . 现代图书情报技术, 2012, 28(10): 83-88
Qu Jianfeng, Li Fang, Zhang Yihua, JLi Bao. Study and Implementation on the Automatic Mapping Rules Between Knowledge Organization Systems——The Case of the Dewey Decimal Classification and the Chinese Library Classification. 现代图书情报技术, 2012, 28(10): 83-88
Permissions
Qu Jianfeng, Li Fang, Zhang Yihua, JLi Bao. Study and Implementation on the Automatic Mapping Rules Between Knowledge Organization Systems——The Case of the Dewey Decimal Classification and the Chinese Library Classification. 现代图书情报技术, 2012, 28(10): 83-88
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
知识组织系统自动映射规则研究与实现*——以《杜威十进分类法》和《中国图书馆分类法》为例
摘要
详细介绍运用数理统计学和语料库语言学的方法建立DDC与CLC的映射规则,并利用该规则设计和实现DDC-CLC映射规则试验系统,然后运用该试验系统生成DDC与CLC映射关系表,最后利用已经同时拥有DDC和CLC的数据对生成的映射关系表进行检验,从而通过不断的改进映射规则得到相对有效的映射关系表。
关键词:
杜威十进分类法; 中国图书馆分类法; 自动映射; 知识组织体系; 映射规则
中图分类号:G253
Study and Implementation on the Automatic Mapping Rules Between Knowledge Organization Systems——The Case of the Dewey Decimal Classification and the Chinese Library Classification
Abstract
This paper applies mathematical statistics corpus linguistics to generate mapping rules between DDC(Dewey Decimal Classification) and CLC(Chinese Library Classification). A test system is then built up and the DDC-CLC mapping table is produced through the system. The mapping table is examined by bibliographic records with DDC and CLC data so that continuously improved mapping rules and tables can be obtained.
Keyword:
Dewey decimal classification; Chinese library classification; Automatic mapping; Knowledge organization systems; Mapping rules
1 引言
知识组织体系(Knowledge Organization Systems, KOS)是对人类知识结构进行表达和有组织地阐述的各种语义工具(Semantic Tools)的统称,包括分类法、叙词表、语义网络、概念本体以及其他情报检索语言与标引语言[ 1]。不同信息系统采用的知识组织体系各不相同,通过异质知识组织体系间的互操作,形成各个信息系统之间的语义交互,使分布式的数字资源得以统一组织、管理和利用,是近年来知识组织体系研究中的热点问题。分类表、标题表、叙词表、术语表等传统的标引语言经过多年的应用实践,它们之间的互操作问题更显迫切,而且先行解决它们的互操作问题也有助于语义网络和本体等新的知识组织工具的“统一”和“兼容”问题的解决。
国外学术界一直比较重视知识组织系统间的互操作研究,实施了许多积极而有效的研究,探索各种方法来减少同一系统中不同词汇表间的冲突。早期的研究方法主要依赖于人工智能,随着计算机方法的应用,信息技术被
用来实现和完善互操作方法。派生法[ 2]、翻译法[ 3]、卫星词表法[ 4]、直接映射法[ 5]、共现映射法[ 6]、转换法[ 7, 8]等互操作方法在实践中被广泛使用,其中映射的方法被美国一些主要联机书目服务中心采用[ 9]。过去,映射方法被认为过多依赖于专家、耗费时间,近年来随着计算机辅助映射研究的深入,自动映射方法已在国内外研究项目中得以应用,如DDC(Dewey Decimal Classification)和EI(The Engineering Index) Classification在工程领域的自动映射。根据知识组织系统映射关系建立过程中人工智力的参与程度,可以分为人工映射和自动映射两种模式[ 10]。人工映射主要基于人的主观判定来确立概念间的对应关系,而自动映射主要根据一定规则或统计的计算原理,主要由计算机自动完成。目前国内自动映射的研究主要有基于规则的方法和基于统计的方法两类。基于规则方法较有代表性的研究有:戴剑波等[ 11, 12]以CLC和DDC为例,将类目表达的整体概念之间的相似度计算转化为词汇之间的相似值计算,词的相似值计算通过词汇的语义相似度计算方法来完成,该方法是利用词的相似度矩阵和空间向量模型,通过一定的加权计算得到类目的相似度,依靠模型和规则来获得类目相似度;贾君枝等[ 13]从分类类目体系中占很大比重的组合类目入手,从等同、包含和交叉三种关系类型研究DDC和CLC组合类目直接映射的匹配规则。另外一些研究将注意力转向基于标引数据的挖掘,即基于统计方法的自动映射研究,具代表性的研究有:李波等[ 14]提出尝试将MARC数据综合起来,根据这些数据中分类号和主题词之间的对应关系,通过统计和分析自动建立一个差错率较低的分类法与主题词或词串表之间的转换系统;章成志等[ 15]利用互信息模型把语料库、释义词典、用户检索日志作为识别相关词的语境而设计的相关词自动提取系统;张雪英[ 16]提出的基于并行文献数据库索引的语言概念转换系统;张轶华等[ 17]通过挖掘书目记录分类共现频次的关系,设计基于统计映射表和人工映射表的DDC-CLC的自动映射系统。综上所述,在知识组织互操作领域,更多学者关注并重视自动映射的研究,无论是基于规则的还是基于统计的方法,减少人工智力干预程度、扩大映射规则和方法在实践中的应用和推广是研究知识组织系统间互操作的发展方向。
本文旨在结合基于统计的自动映射和规则研究,提出运用数理统计学和语料库语言学的方法,通过收集、统计标引记录的分类数据,研究这些对应关系的随机变量和概率分布,在此基础上制定映射规则获取具有一定可靠性的映射关系,建立分类法类目的统计映射表。并且对于未得到映射关系的分类,运用人工干预来获取映射关系的方法对映射关系表进行有益的补充,使其保持完整。为使映射研究更具有实践和应用价值,选取《中国图书馆分类法》(Chinese Library Classification, CLC)第五版[ 18]和杜威十进分类法(Dewey Decimal Classification,DDC)第二十三版[ 19]这两部影响巨大、应用范围较广的文献分类法,并建立它们之间的映射关系。
2 基于数据统计的映射规则研究
运用数理统计学的方法获取DDC与CLC的映射关系表,首先收集了34 648条CALIS西文书目记录作为样本数据,这些记录同时拥有DDC和CLC,对MARC记录提取082和093字段获得DDC和CLC,如表1所示。对表1中的DDC-CLC对应关系汇总处理可以获得最原始映射关系表,然后运用数理统计的方法建立两者之间的映射规则,以便从样本数据中挑选出可靠的映射关系。
| 表1 样本数据 |
2.1 基于数据统计的映射规则
首先对已有的样本数据进行预处理,即对于DDC与其对应的CLC完全相同的数据要进行汇总,并统计其出现的次数,由此作为确定DDC与CLC之间映射关系的一个基础,称其为汇总统计。由表1可以得出同一个DDC可能对应多个不同的CLC,因此需要计算出每个DDC拥有多少样本数据和出现总频次;同一个DDC究竟对应几种CLC即种类统计,如表2所示:
| 表2 汇总统计表 |
利用已有的样本数据可以计算出每组DDC与CLC对应关系的概率P,即P=F1/F2,根据此对应关系与其概率的数据特征可以确定该对应关系的分布是离
| 表3 概率分布 |
然后利用这些样本数据,来确定DDC与CLC对应关系的概率P符合什么条件就可以保留其映射关系。而参数估计(Parameter Estimation)是根据从总体中抽取的样本估计总体分布中包含的未知参数的方法[ 21]。因此该问题可抽象为概率类型是多项式分布的参数估计问题。以DDC与CLC仅有两种对应关系为例,即P(X=x1)=p, P(X=x2)=1-p。其概率密度函数为:
P(x)=px 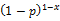
利用极大似然估计对参数p进行估计。样本似然函数定义为:
L(X1,X2,…,Xn;p)= 
对上式取对数得:
ln[L(X1,X2,…,Xn;p)]=ln 
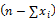
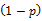
再对上式对p求导,并令其为零:
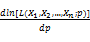

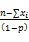
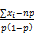
求解上式,可得:
p= 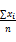
其中,n为样本数。
依据该计算方法,可以利用预处理的数据来获取DDC与CLC的映射关系,此处的预处理数据是指运用汇总统计方法处理之后,得到的DDC与CLC对应关系的概率。准确率(Precision)是自动分类系统的常用评价指标,笔者认为利用一本图书所拥有的DDC从本研究成果的映射关系表中获取的CLC与这本书所拥有的CLC一致为本映射关系“正确”。那么正确率就是映射关系正确的比率。假设任意一本拥有DDC的图书所对应的CLC为X1是正确的正确率为80%,则需P(X=x1)≥0.8。同理,如果对应关系多于两种,并且没有任意一种对应关系的概率大于0.8,那么概率最大的两种对应关系的概率之和大于0.8,以此类推,可以得到一个DDC对应的正确率为80%的CLC为Xi,Xi满足以下条件:
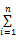
其中,n为满足条件的CLC数量,正确率80%为参数,用户可以根据自己的需求来设定该参数。利用该映射规则可以得到用户设定的正确率的映射关系表。
2.2 映射关系表的扩展
经过这些方法的处理,可以得到满足映射规则的DDC与CLC的映射关系,也存在很多不符合映射规则的数据。为了得到更多的DDC与CLC的映射关系,可以对不符合映射规则的数据中的CLC合并上位类,如表4所示,取CLC三级类并对其进行汇总统计,在此用户可以根据自己需求来设置合并至几级上位类,然后利用映射规则对数据再次进行处理就可以减少未匹配的DDC与CLC的数量。
| 表4 合并上位类并汇总统计 |
对于不符合映射规则的数据中的CLC从高级别的类到一级类不断地合并上位类,最后还是会得到一些不符合映射规则的数据,此时,可以采取人工干预的方法来决定DDC与CLC的映射关系,从而得到完整的映射关系表,也可以利用美国国会图书馆主题词表作为媒介来实现DDC与CLC的映射关系。
3 DDC-CLC映射规则试验系统的应用
框架设计
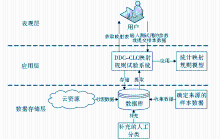
根据DDC-CLC映射规则试验的需求,系统的应用框架可以分为表现层、应用层和数据存储层,如图1所示:
 | 图1 DDC-CLC映射规则试验系统的应用框架 |
(1)表现层:用户输入测试的参数并提交相应的数据给DDC-CLC映射规则试验系统,系统根据统计模型计算出相应的DDC-CLC映射关系表,并且用户可以从系统中提取已计算出映射关系表的部分中间结果集。
(2)应用层:DDC-CLC映射规则试验系统应用统计映射规则模型来计算DDC-CLC映射关系表,并提供用户所需要的参数更改接口,从而不断地完善映射规则。
(3)数据存储层:收集各类样本数据,包含来自确定来源的样本数据和从网上的云资源中采集到的数据,并按照一定格式存储;在形成DDC-CLC映射关系表时,会存在一些无法得到映射关系的类,此时就需要补充人工分类来保证DDC-CLC映射关系表的完整性。
4 实施方案
4.1 DDC-CLC映射规则试验系统的流程
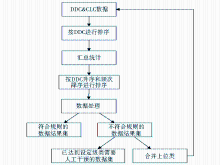
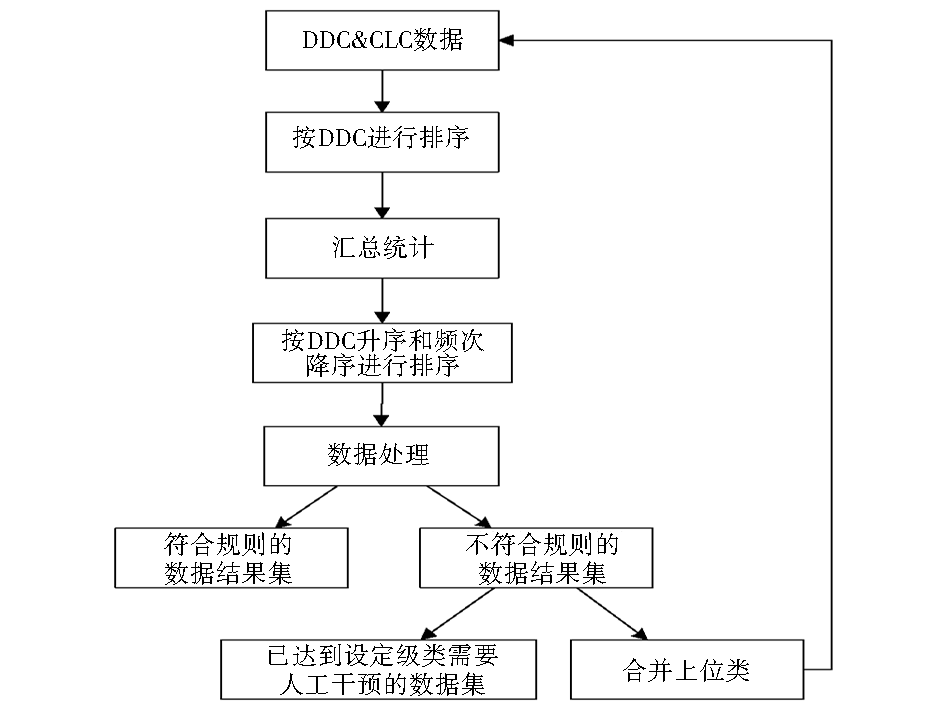 | 图2 DDC-CLC映射规则算法试验 |
系统的流程
根据DDC-CLC对应数据统计和映射规则处理的需求,其中的计算变量有每种DDC对应的CLC在样本数据中出现的次数、种数、概率。为了提高算法的计算效率,需要首先计算出一些中间值,比如出现的次数、种数等。因此,在做应用程序的整体设计时,分成三个基本的程序模块:数据预处理模块即汇总统计;运用映射规则获取映射关系表的模块简称为数据处理;合并上位类,其流程如图2所示。为了方便程序对数据的处理,在一些模块中增加了按照不同字段对数据表的排序处理,经过一系列的程序处理后,最终可以得到符合规则的数据结果集和已达到设定级类不符合规则需要人工干预的数据集。将人工干预的数据处理完毕后,与程序处理得到的结果集合并就得到了DDC-CLC映射关系表。
4.2 DDC-CLC映射规则算法试验系统的实现
(1)汇总统计模块
汇总统计模块是为数据处理做准备工作。经过这个模块对样本数据的处理之后,可以得到频次总计、出现总频次、种类统计。在计算DDC&CLC频次总计后,需要对DDC&CLC的数据进行去重,因为相同数据行对于得出数据的DDC-CLC对应数据映射关系表没有任何意义,还会浪费系统运行时间。
(2)数据处理模块
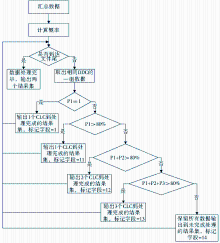
数据处理模块主要是利用映射规则来获取映射关系的结果数据集,因此首先要计算概率,然后依据映射规则对相同DDC的数据组一一处理,直到所有数据都清理完毕,数据处理程序的流程如图3所示:
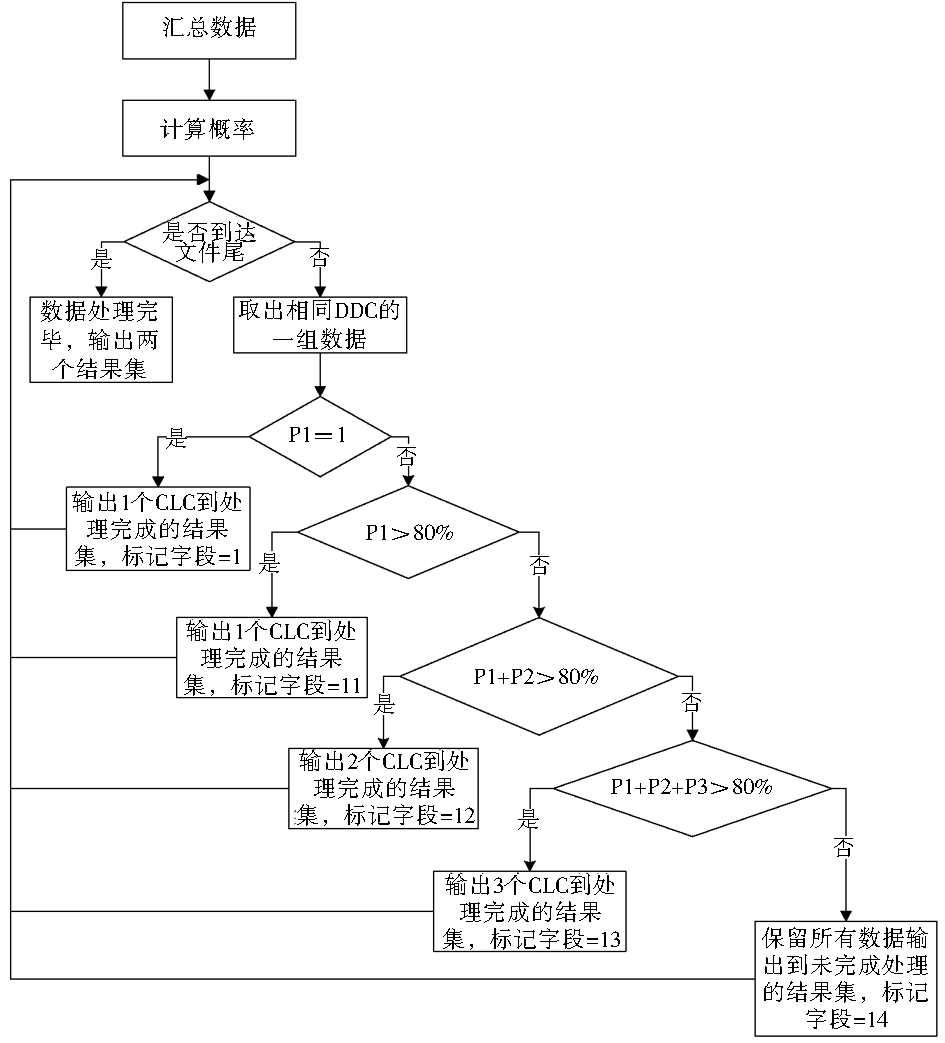 | 图3 DDC-CLC对应数据一对多数据 |
处理程序的流程
图3中的P1指的是相同DDC的一组数据中概率最大值,依此类推P2和P3为次之概率值和次次之概率值;N为相同DDC的一组数据中的CLC种类合计。在做数据处理时,按照映射规则给出不同的数据处理标记,这样使后续数据整理工作中对数据所保留的映射关系的数量以及其概率是否为1可以一目了然,便于审视规则的合理性;对合并上位类之后得到的映射关系,其标记可依次定义为2、21、22、23,3、31等。
(3)合并上位类模块
合并上位类的程序就是对中图分类法的字段进行用户需要的级类提取;比如用户需要按照三级类来对已有的中图分类法数据来合并上位类,需要注意的是CLC三级类并非是简单截取已有分类前三位字符,因为有些是多于三位字符,而且其组成结构是固定的,如TH13、TD-05等。若对这些固定结构直接截取前三位字符的话,“TH13”就变成了“TH1”,然而在CLC中是没有“TH1”这个分类的。因此在合并上位类时,首先要得到这些特殊的CLC三级类列表,然后对照此表进行三级类的提取,这样才能得到有意义的CLC三级类;对于列表中没有出现的就可以直接截取前三位字符来得到CLC三级类。对于原始数据列表中CLC分类没有达到三级分类的予以保留即可。
(4)结果展示
用户通过DDC-CLC映射规则试验系统可以方便地得到DDC-CLC映射关系表,该系统提供了接口来获得所需的所有数据,包括计算过程中一些关键性的中间数据,从而来验证映射规则的合理性。
通过该系统得到相应的DDC-CLC映射关系表后,将其对实际数据进行DDC到CLC的映射进行相应的实际检验,以便及时修正DDC-CLC映射规则的模型,确保DDC-CLC映射关系表可以实现实际应用中正确率与笔者假设的正确率相同。本文将这些书目记录中的分类结果作为同现映射关系,与映射关系表的匹配结果进行相似性比较,从一定程度上评价了本文构建的映射关系表的实际效果。
比如,笔者收集了34 648条CALIS书目记录,对其中相同的DDC-CLC对应关系进行聚类统计,然后对每一个DDC,按照CLC出现概率由大到小的顺序,依次取CLC出现概率之和大于等于80%的建立一个DDC-CLC映射关系表。所取的书目记录共25 813条,占整个收集书目记录的74.5%,然后运用人工干预的数据集来补充完整DDC-CLC映射关系表。为了验证映射关系表的有效性,收集2 000条同时含有DDC和CLC分类标引的剑桥书目记录作为校验数据,利用所建立的映射关系表对校验数据中的DDC分别匹配获得对应的CLC,其正确率统计如表5所示:
| 表5 CLC正确率统计 |
理论上,运用上述方法得到的映射关系表,匹配获得的CLC正确率至少应该达到80%,但由于样本书目记录量非常有限,对DDC类目的覆盖率很低,不能被映射表覆盖的DDC分类号,是通过人工DDC三级类目映射表获得CLC分类号(从一级到三级),所以获得的CLC正确率仅仅在一级类目的正确度高于理想情况下的80%,而CLC三级类目准确率为68.1%,完全准确的比例仅为45.1%。因此该映射规则还需要改进才能更符合假设的正确率。
5 结语
与现有基于规则的研究方法相比,本文基于数据统计的方法,在大量数据样本基础上总结出映射规则和参数,采取概论统计与人工分类相结合的方式建立DDC和CLC分类法分之间的映射关系表,不同于纯粹数学模型和向量矩阵的计算方法。此方法虽然可避免对词表本身做复杂的语义对比分析,但其准确性与样本的大小、质量、参数的确定等有密切关系,尤其是参数设定的依据,需要通过大量的数据实验来验证。本文通过对DDC-CLC映射关系表与实际书目记录中的分类结果比较,匹配度只有一级类目达到80%以上,映射规则还需要不断调整和改进,但对于不断增长的海量网络数据而言,利用这一映射规则和自动映射关系表达到一级类80%以上的匹配度是可以接受的。随着样本数据的增多和映射规则的不断完善,这个映射关系表的正确率将逐步提高。同时,由于存在一定数量不可匹配的数据,在未来的研究中,笔者计划引入其他知识组织体系,如《美国国会图书馆标题表》和《美国国会图书馆分类法》,作为对DDC和CLC映射关系的补充和参照,并最终建立一个高质量、高效率用于自动分类转换的知识库。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|