{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于英汉双语短语级平行语料的类别知识挖掘研究*
引用本文
王东波, 韩普, 沈思, 魏向清. 基于英汉双语短语级平行语料的类别知识挖掘研究* . 现代图书情报技术, 2012, 28(11): 40-46
Wang Dongbo, Han Pu, Shen Si, Wei Xiangqing. Research of Mining the Category Knowledge Based on English-Chinese Humanities and Social Sciences Parallel Corpus in Phrase Level. 现代图书情报技术, 2012, 28(11): 40-46
Permissions
Wang Dongbo, Han Pu, Shen Si, Wei Xiangqing. Research of Mining the Category Knowledge Based on English-Chinese Humanities and Social Sciences Parallel Corpus in Phrase Level. 现代图书情报技术, 2012, 28(11): 40-46
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
基于英汉双语短语级平行语料的类别知识挖掘研究*
摘要
在已有聚类算法的基础上,基于英汉双语短语级人文社会科学平行语料,进行类别知识挖掘的实验。根据实验数据并结合具体的研究需求,确定相应的聚类算法和英语形态转换的算法。通过对汉语、英语和英汉双语词汇级知识聚类的性能进行对比,确定英汉双语词汇特征的性能优于单语。获取的类别知识可以直接应用到知识库、机器翻译模型的构建中,同时探究英汉两种词汇在类别知识获取过程中具体表现。
关键词:
CSSCI; 英汉双语短语级平行语料; Bisecting K-means Clustering; 算法; 类别知识
中图分类号:TP391
Research of Mining the Category Knowledge Based on English-Chinese Humanities and Social Sciences Parallel Corpus in Phrase Level
Abstract
The experiment of mining the category knowledge from English-Chinese humanities and social sciences parallel corpus in phrase level is performed based on the established clustering algorithm. The clustering and morphological conversion algorithms are determined by experimental data and specific research needs. The performance of English-Chinese bilingual word features is better than monolingual word by comparing the performance of the Chinese, English and English-Chinese word level knowledge clustering. The category knowledge is directly applied to knowledge base and machine translation system, and the English and Chinese word’s expression is explored in mining the category knowledge.
Keyword:
CSSCI; English-Chinese; parallel corpus in phrase level; Bisecting K-means clustering algorithm; Category knowledge
1 引言
在面向网络构建的英汉双语平行语料库中,语料存在的一个重要问题是没有类别知识,而类别知识对于机器翻译、辅助机器翻译、跨语言检索以及语言的本体研究具有重要的意义。本文在实验确定的具体聚类和词干或词形算法基础上,面向人文社会科学领域的英汉双语平行语料库,构建了类别知识挖掘模型,并具体探究了英汉双语词汇在类别知识挖掘上的具体表现和差异。
在单语文本的聚类研究中,相关学者[ 1, 2, 3]给出了各种文本聚类的方法以及相应的改进算法,而对于双语文本或多语文本的聚类来说,则相对比较复杂。章成志等[ 4, 5]在分析多语言文本聚类的应用价值前提下,梳理和总结了三种或三种以上语种的聚类方法,指出了这些聚类方法存在的问题,并探究了基于英汉双语平行语料库进行术语抽取的问题。采用“先聚类后合并”的策略,Chen等[ 6]通过计算簇间相似度,把中文的名词、动词和命名实体译成对照的英语,在单语简单聚类和合并聚类簇的方法前提下完成了对英汉双语新闻的自动聚类。在机器翻译系统支持的基础上,结合双语词典,Lawrence[ 7]在把俄语和英语两种文本中的词汇进行全部对齐,开发了针对这两种语言的文本自动聚类系统。在把目标语言翻译成英语的基础上,Evans等[ 8]设计了Columabia’s Newsblaster系统用来进行新闻摘要和话题的自动生成。通过借助语言分析,Mathieu等[ 9]从文本中抽取了相应的特征词,利用相对应的双语词典,完成了英文、法文和西班牙文混合文本的自动聚类。基于人名、机构名和地点名等命名实体,Montalvo等[ 10]在西班牙语和英语文本上进行了相应的聚类实验。借助英法平行语料资源,Dumais等[ 11]完成了对英法双语的潜在语义标引,并把标引的潜在语义应用到信息检索当中,为双语或多语的语义空间生成提供了相应的借鉴。通过在双语或多语的平行语料库的基础上构建实词或实词短语的双语或多语语义空间,Wei等[ 12]实现了对多语言文本的聚类。通过抽取西班牙语和英语可比语料中的相对照的命名实体,Montalvo等[ 13]研究了英语和西班牙语的可比语料聚类的可行性。上述研究是通过机器翻译语料或者可比语料进行相关类别知识挖掘,而本文是直接通过英汉双语平行语料中的词汇,结合相应的聚类算法来进行类别知识挖掘,使用了英汉两种词汇所蕴含的语义知识。
本文基于已有聚类算法,通过构建短语级类别知识挖掘模型,对从面向网络获取的专门领域的英汉双语平行语料进行了归类尝试,具体研究的流程主要包括:
(1)在通用的单语语料上,基于具体实验,确定本文所使用的Bisecting K-means聚类算法和Lemmatization词干或词形还原方法;
(2)对所选取的人文社会科学英汉双语平行语料进行汉语分词、去除停用词和英语进行去除停用词、形态转换等预处理;
(3)在所选取的聚类算法基础上,构建面向英汉双语平行语料的类别知识挖掘模型,并对英汉双语词汇在类别知识挖掘上的性能进行对比。
本文一方面探讨了如何从英汉双语中挖掘类别知识,在一定程度上突破了过去仅仅使用单语言的知识进行聚类的问题;另一方面在聚类过程中,主要使用了短语中包含的信息和知识,这与过去的研究中使用段落甚至篇章的知识具有明显的不同,为更深入地获取短结构集合中的类别知识提供了借鉴。
2 面向英汉双语短语级平行语料的聚类和词干或词形还原算法确定
通过相应的实验,本文确定了基于英汉双语短语级平行语料挖掘类别知识的聚类算法和词干或词形还原算法。
2.1 类别知识挖掘聚类算法确定
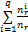
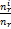
为了从划分和层次聚类这两种聚类算法中确定更适合英汉双语短语级平行语料的聚类算法,通过具体的实验,对比了Bisecting K-means Clustering[ 14]、 K-means Clustering[ 15]和Agglomerative Hierarchical Algorithms[ 16]三种聚类算法的基本性能,而具体的实验是在CLUTO[ 17]平台上进行的,使用了两种准则收敛函数进行聚类实验。对于划分和层次聚类算法来说,K-means Clustering是常见的聚类算法,不再赘述;Bisecting K-means Clustering算法也称为二分K均值算法,整体思想为:在获取K个簇的前提下,把由所有点构成的集合裂变成两个簇,选取任一个簇继续裂变下去,如此反复,直到K个簇产生为止。
在确定这三种聚类算法性能的过程中,使用的实验语料为复旦文本分类语料[ 18],针对复旦语料中类内和类间的各种类别重复问题,同一类别中的重复类别保留一个,类间的重复问题则保留具有单标签的语料文本。分词和词性标注分别使用了中国科学院计算技术研究所的ICTCLAS[ 19]和二级词性标注集合完成了对复旦语料的标注,并且通过停用词表去除了语料中的虚词和各种标点符号。
在聚类算法的确定、词干或词形还原算法的选择以及整个类别知识获取实验性能的评价过程中,纯度(Purity)和熵(Entropy)是被用来评价聚类效果的两个主要指标,具体公式如下[ 20]。若文本真实类别为q,经过聚类,获得了k个簇,则含nr个对象的簇Sr的熵值为:
E(Sr)=
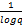 | (1) |
根据公式(1)得到的E值,评价聚类的熵计算方法如下:
Entropy= 
与计算熵一样,聚类簇Sr的纯度值为:
P(Sr)= 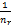
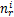
聚类结果的纯度值为:
Purity= 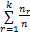
基于复旦语料,使用Bisecting K-means、K-means和Agglomerative三种聚类算法,经过实验所获取的聚类性能如表1和表2所示,其中,I1和I2表示两种不同的准则函数下的聚类结果。
| 表1 三种聚类算法在复旦语料上的Entropy性能 |
| 表2 三种聚类算法在复旦语料上的Purity性能 |
可以看出,Bisecting K-means最好Purity为0.671,在三种算法中是最好的,而Entropy最低达到了0.381,在三种聚类算法中也是最低的。基于三种聚类算法在Entropy和Purity上的表现,在挖掘英汉双语平行短语语料类别知识中使用Bisecting K-means算法。
2.2 英语词干或词形还原算法确定
英语词干或词形还原的算法主要有Porter Stemming、Snowball Stemming和Lemmatization三种。Porter Stemming[ 21]算法可以通过编写规则实现,词库不需要进行专门的维护,同时由于规则不能覆盖到所有的情况,所以不能达到完全正确。Snowball Stemming算法被简称为Porter2算法[ 22],该算法是Porter Stemming的强化版。Lemmatization基于词典与形态分析完成对词汇词干或词形的还原,该算法利用了词性的知识,可以将兼类词准确地还原成相应词对应的形式,所以词干或词形还原的精确度非常高,适合对大规模和专门语料的处理,但该算法需要一个足够大的词典来支持,基于Lemmatization算法开发的比较有影响的词干或词形工具有European Languages Lemmatizer[ 23]和斯坦福大学的Lemmatization[ 24]。
基于上述三种词干或词形还原算法,在20组 Newsgroups[ 25]语料上进行了验证,所使用的聚类算法为通过实验确定的Bisecting K-means Clustering,三种词干或词形还原算法的结果如表3和表4所示:
| 表3 Bisecting K-means Clustering下的词干或词形还原算法的Purity |
| 表4 Bisecting K-means Clustering下的词干或词形还原算法的Entropy |
可以看出, Bisecting K-means Clustering下的三种词干或词形还原算法,Lemmatization的平均Purity是分布较为均匀的,而Entropy从整体上看较低。同时,考虑到Lemmatization整合了另外两种词形或词干还原算法的优点,本文选取Lemmatization算法作为处理英汉双语专门复杂短语平行语料中的词干或词形还原算法。
3 语料的预处理
3.1 语料简介
为了研究基于从网络上抓取的英汉双语平行语料中挖掘类别知识,构建高效、精准的类别知识获取模型,从已获取的英汉双语专门领域平行语料库中,基于《中文社会科学引文索引》[ 26](CSSCI)的中文标题,通过检索程序,构建了人文社会科学英汉双语平行语料库。为了便于基于相应的聚类算法构建类别知识挖掘模型,对每一对英汉双语平行语料添加了类别知识,同时从平行语料长度和内部构成考虑,把该英汉双语平行语料称为英汉双语短语级平行语料。从选用聚类算法所在平台的效率和类别知识挖掘模型构建探究的角度考虑,所选用的英汉双语短语级平行语料的规模为6 343对,类别为20种。
(1)英汉双语复杂短语平行语料的字符处理
汉字编码主要由GBK、GB2312与Big5三种组成,而英语的编码则主要是ASCII、UTF-8与ISO 8859-1三种,本文通过语言识别程序统一转化为Unicode下的UTF-8编码格式。在具体转化的过程中,主要根据英语和汉语的编码范围完成,英语字符的编码范围为00000000-0000007F,而汉语的则为00000080-000007FF与00000800 - 0000FFFF。针对英汉双语平行语料中的字符全角和半角的问题,专门设计了程序处理这一问题,具体的代码如下:
text="recent weeks involving the region’s coal sector";//文本示例
for(int i=0;i< text.length;i++)
{
inta1=(int)ch[i]; if((a1==8216||a1==8217)&&i>0&&ch[i-1]<300&&i { s1=s1+"'"; } } (2)英汉双语短语级平行语料中的英语和汉语处理 利用Lemmatization算法,结合在研究过程中所选取的由593个英语单词构成的停用词表,完成了对英汉双语短语级平行语料中英语词汇的去除停用词、词干或词形还原,并且把连写词,如“You’re” 统一处理成了 “You ’re”。 根据英汉双语平行语料中汉语词汇的整体特征,选取ICTCLAS分词工具完成了对汉语的分词处理。相对于英语来说,汉语不需要进行词汇的形态转换,主要是使用停用词表去掉词汇中的数字、叹词、语气词、拟声词和各种标点符号。 在上述经过转换和处理后的英语和汉语基础上,把每一个英汉双语短语级平行语料对作为一个文本来处理,这实际上说明了本文类别知识获取的实质是基于短文本的类别知识自动聚类,经过处理后的英汉双语短语级平行语料对以文档-特征矩阵的方式储存。经过上述处理后的英汉双语平行语料样例如表5所示:![]()
表5 英汉双语平行语料预处理后的样例
4 基于英汉双语短语级平行语料的类别知识挖掘
英汉双语平行语料中蕴含着丰富的英汉词汇对照知识,这些词汇知识可以直接应用到类别知识的挖掘中,相对于单语的词汇知识,英汉双语词汇特征知识对于类别的挖掘在性能上具有更好的表现。本文将通过具体的实验验证英汉双语词汇特征在聚类中的性能表现。
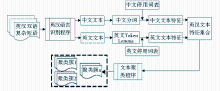
使用的聚类算法为Bisecting K-means Clustering聚类算法,语料规模是由145 528个词汇构成的英汉双语人文社会科学短语级平行语料。具体的类别知识挖掘流程如图1所示:
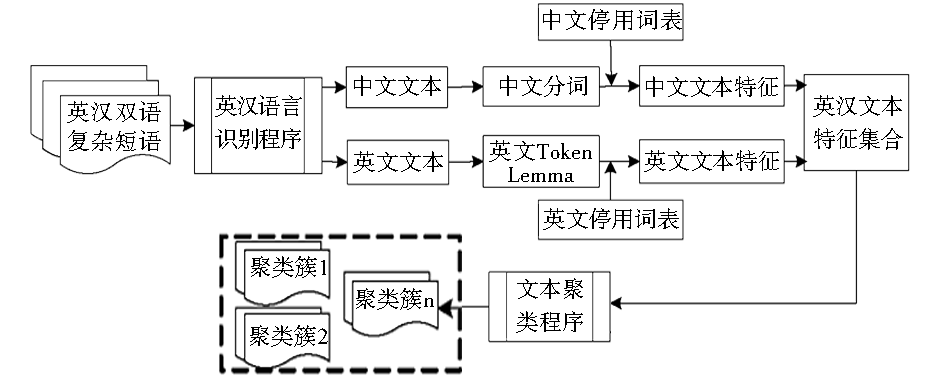 | 图1 基于英汉双语复杂短语平行语料词汇特征聚类流程 |
(1)基于汉语特征的类别知识挖掘性能
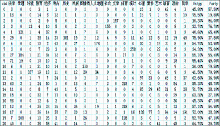
从英汉双语短语级平行语料中,单独抽取出汉语语料,根据图1的流程,完成对汉语的分词、停用词等处理,使用所选取的聚类算法,在指定的类别上完成了对英汉双语平行语料中的汉语语料的聚类。具体的汉语语料的聚类结果如图2所示:
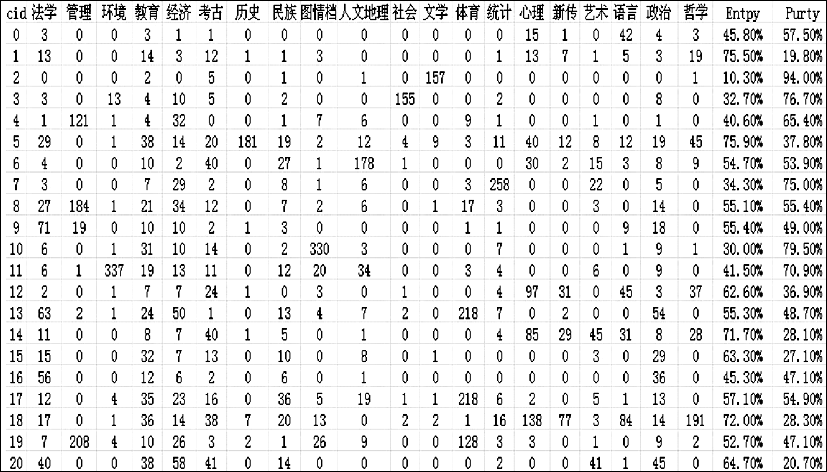 | 图2 汉语特征的聚类结果 |
根据已经获取的语料类别特征,结合CSSCI的具体分类,确定了所聚的类别为21个,共使用了1 164个汉语特征词。从整体看,基于汉语的聚类效果并不理想,Entropy达到了 54.00%,而Purity仅为 50.80%。在具体的21种类别中,第2类和第21类聚类的效果最差,Entropy最高达到了75.50%,而Purity则仅为19.80%。造成这一结果的主要原因是汉语分词精确率差,通用的汉语分词目前在精确率上达到了非常高的程度,但对于专门领域,尤其是对于人文社会科学这一专门领域的语料进行分词,效果并不理想,如“物权法、康乐园、元系统”等本应切分为一个词,均被错切成了“物 权 法、康 乐园、元 系统”。同时,由于人文社会科学学科之间的交叉比较复杂,相对于自然科学领域的类别知识获取而言,本身就有一定的难度。
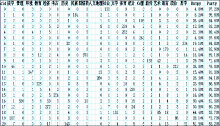
(2)基于英语特征的类别知识挖掘性能
与通过聚类算法挖掘汉语类别知识一样,通过单独抽取英汉双语短语级平行语料中的英语短语语料观察英语特征在聚类中的性能。英语聚类也是在指定的类别前提下完成的,结果如图3所示:
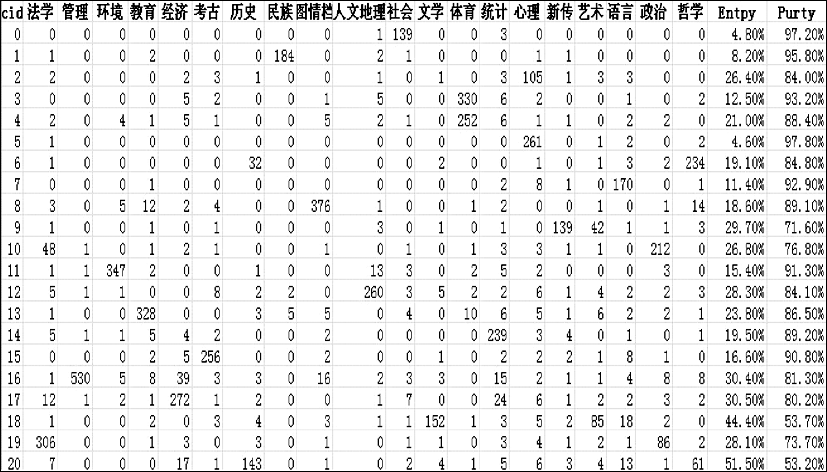 | 图3 英语词汇聚类的性能 |
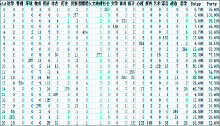
(3)基于英汉双语特征的类别知识挖掘性能
基于英汉单语聚类实验,在整合英汉词汇特征的前提下,基于指定的类别,全面验证了英汉双语词汇特征对于类别知识挖掘的影响,具体的英汉双语词汇特征聚类结果如图4所示:
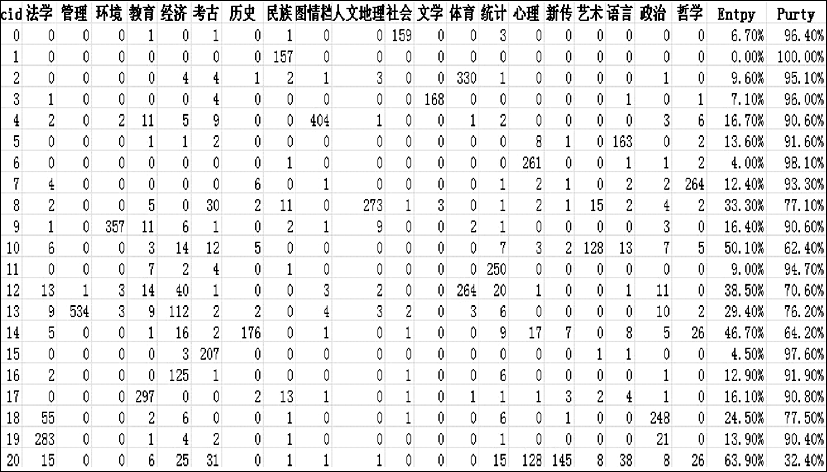 | 图4 基于英汉双语词汇特征的类别挖掘性能 |
在指定的21个人文社会科学类别下,基于7 800个英汉双语词汇特征,完成了英汉双语词汇的类别知识挖掘,Purity为81.90%,而Entropy则仅为23.30%,相对与单独的汉语词汇聚类结果而言,英汉双语在Purity提高了31.10%,Entropy上降低了30.70%,这是一个非常大的提升,有力地说明了英汉双语词汇的特征相对于汉语词汇特征来说,具有非常突出的优势。与英语单语词汇的聚类结果相比较,从整体上看,英汉双语的性能在Entropy上要比英语略好,而在Purity上则稍逊于英语单语。但从21类具体类别的聚类性能对比来看,英汉双语的聚类性能明显优于英语,因为造成英汉双语聚类效果整体表现不佳的原因,对于英语来说,是由于最后一类的性能非常差,Purity仅为32.40%,而Entropy则达到了63.90%,而英语最后一类的Purity就比英汉双语高20.80%。对于英语单语来说,从Purity和Entropy上观察,英汉双语的前20个类别分布均优于英语单语,在第2类中,Purity达到了100%,而Entropy则为0,同时在20个类中,英汉双语的Purity达到90%以上的有13类,而英语仅为7类,Entropy低于10%的英汉双语达到了7类,而英语仅有两类。
通过上述基于汉语、英语和英汉双语的类别知识挖掘和分析,相应的数据充分说明英汉双语词汇特征在类别知识挖掘的性能上要优于汉语和英语单语词汇特征,如果汉语分词效果在专门领域语料的分词上有略微提升,英汉双语词汇特征的性能就会更加突出。
5 结语
本文基于英汉双语短语级人文社会科学平行语料,在通过实验确定的Bisecting K-means Clustering聚类算法和Lemmatization英语形态转换算法的基础上,探究了短语级英汉双语类别知识挖掘的相关问题。通过对汉语、英语和英汉双语词汇级知识聚类的性能进行对比,在具体实验的基础上确定了英汉双语词汇特征的性能优于单语。在未来研究中,针对人文社会科学英汉双语平行语料库中汉语分词差的问题,结合人文社会科学关键词,设计专门的分词系统,以保证汉语人文社会科学词汇在句法和语义上的完整性,进而提高类别知识挖掘的整体性能。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|