{kind=link}
{kind=link}
专利文献中新技术术语识别研究
引用本文
谷俊. 专利文献中新技术术语识别研究. 现代图书情报技术, 2012, 28(11): 53-59
Gu Jun. Study on New Technology Detection in Patents Documents. 现代图书情报技术, 2012, 28(11): 53-59
Permissions
Gu Jun. Study on New Technology Detection in Patents Documents. 现代图书情报技术, 2012, 28(11): 53-59
Copyright©2012, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部版权所有
专利文献中新技术术语识别研究
摘要
主要介绍从中文专利文本中识别新技术术语的方法。利用ICTCLAS分词系统和停用词表抽取文档词元,通过改进的TFIDF模型计算词元权重并筛选出热点词元,再通过词间距测算对热点词元按顺序进行组配,经权重计算和阈值筛选后得到术语集,由专家人工判定识别出有效的新技术术语。最后给出应用实例并进行分析,验证该方法的有效性。
关键词:
技术生命周期; 术语识别; 热点词元
中图分类号:TP391
Study on New Technology Detection in Patents Documents
Abstract
This paper promotes a method which detecting new technology term from the texts of Chinese patents. Firstly, the element of terms in patents are extracted by ICTCLAS segmentation system and stop words lists. Then the hot elements of terms are filtered based on terms weights computing by improved TFIDF model. Secondly, the hot elements of terms are combined orderly by computing the distance between two words, and obtain the terms collection by terms weights computing and threshold filtering. The valid new technology terms are detected by the experts artificially. Finally, the availability of the method is proved through the applied example.
Keyword:
Technology life cycle; Term detection; Hot elements of terms
1 引 言
专利文献作为技术信息最有效的载体,囊括了全球90%以上的最新技术情报,相比一般技术刊物所提供的信息早5-6年[ 1],而且70%-80%发明创造只通过专利文献公开,并不见诸于其他科技文献,相对于其他文献形式,专利更具有新颖、实用的特征。对于企业来说,基于专利文献的技术生命周期的分析能够帮助企业总览技术发展路线,能够让企业挑选最优策略实现自身的技术发展,从而为自身谋取最大利益。
基于专利的技术生命周期反映了技术发展变化的不同阶段、包括萌芽阶段、成长阶段、成熟阶段和衰退阶段[ 2]。在萌芽阶段,由于该技术刚刚起步,企业进行技术投入的热情不高,专利申请量和专利申请人的数量都不多;在成长阶段,或是产业技术有了突破性进展,或是企业根据市场价值和行业政策的判断,增加研发投入,使得专利申请量和专利申请人的数量急剧上升;在成熟阶段,由于技术发展已经成熟,没有过多的企业愿意再花费成本投入该项技术的研发,也没有新的企业进入该领域,因而专利申请量和申请人数量增加趋势减缓;在衰退阶段,可能是替代技术的出现,或者该技术研发遇到了瓶颈,导致专利申请量和申请人数量逐步减少。依据技术生命周期理论,如何从专利文本中识别出新的技术术语,为企业提供相应的信息,是本文研究的重点。
2 相关研究
目前,基于中文专利的新技术术语识别研究相对较少,国内外的关于“新术语”的报道基本限于新闻事件检测领域,因此,本文受上述研究的启发,尝试将新事件的识别应用于新技术术语识别研究中。国内外对于新闻报道中新事件检测与识别方面的研究较为广泛,Zhang 等[ 3]以聚类结果作为话题的宏观描述,并将类簇中的相关报道作为话题的具体内容;Chanlekha等[ 4]针对全球部分地区经常爆发规模较大的疾病问题,首先利用标准语料库作为机器学习的训练语料,同时对新闻报道进行监控,利用支持向量机对新闻事件进行分类,识别出疾病爆发的地区; Ramadan等[ 5]对新闻事件识别的主要步骤(数据预处理、数据描述和数据组织)进行论述,并指出每个步骤中可能出现的问题,提出相应的解决方法,最后利用现有方法对新闻报道中的犯罪类事件进行识别;Sun等[ 6]提出根据新闻和微博的事件内容进行聚类识别事件的方法,并为此构建识别框架;Tu等[ 7]针对现有的新闻事件识别方法中过度偏重词频而忽略了事件新颖性的问题,提出新事件检测的指标体系,包括新颖性指标(NI)和报道规模指标(PVI),通过该算法,可以测算出特定领域事件的新颖程度及生命周期;Dai等[ 8]为解决单条报道中包含的事件特征词语过少的现象,利用AP(Affinity Propagation)和AHC(Agglomerative Hierarchical Clustering)算法构建出AP-AHC模型,解决了单个新闻报道中事件特征词过少的问题;张阔等[ 9]提出利用统计方法优化不同类别新闻对于不同词性词元的权重参数,并利用已有的新闻簇信息动态更新词元权重的方法,取得了良好的效果;洪宇等[ 10]提出基于子话题的比例关系和分布关系建立新话题识别模型,尝试从中抽取新事件;贾自艳等[ 11]借鉴Single-Pass的聚类思想,结合新闻要素给出一种基于动态进化模型的事件探测方法,并以实验证明该算法的有效性;姚占雷等[ 12]利用词间距构建基于互联网新闻报道的突发事件识别模型,并以实验证明该模型在时间上具有较高的敏感性;陈伟等[ 13]提出了一种面向新闻数据流的在线事件检测方法,通过进化谱聚类算法将新闻突发性特征进行聚合,实现事件的识别。总的看来,在新事件识别领域,大多是通过词典分词后,再依据时间轴的分布,按照不同领域的新闻分布进行归类,从而发现新闻报道中的新事件术语。
新闻中的事件识别通常针对某一个时间段中爆发的特定主题的新闻报道进行检测,而在专利文献中,随着科学技术的不断进步,新的技术术语也会随着外部环境(政策环境、经济环境、技术环境等)的变化形成爆发式增长。因此,本文借鉴上述思想,从专利名称、摘要、申请人和申请时间4个方面入手,通过分析词语在语言描述上的特征以及新技术与申请人和专利文献之间的关系,尝试探索新技术术语的识别方法。
3 实验数据
中国国家知识产权局专利检索平台(http://www.sipo.gov.cn)涵盖了1985年以来所有在中国申请和公开的发明、实用新型和外观设计专利,根据国家专利局统计,截至2010年12月,在华发明、实用新型和外观设计专利总量约为703万件,其中发明专利将近200万件[ 14]。为了验证本文所述方法的可行性,从其中下载了截至2010年12月标题或摘要中含有关键词“炼铁”的专利数据作为实验对象,共计1 403件专利。从表结构上看,包括申请号、申请日、名称、公开(公告)号、主分类号、分案原申请号、分类号、颁证日、申请(专利权)人、地址、发明(设计)人、国际申请、国际公布、进入国家日期、专利代理机构、代理人、摘要、公开日、优先权等字段。由于本文主要研究如何结合专利申请人和年份信息,从文本中识别新技术的方法,因此,只从中抽取了标题、摘要、申请日和专利权人等作为主要的实验数据。
4 方法描述
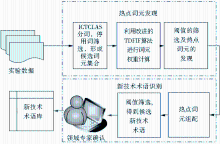
新技术的萌芽、成长、成熟和衰退是一个动态的过程,时间对于技术发展阶段的识别具有重要意义,在指定的时间段内出现频率相对较高的词汇通常有助于找到该阶段技术研发的热点;同时,描述新技术的词汇往往是由两个以上已知词汇搭配组成,这种固定搭配关系会被一直沿用下去,因此,本文将通过热点词元发现和新技术术语获取两个主要步骤实现中文专利中新技术术语的识别。
(1)使用中国科学院计算技术研究所开发的ICTCLAS分词系统对专利中的名称和摘要进行初步分词,记录每个词在句子中出现的位置;
(2)利用改进的TFIDF算法对分词结果进行计算,得到每个词的权重,并进行过滤,完成热点词元的发现;
(3)根据词汇间的位置关系,以每篇专利为一个单元,对涉及到的热点词元按其在文本中出现的顺序进行组配,存入候选技术术语库;
(4)对候选技术库中的词汇分别按其在标题和摘要中出现的频率进行计算,经阈值筛选后得到技术术语;
(5)依据技术生命周期理论,按年统计每个描述词汇的专利数量和申请人数量,经人工判定得到最终的新技术术语集。
具体步骤如图1所示:
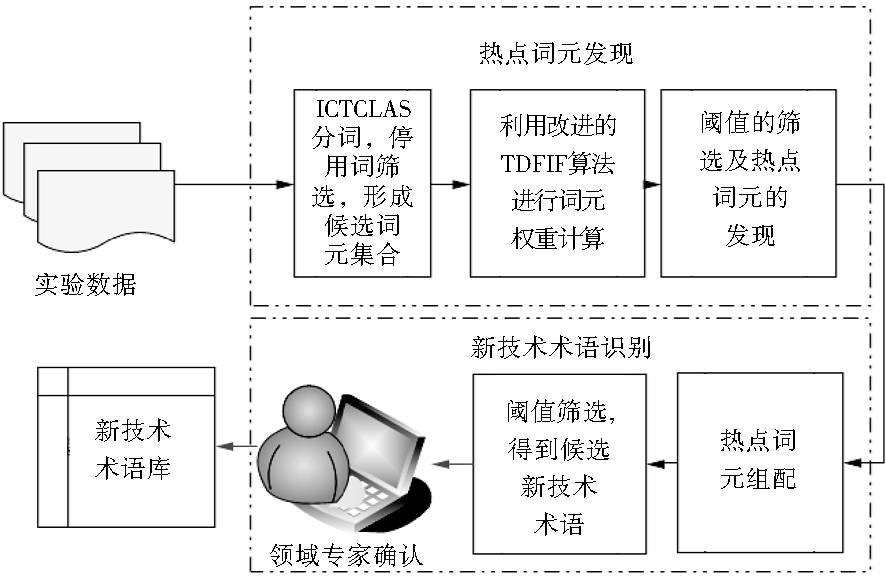 | 图1 新技术术语识别步骤 |
4.1 预处理
首先对实验数据中的标题和摘要信息使用ICTCLAS分词系统进行分词处理。ICTCLAS是一种基于层叠隐马尔可夫模型的词典分词方法,它将汉语词法分析的所有环节都统一到了一个完整的理论框架中,分词速度为500KB/s,分词精度达到98.45%。ICTCLAS能够很好地实现汉语分词、切分排歧、未登录词识别、词性标注等词法分析任务,是目前最好的汉语词法分析器之一[ 15]。为了确保后期识别的有效性,需要利用人工设定的停用词表对分词结果进行筛选,剔除无用的虚词、数量词、标点符号和不能体现文档意义的词和符号,形成分词结果集。同时还需要记录每个词元在语句中出现的位置(如果摘要中有多个句子,则按照句子出现的顺序和词元在句子中出现的顺序依次记录),便于在新技术识别阶段对热点词元按顺序组配。预处理结果如表1所示:
| 表1 预处理结果片段 |
4.2 热点词元发现
热点词元是在一个时间段内申请的专利文本中,被广泛关注的词元(词或短语)。而从文本中抽取这些词元的过程则为热点词元发现。通过对技术生命周期理论的分析,笔者认为在热点词元发现过程中,不仅需要考虑到词频信息,还需要从以下两个角度进行考虑:
(1)技术的生命周期是按一定的时间跨度进行分析的,根据实际需要,通常这个跨度设定为3年至10年不等。而对于新技术术语识别来说,每年的专利文献中词元的组成及其词频信息会因为相关技术的更新和发展而有所不同。因此,为了能够尽早发现新的技术术语,笔者认为将时间跨度定为1年比较合适;
(2)一旦某种新技术进入发展阶段,不仅专利申请量会逐步增加,专利申请人的数量也在迅速增加,这种现象可以理解为市场和政策的引导,推动企业为新兴技术投入更多的研发成本。因此,专利申请人的数量对于新技术识别来说也具有一定的指导意义。
为此,本文对传统的TFIDF模型进行改进,增加申请年和申请人的因素,从而计算得到每个词元的综合权重,公式[ 12]如下:
wi= 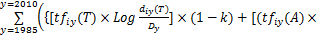
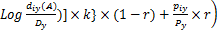 | (1) |
其中,wi表示词元i的权重,tfiy(T)表示在年份y内所有专利名称中出现词元wj的总数,diy(T)表示在年份y内名称中包含词元wi的专利数量,tfiy(A)表示在年份y内专利摘要中出现词元wj的总数,diy(A)表示在年份y内摘要中包含词元wi的专利数量,Dy表示在年份y内所有专利数量;piy表示在年份y内与词元wi相关的专利中申请人的数量,Py表示在年份y内申请人总数;k(0≤k≤1)和r(0≤r≤1)均为调节因子,k用于区分词元在专利名称和摘要中TFIDF值的重要程度,在这里设定为0.2,r表示专利权人的权重对于词元权重的影响程度,当r=0时,表示专利申请人对于词元的权重没有影响,当r接近1时,表示专利申请人对于词元的权重影响逐步增大。通过咨询,相关专家认为专利申请人数量的增减能够反映出某项新技术发展的趋势,与专利文献中词元数量变化同等重要,因此,在这里设定r=0.5。计算结果如表2所示:
| 表2 词元权重计算结果实例 |
计算过程如下:
①从预处理结果(表1)中抽取专利号和词元放入临时表(TmpTable)中;
②声明变量i(初始值为1),临时表的记录总数(记为n),累计权重W(初始值为0);
③若i不大于n,跳至步骤④,否则跳至步骤 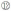
④声明年份变量j(初始值为1985),若j不大于2010,跳至步骤⑤,否则跳至步骤 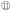
⑤以j为年份限制条件,计算当年名称含词元的总文档数量(nDocTotalTitle),摘要含词元的总文档数量(nDocTotalAbstract),词元在名称中出现的词频(nKeyTitle)和词元在摘要中的词频(nKeyAbstract),以及当年总专利数量(nDoc);
⑥计算nKeyTitle×log(nDocTotalTitle/nDoc)×(1-k)+nKeyAbstract×log(nDocTotalAbstract/nDoc),赋值给变量f1;
⑦以j为年份限制条件,计算专利中与词元相关的专利权人数量(nPri)和当年的专利权人总数(nPriTotal);
⑧计算nPri/nPriTotal,赋值给变量f2;
⑨计算f1×(1-r)+f2×r,并将结果与W累加;
⑩计算当前词元下一年的权重,j自增1;
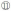
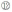
通过观察,权重小于0.05的词元基本为炼铁领域的常用词,因此本文认为将词元权重的筛选条件设置为0.05比较合适,保留权重大于0.05的词元,其余予以剔除,经过计算,共获得84 751个词元,阈值筛选后得到756个热点词元,占词元总数的0.9%。
4.3 候选技术术语获取
识别出的热点词元可能仅仅是新技术描述的一个碎片,无法诠释技术的完整含义,需要将这些碎片按其在句中出现的顺序进行组配,从而获得对新兴技术描述的术语。首先按词元在文本中的位置按1的词间距进行字符串顺序拼接,直到满足指定条件后将其存入候选术语库中;然后计算候选术语在专利名称和摘要中出现的频率,并对候选技术术语库进行更新;按年份计算每个候选技术术语在专利名称和摘要中的词频与当年所有专利申请量的比值,得到该术语的权重;最后经过阈值筛选,提取结果。词元组配需要遵循以下几个原则:
(1)必须按照表1中给定的词元在文中出现的前后顺序进行组配,组配时,两个词元之间的位置距离(词间距)必须为1,表示两个词元为相邻词元,若大于1,则不进行组配。
(2)通过咨询领域专家,笔者了解到构成技术术语的词元数量一般不会超过5个,基于该假设,设定词元组配的最大值为5,即当参加组配的词元数量超过5时,对其进行截断处理。
(3)候选技术术语生成后,在特定时间段内的状态,决定该术语是否能够成为新技术术语,或者被专利申请人持续关注,因此通过计算特定时间段内术语出现的频次与专利申请量的比值,可以实现候选术语的过滤,公式如下:
wt=
 | (2) |
其中,wt表示候选术语t的权重,F(T)ty表示在y年里术语t在专利名称中出现的频次,F(A)ty表示当年术语t在专利摘要中出现的频次,Dy表示当年专利申请的总量,r为调节因子,体现标题和摘要在术语识别中的重要程度。本文将r暂定为0.2,即标题权重为0.8,摘要权重为0.2。计算结果如表3所示:
| 表3 候选技术术语获取结果 |
定义1:专利数据集PC,用于存放专利号、标题、摘要、年份、申请人等信息,Countpc表示PC总条目数;
定义2:预处理结果集PD(见表1),用于存放经分词预处理后的结果集,包括专利号、词元、词元在句中的位置等信息;
定义3:词元ET,PD中存储的分词结果,需要对其进行组配,词元位置PT,表示词元ET在句中出现的位置;
定义4:词间距TL,表示预处理结果集PD中对应专利号相同的词元之间的距离,如果TL>1,表示两个词元不相邻,不可以进行组配,如果TL=1,则可以进行组配;
定义5:词元总数阈值TF,按照假设,TF=5,如果参加组配的词元总数超过TF,则对其进行截断;
定义6:候选术语表TC,存放经过词元组配成功后的词串、词串的名称词频、摘要词频以及词串的权重信息。
具体的识别策略如下:
①声明变量i(初始值为1),若i<=Countpc,跳至步骤②,否则跳至步骤 
②从预处理结果集PD中抽取相同PC中专利号相同并且权重大于阈值0.005的词元,放入临时表(记为TmpTable);
③声明变量j(初始值为1),临时表记录总数n,变量临时字符串sTmp;
④若j<=n,则跳至步骤⑤,否则跳至步骤 
⑤从TmpTable中按顺序取出相应的词元ET,如果ETj与ETj+1词间距TL为1,表示这两个词元为相邻词元,则将这词元ETj和ETj+1合并和存入sTmp(sTmp+=ETj+ETj+1),转向步骤⑩;
⑥如果两个词元词间距不为1,则表示这两个词不相邻,当前词元组配结束,若sTmp此时词元数量为1,说明没有构成术语,跳至步骤⑩,否则跳至步骤⑧;
⑦如果sTmp中合并的词元ET总数超过阈值TF,则按TF值进行截断,并跳至步骤⑧;
⑧如果候选术语表TC中没有找到与sTmp匹配的记录,则在表中新增一条记录,同时将相应的名称和摘要词频设为1;如果找到了匹配记录,则在原有记录中将标题和摘要词频加1;
⑨依据公式(2)计算候选术语的权重,经归一化处理后更新候选术语表TC的权重信息;
⑩j自增1,转向步骤④;
经过计算,共得到438个候选技术术语,以0.005的阈值进行筛选,获得最终的技术术语集。
4.4 新技术术语识别
得到的技术术语并不能立刻被确认为新技术术语,需要进一步处理后才能认定。按照技术生命周期理论,技术的发展与专利数量和专利申请人数量密切相关,因此,本文通过统计与技术术语有关的专利数量和专利申请人数量按年代的变化情况,并以图形的方式描述出某项技术在专利文献中的数量变化过程,最终由领域专家人工选择出代表新技术的术语。
步骤为从技术术语集中取出单个术语,从专利表中抽取与该术语相关的专利文档,统计其文档数量及专利申请人的数量并保存结果;根据统计结果绘制技术生命周期图;由相关技术专家的判断和挑选,完成新技术术语的识别。
5 实例及分析
本系统的开发环境采用了Windows XP操作系统,Visual Studio 2008(C#)和SQL Server 2008数据库,从实验数据中共计识别出73个候选技术术语。由于炼铁技术发展时间较长,高炉炼铁已经是较为成熟的炼铁方法,技术更新换代速度较慢,因此,仅筛选出诸如“富氧鼓风”、“高压冶炼”、“喷吹燃料”、“铁水预脱硅”和“熔融还原”等少量候选技术术语。其中笔者发现“熔融还原”这一术语的权重较高,达到了0.09。为了验证本文方法在新技术术语识别时的有效性,以年份为单位,逐一测算该术语在每一年的识别情况和累计权重。测算结果如表4所示。
可以发现,从2000年开始,技术术语“熔融还原”的累计权重已经超过本文给出的术语识别阈值
| 表4 “熔融还原”年份累计权重(1985-2010) |
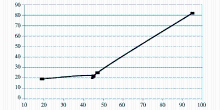
0.005,此时可以将其作为一个新技术术语进行监控;到2001年,该术语的累计权重骤然提高,突破0.05,这时应该将该术语作为一个重点技术术语予以关注。为了了解该术语在实验数据中的变化情况,笔者从年份、与术语相关的专利数量和申请人数量三个方面对实验数据进行统计,结果如表5所示。并以5年为一个时间段,为其绘制技术生命周期图,如图2所示:
| 表5 “熔融还原”相关专利数量和专利权人数量趋势(1985-2010) |
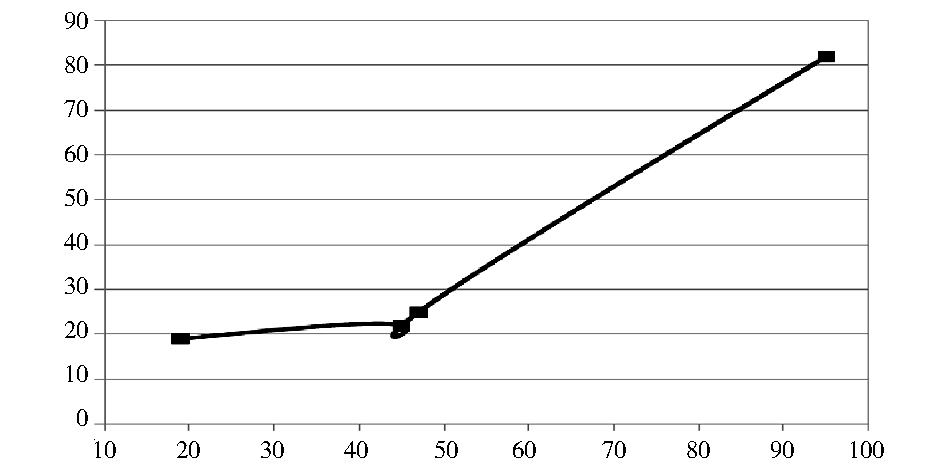 | 图2 “熔融还原”技术生命周期图(1985-2010) |
可以看出,2000年之前,“熔融还原”相关技术的专利数量和申请人数量都不多,可以判定该项技术在中国可能还处于萌芽期。自2000年到2010年,申请量和申请人数量都出现了较大幅度的增长,说明在我国此技术进入发展期。为了探究其原因,笔者咨询有关专家并查阅相关资料发现,1997年在日本京都召开旨在改善气候变暖问题的《气候框架公约》第三次缔约方大会,在会议上通过一项国际性公约——《京都议定书》,该公约要求在2008年至2012年间,全球主要工业国家的工业二氧化碳排放量必须比1990年的排放量平均要低5.2%[ 16]。我国则在1998年签署了这一议定书,标志着中国进入了“节能减排”时代。
在钢铁生产过程中,高炉炼铁是环境污染的主要因素,熔融还原炼铁则是一种非高炉炼铁技术,相比高炉炼铁,不管是炼铁成本还是废气排放量都有大幅度降低。因此,钢铁企业为了在炼铁新技术领域占有一席之地,争相开发熔融还原的相关技术,从而出现了2000年之后专利数量和申请人数量明显增多的现象。
6 结语
新技术术语的识别能够让企业及时监控行业的最新研发动向,调整自己的研发重点,从而在激烈的市场竞争中占据有利位置。本文借鉴新闻报道中新事件检测的相关思想,结合技术生命周期理论,通过分词、候选术语获取和新技术术语识别等步骤,实现了专利文本中新技术术语的提取。实验证明,由于专利时间和申请人数量因素的加入,该方法具有一定的有效性。
然而,本文选择的实验数据规模较小,而且只选择了名称和摘要中出现过“炼铁”的专利,针对性较强,无法证明其在大规模数据中的通用性;此外,由于基于统计方法本身的不足,本文对新词的敏感度不高,新的技术术语在出现初期无法被正确识别,即使被识别出来也会因累计权重不高而被剔除,只有在技术发展阶段才能被认定为新技术术语而单独列出。在实际应用阶段,可能会因为这种问题导致企业丧失技术发展的最佳时机,需要进一步解决和完善。在今后的研究中,一方面要提高实验数据的规模,以测试本方法的通用性;另一方面,需要探寻新的解决方案,合理增加技术术语在出现初期的权重,从而进一步提高新词敏感度,为企业的专利预警实践提供有意义的帮助。
[14] 国内外三种专利申请受理状况总累计表 [EB/OL]. [2011-07-22]. http://www.sipo.gov.cn/sipo2008/ghfzs/zltj/zljb/201101/t20110110_562647.html.(Three Kinds of Patents Received Total Cumulative Table [EB/OL]. [2011-07-22]. http://www.sipo.gov.cn/sipo2008/ghfzs/zltj/zljb/201101/t20110
110_562647.html.)
[15] ICTCLAS简介 [EB/OL]. [2011-06-10]. http://ictclas.org/ictclas_feature.html.(Introduction to ICTCLAS [EB/OL]. [2011-06-10]. http://ictclas.org/ictclas_feature.html.)
[16] Kyoto Protocol to the United Nations Framework Convention on Climate Change[EB/OL].[2011-08-12]. http://unfccc.int/resource/docs/convkp/kpeng.html.
(作者E-mail:jungu@yahoo.cn)
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|