

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
PivotViewer在图书馆OPAC交互中的应用
引用本文
齐晓晨, 孙臻. PivotViewer在图书馆OPAC交互中的应用. 现代图书情报技术, 2012, 28(10): 93-100
Qi Xiaochen, Sun Zhen. Application of PivotViewer in OPAC Interaction of Library. 现代图书情报技术, 2012, 28(10): 93-100
Permissions
Qi Xiaochen, Sun Zhen. Application of PivotViewer in OPAC Interaction of Library. 现代图书情报技术, 2012, 28(10): 93-100
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
PivotViewer在图书馆OPAC交互中的应用
摘要
以新书通报为例,介绍PivotViewer的应用实现过程要点,全方位展示这种全新的数据可视化模式在图书馆OPAC显示中带来的效果,证明将PivotViewer应用到图书馆OPAC交互中可以为读者提供更加友好的人机对话和交流环境,并能有效提高读者的检索效率。
关键词:
PivotViewer; OPAC; 图书馆
中图分类号:G250.78
Application of PivotViewer in OPAC Interaction of Library
Abstract
Taking the new books’ notice for example, this paper introduces how to realize the application of PivotViewer in detail. It also shows the outstanding effects that the brand-new pattern of data visualization brings to OPAC interaction of library, which proves the application of PivotViewer in OPAC can provide readers with more friendly man-machine dialogue and communication environment, and the retrieval efficiency can be highly improved.
Keyword:
PivotViewer; OPAC; Library
1 引言
在计算机编目普及的今天, OPAC 是图书馆向用户揭示资源的重要途径,可视化又是OPAC的发展趋势。而目前国内图书馆使用的自动化系统OPAC的检索结果或是资源推荐(如汇文系统的新书通报、热门借阅等)大部分都存在以下两方面缺点:
(1)显示方式几乎都是千篇一律的基于文本的线性列表,比较死板,无法揭示书目信息之间隐藏的信息特征,一旦检索结果命中数比较大,用户极易视觉疲劳而无法区分,且有的系统只有单独打开每条数据的链接才能显示图书封面及其他详细信息。
(2)在对检索结果的数据筛选上,只能逐项选择条件来缩小范围,不能自由修改检索条件组合。
PivotViewer可以弥补以上不足,它是Silverlight工具箱里的一个开发控件,其前身Pivot浏览器由微软 Live Labs于2009年11月19日发布[ 1],该技术可在较短时间内载入近千条数据并将其进行可视化处理,在轻松阅览高分辨率的数据内容的同时,还允许用户自由筛选大量可视化信息和切换视图[ 2]。
PivotViewer适合用在以单一维度为基础的数值分析上,可以呈现这个基础维度与其他维度之间的分布计数或者与其他量值间的分布状态,它可被应用于零售业展示、图片图像展示、商业智能分析、学术研究展示等方向。目前国外一些交友、租售房屋、选择婚礼场地的网站已经应用到了该项技术。图书馆中,图书、期刊、音像资料的封面图像都是可供展示的内容,因此,PivotViewer技术可以并且非常适合应用到图书馆OPAC中。
本文将PivotViewer引用到图书馆OPAC中,以图书馆新书通报为例,展示了这种筛选自由、切换视图流畅、图书图像与书目信息完美结合的全新的OPAC交互可视化模式。
2 PivotViewer实现的技术原理和环境需求
2.1 实现原理
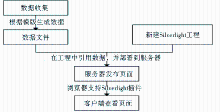
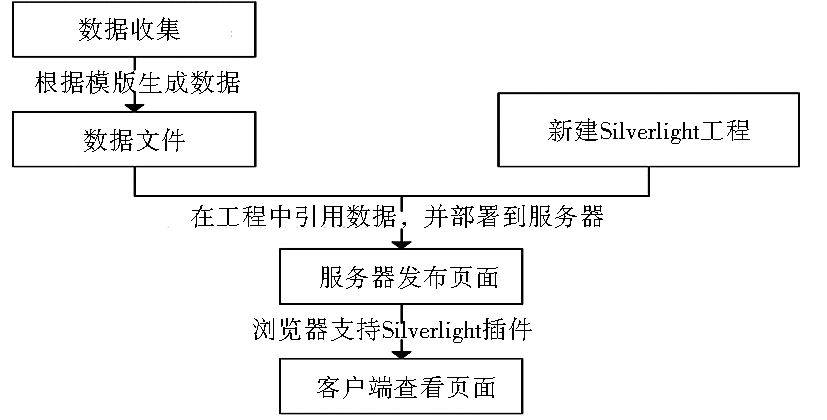
PivotViewer 主要基于 Pivot 和 Silverlight 4 的 Deep Zoom 技术,可供开发者创建自己的 Pivot 内容,并嵌入至网页。其实现分为数据收集和数据展示两部分,以在图书馆的应用为例,数据收集主要包括汇总所要展示的图书信息(如题名、责任者、出版年等)及图书封面(图片来源有豆瓣图书、超星的读秀学术搜索或图书馆手工扫描等方法),然后将图书信息与图片使用工具转换为PivotViewer的数据源文件;数据展示主要是将数据源部署到服务器上,并通过Silverlight页面来展现给用户。主要实现流程如图1所示:
2.2 软硬件环境
由于PivotViewer是Silverlight中的一个控件,因此需要针对Silverlight的开发工具——Microsoft Visual Studio 2010 + Silverlight 4 SDK;而Silverlight是作为浏览器插件运行在浏览器上,所以要用PivotViewer展示数据,还需要准备一台Web服务器,利用Microsoft提供的工具将收集到的数据部署在服务器上,才能够通过浏览器查看PivotViewer页面。推荐服务器操作系统为Windows Server 2008 R2,Web发布系统为IIS 7.1。
3 PivotViewer具体应用实现
本文以图书馆新书通报为例来介绍一个PivotViewer页面制作的全过程。
3.1 数据收集
Microsoft提供了三种数据收集的方式:使用Excel收集数据;使用命令行工具收集数据;在页面中实时收集数据。
其中,用Excel收集数据需要用到一个Excel插件:Microsoft PivotViewer Collection Tool for Microsoft Excel(下载地址:http://www.silverlight.net/learn/data-networking/pivot-viewer/download-excel-tool),由于Excel收集数据在分类定制上比较弱,而实时收集数据因在用户打开页面时进行数据收集会占用比较长的时间,所以本文推荐使用命令行工具Pivot Collection Tool for the Command Line(下载地址:http://pauthor.codeplex.com)收集数据。
下载该工具后,在命令行下执行代码命令,即设置文件的输入和输出路径,代码示例如下:
X:\Pauthor-RC3\Pauthor\bin>Pauthor.exe /source cxml X:\source.cxml /target deepzoom X:\newbook.cxml
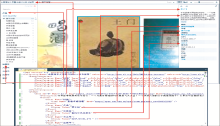
其中源文件为source.cxml,输出文件为newbook.cxml。源文件为一个后缀为cxml的文件,是个UTF-8编码的XML文件,源文件和PivotViewer页面的对应如图2所示:
 | 图2 源文件和PivotViewer页面的对应图 |
根据以上数据对应关系,把准备展示的图片信息数据制作成相应的XML文件,然后借助Pivot Collection Tool for the Command Line生成PivotViewer的数据源文件,包括索引文件(如上例中生成的newbook.cxml)和数据文件(如上例中在索引文件newbook.cxml旁生成数据文件夹newbook_files)。
3.2 服务器准备
需将以下三个MIME类型添加到Web服务器:
.cxml - text/xml
.dzc - text/xml
.dzi - text/xml
然后将本文3.1节生成的数据源文件部署到Web服务器根目录下。
3.3 数据发布
打开Visual Studio 2010,在Web服务器根目录新建一个Silverlight 4项目。
(1)在项目中添加引用“System.Windows.Pivot.dll”(在C:\Program Files (x86)\Microsoft SDKs\Silverlight\v4.0\PivotViewer\Jun10\Bin\下)。
(2)在前台页面xaml里添加PivotViewer所需的引用声明:
xmlns:pivot="clr-namespace:System.Windows.Pivot;assembly=System.Windows.Pivot"
(3)在页面中添加一个PivotViewer并在后台事件中指定PivotViewer的数据源:
public MainPage()
{
InitializeComponent();
PivotViewerControl.LoadCollection("http://127.0.0.1/newbook.cxml", " ");
}
(4)运行编译工程,编译完毕后即可从客户端查看PivotViewer页面。
4 PivotViewer效果演示
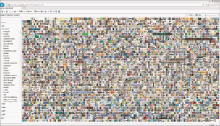
以上步骤完成后打开浏览器查看PivotViewer页面看到的整体效果如图3所示:
 | 图3 PivotViewer页面整体效果 |
在右上角可以选择图书封面排序条件,并可以选择Graph View按钮切换成聚合分类视图,如图4所示:
 | 图4 PivotViewer聚合分类视图 |
用户可在左侧的检索框输入检索词,同时在左侧的筛选面板中选择自己需要的条件,任意单选或多选、增加或删除条件,右侧的筛选结果界面都可流畅切换至新的筛选结果,利用检索词“海洋”、“海洋出版社”和“青岛海洋大学出版社”以及大类号P、T、Q、X作为筛选条件的检索结果如图5所示,视图最上方一行文字显示的即为此次的检索条件组合。
 | 图5 多种条件组合检索结果 |
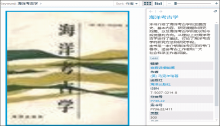
点击其中的任何一幅图片即会放大至合适大小,并将有关信息显示在右侧的概述面板中,如图6所示:
 | 图6 单项数据详细信息显示 |
此外,在PivotViewer视图中的任何图像都可自由拖动、缩放。Deep Zoom技术确保了图像拖动缩放的平滑和视觉连续性,其动画效果很完美。
5 结语
实践证明,与已有的图书馆自动化系统的OPAC相比,应用了PivotViewer技术的图书检索结果界面显示更直观、美观、迅速而且具有多维性,检索组合更自由,也更方便读者参与互动。用户使用这样的可视化界面,通过图形、视觉和联想不仅可以获取满意的检索结果,还能发现书目信息的模式、聚类、区别、联系与趋势,从而放大自身认知功能。
PivotViewer带来的这种全新的数据可视化模式,经过开发或可应用到图书馆工作的更多领域,比如影视资料介绍、文献专题展览、资源推荐(如图书排行等)。
目前,中国海洋大学图书馆已试验将PivotViewer应用到了2011年度新书展示中[ 3]。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|